基于稀疏自动编码器的深度神经网络实现
2018-01-18张光建
张光建
(四川建筑职业技术学院,德阳 618000)
0 引言
监督学习是人工智能的最强大的工具之一,目前在自动邮政编码识别,语音识别,自动驾驶汽车等应用上取得了明显的成功。但监督学习在应用中需要人工对输入样本进行特征提取,只有良好的特征提取,监督学习系统才能成功学习,所以大量的研究人员需要花费大量的精力和时间去研究如何更好的提取样本特征,但提取的特征对于新问题的解决又不具有通用性。深度网络中的自编码器(Deep AutoEnoder,DAE)可以自动提取对象特征,降低输入维度,充分发掘海量数据中蕴藏的丰富信息。
自动对无标记样本进行特征提取,可以使用自编码器来完成。自编码器(AutoEncoder,AE)算法有4类:基于稀疏理论的AE被称为稀疏自编码器,它是目前应用最为广泛的深度自编码器。
1 深度神经网络
1.1 深度神经网络
早期应用广泛的BP神经网络[1]是人工神经网络(Artificial Neural Network,ANN)的一种模型,如 图 1所示。它属于浅层网络,由于运算速度和学习算法的限制,网络中隐藏层的数量很少,模型一般由三层构成:一个输入层,一个隐藏层,一个输出层。输入是训练数据,中间是隐藏节点,输出是标记。训练数据可以用一定的权重激活隐藏节点,隐藏节点激活输出标记。
深度神经网络(Deep Neural Network,DNN)一般包含多个隐藏,模型如图2所示。研究表明多个隐藏能更好地刻画对象的特征。就如人眼看一幅图片,凑近眼睛上只能看到几个像素,而远看还能看清图片的全貌。
神经网络的层数多起来,就如远看一张图片一样,是观察粒度上的改变。而更宏观的粒度层面是由更微观的粒度层面一层一层传递和堆砌出来的,这个传递过程需要信息丢失尽可能少。

图2 深度神经网络
DNN模型本质上是多层ANN的模型,但深度神经网络和传统ANN在权值的初值选取和训练机制等方面截然不同。主要在于权值的预先训练算法上。由于DNN模型中层数过多,权值的数量将会呈爆炸性增大,如输入的是一幅像素为1K×1K的图像,隐含层有1M个节点,光这一层就有1012个权重需要训练。有别于传统ANN的BP学习;深度神经网络的学习是采用深度学习。
1.2 深度学习
深度学习(Deep Learning,DL)是 Geoffrey Hinton等人[2]提出的,在2006年提出的。是在非监督数据上建立多层神经网络的一个有效方法,Hinton证明了多隐藏层的人工神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻画,从而有利于可视化或分类;深度神经网络在训练上的难度,可以通过逐层预训练[3](layer-wise pre-training)来有效克服,逐层预训练是通过无监督学习(Unsupervised learning)实现的。
根据Geoffrey Hinton的训练过程,分为两步,一是每次训练一层网络,二是调优使原始输入的x向上生成的高级表示r和该高级表示r向下生成的x′尽可能一致。方法是逐层提前预先训练每一层的权值,并且只需要使用无标记的样本(无监督训练)。当每一层都预先训练完毕后,再使用少量的有标记样本进行有监督的梯度下降,完成微调。
对一幅大小为256×256像素的图片,深度学习模型如图3所示。
2 自编码器
自编码器[4]是一个典型的前馈神经网络,它的目标就是学习一种对数据集的压缩且分布式的表示方法(编码思想)。

图3 深度学习模型
2.1 自编码器的基本模式
自编码器由编码器和解码器两部分组成。如图4所示。将标记样本输入编码器,得到输入的表示。如果解码器的输出与输入相似(在误差允许的范围里),就证明解码器是正确的。可以通过调整编码器和解码器的参数,使得重构误差最小。对无标签数据,误差的来源就是直接重构后与原输入相比得到。编码器网络在训练和部署的时候使用,译码器网络只是在训练的时候使用。编码器网络的目的是找到一个给定的输入的压缩表示。

图4 自编码器模式
2.2 自编码器实现原理
自编码器由三层构成,L1为原始输入层,L2为编码层,L3为解码层,如图5所示。其中在L1和L3层中神经元数相同,L2层神经元数目要小于L1层。
自编码器通过输入x,一个编码器函数 f,输出表示y=f(x);解码器函数g,输出r=g(h)=g(f(x))。对无标记的训练样本集 x,其中x(i)∈Rn,网络理想目标是输出值精确等于输入值,,但一般很难达到,所以满足,h(W,b)(x)≈x。输出是对输入的重构。
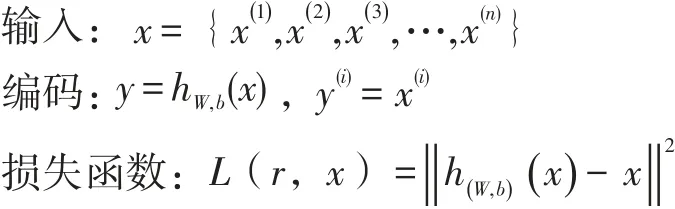
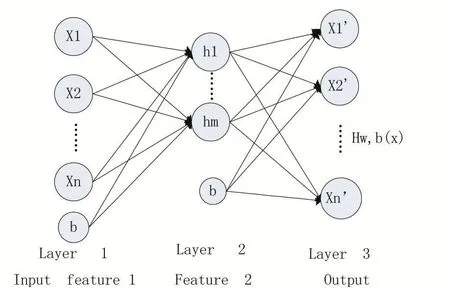
图5 自编码器结构
深度学习是基于神经网络,深度学习创造性在自编码和稀疏性。自编码是深度学习把原始输入当作训练数据,输出还是训练数据,这样假如中间神经元数比原始输入数据少,就会对原始输入数据起了个压缩的作用。稀疏性是中间神经元多一点,为防止训练过拟合,可以加一个限制,假设每个训练数据都激活尽量少的中间层神经元(人类大脑对每个输入不可能所有神经元都起反应,肯定也是少量神经元有反应)。训练出来的模型就可以很好的表示原始数据,再对训练好的数据在有监督的数据上做进一步训练,可以满足新的需求。稀疏自编码模型是一种无监督学习模型,也可以对数据进行降维。
神经网络学习到的实际上并不是一个训练数据到标记的“映射”,而是去学习数据本身的内在结构和特征(也正是因为这,隐含层也被称作特征探测器(fea⁃ture detector))。通常隐含层中的神经元数目要比输入层的少,这是为了使神经网络只去学习最重要的特征并实现特征的降维,如假设输入x是一幅10×10的图像(100像素),n=100,即L1层的s1=100,在L2层的s2=50,y∈R100,因为隐藏层只有50个神经元,网络被迫学习压缩表示的输入。获得隐藏一个神经元激励函数a(2)∈R50,它需要重新构建100个像素的输入x。这是简单的自编码器,类似于PCA模型(传递函数不使用sig⁃moid而使用线性函数,就是PCA模型)。自编码器的隐藏层的神经单元数目大于输入数量。可以使用稀疏约束规则完成。
2.3 稀疏自编码器(Sparse Autoencoder)
稀疏自编码器[5]是在原型自动编码器的代价函数中增加稀疏惩罚约束条件,模式如图6所示。
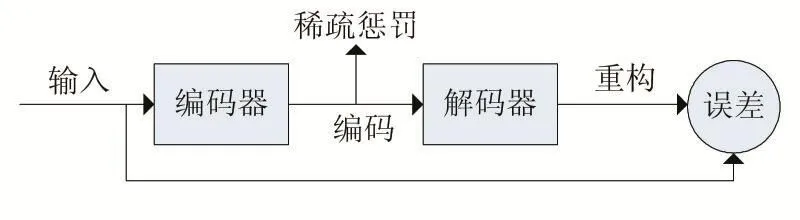
图6 稀疏自编码器模式
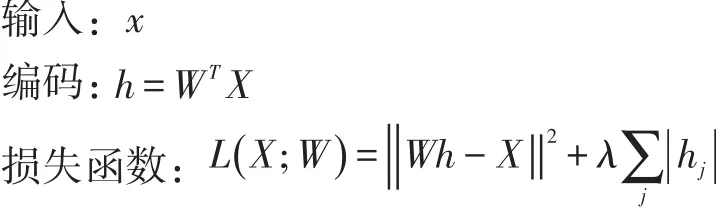
3 仿真
使用 MATLAB R2015a版本的 AutoencoderDigit⁃sExample调试,对NIMIST为训练样本集,样本集是28×28像素的手写数字图像。部分样本如图7所示。

图7 部分样本图
建立第1个自编码器,输入为无标记样本,每个样本是784维。输出定为100(一般输出要比输入小,这样才能起来压缩提取输入特征的目的)。建立前馈神经网络的模型如图8所示。提取出来的特征可视化如图9所示。

图8 自编码器结构
如果自编码器1的输出与输入的误差达到要求,即可确定自编码器1对特征的提出有效,完成编码器训练。可视化自动提取的特征如图所示。

图9 自动提取特征
用同样的方法完成第二个自编码器的训练。使用第一层的自编码器的输出作为输入。模型如图10所示。
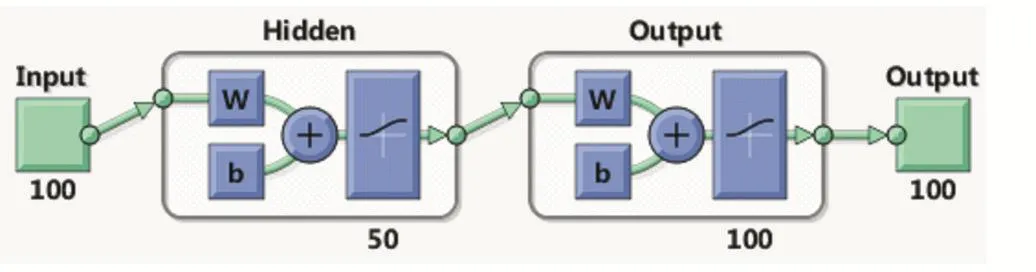
图10 自编码器2
深度网络的最后一层是级联了一个Softmax分类器,这一层是有监督学习,使用验证数据集(有标记样本)再进行0-9的10类的模式识别。Softmax是训练多分类器,Sigmoid函数只能分两类,而Softmax能分多类,Softmax是Sigmoid的扩展。最后根据2个编码器提取的特征(权值),重新组建深度神经网络模型如图11所示。
根据如图12所示的混淆矩阵,可以看到数字识别正确率为99.5%。使用自编码器学习提取的特征来建立模式识别系统,系统具有很好的识别率。

图11 深度神经网络模型
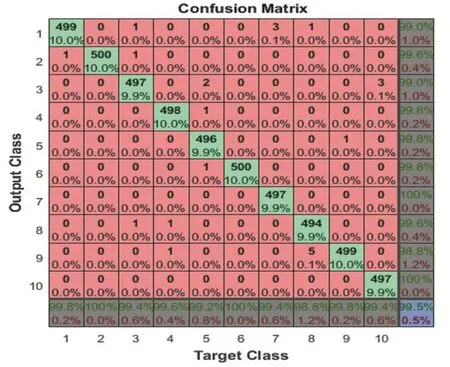
图12 混淆矩阵
4 结语
自编码器是在特征层次结构的深度模型中以无监督特征学习为目的,使用逐层初始化的训练方法来建立问题模型。仿真中可以看到在深度神经网络的应用中,使用的隐藏层数,以及需要使用多少个自编码器才能达到对象特征的有效提取,这些都是根据经验及应用的误差需求进行反复实验测试来得到,目前还没有比较完善的公式及推理。
深度网络中的自编码器是通过学习输入数据的结构得到初值,这个初值更接近全局最优,从而能够获得更好的效果。大数据的训练不易造成过拟合。
[1]张光建.基于神经网络的钢筋混凝土碳化深度预测研究[J].成都航空职业技术学院学报,2016,01:67-69+77.
[2]HINTON G,OSINDERO S,THE Y.A Fast Learning Algorithm for Deep Belief Nets[J].NEURAL Computation,2006,18(7):1527-1554.
[3]BENGIO Y,LAMBLIN P,POPOVICI D,et.Greedy Layer-Wise Training of Deep Networks[C].Proc of the 12th Annual Conference on Neural Information Processing System,2006:153-160.
[4]Rumelhart D E,Hinton G E,Williams R J.Learning Rep-Resentations by Back-Propagating Errors[J].Nature,1986,323:533-536.
[5]Luo Xuxi,Li Wan.A Novel Efficient Method for Training Sparse Auto-Encoders[C].Proc.of the 6th International Congress on Image and Signal Processing,2013:1019-1023.
