一种改进SCHMM/ANN的语音识别算法的提出
2018-01-08胡岩松
◎胡岩松
一种改进SCHMM/ANN的语音识别算法的提出
◎胡岩松
本文所采用的一种SCHMM/ANN模型,通过在ubuntu 14.04环境下搭建了用于语音识别的Kaldi系统,编写了两种模型的训练及识别脚本。利用开源的语音库THCHS-30对两种模型进行了验证,得到了无噪声环境下两者的语音识别率。对两种模型进行了抗噪性能的分析,测试语音中加入高斯白噪声对两种模型进行实验测试。最后通过实验数据说明了混合模型在噪声环境下能够取得较好的识别效果,并通过实验证明了改进的端点检测算法在两种模型的语音识别当中都是有效的。
基本算法
隐马尔可夫模型的表示方法:
3)A= (aij)N×N:状态转移概率分布。aij表示当前时刻状态从si转移到sj的概率。
4)B= (bjk)N×M:观测值概率分布。bj(k)指的是当前时刻模型状态为Sj,观测值的概率。
5)π,初始状态概率矩阵。其中:
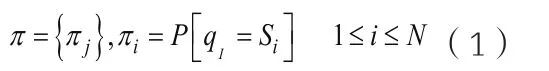
上面介绍的几个参数可以用来描述一个完整的隐马尔可夫模型,表示为λ=(N,M,A,Bπ)。通常N和M为固定值,HMM模型可简单表示为:λ= (A,B,π)(2)
子空间高斯混合模型也有高斯混合模型相对应的状态,但是子空间高斯混合模型并不是直接给出每一个状态的参数,而是通过一个相近的特征向量从全局高斯中映射而来。子空间高斯混合模型可以用全局高斯参数Mi,wi,和∑i,来描述:
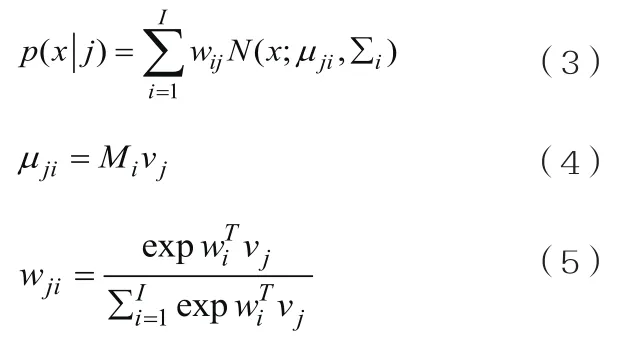
在这里,x是特征向量,j是上下文相产的模型状态。语音识别的模型状态j是由I个高斯组成的混合高斯。参数uij,∑ij,wij通过vj,Mi,∑i和wi推导出来(这是一个简化的描述)。我们使用术语“子空间”来表明高斯混合模型参数限制在整个空间的子空间范围内。我们注意到公式(5)的分母是有必要归一化的。我们也注意到,如果我们不使用指数函数,那么辅助函数中我们构建的E-M将不能保证是凸函数,这将导致我们在优化的过程中遇到困难。如果我们要声明单个权重wij作为模型的参数,而不是使用这个公式来得到,模型的规模将会由我们认为不好的权重所决定。这样最大似然估计框架将不再是有效的,它将会导致零权重出现。
仿真实验及结果分析
考虑到HMM和ANN各自的优缺点,在这里我们考虑将两者结合起来应用到语音识别中,将两者取长补短应用到语音识别领域。在这里,我们将神经网络的输出作为隐马尔可夫模型的输入信号,利用神经网络强大的描述能力来区分各种语音信号的特征,从而提高语音在同音字以及噪声环境下的识别率。
本实验在Kaldi语音识别系统中完成。实验采用清华大学开源语音库THCHS-30作为训练和测试的语音库,THCHS-30主要包含四个组A,B,C和D。其中A,B和C组主要是语音识别的训练样本。D组是语音识别的测试样本,D组又分为四个部分,分别对应四组测试结果。数据准备及数据的特征提取的脚本文件过程中我们采用的是MFCC作为语音信号特征提取的参数。其中的echo函数用来显示当前语音识别过程的进度。其中涉及到很多语音相关的脚本文件,这些脚本文件都是Kaldi语音识别系统为我们提供的用于语音识别相关操作的脚本文件。因为实验需要训练大量的语音数据,所以整个实验的训练和识别过程很漫长。
从语音识别的结果的数据可以看出,在纯净语音环境下,HMM/DBN混合模型的WER为14.2 070,传统HMM的语音识别系统的W ER为15.7070。从数据可以得出,在纯净的语音环境中HMM/DBN混合模型的识别效果只是略微优于传统的HMM模型,但两个模型的WER差异并不大。在这种环境下进行两种模型的结合,并不能有效地改善语音的识别率,而且还会增加训练时间,增加了开发的成本。因为模型的结合重点是针对在噪声环境下语音识别的情况,所以接下来我们继续对单一模型和混合模型在噪声环境下的语音识别进行研究。

表1 加入高斯白噪声两种模型的WER
通过Matlab可以实现对测试语音信号加入高斯白噪声。信噪比分比为5dB,10dB, 15dB, 20dB, 25dB, 30dB和35dB,得到的实验结果如表1所示。为了更直观地比较两种模型在噪声环境下的识别效果,可以看出,在高斯白噪声环境下,混合模型的语音识别效果明显优于传统模型的语音识别效果。实验结果表明:基于隐马尔可夫和人工神经网络混合的语音识别系统的抗噪性能明显优于传统隐马尔可夫模型的语音识别系统。混合模型利用了HMM强大的时序建模能力和ANN强大的描述能力,使得混合模型在一定噪声环境下仍然具有较高的语音识别能力。混合模型独特的抗噪声性能使这种模型在应用到产品的时候更有实际价值。
辽宁石化职业技术学院)
