基于缺陷的测试用例优先级排序方法
2018-01-17朱凌燕
朱凌燕

摘 要 测试用例的优先级排序是提高回归测试效率的有效手段,针对回归测试用例的选择和执行问题,考虑缺陷影响因素,将缺陷严重性、缺陷优先级和出错原因等因子应用于测试用例优先级排序。通过实验,比较测试用例排序前和排序后的缺陷检测情况。结果表明,排序后的测试用例能够提高回归测试的效率,有效保证软件产品的质量。
【关键词】回归测试 测试用例 优先级排序 软件缺陷
回归测试作为测试流程的重要环节,用于验证缺陷是否解决以及缺陷的解决是否引起其他潜在缺陷的出现。回归测试阶段如果毫无策略地执行已有的测试用例集,势必会造成大量的时间和人力资源的浪费。为了降低回归测试的成本,国内外科研人员将测试用例优先级排序技术引入到回归测试阶段,根据不同条件充分考虑测试用例的重要程度,赋予每个测试用例一个优先级,根据优先级从高到底的顺序依次执行测试用例,从而提高测试用例的使用效率。1997年,Wong等最先提出了在回归测试选择技术基础上对测试用例集进行最小化或优先级处理,根据测试用例的覆盖能力对测试用例进行优先级排序;2002年,Kim等研究了综合考虑各种测试历史的优先级技术;2005年,Srikanth等研究了基于需求的回归测试用例优先级技术;2006年,Walcott等研究了与时间因素相关的优先级技术;2010年,KeZhai等研究了基于位置的服务软件测试中的测试用例优先级排序;2012年,潘伟丰等人研究了一种基于复杂软件网络的回归测试用例优先级排序方法。
本文从软件缺陷角度出发,充分利用上一轮软件测试的结果,引入与软件缺陷相关的影响因子,对测试用例进行优先级排序,提高回归测试的效率。
1 测试用例优先级排序方法
1.1 定义
Rothermel将测试用例优先级排序定义为:T为给定的测试用例集,PT为T中测试用例所有可能的执行顺序,f为PT到实数集的映射函数,测试用例优先级的研究目标就是找到其中的一个排列T'∈PT,使得对于任意的T''∈PT且T''≠T',都有f(T' )>f(T'')。f是对排序目标的定量描述,用来度量排序的有效性,f的值越大,表明测试用例的排序越有效。
1.2 影响因子
目前,围绕回归测试用例优先级排序问题主要在寻找影响测试用例优先级的因素等方面展开。本文针对映射函数f的定义,将测试用例的缺陷检测能力DDA(defect detection ability)作为其优先级排序的取值,将发现缺陷的严重性、优先级和出错原因等作为缺陷检测能力的影响因子。以下针对各个影响因子,分别得出其影响缺陷检测能力的量化值。
1.2.1 缺陷严重性
根据缺陷对软件运行造成的影响来划分缺陷的严重性,一般分为四个等级:致命缺陷、严重缺陷、普通缺陷、轻微缺陷。具体定义如下:
致命缺陷:造成系统或应用程序崩溃、死机;造成数据丢失;主要功能完全丧失,导致本模块以及其他模块异常等问题。
严重缺陷:系统的主要功能部分丧失,导致本模块功能失效或异常退出,但不影响其他模块;次要功能完全丧失;数据丢失,但可以回复。
普通缺陷:次要功能没有完全实现,但不影响系统的基本使用;提示信息不准确;操作时间长等。
轻微缺陷:拼写错误,界面美观等问题,不影响功能的操作和执行。
按严重性从高到低的顺序依次定义一个1到10之间的值。ds代表不同缺陷严重性对应的量化值,其中致命缺陷的ds值为8,严重缺陷的ds值为4,普通缺陷的ds值为2,轻微缺陷的ds值为1。使用公式(1)量化得到第i个测试用例发现不同严重性缺陷的能力值ESi。
式(1)中,Si表示第i个测试用例发现的所有缺陷的严重性值和,由表达式(2)量化得到,max(S)表示测试用例集中,单个用例发现的缺陷严重性值和的最大值。
式(2)中,dsj表示第i个测试用例发现的第j个缺陷的严重性的量化值,k标识第i个测试用例发现的缺陷个数。
1.2.2 缺陷优先级
根据处理缺陷的紧迫性来划分缺陷优先级,一般分为四个等级:紧急、高级、中级、低级。具体定义如下:
紧急:需要立即解决的缺陷,可以对应严重度为致命的缺陷,但不绝对,或者是客户需要马上实现的特殊要求。
高级:需要尽快解决的缺陷,可以对应严重度为严重的缺陷,但不绝对,或者是会影响测试进行的缺陷。
中级:需要较快解决的缺陷,可能是某个不影响到其他功能的单个功能失效缺陷。
低级:可以稍迟处理或者在往后版本中处理,甚至不进行处理也可以的缺陷。
为每种缺陷优先级定义一个1到4之间的值。dp代表不同缺陷优先级对应的量化值,其中紧急缺陷的dp值为4,高级别缺陷的dp值为3,中级别缺陷的dp值为2,低级别缺陷的dp值为1。使用公式(3)量化得到第i个测试用例发现不同优先级缺陷的能力值EPi。
式(3)中,Pi表示第i个测试用例发现的所有缺陷的优先级值和,由表达式(4)量化得到,max(P)表示测试用例集中,单个用例发现的缺陷优先级值和的最大值。
式(4)中,dpj表示第i个测试用例发现的第j个缺陷的优先级的量化值,k表示第i个测试用例发现的缺陷个数。
1.2.3 出错原因
每个缺陷都有其出错原因,一般可以划分为四类:需求缺陷、设计缺陷、代码缺陷、其他缺陷。具体定义如下:
需求缺陷:系統未满足用户的要求而导致的缺陷。
设计缺陷:系统设计与需求规格中的功能说明不相符而导致的缺陷。
代码缺陷:代码未按设计说明书中的要求设计,或代码本身的逻辑错误导致的缺陷。
其他缺陷:不在需求缺陷、设计缺陷、代码缺陷之列的其他缺陷。endprint
为每种出错原因定义一个1到10之间的值。dr代表不同出错原因对应的量化值,其中需求缺陷的dr值为8,设计缺陷的dr值为6,代码缺陷的dr值为4,其他缺陷的dr值为2。使用公式(5)量化得到第i个测试用例发现不同出错原因缺陷的能力ERi。
式(5)中,Ri表示第i个测试用例发现的所有缺陷的出错原因值和,由表达式(6)量化得到,max(R)表示测试用例集中,单个用例发现的缺陷出错原因值和的最大值。
式(6)中,drj表示第i个测试用例发现的第j个缺陷的出错原因的量化值,k表示第i个测试用例发现的缺陷个数。
至此,回归测试中第i个测试用例的优先级取值DDAi可通过式(7)来计算:
其中WS、WP、WR分别是ESi、EPi、ERi对应的权值,它们的取值可以根据实际情况来调整。
测试用例优先级排序方法就是在得到每个测试用例的优先级取值后,按从高到底的顺序重排测试用例集,利用排序后的测试用例集来执行新一轮的回归测试。
2 度量标准及实验分析
2.1 度量标准
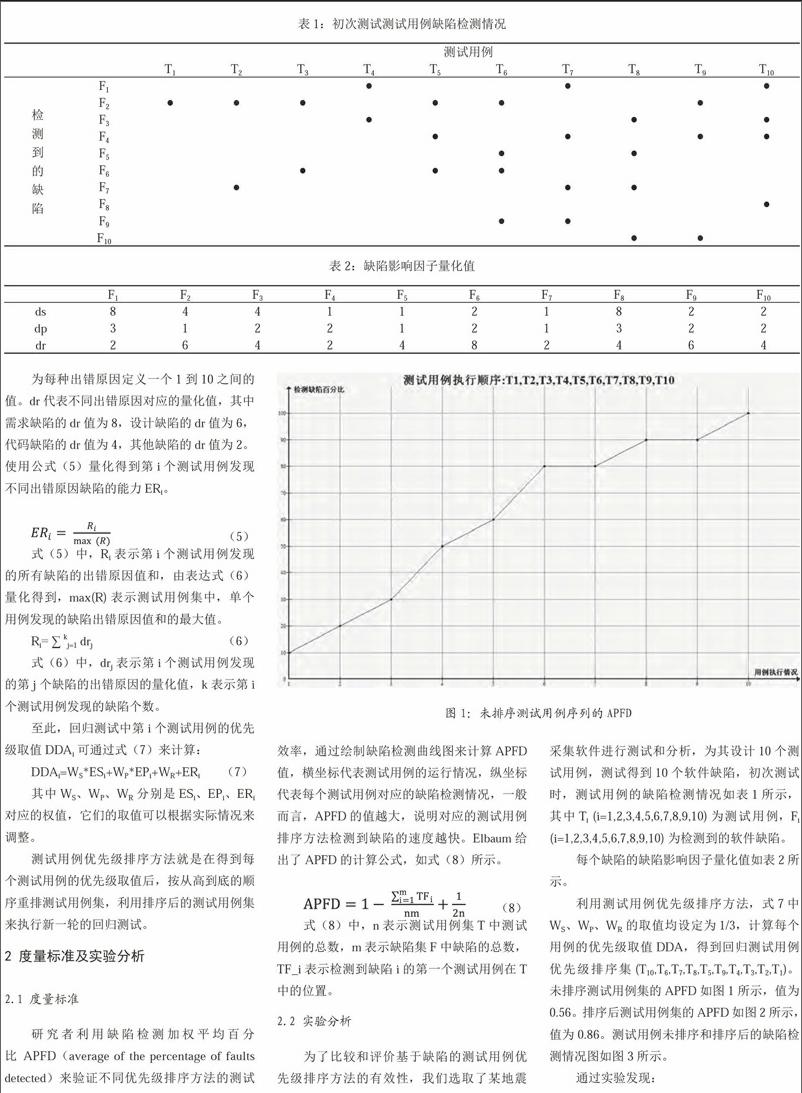
研究者利用缺陷检测加权平均百分比APFD(average of the percentage of faults detected)来验证不同优先级排序方法的测试效率,通过绘制缺陷检测曲线图来计算APFD值,横坐标代表测试用例的运行情况,纵坐标代表每个测试用例对应的缺陷检测情况,一般而言,APFD的值越大,说明对应的测试用例排序方法检测到缺陷的速度越快。Elbaum给出了APFD的计算公式,如式(8)所示。
式(8)中,n表示测试用例集T中测试用例的总数,m表示缺陷集F中缺陷的总数,TF_i表示检测到缺陷i的第一个测试用例在T中的位置。
2.2 实验分析
为了比较和评价基于缺陷的测试用例优先级排序方法的有效性,我们选取了某地震采集软件进行测试和分析,为其设计10个测试用例,测试得到10个软件缺陷,初次测试时,测试用例的缺陷检测情况如表1所示,其中Ti (i=1,2,3,4,5,6,7,8,9,10)为测试用例,Fi (i=1,2,3,4,5,6,7,8,9,10)为检测到的软件缺陷。
每个缺陷的缺陷影響因子量化值如表2所示。
利用测试用例优先级排序方法,式7中WS、WP、WR的取值均设定为1/3,计算每个用例的优先级取值DDA,得到回归测试用例优先级排序集(T10,T6,T7,T8,T5,T9,T4,T3,T2,T1)。未排序测试用例集的APFD如图1所示,值为0.56。排序后测试用例集的APFD如图2所示,值为0.86。测试用例未排序和排序后的缺陷检测情况图如图3所示。
通过实验发现:
(1)与不进行排序的测试用例集相比,采用基于缺陷的优先级排序算法得到的测试用例集,其执行效率得到了明显的改善,能够提高缺陷的检测效率。
(2)从未排序和已排序测试用例缺陷检测情况图可见,排序后的测试用例集在执行到40%的测试用例时就检测出了软件的全部缺陷,而未排序的测试用例集在执行完所有的测试用例时才检测出所有的缺陷。
3 结论
本文中的基于缺陷的测试用例优先级排序方法,将软件缺陷作为测试用例优先级排序的影响因素,通过计算缺陷严重性、缺陷优先级和出错原因等与软件缺陷相关的因子的影响值,最终得到测试用例优先级的取值,按照测试用例优先级取值的大小决定测试用例的执行顺序。通过这种优先级排序方法,能够尽快检测到软件缺陷,提高测试用例的检测效率;能够尽快达到测试的覆盖率标准,降低测试的时间成本和人力开销。
在实际测试中,由于测试用例排序本身也存在一定的成本开销,所以下一步的工作主要是在测试用例范围选择的基础上进行优先级排序,从而降低一部分的排序开销。
参考文献
[1]W E Wong,J R Horgan,S London and H Agrawal.A study of effective regression testing in practice[C].Proceedings of the 8th IEEE International Symposium on Software Reliability Engineering,1997:230-238.
[2]J M Kim,A Porter.A history-based test prioritization technique for regression testing in resource constrained environments[C]. Proceedings of the 24th International Conference on Software Engineering,2002:119-129.
[3]Srikanth H,Williams L,Osborne J. System test case prioritizationofnew and regression test cases[C].Noosa Heads,Australia,Proceedings ofthe 4th International Symposium on Empirical SoftwareEngineering,2005:64-73.
[4]Walcott K Sofia M L,Kapfhammer G M,et a1.Time-awaretestsuite prioritization [C].Portland,Maine,USA:Proceedings of theInternational Symposium on Software Testing and Analysis,2006:1-12.
[5]KeZhai,Bo Jiang,Chan W K,etal.Taking Advantage of service selection:A Study on the testing of location-based web services through test case prioritizationa[C]. Miami,Florida,USA:Proceedings of the IEEE International Conference on Web Services,2010:211-218.
[6]潘伟丰,李兵,马于涛等.基于复杂软件网络的回归测试用例优先级排序[J].电子学报,2012,40(12):2456-2465.
[7]Rothermel G,Untch R H,Chu C Y,et a1.PrioritizingTest Cases for Regression Testing[J].IEEE Transactions on Software Engineering,2001,27(10):929-948.
[8]屈波,聂长海,徐宝文.回归测试中测试用例优先级技术研究综述[J].计算机科学与探索,2009,3(03):225-233.
[9]Elbaum S,Rothermel G,Kanduri S,et a1.Selecting aCost-effective Test Case Prioritization Technique[J].Software Quality Journal,2004,12(03):185-210.
作者单位
中国石油化工股份有限公司石油物探技术研究院 江苏省南京市 211103endprint
