基于优化核极限学习机的光伏出力短期预测
2018-01-05田德,张琦
田 德, 张 琦
(广东工业大学 自动化学院,广东 广州 510006)
基于优化核极限学习机的光伏出力短期预测
田 德, 张 琦
(广东工业大学 自动化学院,广东 广州 510006)
光伏出力的精确预测有利于确保电力系统的可靠运行,减小投资者的利益风险。考虑到光伏出力的不确定性和非平稳性,首先采用自适应白噪声的完整集合经验模态分解(Complete Ensemble Empirical Mode Decomposition with Adaptive Noise,CEEMDAN)将原始光伏出力序列分解为一系列相关性较强、较平稳的子序列,再使用核极限学习机(Kernel Extreme Learning Machine,KELM)分别对每一子序列进行预测。由于KELM学习参数选取对其预测性能有较大影响,提出了基于改进蝙蝠算法(Improved Bat Algorithm, IBA)对KELM模型参数进行寻优。最后,将每一子序列预测结果通过求和相加获取最终的预测值。实际算例表明,该IBA算法收敛速度快,全局搜索能力强,所提的CEEMDAN-IBA-KELM组合方法能有效提高光伏出力的预测精度。
光伏出力预测; 自适应白噪声;集合经验模态分解; 核极限学习机; 参数优化; 改进蝙蝠算法
0 引言
绿色清洁能源特别是太阳能和风能是目前最具商业发展前景的发电方式之一,已受到了越来越多的重视。然而,随着并网光伏发电技术的不断发展,给电力系统的运行稳定性带来了严峻的挑战。因此,并网光伏出力的准确预测不仅能有效降低大规模光伏发电接入对电网的影响,提高电网对光伏的接纳能力,而且太阳能资源的充分利用可以获得较高的经济效益和社会效益。
目前,光伏输出功率预测方法主要集中于单一的人工智能预测方法,包括人工神经网络、支持向量机等。但以上单一预测的方法均受到自身特性的限制,根据相似日原理选取预测样本,建立径向基神经网络预测模型,虽然径向基神经网络优于一般的BP神经网络,但其仍存在中心矢量和隐层节点数难以确定的问题[1-3]。文献[4-5]根据光伏出力及其影响因素建立了基于支持向量机回归预测模型,适合于多变的复杂天气情况下光伏预测,但支持向量机模型参数选取对预测性能存在较大影响。组合预测方法结合了各单一预测方法的优势,因此受到了越来越多的关注。现阶段,组合预测方法主要有:1)将各单一模型预测值根据某种权重关系筛选出最佳的权重组合系数,从而建立权重组合预测模型[6]。2)基于单一预测模型参数优化的组合方法,如文献[7]采用遗传算法对人工神经网络的权值和阈值进行优化。3)基于信号分解技术的组合预测方法,其中,信号分解技术主要包括小波分解[8-9](Wavelet Decomposition,WD)、经验模态分解[10](Empirical Mode Decomposition,EMD)和集合经验模态分解[11](Ensemble Empirical Mode Decomposition,EEMD)等,即通过将原始数据信号分解为一系列子序列,对其分别采用人工智能算法进行预测并求和得到最终的预测结果。
考虑到光伏出力序列的波动性和随机性特点,本文采用一种自适应白噪声的完整集合经验模态分解[12](Complete Ensemble Empirical Mode Decomposition with Adaptive Noise, CEEMDAN) 方法,通过在分解的各个阶段添加自适应白噪声,并根据计算剩余的余量信号以得到各个分量信号,该方法克服了传统EMD方法模态混叠缺点以及EEMD分解低效率的问题,且可以有效降低光伏序列的非平稳性。基于此,提出一种基于CEEMDAN与IBA-KELM组合预测方法, 充分考虑了KELM模型参数选取对预测结果精度的影响[13],采用改进的蝙蝠算法对其参数进行优化。最后,以美国俄勒冈州某光伏电站数据为例,验证了本文采用的CEEMDAN-IBA-KELM组合预测方法具有优良的预测精度。
1 光伏出力影响因素分析
光伏功率预测[14-16]是一个复杂的非线性问题,因此决定功率大小的因素有许多。实际工程中,光伏输出功率可表示为[17]:
P=ηIsA[1-0.005(T+25)]
(1)
式中:η为光伏阵列的转化效率;Is为辐照强度,(W/m2);A为阵列的总面积,(m2);T为大气温度,(℃)。
通常对既定的光伏电站其安装角度及光伏阵列转换效率已包含在历史输出功率数据中,因而无需考虑。因此,从上式可知光伏功率输出受太阳辐照强度和环境温度的影响。而实际中,除了这2个影响因素外,对于光伏出力预测还需考虑天气类型、风速、季节等。
1.1 气象因素对光伏功率的影响
为分析太阳辐照、环境温度和风速对光伏输出功率的影响,以美国某光伏电站的历史数据为例,随机选取2015年某3天的历史数据绘制光伏输出功率与太阳辐照强度、温度和风速的关系示意图,如图1~3所示。由图可知,太阳辐照强度与光伏输出功率曲线变化趋势基本一致,耦合程度高,说明太阳辐照是影响光伏功率输出最为主要的因素;图2和图3中温度、风速均与光伏输出功率呈现一定的相关性,且风速随机性较强,对光伏输出功率影响较弱。因此,本文将光伏辐照强度、温度均作为IBA-KELM模型的输入变量[18-19]。
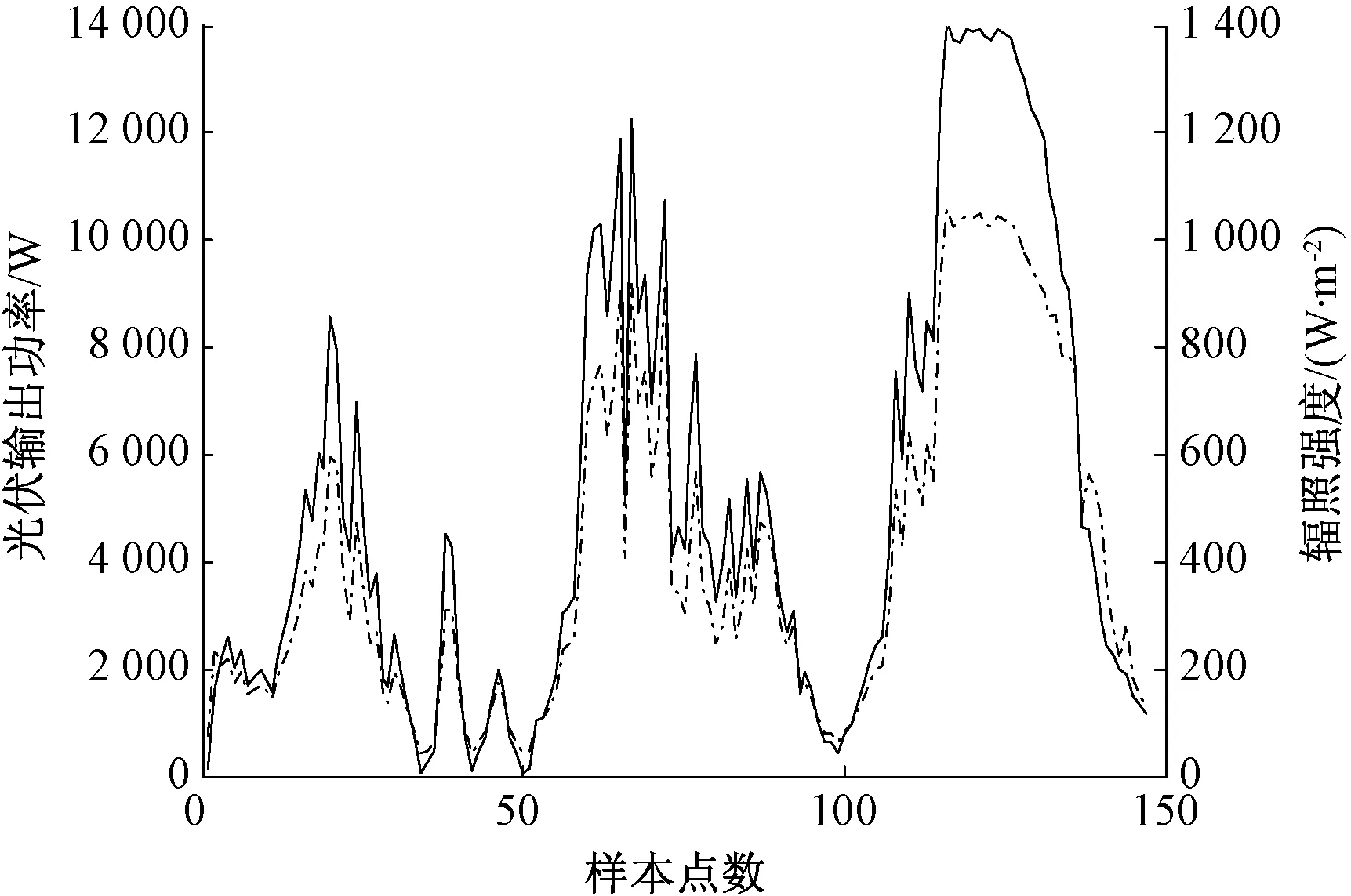
图1 光伏输出功率与太阳辐照曲线图
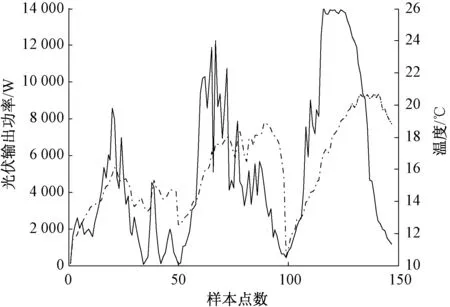
图2 光伏输出功率与温度曲线图
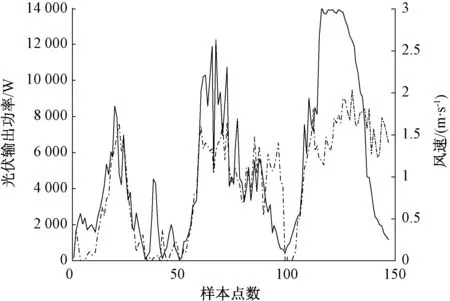
图3 光伏输出功率与风速曲线图
1.2 不同天气类型下光伏输出功率大小
图4为2015年5~6月某3天的晴天、突变天气、雨天3种主要天气类型下的光伏输出功率。从图中可以看出,晴天的光伏输出功率曲线相对平稳;而突变天气、雨天的光伏功率曲线波动性、随机性较强,这一情况不仅增加了光伏功率预测的难度,而且对光伏电站运行的安全稳定性造成影响[20]。因此,针对不同天气类型数据分别进行预测尤为重要。
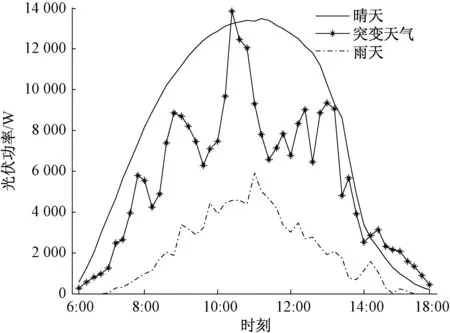
图4 不同天气类型下的光伏功率曲线
1.3 不同季节下光伏输出功率大小
以晴天为例,选取春、夏、秋、冬四季下的光伏功率曲线如图5所示。由图可知,春季与夏季日照时间长,其光伏功率输出值相对较大;秋季与冬季温度低、日照时间相对较短,其光伏功率输出值相对较小。因此,不同季节的光伏输出功率对预测存在一定的影响。
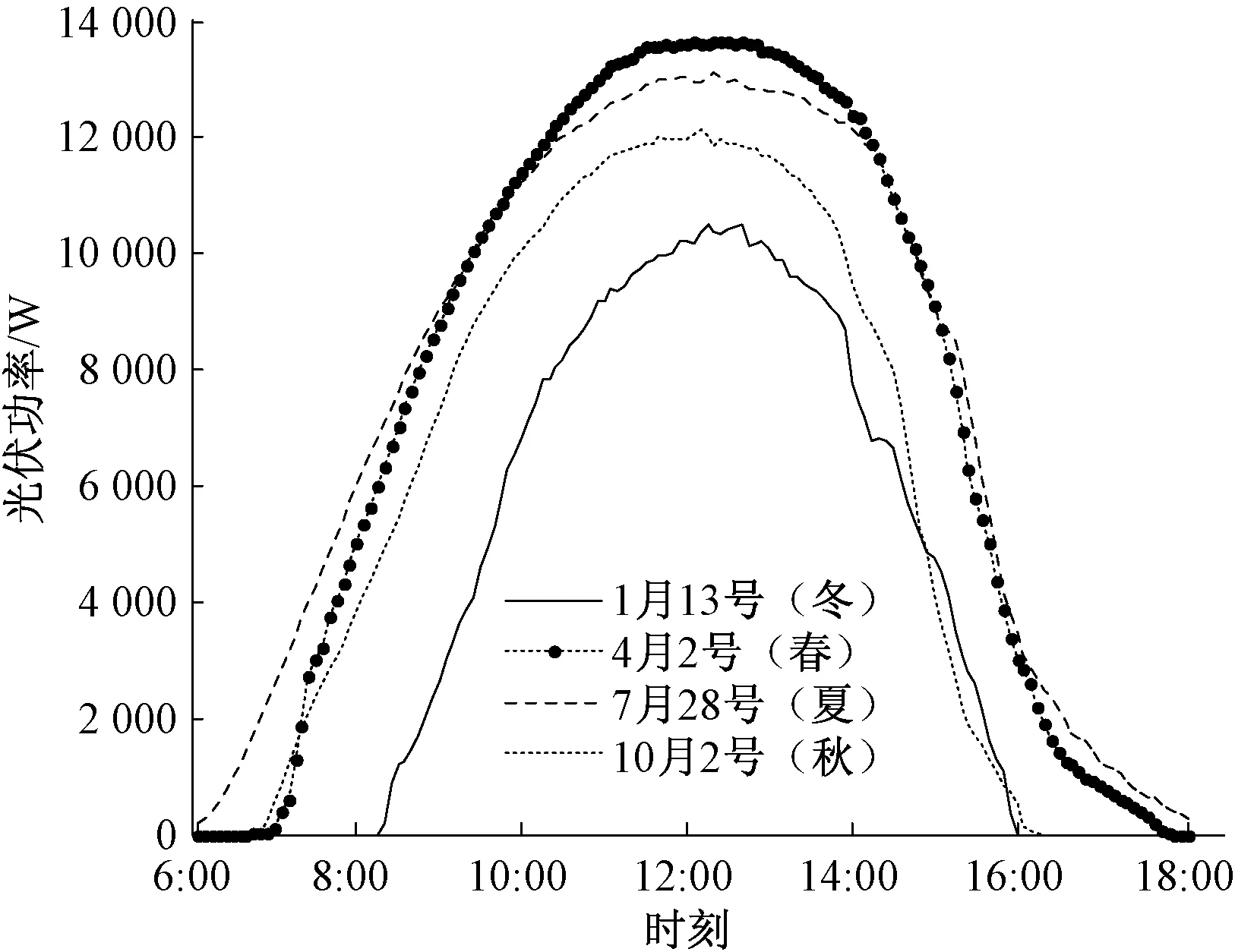
图5 不同季节下的光伏功率曲线
2 相似日选取
考虑到光伏输出功率在不同天气类型下差别较大,为准确选取与预测日最为相似的历史功率输出日以减小预测误差,采用数据挖掘中应用较广泛的K-means算法[21]。
假设原始光伏功率数据样本为xi={x1,x2,…,xn},将样本聚类为c类,其具体过程如下[22]:
(1)从原始样本中随机选取c个输入样本作为初始聚类中心,c即代表1.2节中3种不同天气类型。
(2)以距离中心最近原则,计算样本xi与kc间的欧氏距离,将该样本分配至最邻近聚类集合εk中。
(3)计算εk中各样本的平均值,重新生成新的聚类中心。
(4)重复步骤(2)、(3),直至相邻2次计算中的聚类中心不变时算法结束。
3 组合预测模型
3.1 CEEMDAN方法
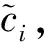
(2)
因此,根据CEEMDAN将原始u(t)信号分解为:
(3)
式中:i=1,2,…,K,K为模态分量的总数。
3.2 KELM算法
KELM算法[24]是依据传统极限学习机(Extreme Learning Machine, ELM)的基础而提出的。因传统ELM的输入层权值及隐层权值均随机设定,其预测性能较差,因此,根据支持向量机的原理引入核函数,从而提出了KELM算法,其具体证明过程可参见文献[25]。其中,KELM模型的输出及其核函数公式为:
(4)
K(μ,ν)=exp(-(μ-ν2/g))
(5)
式中:C为惩罚系数;I为单位稀疏矩阵;核函数K(μ,ν)一般采用为RBF核;g为核系数。
该算法克服了传统ELM在处理低维数据时线性不可分的缺点并提高了算法的学习速率和泛化能力。但KELM模型的预测性能仍受其学习参数的影响较大,所以本文采用全局搜索能力强的IBA进行参数优化。
3.3 IBA优化KELM
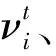
fi=fmin+(fmax-fmin)·rand
(6)
(7)
(8)
(9)
式中:ωini、ωter分别为惯性系数的初始值和最终值;c为惯性权重相关系数;τ为当前迭代次数;τmax为最大迭代次数。
根据改进后的BA优化KELM的步骤描述如下:
1)设置IBA相关参数,主要包含:种群数目N,最大迭代次数τmax,最小频率fmin、最大频率fmax,最大音量A,最大脉冲率r,惯性系数的初始值ωini和最终值ωter;惯性权重相关系数c1。
2)随机初始化蝙蝠位置xi,其由惩罚因子C和核参数g组成,并根据适应度函数f(xi)值寻找当前最优位置x*。
3)位置更新。根据公式(6)~(9)更新每一个体脉冲频率、速度与位置。
4) 设定随机数rand,若rand>r,则随机产生新解。
克什米尔地区一直是印度和巴基斯坦的争议地区,其归属权之争由来已久,导致政局一直不稳定。20世纪中期的两次印巴战争使得矿区无法勘探和开掘,本计划于1990年实施的新矿区开发项目也因政治动乱而没能进行。同时由于地理环境也比较特殊——平均海拔超过4000米,人类生存条件恶劣,常年处于低温严寒状态,适宜开采的时间每年仅2-3个月。加之山上基本设施匮乏,大型开采机械又无法运到山上,这些因素都造成克什米尔蓝宝石开采成本巨大。以至于克什米尔矢车菊、皇家蓝,很多人也只闻其名不见其物!
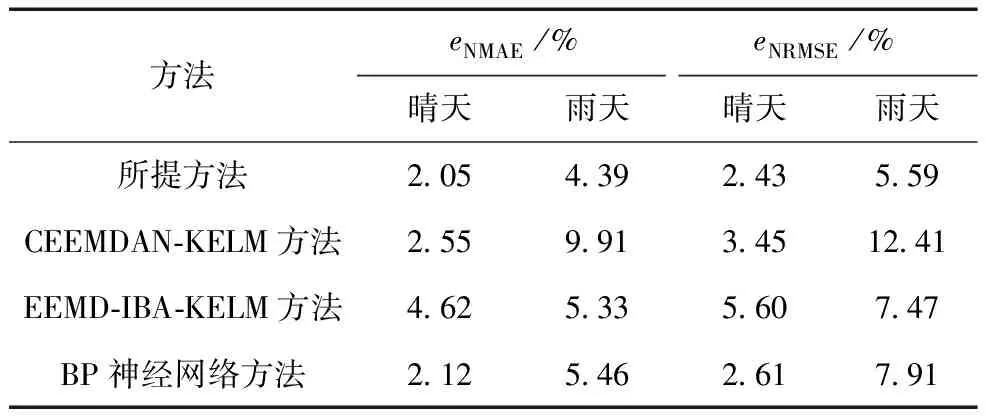
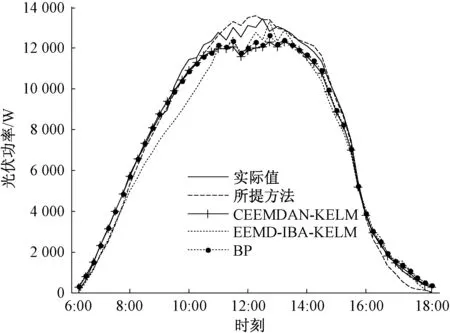
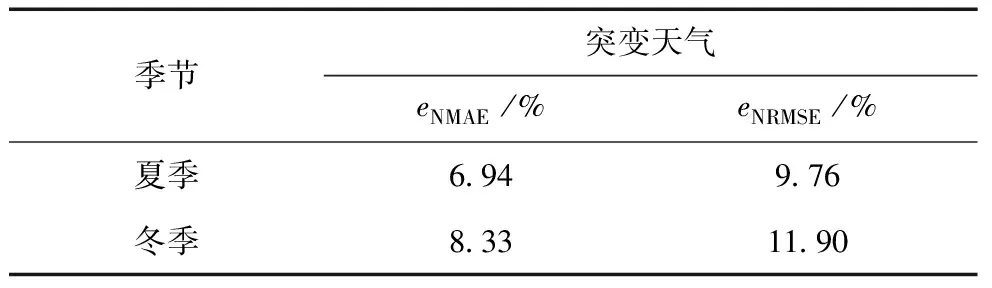
5)设定随机数rand,若rand 6)将所有个体的适应度值重新排序后,找出当前最优解。 7)判断是否满足算法终止条件,若满足,则输出最优解,否则跳回2)继续迭代,直至迭代次数τ=τmax,输出当前最优解。 8)根据最优解获取最优C和g,从而建立KELM预测模型。 基于CEEMDAN-IBA-KELM的光伏出力预测模型如图6所示,结合图6对其具体过程进行描述: 1)首先将光伏原始功率数据及气象数据进行归一化处理,以消除不同量纲数据间的差别。 2)设置K-means聚类算法的聚类数c=3,分别代表3种天气类型,根据聚类结果选取与待预测日中相似度最大的5天数据。 3)将不同天气类型下的光伏出力样本序列分别通过CEEMDAN方法分解为一系列相关性强的子模态分量。 4)根据得到的各分量分别建立KELM预测模型。 6)分别对各子序列进行预测。 7)将各序列预测结果通过相加求和得到最终的预测值。 图6 CEEMDAN-IBA-KELM组合预测算法流程图 以美国某光伏电站为研究对象,其机组容量为15 kW。由于光伏功率输出通常在白天,因而,选取2015年2月~10月的06:00~18:00时间段每15 min一个点的实测光伏数据为样本(包括光伏历史功率数据、太阳辐照强度、环境温度等历史气象数据),每天总共49个点。 首先,根据聚类算法选取的5天相似日中的前4天的光伏功率数据和相应气象数据为训练样本,第5天的光伏功率数据为测试样本,并对数据集进行归一化处理到[0,1]区间。本文为提前1天的光伏功率预测,分别采用归一化绝对平均误差eNMAE和归一化均方根误差eNRMSE作为预测误差评价标准,其公式为[28]: (10) (11) 然后,以突变天气的光伏功率数据样本为例,经CEEMDAN分解得到的子模态如图7所示,其中,子模态总数K=8。 图7 突变天气下光伏功率序列CEEMDAN分解 为了验证本文所述组合预测模型的有效性,将CEEMDAN分解得到的各个模态序列与预处理后的气象数据形成测试集,分别建立IBA-KELM模型进行预测,最后将各序列预测结果求和叠加得到光伏预测值。其中,KELM学习参数的范围为C∈(0.01,1000),g∈(0.01,1000)。 同时,为了进一步验证本文所提方法的可行性,提出了多种方法对光伏功率进行预测,包括BP神经网络方法、未优化的CEEMDAN-KELM方法、EEMD-KELM方法和所提出的CEEMDAN-IBA-KELM方法。为公平起见,各优化模型的种群数目均取20,最大迭代次数为200。其中,未优化时的KELM算法中,C=10,g=100。基于晴天、雨天下各模型预测误差分析指标结果如表1所示,各预测算法结果如图8、9。 由表1和图8、9可知: 1)晴天的预测精度明显高于雨天,说明雨天光伏出力具有较强的随机性和波动性。 2) 基于IBA优化的组合预测方法误差低于其他方法,说明IBA优化KELM模型的参数,可以更好地提高KELM泛化能力和预测精度。 3)经CEEMDAN分解处理后预测精度明显高于EEMD分解处理后的预测精度,说明CEEMDAN可以有效克服模态混叠缺点,提高预测精度。且采用CEEMDAN分解处理有利于降低光伏出力序列的非平稳性,减小预测误差。 表1 不同算法的预测指标 图8 晴天不同算法预测结果 图9 雨天不同算法预测结果 为进一步验证CEEMDAN-IBA-KELM模型在不同季节预测效果,选取了2015年7月、12月对应夏季与冬季2种极端情况,分别对每个季节下的突变天气进行提前1天预测,预测结果如图10所示,预测误差评价如表2所示。 由图10与表2分析可知,在2种极端季节情况下,本文方法的预测结果均能够很好地跟踪到实测功率曲线,在冬季情况下光伏出力波动较大,其预测效果较弱。相反地,夏季时光伏出力波动较小,其预测效果最好,且相应的eNMAE、eNRMSE误差最小均达到6.94%和9.76%。 综上,不论是夏季还是冬季,不同天气类型下的eNMAE、eNRMSE均较小,可以说明所提的CEEMDAN-IBA-KELM预测模型的有效性。 图10 突变天气夏季与冬季预测结果 季节突变天气eNMAE/%eNRMSE/%夏季694976冬季8331190 (1)针对不同天气类型的光伏出力的差异,采用聚类算法将光伏历史数据进行相似日选取,可以减小预测误差。 (2)由于光伏出力的随机性、非平稳性等特点,采用CEEMDAN分解技术将原始光伏功率序列分解为一系列规律性较强的子序列,分别对分解后的多个子序列建立KELM预测模型,从而有效提高预测精度。 (3)针对KELM参数盲目选取的弊端,导致算法收敛速度慢、预测精度不高,本文提出了基于改进的蝙蝠算法优化KELM的核参数和惩罚系数。算例结果表明,该方法大大提高了预测的准确性,具有较好的可行性。 [1]MELLIT A, PAVAN A M. A 24-h forecast of solar irradiance using artificial neural network: Application for performance prediction of a grid-connected PV plant at Trieste, Italy[J]. Solar Energy, 2010, 84(5):807-821. [2]王彬筌, 苏适, 严玉廷. 基于BP神经网络的光伏短期功率预测模型[J]. 电气时代, 2014,33(5):78-81. [3]王晓兰, 葛鹏江. 基于相似日和径向基函数神经网络的光伏阵列输出功率预测[J]. 电力自动化设备, 2013, 33(1):100-103. [4]YANG X, JIANG F, LIU H. Short-term solar radiation prediction based on SVM with similar data[C]// Beijing: Renewable Power Generation Conference, 2013. [5]栗然.李广敏.基于支持向量机回归的光伏发电出力预测[J].中国电力,2008,41(2):74-78. [6]杨锡运, 刘欢, 张彬,等. 组合权重相似日选取方法及光伏输出功率预测[J]. 电力自动化设备, 2014, 34(9):118-122. [7]MELLIT A, KALOGIROU S A, DRIF M. Application of neural networks and genetic algorithms for sizing of photovoltaic systems[J]. Renewable Energy, 2010, 35(12):2881-2893. [8]朱红路, 李旭, 姚建曦,等. 基于小波分析与神经网络的光伏电站功率预测方法[J]. 太阳能学报, 2015, 36(11):2725-2730. [9]MANDAL P, MADHIRA S T S, HAQUE A U, et al. Forecasting power output of solar photovoltaic system using wavelet transform and artificial intelligence techniques[J]. Procedia Computer Science, 2012, 12(1):332-337. [10]徐敏姣, 徐青山, 袁晓冬. 基于改进EMD及Elman算法的短期光伏功率预测研究[J]. 现代电力, 2016, 33(3):8-13. [11]茆美琴, 龚文剑, 张榴晨,等. 基于EEMD-SVM方法的光伏电站短期出力预测[J]. 中国电机工程学报,2013, 33(34):17-24. [12]李晓莉, 李成伟. 改进的自适应噪声总体集合经验模态分解在光谱信号去噪中的应用[J]. 光学精密工程, 2016, 24(7):1754-1762. [13]裴飞, 陈雪振, 朱永利,等. 粒子群优化核极限学习机的变压器故障诊断[J]. 计算机工程与设计, 2015(5):1327-1331. [14]LI Y, HE Y, SU Y, et al. Forecasting the daily power output of a grid-connected photovoltaic system based on multivariate adaptive regression splines[J]. Applied Energy, 2016, 180(1):392-401. [15]KUDO M, TAKEUCHI A, NOZAKI Y, et al. Forecasting electric power generation in a photovoltaic power system for an energy network[J]. Electrical Engineering in Japan, 2009, 167(4):16-23. [16]张华彬, 杨明玉. 基于天气类型聚类和LS-SVM的光伏出力预测[J]. 电力科学与工程, 2014, 30(10):42-47. [17]王守相, 张娜. 基于灰色神经网络组合模型的光伏短期出力预测[J]. 电力系统自动化, 2012, 36(19):37-41. [18]叶林, 陈政, 赵永宁,等. 基于遗传算法—模糊径向基神经网络的光伏发电功率预测模型[J]. 电力系统自动化, 2015,39(16):16-22. [19]谢恩哲. 考虑气象要素的光伏预测模型研究[D]. 哈尔滨:哈尔滨理工大学, 2015. [20]贺文, 齐爽, 陈厚合. 蚁群BP神经网络的光伏电站辐照强度预测[J]. 电力系统及其自动化学报, 2016, 28(7):26-31. [21]孔英会, 安静, 车辚辚,等. 基于增量DFT概要的数据流聚类算法[J]. 华北电力大学学报(自然科学版), 2007, 34(5):85-89. [22]邵堃侠, 郭卫民, 杨宁,等. 基于K-means算法的RBF神经网络预测光伏电站短期出力[J]. 上海电机学院学报, 2017,20(1):27-33. [23]陈雷, 陈国初, 朱志权. 基于CEEMD-HT算法的谐波分析方法[J]. 电力科学与工程, 2017, 33(1):61-66. [24]HUANG G B,ZHU Q Y,SIEW C K. Extreme learning machine:Theory and applications[J]. Neurocomputing,2006,70(1-3):489-501. [25]杨锡运,关文渊,刘玉奇,等.基于粒子群优化的核极限学习机模型的风电功率区间预测方法[J]. 中国电机工程学报, 2015, 35(S1):146-153. [26]YANG X. Bat algorithm for multi-objective optimization[J]. International Journal of Bio-Inspired Computation, 2012, 3(5):267-274. [27]范彬, 周力行, 黄頔,等. 基于改进蝙蝠算法的配电网分布式电源规划[J]. 电力建设, 2015, 36(3):123-128. [28]张亚超, 刘开培, 秦亮. 基于VMD-SE和机器学习算法的短期风电功率多层级综合预测模型[J]. 电网技术, 2016, 40(5):1334-1340. Short Term Prediction of Photovoltaic Output Based on Optimized Kernel Extreme Learning Machine TIAN De, ZHANG Qi (School of Automation, Guangdong University of Technology, Guangzhou 510006, China) Accurate prediction of PV output is helpful to ensure the reliable operation of power system and reduce the risk of investors. Considering the uncertainty and non-stationarity of the PV output, firstly, the complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) is used for the decomposition of the original PV output sequence into a series of strong correlation, stable sub sequences; and then kernel extreme learning machine (KELM) is built to carry out prediction for each sub sequence. Due to the great influence of the selection of KELM learning parameters on the prediction performance, an improved bat algorithm (IBA) is proposed to optimize the parameters of KELM. Finally, the final prediction value is obtained by adding each subsequence. The practical example shows that the IBA has a fast convergence speed and strong global search ability, and the proposed CEEMDAN-IBA-KELM combination method can effectively improve the prediction accuracy of PV output. photovoltaic output prediction; complete ensemble empirical mode decomposition; adaptive noise; kernel extreme learning machine; parameter optimization; improved bat algorithm 2017-07-11。 10.3969/j.ISSN.1672-0792.2017.12.003 TM615 A 1672-0792(2017)12-0015-07 田德(1992-),男,硕士研究生,主要研究方向为新能源发电。 张琦(1992-),女,硕士研究生,主要研究方向为新能源发电。3.4 组合预测方法建模流程

4 算例及仿真结果分析
4.1 数据来源
4.2 仿真结果分析
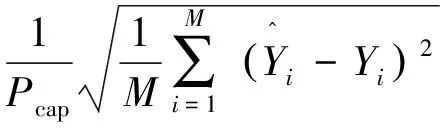
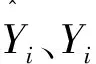


5 结论
