基于超图的多文档新闻关键词抽取∗
2018-01-04范泽泉
范泽泉 赖 华
(1.昆明理工大学信息工程与自动化学院 昆明 650500)(2.昆明理工大学信息处理重点实验室 昆明 650500)
基于超图的多文档新闻关键词抽取∗
范泽泉1赖 华2
(1.昆明理工大学信息工程与自动化学院 昆明 650500)(2.昆明理工大学信息处理重点实验室 昆明 650500)
新闻作为网络信息传播的重要载体,其本质是一个以接近真相为目标的持续过程。随着时间的推进,针对同一新闻事件会出现大量详尽程度不同的网页。如何在这些网页中快速、准确地抽取出这一系列新闻的关键信息成了一个越来越重要的课题。关键词作为对文章内容的简要概括,可以使用户快速了解新闻事件,从而节省大量的时间,因此关键词抽取技术被认为是解决此类问题的关键。文章通过分析新闻网页的特点,提出一种新的基于超图模型的多文档关键词抽取方法,该方法以词作为节点,新闻网页作为超边,并结合网页信任度、新闻发布时间因素,建立了多新闻文档的超图模型,最后使用超图排序算法抽取出关键词。实验的结果验证了该方法的准确性。
多文档超图模型;超图排序;随机游走;关键词抽取;网页信任度;时间因素
1 引言
随着信息技术的飞速发展,互联网上的信息呈现出几何级数的增长,其中存在着海量的新闻网页。有时针对同一新闻事件,随着事件的逐步推进,又会出现不同层面、详尽不同的报道。如何从海量的网页中快速、准确地抽取出这一系列新闻事件的关键信息成为了数据挖掘方面的研究热点。
关键词能表达文本的主题思想与内容,在信息检索系统的应用中,它常用于标引文章的主要内容以供用户进行查阅[1]。可以说,关键词是表达一个文档核心意义的最小单位,它可以在极少的时间内就使用户对新闻事件建立起一个较为清晰的了解。关键词在期刊和会议论文当中通常是由作者自己标注,然而,对于大量的新闻文章来说,却普遍没有关键词[2]。因此如何自动地从新闻文档中抽取关键词具有十分重要的实际应用及研究价值。
国内外关于关键词提取技术的研究,主要分为以下几类:第一类是基于统计的抽取方法,即统计候选词在文档中出现的频率和位置,对这两类特征值加权求和,最后进行排序。如Salton等提出的TF-IDF算法就是基于这种思想[3]。而Mihalcea等提出的TextRank算法,首先根据词共现关系构建图网络,然后再进行排序来抽取关键词[4]。第二类是基于语言学的抽取方法,主要利用自然语言处理的相关技术来提高抽取的准确度。如索红光等考虑到词汇间的依存关系,利用知网知识库构建词汇连,再结合词频特征从候选集中抽取关键词[5]。第三类是基于机器学习的方法,如ADM公司的Tur⁃ney将文本内容分为关键词类和非关键词类,只针对关键词类挑选特定的关键词作为文档的关键词。后来基于这一思想,美国著名的数学家Witten等人提出采用朴素贝叶斯算法作为分类器来对关键词进行自动提取[6]。
近年来,基于图的排序算法已经成功地应用于文本摘要[7]和关键词抽取[8]。然而传统的图模型仅能表达句子与词之间简单的二元关系,却无法很好地描述词与文档之间,文档与文档之间更加高阶的多元关系。同时,目前的关键词抽取研究大多集中在单文档环境下,却忽视了新闻的本质是一个动态的过程。为此,文章提出了一种基于超图的多文档新闻关键词抽取方法。
2 超图
在数学上,超图是普通图的一种泛化,普通图中一条边只能连接两个顶点,表示这两个顶点之间满足一定的关系,然而在实际生活中,各个对象间的关系往往要复杂得多。超图与普通图最大的区别在于,一条超边可以包含两个以上的顶点。对于许多问题,普通图并不能完全表示各个对象间的关系,如图1中给出的例子。一个文档集需根据不同的主题进行区分,唯一已知的信息是各个文档的作者。如果使用普通图模型来表示,一个顶点代表一篇文档,若两个顶点被一条边相连,则代表这两篇文档拥有同一个作者。显然这种方法丢失了同一作者是否是三篇或以上文档的作者的信息。同一作者所写的文档极有可能是属于同一主题的,这一信息是非常重要的。而在使用超图表示这一问题时,因为一条超边可以包含多个顶点,所以在构建超图时,一条超边可以表示一个作者,该作者的所有作品都包含在此超边之中。因此相比于简单图,超图显然更好地表示出了文档与作者之间的关系[9]。
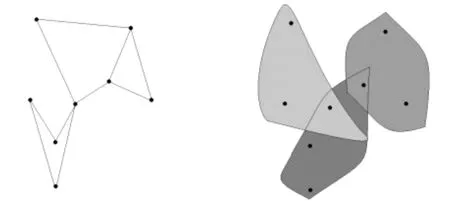
图1 超图与普通图
设超图 H=(V,E),其中V={v1,v2,v3,…,vn-1,vn}是一个有限的集合,表示超图的顶点集,其中的每一个元素都是超图的一个顶点。 E={e1,e2,e3,…,em-1,em}是V的一系列的集族,表示包含至少一个顶点的超边的集合,ei为超边。每条超边包含的顶点的个数称之为超边的度,定义为δ(e)= ||e,通常情况下,超图的顶点和超边都有对应的权值。
一个简单的超图如图2所示,图中包含6个顶点,4条超边,即顶点集V={v1,v2,v3,v4,v5,v6},超边集 E={e1,e2,e3,e4},其中e1={v1,v2,v3},e2={v2,v3},e3={v3,v5,v6},e4={v4},e1的度为3。由此可以看出,当超边只包含两个顶点的时候,超图就相当于简单图,因此可以说超图是简单图的泛化。
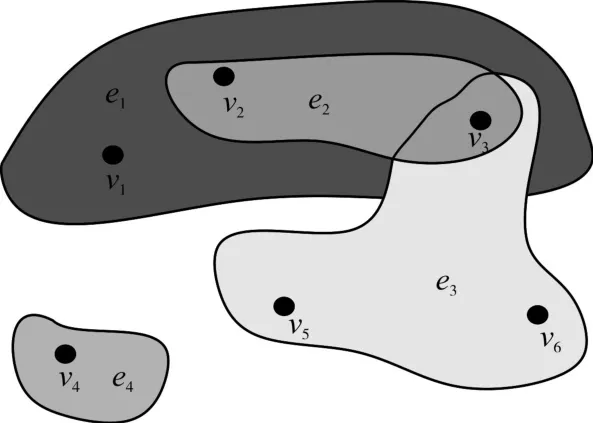
图2 超图
超图的关联矩阵定义如下:
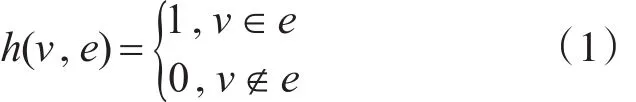
顶点和超边的度定义如下:
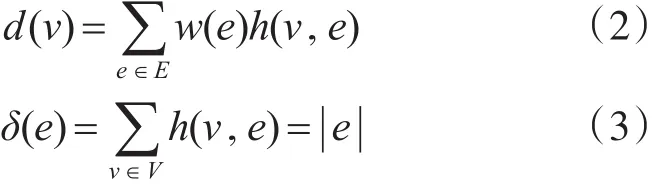
Dv和De分别代表超图中顶点和超边的度的对角矩阵,We是超边权重的对角矩阵。
3 基于超图的多文档新闻关键词抽取
定义超图H=(V,E,W)作为一个带有权重的超图。因为本文研究的内容是多文档下新闻关键词的抽取,因此一条超边表示一篇新闻文档。对于一篇新闻文档,首先进行中文分词、去除停用词,得到该文档的词集合。
传统的关键词提取方法是使用TF-IDF算法,该算法倾向于过滤掉常见的词语,保留重要的词语[10]。在这里,根据得到的词集合中每个词的TF-IDF值进行排序,取排名前20的词作为超图的顶点,并由这些词生成一条超边。即一篇新闻文档是由其中TF-IDF值最高的20个词来表示。
3.1 顶点权重计算
超图中的顶点代表新闻文档中的词,为了使关键词抽取的结果更加准确,为顶点设置权重。
本文中,超图顶点的权重由两部分组成,第一部分是顶点的tf-idf值,第二部分由顶点对应词的词性决定。词语的词性表示词语在句中的作用,根据句法规则,不同词性的词语重要程度往往不同。例如,名词通常表述一个实体概念,符合关键词反映文档主要内容的原则,因此新闻文档中的关键词多以名词为主。而连词、介词这样的虚词表述具体事物的能力较弱,几乎不可能成为关键词[11]。文章采用统计的方法,从网易新闻、腾讯新闻网站上随机选取了100个网页,通过人工的方式对其进行关键词提取,然后对这些关键词进行词性统计,词性特征权重如表1所示。
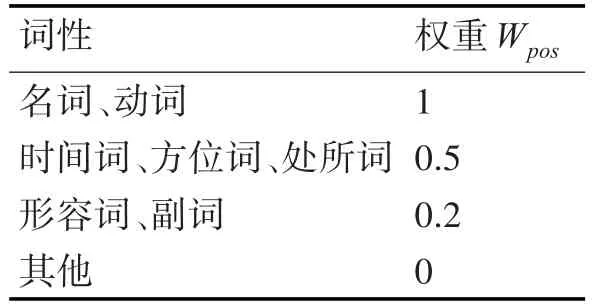
表1 词性与权重
则多文档新闻超图模型的顶点权值即可定义如下:
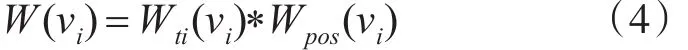
3.2 超边权重计算
3.2.1 时间因素
新闻是一个动态发展的过程,随着时间的推移,同一个事件往往会有新的内容被媒体挖掘出来。因此对于新闻事件来说,时间是一个很重要的因素,越新的新闻,在内容上就越真实、越详细。在本文定义的超图模型中,超边代表新闻文档,因此我们将时间作为超边权重的第一个因素,时间越新的新闻,其作为超边便拥有越高的权重。
本文定义的时间因素如下所示:

其中:c和p分别表示当前时间(current)和新闻发布时间(publication)。
Q是一个衰减率参数,取值介于0到1之间。当Q的取值接近0时,会使得排序更多的依赖于新发布的新闻;而当Q的取值接近1时,排序的结果则不怎么依赖新发布的新闻。本文中Q取值为0.5。
3.2.2 评论数因素
互联网上存在大量的新闻网站,这其中有的新闻网站具备足够的权威性,其发布的新闻往往经过很认真的考证,内容也真实可信。而有些网站不但权威性不足,为了吸引用户还恶意夸大新闻内容、制造噱头。对于这种网站的新闻,其关键词不但无法帮助用户了解新闻事件,有时甚至还会误导用户。
我们浏览了大量的新闻网站,发现权威的新闻网站有很多的用户,发布的新闻也有大量的用户评论。而权威性不足的网站,即便为了吸引用户而夸大新闻内容,却依然少有用户观看,其发布的新闻评论数也非常少。
因此,本文把评论数作为超边权重的第二个因素,评论数越多的新闻,说明发布该新闻的网站有着较高的权威性,所以相应代表这篇新闻的超边理应有着更高的权重。评论数权重公式定义如下:
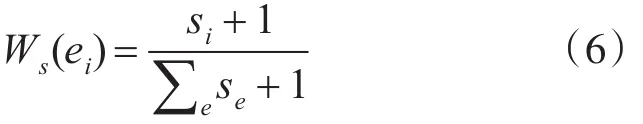
其中:si表示文档di下的评论数,∑ese表示文档集的总评论数。通常,为了避免文档评论数为0的情况,我们给每一个值都手工加上了1。
则多文档新闻超图模型的超边权值即可定义如下
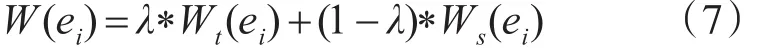
其中,λ是一个平滑参数,其取值介于0~1之间,用来权衡时间要素与评论数要素,在本文中,λ取值为0.5。
考虑新闻文档的时间因素与评论数因素并把其作为超边的权重,是为了反映新闻文档本身对关键词的重要性。在生活中,新闻内容常会随时间快速改变,而相应的关键词也会改变。传统的关键词提取算法仅仅考虑关键词在文章中的位置等因素,却忽略了文档本身的属性也可以影响关键词抽取的准确性。
3.3 随机游走
超图的超边可以包含多个顶点,其随机游走可以分成两步进行描述:
第一步:漫游者从当前所在的节点u,根据包含u的单条超边的权重与包含u的所有超边的权重之和的比值作为概率选择一条超边e;
第二步:漫游者从e上,以目标顶点v的权重和边e∈E(u)∩ E(v)中的所有顶点的权重之和的比值作为概率选择目标顶点v。
我们定义带权的超图的关联矩阵Hw如下:
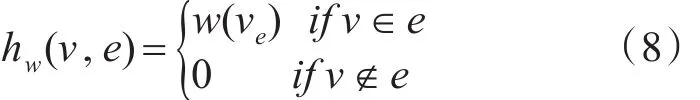
则带权超图中超边的度定义如下:
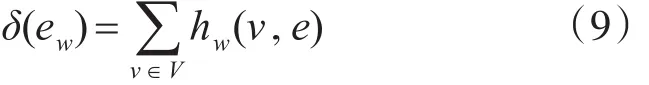
转移矩阵P定义如下:
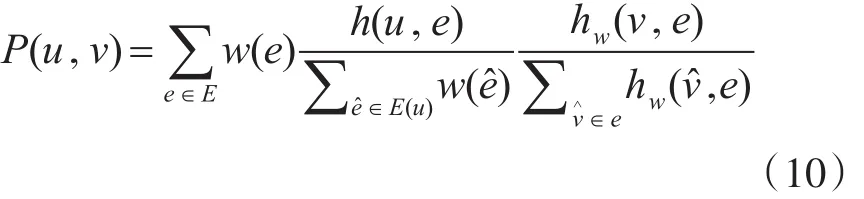
矩阵的表示形式如下:
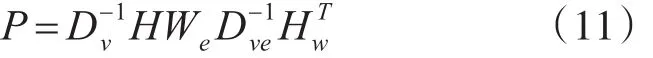
Dv是式(2)中顶点度的对角矩阵。We是超边权重的对角矩阵。 Dve是式(9)中超边度的对角矩阵。为了避免回路,本文把P当中的对角线元素置0,然后把P归一化,让每一行元素之和为1。
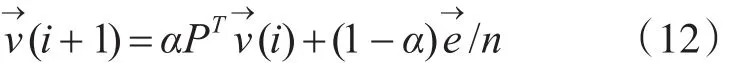
本文中,阻尼系数α的值为0.85,n是超图中顶点的个数。→e∈Rn*1是长度为n的单位向量。αPT→v表示漫游者从当前顶点u选择一条关联的超边进行跳转,(1-α)→e/n表示漫游者以(1-α)/n的概率跳转到一个新的顶点。
在PageRank随机游走的迭代过程中,当→v的值发生变化时,顶点的权重也相应变化,所以Dv、Dve、We和W 的值都会改变。在最开始,使用式(4)所得到的顶点权重作为初始值,通过顶点权重得到 Dv、Dve、We和W 的值,从而可以计算出P的值,然后进行初次迭代。迭代得到的值即词的权重向量,由此可以重新计算Dv、Dve、We和W ,继而再次得到P的值。反复迭代这一过程,直到相邻两次迭代和对应位置元素差值的绝对值小于本文设定的阈值(0.0001),此时停止迭代。然后取得分最高的K(本文中K取值为50)个词,作为最终提取的关键词。
4 实验与分析
4.1 数据集及评价标准
为了保证实验数据的随机抽样性,本次实验选择10个新闻事件,针对每一个新闻事件,从不同的新闻网站中选择10篇相关且不重复的新闻,总计10组共100篇新闻。针对每一组的10篇新闻,人工标注出该组新闻文档中的关键词,每一组共标注最多50个关键词。之后针对每一组的10篇新闻,利用本文提出的方法,从每一组当中提取出50个得分最高的词。
我们通过查准率、召回率和F值3项指标对关键词抽取的有效性进行评价。
查准率(Precision):是指人工抽取和自动抽取均判断为关键词的数目占整个自动抽取为关键词的比率,它反映关键词抽取系统准确抽取关键词的能力。
召回率(Recall)是指人工抽取和自动抽取均判断为关键词的数目占整个人工抽取关键词的比率,它反映关键词自动抽取系统发现关键词的能力。
F值(F-Measure)是查准率与召回率的调和平均值。
4.2 实验与分析
为了验证基于超图排序的关键词抽取方法的有效性,本文一共设计了两个实验,实验一验证新闻文档的时间要素与评论数要素对抽取结果的影响,实验二则是与其他抽取方法的对比实验。
实验一中,本文首先去掉时间要素与评论数要素,超边的权重计算采用基本的平均值方式,即超边的权重等于超边中所有顶点权重的平均值;之后再将超边权重的计算改为时间要素与评论数要素之和,对比这两次实验,结果如表2所示。
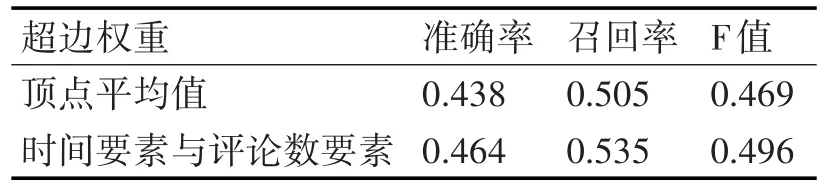
表2 超边权重对实验结果的影响
实验结果表明,以时间要素与评论数要素作为超边权重的方法要比传统的顶点权重平均值的方法更加优秀。
实验二中,本文选择了三种方法进行对比实验,这三种方法分别是TF-IDF、TextRank和WordRank。TextRank方法是基于传统图模型的关键词抽取方法;TopicSignatures方法在提取一篇新闻的关键词时,首先会将该新闻文档所在组中剩余的九篇新闻文档作为背景语料,然后基于这些语料来进行关键词的抽取[12]。评价结果如表3所示。
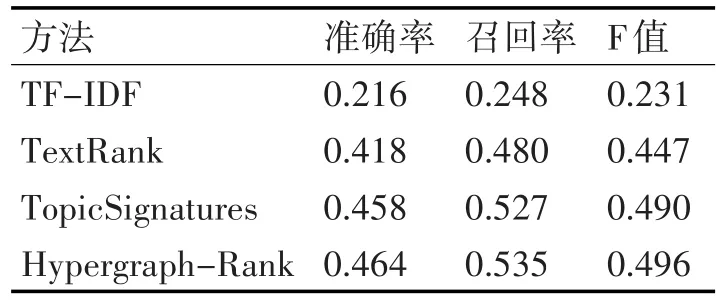
表3 对比实验结果
实验结果表明,相比基于传统图模型的Tex⁃tRank方法,超图模型因为能够表达词与文档、文档与文档的多元关系,在关键词抽取方面有了明显的提高;而相比于考虑背景语料的TopicSignatures方法,基于超图排序的方法因为考虑到了每篇新闻文档的时间要素与评论数要素,使得抽取结果也有了一定的提升。
5 结语
尽管超图的概念在很多年前就被提出,但直到近年来它才被应用于自然语言处理领域。超图是传统图的泛化,不同于传统图,超图可以表示更加复杂的关系,这个优点使得超图在关键词抽取中具有更好的效果。在本文中,我们提出了一种基于超图排序的多文档关键词抽取方法,并基于新闻文档的特性,设置了时间与评论数两种要素作为新闻文档的权重,实验结果证明了这种方法的有效性。我们的下一个工作将会考虑多语言环境下的关键词抽取。目前,在关键词抽取领域,超图的应用还不广泛,技术尚未成熟,但毫无疑问,基于超图的方法具有巨大的潜力。
[1]徐高.基于词跨度的网页关键词提取方法研究[D].湘潭:湘潭大学,2015.XU Gao.Method of Webpage Keyword Extraction Based on Word Span[D].Xiangtan:Xiangtan University,2015.
[2]王民.新闻文档关键词抽取技术研究[J].科技传播,2015,07:85-86,204.WANG Ming.Research on Keyword Extraction Technolo⁃gy in News Documents[J].Public Communication of Sci⁃ence&Technology,2015,07:85-86,204.
[3]Salton G,Buckley C.Term-weighting approaches in auto⁃matic text retrieval[J].Information processing&manage⁃ment,1988,24(5):513-523.
[4]Mihalcea R,Tarau P.TextRank:Bringing Order into Texts[J].Unt Scholarly Works,2004:404-411.
[5]索红光,刘玉树,曹淑英.一种基于词汇链的关键词抽取方法[J].中文信息学报,2006,06:25-30.SUO Hongguang,LIU Yushu,CAO Shuying.A Keyword Selection Method Based on Lexical Chains[J].Journal of Chinese Information Processing,2006,06:25-30.
[6]WITTEN I H,PAYNTER G W,FRANK E,et al.KEA:practical automatic keyphrase extraction[C]//Proceedings of the Fourth ACM Conference on Digital Libraries.ACM,s1999:254-255.
[7]吴振东.基于图模型聚类的文本摘要方法研究[D].杭州:浙江工商大学,2015.WU Zhendong.Research on Document Summarization Based on the Cluster of Graph[D].Hongzhou:Zhejiang Gongshang University,2015.
[8]翟周伟,刘刚,吕玉琴.基于图模型的关键词挖掘方法[J].软件,2012,08:9-13.ZHAI Zhouwei,LIU Gang,LV Yuqin.Keywords Mining Method Based on Graph Model[J].SOFTWARE,2012,08:9-13.
[9]徐杰.基于超图融合语义信息的图像场景分类方法[D].北京:北京交通大学,2014.XU Jie.A Hypergraph-based Semantic Information Fu⁃sion Method for Image Scene Classification[D].Beijing:Beijing Jiaotong University,2014.
[10]钱爱兵,江岚.基于改进TF-IDF的中文网页关键词抽取——以新闻网页为例[J].情报理论与实践,2008,06:945-950.QIAN Aibing,JIANG Lan.Keyword Extraction of Chi⁃nese Web Pages Based on Improved TF-IDF——Take the news page as an example[J].Theory&Application,2008,06:945-950.
[11]毛新武.基于组合特征的中文新闻网页关键词提取研究[D].北京:北京林业大学,2013.MAO Xinwu.Research on Keyword Extraction from Chi⁃nese News Web Pages based on Compose Features[D].Beijing:Beijing Forestry University,2013.
[12]Lin C Y,Hovy E.The automated acquisition of topic sig⁃natures for text summarization[C]//Proceedings of the 18th Conference on Computational Linguistics-Vol-ume 1.Association for Computational Linguistics,2000:495-501.
News Keyword Extraction in Multi-documents based on Hypergraph
FAN Zequan1LAI Hua2
(1.School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500)(2.Intelligent Information Processing Key Laboratory,Kunming University of Science and Technology,Kunming 650500)
As an important carrier of network information dissemination,the essence of the news is a continuous process aimed at reaching the truth.As time goes by,there will be a large number of different web pages for the same news event.How to quickly and accurately extract the key information of these news has become an increasingly important issue.Keywords as a brief summary of the article content,which can be used to quickly understand the news events,thus saving a lot of time,so keyword ex⁃traction technology is considered to be the key to solve this problem.Based on the analysis of the characteristics of news web pages,this paper proposes a new method for extracting multi-document keywords based on hypergraph model.This method takes words as nodes and news web pages as hyperedges,considering the factors of web-trust and the time of news,a hypergraph model of multi-news documents is established.Finally,the keywords are extracted by hypergraph ranking algorithm.The experimental re⁃sults verify the accuracy of the method.
multi-document hypergraph model,hypergraph ranking,random walk,keywords extraction,web-trust,time factor
Class Number TP391
TP391
10.3969/j.issn.1672-9722.2017.12.031
2017年6月13日,
2017年7月28日
范泽泉,男,硕士,研究方向:自然语言处理。赖华,男,副教授,研究方向:自然语言处理。
