基于文本的抑郁情感倾向识别模型①
2018-01-08施志伟高俊波胡雯雯刘志远
施志伟,高俊波,胡雯雯,刘志远
(上海海事大学,上海 201306)
基于文本的抑郁情感倾向识别模型①
施志伟,高俊波,胡雯雯,刘志远
(上海海事大学,上海 201306)
针对学生在新浪微博文本中所表现出来的抑郁情感倾向,提出了一种识别抑郁情感倾向的模型. 通过在本校广泛发动学生在线填写抑郁自评量表,获得学生的量表得分. 采集学生的微博文本,并请本校心理学老师对微博进行人工标注. 在预处理阶段,利用抑郁情感词典重新组合在分词阶段被拆分的抑郁情感词,以提高识别正确率. 然后基于支持向量机构建一个情感分类器对微博数据进行训练,经过不断的学习反馈,获得较好的分类效果; 最后,定义了抑郁指数来衡量个体在一段时间内的抑郁倾向程度. 实验结果表明,抑郁指数衡量的抑郁程度大致与量表结果吻合,该方法识别准确率达到82.35%.
抑郁倾向识别; 抑郁自评量表; 抑郁情感词典; 支持向量机; 抑郁指数; 新浪微博
微博作为一种开放化的互联网社交服务,由于文体格式自由、使用方便,越来越多的用户通过微博发布自己的所见所闻,所感所思. 在海量微博文本中,有很多蕴藏着个人情感,可以利用这些文本进行情感分析研究[1]. 当前,情感分析研究主要是针对某个具体事物的评论[2],如影评,产品评论等,而针对文本中所蕴藏的抑郁情感的研究还比较少.
在世界范围内,抑郁症是人们面临的最为普遍的心理疾病之一. 随着微博等社交网络平台的发展壮大,许多研究者借助用户网络特征行为来判别其心理抑郁情况[3]. 文献[4]基于产妇在产后社交网路中对话频度、语言风格等进行分析,建立产妇抑郁统计模型. Wang[5]等将抑郁患者视为一个节点,并以此为中心构建一个图网络,根据网络中相邻节点的属性及连接权重,给出模型来计算抑郁状况. 文献[6]采用脑成像方法研究静息态下不同性别的抑郁症患者的脑功能差异. 文献[7]从用户发微博的时间、粉丝数及关注数等方面来分析用户的抑郁情况.
本文将对学生微博文本中所蕴含的抑郁情感倾向展开研究,并定义抑郁指数来衡量个体在一段时间内的抑郁倾向程度,为高校的心理工作者及医院医护人员识别抑郁患者提供辅助手段.
1 相关工作
1.1 抑郁症
抑郁症是一种普遍的心理疾病,成因非常复杂,研究者对抑郁症的发病机理提出了许多理论假说[8]. 心理及医学研究者还提出了各种抑郁症诊断量表,为相关实践提供了重要的实验依据. Zung[9]提出的抑郁自评量表具有高度可操作性及适应性,很多医疗机构也使用此量表来度量患者的抑郁程度. 它根据得分将抑郁情绪分为四类,[20,41]表示正常,[42,49]表示轻度抑郁,[50,57]表示中度抑郁,[58,80]表示重度抑郁. 本文采用SDS抑郁自评量表做对比实验.
1.2 构建抑郁情感词典
目前,开源情感词典众多[10],但还没有一部完整的抑郁情感词典. 本文在已有情感词典基础上,构建一个基础的抑郁情感词典,共统计常见抑郁词1041个. 考虑到微博用语的特征及时代性,采集抑郁情感网络流行词语54个; 从新浪微博抽取26个常用抑郁情感符号加入抑郁情感词典. 抑郁情感词典中部分词如表1所示.

表1 抑郁情感词典
2 抑郁情感倾向识别模型
本文建立的抑郁情感倾向识别模型主要包括以下几个部分,如图1所示.
采集数据之前,在上海海事大学校内广泛发动学生在线(网页或者微信)填写抑郁自评量表(https://sojump.com/jq/9743549.aspx),获得每个学生的抑郁倾向得分. 在学生知情并授权的情况下采集微博语料,并请本校的心理咨询师对学生的微博文本进行逐条标注.用预处理后的训练样本训练分类器,得到可靠的抑郁情感识别器,并对抑郁指数和量表得分进行皮尔逊相关性分析,最后给出抑郁指数和抑郁程度之间的关系式.
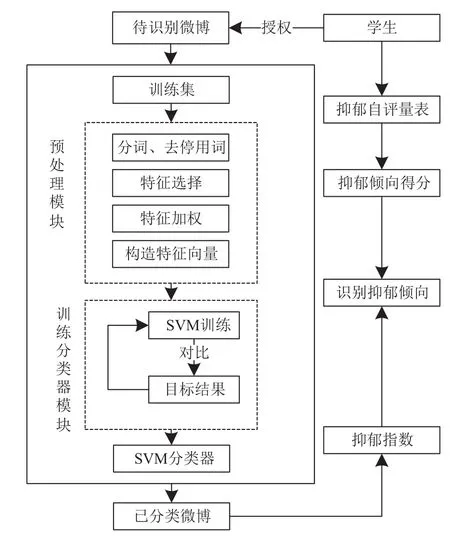
图1 学生抑郁情感倾向识别模型
2.1 预处理
2.1.1 去停用词
对微博文本构造特征向量前,先进行分词和去停用词处理,本文使用中科院分词系统ICTCLAS. 在分词后,许多抑郁情感词被拆分,如“草泥马”被分割成“草/泥/马”,为了更好保留抑郁情感词,参照已经构建的抑郁情感词典,将这类词恢复原状. 去停用词是利用构建好的停用词表过滤掉无用的字词. 鉴于微博文本特点及多次去停用词的结果,本文在哈工大去停用词表的基础上,加入了一些特殊的人名、地名及无关的字词,如“上海”、“TFBOY”等. 经过反复试验,此方法有更好的实验效果.
2.1.2 特征选择
特征空间的高维性和稀疏性是文本分类中面临的最大问题. 将特征项全部保留,这将导致维度太大,降低分类效率和准确率,因此必须进行特征降维. 本文采用CHI进行特征选择[11],其主要思想是假设特征t和类别ci之间符合 CHI分布,CHI统计值越大,特征与类别之间的相关性越强,对类别的贡献度越大. 计算公式如式(1)所示.
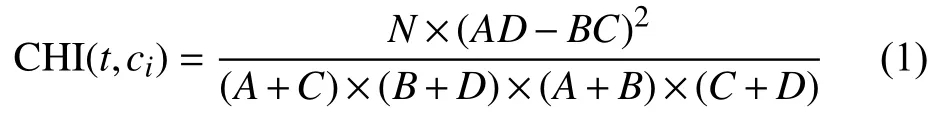
最后,取特征t的最大值作为其全局CHI统计量,如式(2).

2.1.3 特征加权


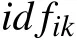
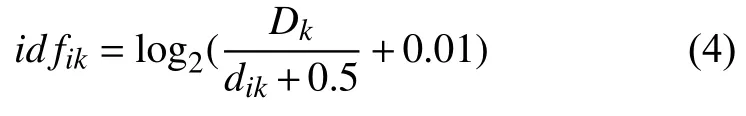
则特征词ti在文档dk中的权重为:
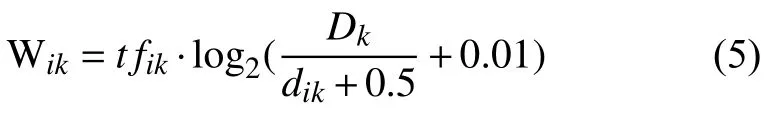
2.1.4 构造特征向量
本文采用向量空间模型对微博文本进行刻画. 在向量空间模型中,文本被视为由特征权重构成的特征矩阵,关于文本的所有处理都在向量空间上进行. 根据特征选择和特征加权的结果,微博文本将被表示成如下的向量空间模型.

每一行表示一条微博,wij表示第i条微博的第j个特征词的权重;n表示文本集中微博总数,m表示每条微博的特征维数.
微博长短不一,按向量空间模型构造的矩阵是一个有大量特征值为零的稀疏矩阵. 为了避免浪费存储空间,提高运算效率,本文采用 (L T:W)形式来表示每条微博,其中L表示每条微博的标签,T表示特征项,W为特征项的权重. 如:“我真的爱你,闭上眼,以为我能忘记,但流下的眼泪,却没有骗到自己”,这句话特征选择后得到 5个特征词,分别为“骗”、“爱”、“眼泪”、“闭上眼”、“流下”. 故而这句话可以表示成“1.0 28:0.4528 39:0.2295 49:0.3215 862:0.5811 1832:0.54878”,其中 1.0 表示标签,28 是特征词“骗”的索引号,0.4528是特征词的权重.
2.2 SVM分类器的构建
支持向量机是一种实用高效的机器学习方法[13,14],和其他方法相比,它在处理非线性及高维分类问题中表现出其特有的优势. 处理非线性的文本分类问题,首先构造非线性映射函数将数据x变换到高维空间F,然后在高维空间F使用线性分类器分类. 公式(6)实现把数据从低维空间转换到高维空间F.

在空间变换后,采用高斯核函数实现非线性问题线性化. 高斯核函数如下[15]:
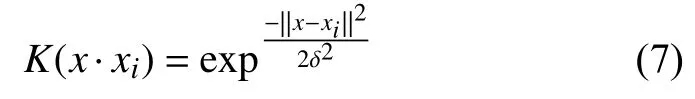


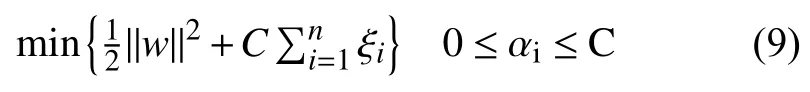
其中C为参数,用于控制上述目标函数中两项之间的权重. 此外,将约束条件加入到目标函数中,构造拉格朗日函数,解得 0≤ αi≤C,αi表示约束条件所对应的拉格朗日乘子. 相应的分类函数如公式(10).
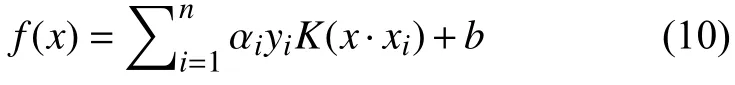
其中,x表示待分类微博文本,xi表示对文本的支持向量,yi为xi对应的分类,当f(x)≥0,则x有抑郁倾向,f(x)<0则正常.
2.3 抑郁指数
对微博文本分类后,只能看出单条微博的抑郁情况,而不能刻画个体在一段时间内整体抑郁倾向状况.通过观察、比较大量学生的抑郁微博数,在上述抑郁情感识别模型基础上,本文提出抑郁指数来衡量个体在一段时间内的抑郁倾向程度,计算公式如(11). 其中Nd表示分类结果中抑郁微博条数,Nt表示总的微博数,DI的值越大表示抑郁情感倾向越严重.

鉴于本文仅从微博文本这一特征来分析个体抑郁倾向情况,不涉及微博关注数、粉丝数等其他结构特征,故而只取抑郁微博数与总微博数的比值作为抑郁指数.
3 实验及结果分析
3.1 语料收集与标注
从2016年9月22到2016年12月23号,共381名学生在线作答,剔除无效量表,实际有效 271 人. 从得分结果来看,有抑郁倾向 80 人,正常 191 人. 按照3:1的比例,分别从两类学生中随机抽取训练用例和测试用例,训练集和测试集中人数如表2所示. 按照每人采集500条,不足采集全部的原则,共获得7321条微博文本. 对训练集中微博语料进行人工标注后,共获得抑郁微博1512条,正常微博3786条; 测试集共2023条微博.
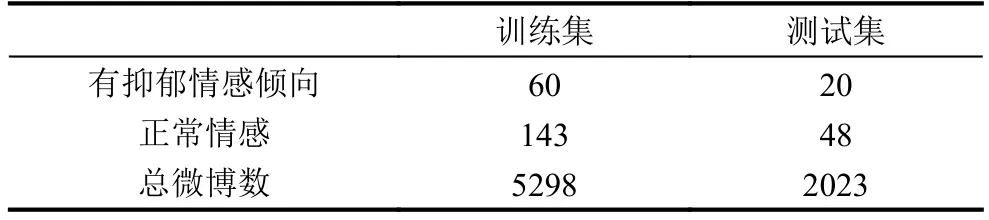
表2 训练集和测试集人数及微博数
3.2 评价标准
本文采用分类正确率来评价分类效果,公式如下:

其中,a表示被正确判断为抑郁的微博数,b表示被误判为抑郁的微博数,c表示被正确判断为正常的微博数,d表示被误判为正常的微博数.
3.3 结果分析
实验1. 对测试集中2023条微博,分别在采用抑郁情感词典和不采用抑郁情感词典的情况下进行实验,结果如表3所示.
从表3可以看出,采用人工构建的抑郁情感词典后,对单条微博的识别正确率显著提高.
实验2. 利用分类器对测试集中每个学生的微博文本进行分类,得到68个测试用例的抑郁指数和正确率,部分数据如表4所示.

表3 采用抑郁情感词典的实验准确率
对实验结果中抑郁指数DI和量表得分Score进行分析,发现它们之间有一定的联系,画出两者之间的散点图,如图2,其中Index值为1表示有抑郁倾向,Index值为-1表示正常. 对两者之间的相关性进行皮尔逊检测,发现DI和Score在0.01水平(双侧)上显著相关,且 r=0.544,说明两者有较强的相关性. 根据相关性检测结果以及量表得分与抑郁程度的关系,给出抑郁指数与抑郁程度之间的关系式为公式(13).
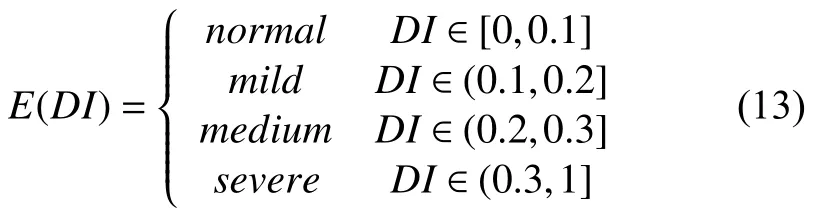

表4 不同学生抑郁指数及抑郁量表得分情况
抑郁指数在[0,0.1]时,情绪状态正常; 抑郁指数在(0.1,0.2]时,开始有抑郁倾向但处于轻度状态; 抑郁指数在 (0.2,0.3]时,处于中度抑郁状态; 当抑郁指数在 (0.3,1]时,抑郁情况已经比较严重了,必须采取有效的治疗手段. 其中,当 DI在[0.08,0.15]时,正常与抑郁的交叉现象很明显,这与部分学生量表得分在42分左右有明显的关系.
表5给出了68个测试用例的识别结果,正常情绪的识别准确率比抑郁倾向的识别准确率低,可能是由于学生在正常状态下所发的微博中包含了相关抑郁词.
实验3. 从 2016年 3月到2017年 2月,采集3位学生在此期间所有微博数据,以月为单位分别求出抑郁指数并画出走势图,结果如图3.
从图3可以看出,抑郁倾向呈现出波动状态,但在一定时间范围内,有抑郁倾向的学生的抑郁指数普遍比正常人要高,而且情绪波动更剧烈.
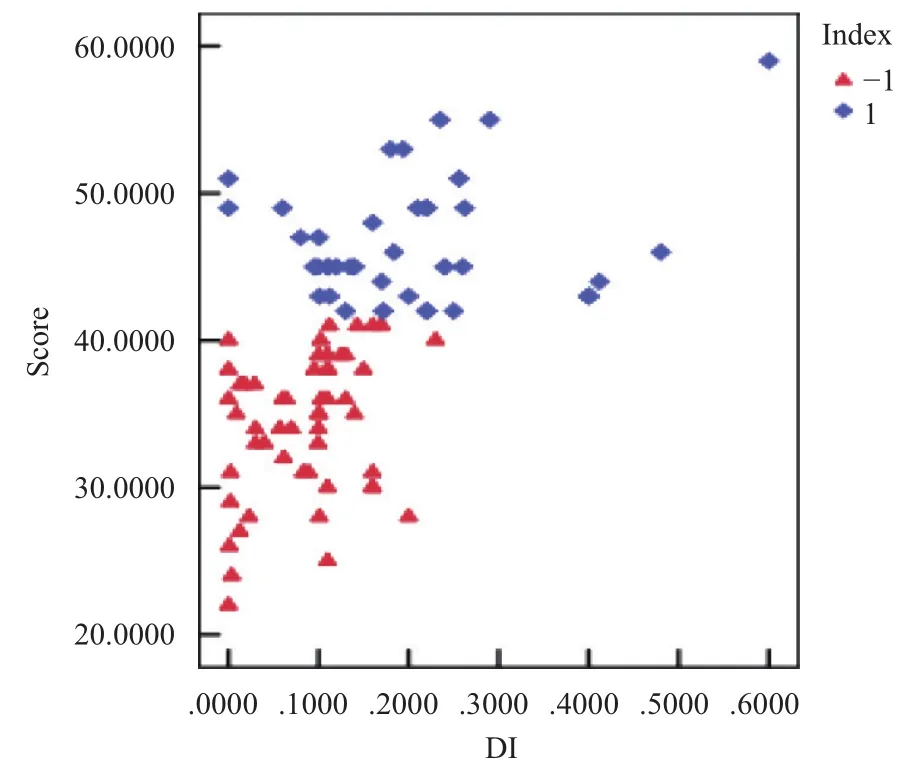
图2 DI与 Score 的关系散点图

表5 学生测试用例的分类结果
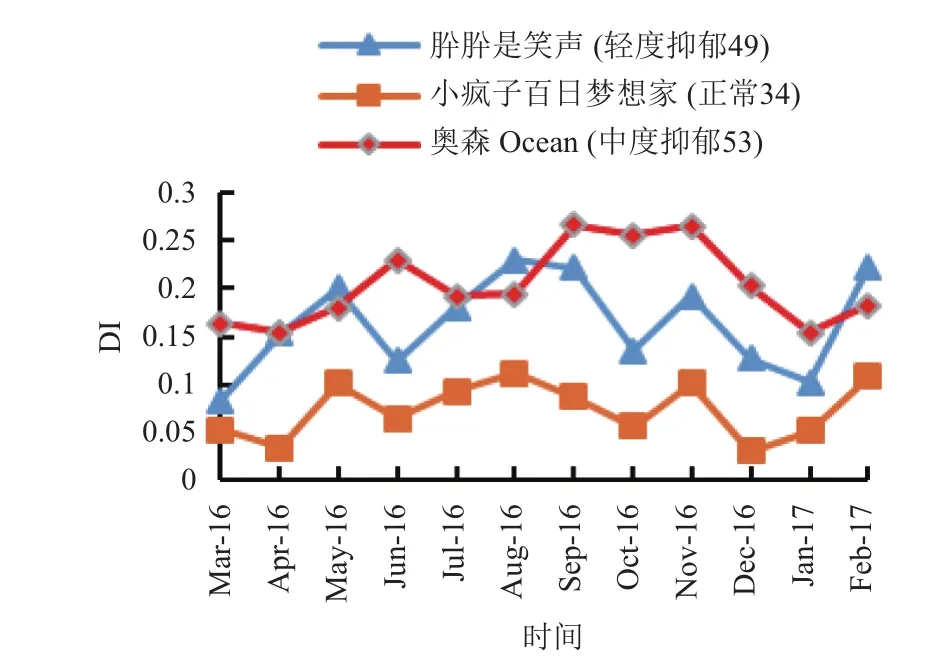
图3 不同学生的抑郁倾向走势图
4 结语
抑郁情感倾向分析试图从微博文本中识别出个体在某段时间内的抑郁倾向状况. 在学生知情且授权的情况下,获取学生的微博文本; 在学校心理咨询师的帮助下对微博文本进行情感极性标注,并使用机器学习算法训练分类器,实现面向微博文本的学生抑郁情感倾向识别. 实验结果表明,该方法对学生的抑郁情感倾向有较好的识别效果.
鉴于微博文本语言极具特色,不少学生的微博都是通网络图片或表情来传达情感,这对深入研究学生的抑郁情感倾向提出了非常高的要求. 此外,仅仅通过微博文本来分析抑郁倾向情况,而没考虑微博周边其他一些因素,如关注数、粉丝数、微博发表时间等,这些都是需要继续研究改进的地方.
1刘楠. 面向微博短文本的情感分析研究[博士学位论文]. 武汉: 武汉大学,2013: 24–91.
2Pang B,Lee L,Vaithyanathan S. Thumbs up? Sentiment classification using machine learning techniques. Proc. of the ACL-02 Conference on Empirical Methods in Natural Language Processing-Volume 10. Stroudsburg,PA,USA.2002. 79–86.
3Youn SJ,Trinh NH,Shyu I,et al. Using online social media,Facebook,in screening for major depressive disorder among college students. International Journal of Clinical and Health Psychology,2013,13(1): 74–80. [doi: 10.1016/S1697-2600(13)70010-3]
4De Choudhury M,Counts S,Horvitz E. Predicting postpartum changes in emotion and behavior via social media.Proc. of the SIGCHI Conference on Human Factors in Computing Systems. New York,USA. 2013. 3267–3276.
5Wang XY,Zhang CH,Ji Y,et al. A depression detection model based on sentiment analysis in micro-blog social network. Proc. of the PAKDD 2013 International Workshops on Trends and Applications in Knowledge Discovery and Data Mining-Volume 7867. New York,USA. 2013.201–213.
6王丽,姚志剑,滕皋军,等. 静息态下不同性别抑郁症患者脑功能及其差异的fMRI研究. 中国心理卫生杂志,2008,22(4): 271–275.
7李鹏宇. 微博社交网络中的学生用户抑郁症识别方法研究[硕士学位论文]. 哈尔滨: 哈尔滨工业大学,2014. 17–60.
8郭珊,郭克锋. 抑郁症的研究进展. 中国临床康复,2005,9(4): 131–133.
9Zung WWK,Richards CB,Short MJ. Self-rating depression scale in an outpatient clinic: Further validation of the SDS.Archives of General Psychiatry,1965,13(6): 508–515. [doi:10.1001/archpsyc.1965.01730060026004]
10徐琳宏,林鸿飞,潘宇,等. 情感词汇本体的构造. 情报学报,2008,27(2): 180–185.
11谭松波. 高性能文本分类算法研究[博士学位论文]. 北京:中国科学院计算技术研究所,2005.
12Aizawa A. An Information-theoretic perspective of tf-idf measures. Information Processing & Management,2003,39(1): 45–65.
13张学工. 关于统计学习理论与支持向量机. 自动化学报,2000,26(1): 32–42.
14Vapnik VN. The Nature of Statistical Learning Theory. New York: Springer,1995.
15郭丽娟,孙世宇,段修生. 支持向量机及核函数研究. 科学技术与工程,2008,8(2): 487–490.
Depression Tendency Identification Model Based on Text Content Analysis
SHI Zhi-Wei,GAO Jun-Bo,HU Wen-Wen,LIU Zhi-Yuan
(Shanghai Maritime University,Shanghai 201306,China)
In order to solve the problem of identifying depression tendency among students on sina microblog platform,this paper proposes a depression tendency identification model. By inviting students widely to fill in the self-rating depression scale online on campus we can get the students’ score. We collect students’ microblog text and ask the psychology teacher to annotate the microblog artificially. In the pretreatment stage,we use the depression emotional dictionary to reassemble the depressed emotion words that are split at the segmentation stage so as to improve the recognition accuracy rate. And then we build a classifier based on the support vector machine to train the data. Through continuous learning and feedback,we get a better classification result. Finally,this paper defines the depression index and uses it to measure the degree of depression for a period of time. The experimental results indicate that the degree of depression measured by depression index is approximately consistent with the results of the scale,the accuracy of the method being 82.35%.
depression tendency identification; self-rating depression scale; depression emotional dictionary; support vector machine (SVM); depression index; sina micro-blog
施志伟,高俊波,胡雯雯,刘志远.基于文本的抑郁情感倾向识别模型.计算机系统应用,2017,26(12):155–159. http://www.c-sa.org.cn/1003-3254/6088.html
上海海事大学研究生创新基金(2016ycx036)
2017-03-09; 修改时间: 2017-03-27; 采用时间: 2017-03-31
