基于内存的数据存储技术研究*
2018-01-09许春聪文海雄黄忠主
许春聪,刘 钊,文海雄,黄忠主,郑 强
(解放军75837部队,广东 广州 510630)
基于内存的数据存储技术研究*
许春聪,刘 钊,文海雄,黄忠主,郑 强
(解放军75837部队,广东 广州 510630)
基于内存的数据存储已经成为缓解磁盘I/O性能瓶颈的重要方式之一。简要介绍了缓解系统I/O性能瓶颈的4种方式,阐述了分布式内存文件系统的优势,并提出了未来的研究重点。
内存;数据存储;缓存;文件系统
鉴于机械运动特性,磁盘性能的提高在很大程度上受到磁盘I/O性能的限制。虽然磁盘的容量逐年增大,但访问延迟和带宽的性能改善却收效甚微。随着多核处理器技术和新型网络的迅猛发展,磁盘I/O与处理器和网络的性能差距越来越大。为了弥补磁盘I/O性能的不足,大多数的数据中心采用RAID、并行文件系统和I/O库等技术来提高系统的数据吞吐量。对于大块数据的连续访问,这一方法能够提供较高的访问带宽。但是,对于随机I/O的访问,由于磁盘的寻道时间、准备时间相对比较长,系统的访问延迟和数据吞吐量的性能却改善很小。
从计算机技术发展的现状和趋势看,使用DRAM构建大规模存储系统的条件已经成熟。一方面,高密度的内存封装技术使单片DRAM的容量快速增加,使用DRAM已经可以构建数十太字节的海量数据存储;另一方面,DRAM的价格快速下降,构建大规模内存存储系统的成本可以被接受。
以内存为数据的基本存储介质是提高系统性能的有效方法之一。当前,以内存方式来缓解系统I/O性能瓶颈的主要有主存数据库、基于内存的key-value数据存储、磁盘缓存和内存文件系统4种方式。
1 主存数据库
主存数据库将整个关系型数据库永久地放进内存中,重新设计查询处理、并发控制与恢复的算法和数据结构,以更有效地使用CPU周期和内存,其数据访问结构、操作算法和恢复机制等均有一些根本性的变化,性能有较大的改善。DeWitt D J于1984年第一次提出了主存数据库的概念,指出了平衡二叉树访问方法、Hash操作算法更适用于主存数据库,并提出了主存数据库的恢复机制[1]。之后研究者们又陆续提出了使用检查点技术实现主存数据库的恢复机制[2],按区双向锁定模式解决主存数据库中的并发控制问题[3],以堆文件作为主存数据库的数据存储结构等技术[4],使主存数据库的理论和技术更加完善。目前,常用的主存数据库有eXtremeDB、Oracle TimesTen、SolidDB和Altibase等。相对于I/O库技术,主存数据库基于内存进行体系结构设计,从根本上抛弃了磁盘数据管理的传统方式,并且在数据缓存、快速算法、并行操作方面也进行了相应的改进,以提高数据处理速度。但它有3个重要的不足:①不适用于非结构化数据的存储;②当数据库的记录数超过一定数量时,性能会急剧下降;③动态扩展性不足。
2 基于内存的key-value数据存储
基于内存的key-value的数据存储结构简单,并具有高可扩展性和高效率访问的特性。基于内存的key-value的数据存储主要应用于对事务一致性、写实时性、读实时性要求不高,并且不会执行多表关联查询的场合。它一般用来作为大型网站动态数据的缓存,以提升高并发访问的性能。典型的基于内存key-value的数据存储系统有Memcached[5]和Redis。分布式的内存对象缓存系统Memcached是在内存里维护一张巨大的key-value数据表,用来存储经常被访问的数组和文件,它主要支持数据库记录,单个value不能超过1 MB。它一般用于减少数据库负载,加速动态Web应用,提升访问速度。Redis将整个数据库加载在内存中进行操作,定期将数据备份到硬盘上。它支持List链表和Set集合的数据结构,单个value不能超过1 GB。
但是,key-value的数据存储不能直接支持传统应用的计算和数据存储,这主要体现在以下3个方面:①传统应用基于POSIX语义的数据访问接口,key-value数据存储系统一般采用put和get这2种典型的接口,在接口语义和接口实现上都不能与传统应用相兼容;②key-value的数据存储系统没有充分考虑到数据一致性对传统应用数据访问性能的影响;③key-value存储结构不支持存储对象的区间查询,这限制了数据对象的操作。
3 磁盘缓存
磁盘缓存是解决系统磁盘I/O瓶颈的传统方法,其基本思想是充分利用局部性原理,将最频繁访问的文件数据存储在内存中,尽量减少文件系统访问磁盘的次数。采用缓存机制的目的是提高系统访问内存数据的命中率,它一般辅以替换算法[6]和I/O聚合[7]2项技术。采用高效的替换算法,系统可以保证缓存空间中存储的都是最频繁或最近被访问的文件数据;采用I/O聚合技术,系统可以尽量减少读写磁盘的次数。然而,磁盘缓存具有以下几方面的不足:①需要频繁地在内存与磁盘间移动数据,操作复杂。这是因为磁盘才是文件的最终存储介质,将磁盘文件数据读入内存,需要访问元数据和数据,其管理的开销比较大。②需要维护内存与磁盘间的数据一致性。采用缓存机制使得内存中的数据仅是一个备份,所以,必须采用可靠的机制保证内存与磁盘间的数据一致性。考虑性能和机器故障2个因素,数据一致性的维护就比较复杂。③无法解决网络传输速度慢的问题。在传统的基于磁盘的存储系统中,磁盘I/O是整个系统的性能瓶颈。假设缓存容量增大至磁盘的容量,访问操作的命中率可达100%.由于网络传输延迟比DRAM的访问延迟大得多,网络数据传输将成为制约系统性能的重要因素。因此,不能简单地采用增大内存的方法来解决磁盘I/O性能瓶颈。④无法高效地利用大量可用内存。当磁盘文件缓存的容量增大到一定程度后,由缓存增加所带来的边际效益将会减少[8]。当内存容量达到一定容量后,增大内存容量不仅无法明显提高系统的性能,反而会使系统的能耗和一致性维护的开销明显增大。
4 内存文件系统
内存文件系统,是指直接在内存中建立文件系统,将内存作为元数据和数据存储的基本介质。内存文件系统与磁盘缓存的最大区别是,内存是基本的存储介质。内存的带宽大,访问延迟小,使用内存来替代磁盘能够更加高效地缓解磁盘I/O瓶颈。
4.1 内存文件系统的优势
内存文件系统主要有以下2个优势:①内存文件系统的文件组织方式可以采用更加紧凑、更加高效的数据组织结构。鉴于DRAM在随机访问方面的优势,内存中的数据存储完全不需要采用固定数据块大小的组织方式。更加紧凑的组织方式能够更加高效地利用内存的空间。②与主存数据库和key-value数据存储相比,内存文件系统的内存存储空间具有文件语义,系统可以使用文件访问接口管理内存存储空间。这一特性使内存文件系统能够满足传统应用的需求。
4.2 分布式内存文件系统的优势
分布式内存文件系统将内存作为基本的存储介质,以磁盘作为数据备份设备,其逻辑视图如图1所示。
与传统分布式文件系统相同,分布式内存文件系统具有高可扩展性、高容错性、高可用性等特点。此外,分布式内存文件系统能够充分发挥DRAM的性能优势,具有高数据吞吐量和低访问延迟的优势。相对于主存数据库和基于内存的key-value数据存储,分布式内存文件系统具有兼容传统应用的特性。
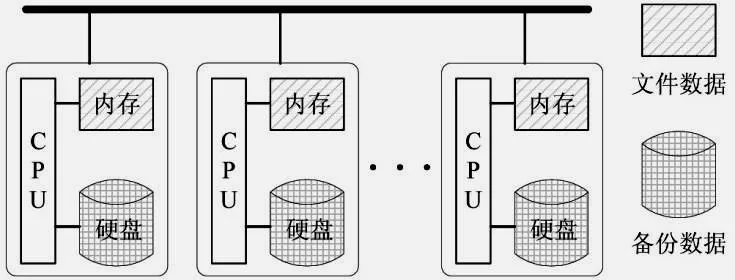
图1 分布式内存文件系统的逻辑视图
5 结论
基于内存存储数据是缓解磁盘I/O性能瓶颈的可行方式之一,由于非易失性内存的特性,基于内存构建数据存储系统还需要深入研究系统的可靠性技术。要想增强系统的可靠性,可以从供电系统、备份策略、数据冗余等方面入手研究,以确保系统不掉电、数据不丢失。
[1]DeWitt D J,Katz R H,Olken F,et al.Implementation Techniques for Main Memory Database Systems[C]//Proceedings of the ACM SIGMOD international conference on Management of Data.Boston:ACM,1984:1-8.
[2]HagmannRB.A crashrecoveryschemefora memory-resident database system[J].IEEE Trans.Comput.,1986,35(9):839-843.
[3]Lehman T J,Carey M J.Concurrency Control in Memory-Resident Database Systems[R].University of Wisconsin-Madison Computer Sciences Department Technical Report,1987.
[4]Gray J,Putzolu F.The 5 minute rule for trading memory for disc accesses and the 10 byte rule for trading memory for CPU time[J].Acm Sigmod Record,1987,16(3):395-398.
[5]Masahiro Nagano.Memcached全面剖析[M].&charlee,译.[出版地不详]:[出版社不详],2008.
[6]黄敏,蔡志刚.缓存替换算法研究综述[J].计算机科学,2010,33(12):191-193.
[7]Dongarra J,Kennedy K,White A,et al.Sourcebook of Parallel Computing[M].San Francisco:Morgan Kaufmann,2005.
[8]Roselli D,Lorch J R,Anderson T E.A Comparison of File System Workloads[C]//Proceedings of 2000 USENIX Annual Technical Conference.Monterey,San Diego,California,USA,2000:18-23.
TP301
A
10.15913/j.cnki.kjycx.2018.02.019
2095-6835(2018)02-0019-03
本文受军队某重大科研项目支持
许春聪(1980—),男,主要从事云计算、分布式文件系统方面的研究。刘钊(1983—),男,主要从事分布式系统、网络安全方面的研究。文海雄(1976—),男,主要从事数据管理、信息服务方面的研究。黄忠主(1987—),男,主要从事数据挖掘、自动化系统方面的研究。郑强(1986—),男,主要从事并行分布式处理、模式识别方面的研究。
白洁〕
