Hadoop平台垃圾邮件过滤算法研究
2018-01-06张自圃
种 飞,徐 野,张自圃
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
Hadoop平台垃圾邮件过滤算法研究
种 飞,徐 野,张自圃
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
传统分布式大型邮件系统对海量数据的处理虽然具有比较高的准确性,但是具有效率低、程序复杂、占用资源多等缺点,因此,需要在传统过滤技术的基础上进行优化。采用Hadoop平台贝叶斯过滤算法的Mapreduce框架,对系统配置进行优化,能够得到比较全面的知识库,不仅提高了邮件过滤阶段的可靠性,还使实验性能评价指标有了很大的提升。
Hadoop;Mapreduce;垃圾邮件;贝叶斯过滤算法
随着Intenet的迅速发展,电子邮件技术使通过互联网来进行邮件信息交换成了现实,电子邮件凭借其快速便捷、成本低廉、易于保存等特点得到了人们的认可,并迅速成为当今交流的主要方式之一。然而,随之而来的副产品也就是垃圾邮件也渐渐地影响到人们生活,例如:传播病毒,发送广告和不良信息,严重时甚至会影响使用者的生命安全,所以应该加强对垃圾邮件进行处理。
在传统的垃圾邮件过滤技术中,主要采用基于黑白名单技术[1],基于规则的过滤技术[2],基于内容统计的过滤技术。在传统的过滤技术中,都呈现出一些缺点,比如:准确率低、处理数据慢、成本高、操作复杂等。贝叶斯算法[3]在内容统计过滤技术中得到了很好的运用,它对文本具有很强的分类能力且准确率高,不过这种技术前期要进行大量的训练,之后得出知识库,其对训练样本的依赖性太强,故面对海量的邮件文本具有一定缺陷。
考虑到传统垃圾邮件过滤技术的缺陷,本文提出在Hadoop平台上对过滤算法的应用,并作适当的改进,又采用分布式的Mapreduce编程模型,这样不仅可以对海量数据分布式处理,还有效提高了系统对垃圾邮件的执行效率。
1 过滤技术介绍
1.1 贝叶斯定理
概率论中的贝叶斯定理(Bayes'theorem)[3]是一个学习定理,贝叶斯定理基础是基于条件概率分布和边缘概率分布。
设S是随机事件,E是它的样本空间。则随机事件S中某一事件A发生,记为P(A),称为事件A发生的概率。
条件概率公式:设A、B是两个事件,且P(A)>0,则称

(1)
是在A发生基础上B发生的条件概率。

=P(B1)P(A/B1)+P(B2)P(A/B2)+…+P(Bn)P(A/Bn)
(2)
贝叶斯公式(Bayes formula):设试验S的样本空间为E,A为S的事件,B1,B2,…,Bn为E的一个划分,且P(Ai)>0,P(Bi)>0(i=1,2,…,n),则


(3)
1.2 Hadoop云计算
云计算是网络计算、分布式计算、并行计算等传统计算机和网络技术发展融合的产物,也是效用计算、虚拟化、硬件即服务(HaaS)、软件即服务(SaaS)、平台即服务(PaaS)等概念结合创新的结果。Hadoop三大核心设计Mapreduce、HDFS和HBase,分别是Google云计算核心技术Mapreduce、GFS和Bigtable的开源实现。
Mapreduce模型[4]是一种在集群上能够进行分布式并行处理海量数据的模型,是一种可用于数据处理的编程模型,该模型结构简单,Mapreduce程序本质上是并行运行的,可以将大规模的数据分析任务分发给任何一个拥有足够多机器的数据中心,其优势在于处理大规模数据集[5]。Mapreduce的工作原理大致可分为Map阶段和Reduce阶段,两个阶段在处理数据时都以键值对进行,其输出和输入的类型相同。Mapreduce作业(job)包括输入数据、Mapreduce程序和配置信息。系统把作业处理为许多任务并由Map和Reduce来完成。在执行任务时主要由一个Jobtracker和一系列Tasktracker节点进行。Jobtracker负责对任务的管理,Tasktracker 负责处理任务,Jobtracker与Tasktracker之间的通信和任务分配通过心跳机制实现,Tasktracker会主动定期向Jobtracker发送心态信息,询问是否有任务要做,果有,就会申请到任务。Tasktracker拿到任务,会将所有信息拷贝到本地。如果某个Tasktracker节点坏掉,这时Jobtracker会调用另一个Tasktracker节点继续执行任务,原理如图1所示。当Map阶段输出键值对流入到Reduce阶段的过程中,要经过Shuffle(混洗),这样不仅降低了Reduce阶段的工作量,还有利于数据的处理。

图1 Hadoop平台Mapreduce的工作原理
2 朴素贝叶斯算法的应用
2.1 朴素贝叶斯算法
朴素贝叶斯算法是目前公认的一种简单而有效的概率分类方法[6],是通过假设各元素之间相互独立而得到的一种简化算法。
朴素贝叶斯分类器对文本分类具有准确率高、易操作等优点,其工作原理是算出文本dx属于Di类的概率。当计算P(Di/dx)时,利用了贝叶斯公式:

(4)
其中,根据全概率公式,有

(5)
Di类的先验概率为

(6)
由以上算法可知,判定一个事件的类别,只要得出它的概率即可。假设文本d有特征字符串wj(j=1,2,…,n)为某一事件,并且wj出现是相对独立的。设定P(wj/Di)表示特征项wj在事件Di中的条件概率,既文本d是Di类的概率,P(Di)表示Di类的先验概率,有

(7)
分词结果如图2所示。

图2 朴素贝叶斯分类器分词
设邮件分为:正常邮件类Ham和垃圾邮件类Spam。首先对待训练样本分类,分为垃圾邮件(Spam)和正常邮件(Ham)两大类,再对邮件集合中的所有邮件进行读取扫描并提取特征字符串w1、w2、…、wn,统计每个字符串出现的次数f1、f2、…、fn。假设特征字符串w1、w2、…、wn之间互不影响,由以上算法得,一封邮件d是垃圾邮件的概率为

(8)
邮件d是正常邮件的概率,如下公式:
(9)
其中P(d)的计算公式如下
=P(Spam)×P(d/Spam)+P(Ham)×P(d/Ham)

(wi/Ham)
(10)
式中n是指特征词的总数。
P(wi/Spam)=
(11)
P(wi/Ham)=
(12)
由式(8)和式(9)之比得到如下公式:

(13)
由公式(13)知,中间值P(d)可以不用计算,这不仅减少了计算量,还提高了运算效率。取阀值M,若K≥M,则可判定该邮件d为垃圾邮件,否则归为正常邮件。阀值越大,则判定结果越精确。
2.2 MapReduce模型的朴素贝叶斯算法实现
系统将输入的文件分割为许多分片split,经过处理后形成键值对(k1,v1),此键值对输入Map,由Map阶段进行处理输出另一中间结果(k2,v2),之后系统将此键值对经过shuffle阶段的处理再次生成一个键值对(k2,{v2i,…}),最终进入Mapreduce模型的最后阶段,键值对(k2,{v2i,…})经Reduce处理得到键值对(k3,v3),流程图如图3所示。
垃圾邮件过滤系统分为训练部分和过滤部分。训练阶段有3个Mapreduce处理过程如图4所示,首先对待训练邮件集进行预处理,得到正常邮件集和垃圾邮件集;其次由训练部分的前两个Mapreduce对预处理结果进行特征词提取和词频的计算,由第三个Mapreduce计算出垃圾邮件特征词的条件概率;最后得出邮件的知识库。过滤阶段和训练阶段类似,同样用Mapreduce模型来过滤垃圾邮件,只是比训练阶段少一个Mapreduce过程,一个Mapreduce用来对待过滤邮件进行同样预处理,把预处理数据和知识库同时导入另一Mapreduce(即朴素贝叶斯过滤模块)进行过滤,最后得出的结果就是合法邮件和垃圾邮件。

图3 Mapreduce工作流程

图4 待训练邮件集训练过程
这里取正常邮件和垃圾邮件各50封,训练集和测试集如图5所示,具体分类细节如图6所示。
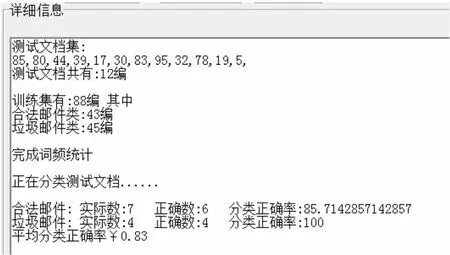
图5 训练和测试结果

图6 邮件分类明细
3 结果分析
本文在开源的Hadoop平台上进行实验,由于实验环境有限,采用伪分布式方式搭建6个节点构成集群,其中1个主节点,5个从节点。CPU型号为Inter(R)Core(TM) i5-2410M CPU @ 2.30GHz 2.30 GHz,8.0GB内存,操作系统为CentOS64位,Hadoop版本为2.2.0,jdk-7u51-linux-x64版本的jdk。
采用的样本来自于个人收集的邮件,包含有广告、公司内部及私人邮件等共64620封,其中垃圾邮件42854封、合法邮件21766封。
为了更好地测试算法的性能,要从垃圾邮件和正常邮件中取出一定数量的邮件,以保证数据的合理性,故取54封垃圾邮件和66封正常邮件。从邮件类别集合中分别取出7000封邮件进行训练,余下50500封邮件进行测试。在测试之前,把要进行测试的邮件集分为5等份,在相同的条件下进行实验,最后取平均值。在对垃圾邮件过滤实验进行判断时,用召回率(R)、查准率(I)、判对率(T)和F值四个实验性能评价指标[7]来衡量过滤算法的性能。召回率为系统判定正确的垃圾邮件与实际的垃圾邮件之比,召回率越高表示漏掉的垃圾邮件越少。查准率为系统判定正确的垃圾邮件与系统判定的垃圾邮件之比,查准率越高表示系统误判的合法邮件越少。判对率为所有系统判定类别正确的邮件与所有系统判定的邮件之比,其反映正确归类邮件的能力。F值为垃圾邮件查准率和召回率的综合运用,即为2IR/(I+R)。
在不同的实验中,令阀值为0.8,分别在传统邮件过滤算法和Hadoop平台朴素贝叶斯算法的两种情况下进行实验,得出结果并进行比较,如表1所示。改变阀值再重复测试,对比测试效果。

表1 传统过滤算法和Mapreduce模型过滤算法对比
由测试数据可知,在阀值一定的前提下,Mapreduce模型朴素贝叶斯算法的各个性能指标都要优于传统分布式贝叶斯算法。将朴素贝叶斯算法运用到Hadoop平台上,实现对垃圾邮件的分布式处理,使得对处理海量垃圾邮件的效率和准确性都有了显著提升。图7为DataNode数量与加速比的关系图。

图7 DataNode数量与加速比的关系图
由图7可知,随着DataNode节点数量的增加,其加速比也随之升高,即相比传统的贝叶斯过滤算法,改进后的过滤系统在处理时间上明显减少。
4 结束语
传统的垃圾邮件过滤算法,在面对海量数据时会出现处理效率低、资源浪费大、运行成本高等缺点。但将此算法过度到Hadoop平台下实现,能够运用廉价的PC构建庞大的集群实现性能高的数据处理平台,提高了邮件过滤平台的性价比,面对海量邮件也能发挥其良好的处理能力。由实验可得,运用在Hadoop平台的朴素贝叶斯算法远优于传统的垃圾邮件过滤算法,该算法在Mapreduce模型上能够很好的执行,进一步提高了处理海量数据的性能。
[1] 徐洪伟,方勇,音春.垃圾邮件过滤技术分析[J].通信技术,2003(10):126-128.
[2] 向旭宇,姬林,杨岳湘.电子邮件系统过滤技术研究及实现[J].计算机应用研究,2003(20):136-137.
[3] Seigo Michaela A.In vivo assessment of retinal neuronal layers in multiple sclerosis with manual and automated optical coherence tomography segmentation techniques[J].Journal of Neurology,2012,259(10):2119-2130.
[4] White T.Hadoop 权威指南[M].周敏奇译.北京:清华大学出版社,2011.
[5] 怀特.Hadoop权威指南[M](第三版).华东师范大学数据科学与工程学院译.北京:清华大学出版社,2015.

[7] 李文斌,陈嶷瑛,刘椿年,等 .邮件过滤算法的比较[J] .计算机工程与设计,2008,29(17):4433-4436.
ResearchonSpamFilteringAlgorithmofHadoopPlatform
CHONG Fei,XU Ye,ZHANG Zipu
(Shenyang Ligong University,Shenyang 110159,China)
Traditional distributed large-scale mail system deals with the massive data.Although it has relatively high accuracy,but it has low efficiency,complex proceduce and other drawbacks.Therefore,it needs to be optimized by traditional filtering technology.Hadoop platform Bayesian filter algorithm Mapreduce framework is adopted to optimize system configuration and could get a more comprehensive knowledge base,which improves nots only the reliability of the mail filter phase,but also experimental performance of evalution index.
Hadoop;Mapreduce;spam;Bayesian filtering algorithm
2017-01-08
种飞(1987—),男,硕士研究生;通讯作者:徐野(1976—),男,教授,博士,研究方向:无线网络信息处理技术等。
1003-1251(2017)06-0042-05
TP393
A
马金发)
