基于数据挖掘技术的山西省山洪灾害预警决策支持系统研究
2018-01-16李爱民付文博
李爱民,付文博
(1.山西水文水资源勘测局,山西 太原 030000;2.华中科技大学,湖北 武汉 430070)
数据挖掘(Date Mining,简称DM)是指利用统计学习方法、人工智能算法等分析海量数据中隐藏的数据关系,提炼出具有潜在价值的数据走向与结构模式,并利用这些规则重建预测模型,提供决策支持的过程[1]。
1995年在加拿大召开的第一届知识发现和数据挖掘国际学术会议上首次提出数据挖掘的概念[2],此后,数据挖掘作为信息获取和知识发现过程中的重要步骤,受到极大的关注与重视,随着互联网的普及和信息时代的来临,数据挖掘技术变得日趋成熟并逐渐流行,在各行各业应用广泛。胡文红[3]等人利用数据挖掘技术中的分段聚合法结合最大特征点优先匹配的动态时间弯曲距离算法对杭州市的历史水位与降雨信息数据进行了成功验证。范梦歌[4]等人则运用聚类分析对浙江118个具有20 a以上雨水情资料的流域进行了相似性研究。
1 分析方法
1.1 数据挖掘基本分析方法
数据挖掘的分析方法多种多样,各有不同。按照其功能可以分为分类与回归、聚类、关联规则与时序模式这四种[5]。
分类和回归是用来描述数据类别或预测数据趋势的两种重要的数据分析方法,分类(Classification)是将数据归入预先定义好的群组或类中,而回归则(Regression)是以历史数据来预测数据未来的趋势[6]。分类与回归中常用的算法有:小波神经网络法、模糊神经网络法、径向基函数法和反向传播法[7];聚类分析(Cluster analysis)是依据数据属性上的相似性,在未给定分组和类别的情况下进行信息自动聚集的一种方法,也称为无指导学习,常用的聚类分析的方法有模糊C-均值聚类、神经网络聚类、层次聚类、K-means聚类、高斯聚类等[8-10]。
关联分析(Association)的任务是发现事物间的相关程度,揭示在数据中间接表现出来的隐含关系,常用的两种分析方法是关联规则和序列模式分析[11],关联规则主要是发现事物间的相互依赖性,而序列模式则是挖掘数据间的前因后果关系[12]。Apriori算法、灰色关联法、HotSpot算法和FP-Tree算法是在关联分析中常用的算法[13];时序模式包含两种类型,一种是时间序列分析,另一种则是序列发现,时序模式描述的是基于时间或其他序列的经常发生的规律或趋势。时间序列常用的模型有加法模型和乘法模型[14]。时序算法常用的有指数平滑法、移动平均法和灰色预测法等[15]。
1.2 数据挖掘一般过程
数据挖掘的一般过程主要包括六个部分:①定义挖掘目标;②数据取样;③数据预处理;④数据探索;⑤模型建立;⑥模型评估。其具体的流程如图1所示。
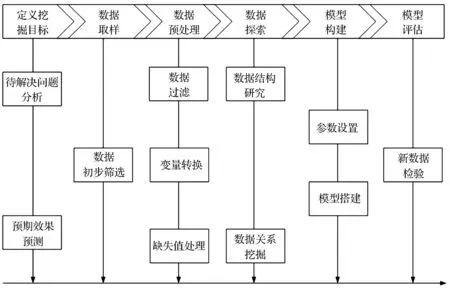
图1 数据挖掘过程示意图
定义挖掘目标主要是明确两个方面的问题:第一,弄清楚数据挖掘需要解决的问题;第二,数据挖掘完成后能够达到的效果。数据取样的标准是筛选出数据库中最新的且相关性好、可靠性高的数据。数据的预处理包括三个部分的工作:一是筛选,过滤掉某些不符合期望的观测值;二是变量转换,对数据进行转换操作以使数据和将要建立的模型拥有更好的拟合程度;三是缺失值处理,推导、填充空缺数据。数据探索是数据预处理的进阶工作,主要是探究数据间的结构关系与典型特征,为模型建立工作提供可靠的变量与算法选择依据,但数据探索与预处理也是一个双向的工作过程,在数据探索的过程中,当发现数据量太少或者数据质量不够好,往往会返回到数据取样阶段重新选择数据。在数据探索阶段常常要进行对比分析、统计量分析、周期性分析与相关分析等[16]。
模型的建立是数据挖掘的核心,是对采样数据轨迹的概括,它反映的是采样数据内部结构的一般特征,往往需要根据数据的特征、挖掘经验来选择合适的算法,进而选择合适的模型。模型评估一般会首先使用原来建模的数据样本进行检验,当获得较好的效果时,再寻找一些实际可靠的新数据进行再次验证,只有当两次检验的结果都很好时,模型才是准确的。
2 基于数据挖掘的山洪预警决策支持系统构建
山洪灾害预警决策支持系统作为“智慧水利”中的一部分,是山洪管理信息化支持的重要组成部分。山西省开发的多模型山洪灾害预警决策支持系统是在传统的数据库、知识库和模型库的决策支持系统基础上,采用数据仓库、数据挖掘以及专家系统的有关理论,构建省内统一的监测预警平台和数据共享平台,然后借助平台来获取实时雨水情、实时监测信息、山洪灾害分析评价成果、水利工程信息、预警(预报)模型、历史雨水情、文档资料、舆情信息等多种数据,进行数据的取样、预处理和探索,建立适合本地区的水文模型,最后集成多个模型来统一构建的。
2.1 总体构架与系统类库
山西省山洪预警决策支持系统采用的是软件架构模式搭建系统的体系结构,根据系统的功能需求,并兼顾今后的业务扩展,系统采用多层体系架构,包括用户层、应用层、支撑层、数据层和基础设施。系统体系结构如图2所示。
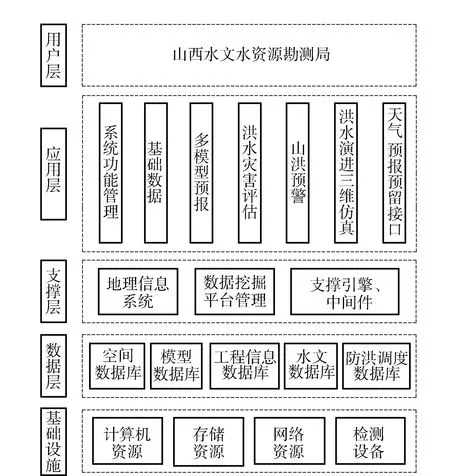
图2 系统体系结构图
基础设施层是整个系统的硬件基础,主要包括计算机资源、存储服务器、网络设备以及底层的监测采集设备等;数据层则是整个系统构架最重要的部分,数据库的准确度直接影响到系统预测结果的可靠性。数据层集中组织和管理暴雨山洪灾害风险预警所需的各类数据,包括空间数据、模型数据、水文数据、历史洪灾统计数据、洪水风险图数据等。应用支撑平台层包括地理信息系统平台、数据挖掘管理平台和支撑业务系统的各类引擎和中间件。应用层是用户使用应用系统的接口,包括整个系统的使用方法。
山洪灾害预警预报系统是较复杂的大型应用软件,系统必须配备先进的技术解决方案才能适应山西省水利信息化的发展。面向对象技术是当前软件开发方法的主流,其核心思想是高度模仿人类思维,充分保证计算机程序领域的概念及结构与现实问题领域保持一致,且基于面向对象技术的系统不仅能显著提高系统的效率性与重用性,而且易于维护与扩展。山西省山洪灾害预警决策支持系统正是采用面向对象技术和设计模式,通过对系统中各种业务需求进行抽象设计,形成如下几种满足业务需要的类,如图3所示。
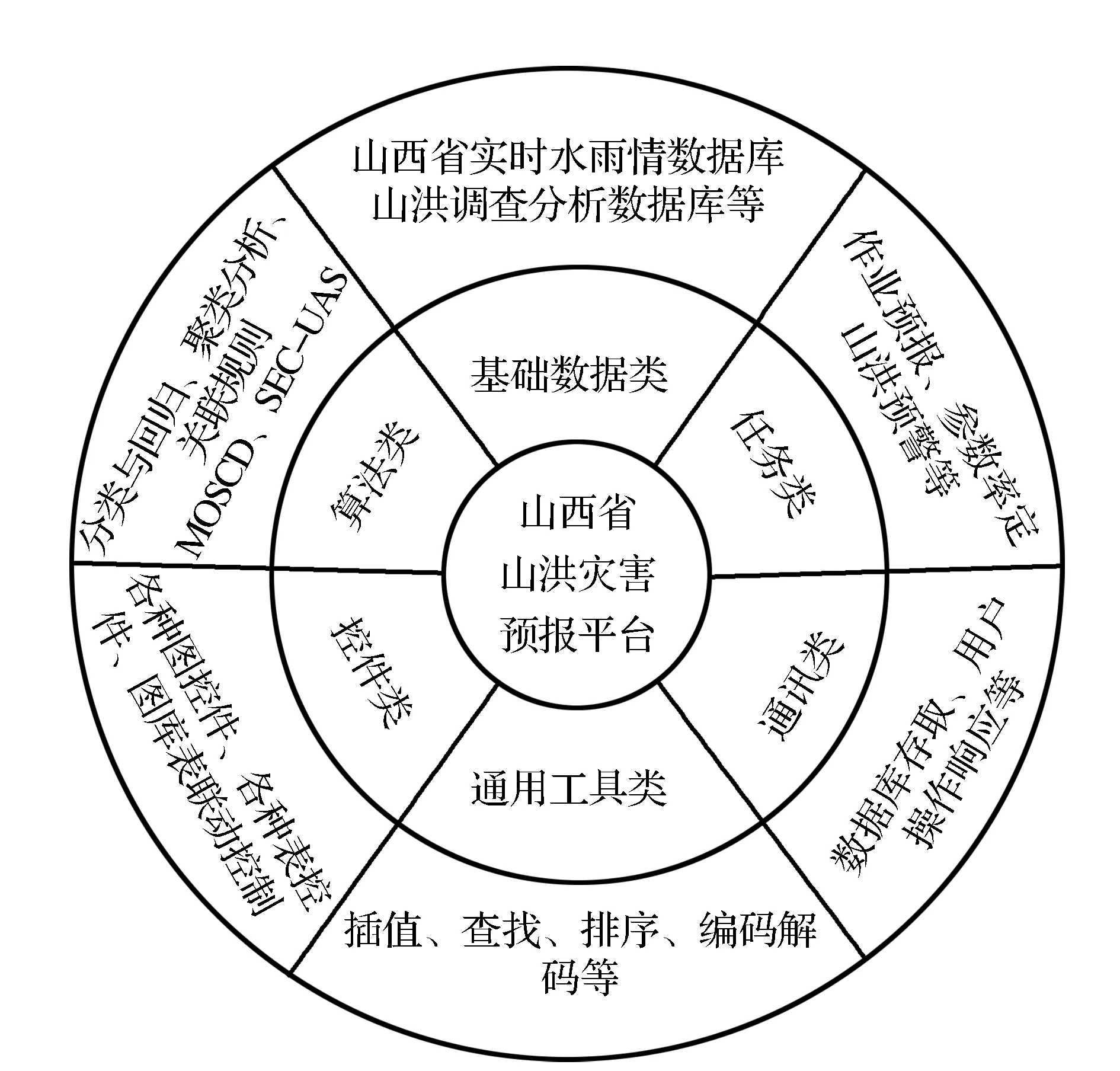
图3 系统类设计示意图
2.2 系统关键技术
山西省山洪预警决策支持系统主要由三部分组成:数据共享仓库、网络分布式模型的智能化开放式模型库、基于WPF与GIS的动态生成交互平台。
数据共享仓库实质上是经过一系列数据清洗、融合、同化、变换、装载处理后的高度统一的数据集合体。山西省山洪灾害数据共享仓库体系结构分为源数据、数据处理、数据仓库3个层次:
(1)源数据层主要为数据仓库提供源数据,山洪灾害的源数据包括水文地质、地形地质、社会经济等方面的基础资料和评价分析成果等。
(2)数据处理层主要是将数据仓库所需的相关数据,统一清洗、融合、同化、变换、装载,再将这些数据返还存储至数据共享仓库中。
(3)数据共享仓库主要包含两大类数据,一是实时共享数据仓库,二是历史数据仓库,主要采取多维链表来储存数据。
网络分布式模型的智能化开放式模型库主要是利用数据共享仓库及数据访问和分析层所提供的信息、模型、方法与规则,对山洪灾害进行预测预警管理。该模型库包含专家知识库、模型库两类。其中专家知识库主要储存洪水预警预报的常规理论和区域水文专家的经验,为后期系统预警决策提供足够的理论支撑;模型库则包括新安江模型、TOPMODEL模型、双超模型等等多种模型。基于WPF与GIS的动态生成交互平台则是结合二三维GIS与虚拟现实技术,完善服务的发现、匹配、计划、组合机制,研发以GIS服务器和算法模型服务群为核心的Web Services群,建立基于持续集成方法和面向服务体系的分布式松耦合研究基础平台,实现空间数据和算法结果数据的动态交互,提高各数据库系统的数据内聚性,增强异构系统之间的松耦合性,保障系统安全性,独立性与包容性。
2.3 系统功能
山西省山洪灾害预警决策支持系统功能描述如下:
(1)基础信息查询。通过搜索可以查看到山西省100多个县区的基本水文信息和不同典型流域的雨量站、水文站分布情况及基本流域信息。
(2)洪水预报功能。洪水作业预报,运用多模型对流域产汇流的模拟得出不同断面在5种不同模型的预测下的径流。起始时间、预测时间以及前沿时间可由用户选择,默认为已有资料的起始年和结束年。
(3)动态预警功能。本功能的实现主要是通过读取8个不同流域的实时降雨数据库,根据历史资料计算出不同流域的1 h、2 h的临界雨量判别函数,以5种模型计算出实时降雨相对应的实时土壤含水量对应的1 h、2 h雨量依次进行判别是否预警。
(4)三维仿真演示。此功能借鉴GIS三维仿真的功能,包含土地利用、遥感影像、土壤质地等图层,以三维的视角生动的展示了流域的基本地理信息,动态的展示了流域洪水的流动淹没情况,显示了更加准确的洪水信息供用户决策。
3 结 论
基于数据挖掘技术的山洪灾害预警决策支持系统的开发,势必会为山西省内各乡镇级以及村级的山洪灾害防治工作提供全面、详细的信息支撑,为山西省水情预报和暴雨山洪灾害防治,提供可视化的支撑平台。其次,为数据挖掘技术系统的研制与开发开辟了一种高效实用的路径。随着数据挖掘在水利行业上的应用扩展,数据的收集与系统性分类整理将会越来越规范,获取的信息质量也会越来越高,相信未来山洪灾害预警决策支持系统会更加成熟,预警结果会更加准确,各部分功能也会更加全面。
[1] 潘振宇. 数据挖掘技术与Weka工具在河道洪水预报中的应用[D].成都:电子科技大学,2012.
[2] 张小娟, 蒋云钟, 邢志,等. 数据挖掘方法在北京市用水规律分析中的应用[J]. 中国水利, 2007(16):21-23.
[3] 胡文红, 孙欣欣. 基于时间序列的数据挖掘技术在城市内涝灾害中的应用研究[J]. 科技通报, 2016, 32(6):229-231.
[4] 范梦歌, 刘九夫. 基于聚类分析的水文相似流域研究[J]. 水利水运工程学报, 2015(4):106-111.
[5] 郑胤乐. 采用Web图表展现的决策支持系统在服务外包平台中的研究与应用[D]. 南昌:南昌大学, 2010.
[6] 罗海蛟, 刘显. 数据挖掘中分类算法的研究及其应用[J]. 计算机技术与发展, 2003, 13(Z2):48-50.
[7] 陈敏. 基于BP神经网络的混沌时间序列预测模型研究[D]. 长沙:中南大学, 2007.
[8] 宋广军, 宋婉约. 数据挖掘技术在行业应用中的分析与比较[J]. 科技风, 2012(19):97-98.
[9] 王广. 基于改进差分进化的K均值聚类算法在入侵检测中的研究[D]. 北京:北京化工大学, 2016.
[10] 陈敏. 基于BP神经网络的混沌时间序列预测模型研究[D]. 长沙:中南大学, 2007.
[11] 王呈慧. 数据挖掘的认识及应用[J]. 山西青年职业学院学报, 2007, 20(4):106-107.
[12] 陈卓, 杨炳儒, 宋威,等. 序列模式挖掘综述[J]. 计算机应用研究, 2008, 25(7):1960-1963.
[13] 陈志飞, 冯钧. 一种基于Apriori算法的优化挖掘算法[J]. 计算机与现代化, 2016(9):1-5.
[14] 薛潇. 基于数据挖掘的入侵检测研究与应用[D]. 无锡:江南大学, 2009.
[15] 彭丽. 数据挖掘中几种划分聚类算法的比较及改进[D]. 大连:大连理工大学, 2008.
[16] 张忠杰. 基于信息系统用户服务感知评价的数据挖掘[D]. 青岛:青岛理工大学, 2014.
