基于联合模型的中文社交媒体命名实体识别∗
2018-01-04彭艳兵
易 黎 黄 鹏,2 彭艳兵 程 光
(1.南京烽火软件科技有限公司 南京 210019)(2.武汉邮电科学研究院 武汉 430074)(3.东南大学计算机科学与工程学院 南京 210096)
基于联合模型的中文社交媒体命名实体识别∗
易 黎1黄 鹏1,2彭艳兵1程 光3
(1.南京烽火软件科技有限公司 南京 210019)(2.武汉邮电科学研究院 武汉 430074)(3.东南大学计算机科学与工程学院 南京 210096)
随着互联网的发展,对中文社交媒体中命名实体进行识别具有重要的意义,传统的做法是采用监督学习方法,局限于标注数据的稀缺。然而,通用领域中有足够的语料库且社交媒体中的海量未标注的文本可以用于提高命名实体识别的效果。论文提出了一个联合模型,利用通用领域语料库和社交网络领域中未标注的文本进行训练。该联合模型由两个模型组成,一个是跨领域学习模型另外一个是半监督学习模型。跨领域学习基于领域的相似性学习通用领域的信息。半监督学习通过主动学习目标域内未标注的信息。该联合模型提高了命名实体识别的效果,且大大减小了人工标注语料工作。
命名实体识别;社交媒体;跨领域学习;领域相似性;半监督学习;主动学习
1 引言
命名实体识别是自然语言处理的一项基础任务,命名实体识别是指对文本中的命名实体进行识别、筛选并加以分类,命名实体包括五种类型:人名、主题、机构名、专有名词和地名。命名实体识别已广泛用于各种智能应用,例如信息抽取、信息检索、问答系统和机器翻译等。越来越多的人关注命名实体识别在社交媒体上的应用,通过前人的不断努力使得英文社交媒体的命名实体识别效果缩小了和传统领域的差距,但由于社交媒体的不规范和噪音多使得对其命名实体的识别非常困难。Peng和Dredze利用条件随机场对中文社交媒体的命名实体进行识别,局限于小量的标注数据采用监督学习的方法[1],但需要大量的人工标注工作。本文用深度学习的方法来训练领域外语料库和社交媒体中未标注的文本。
本文提出了一个联合的模型,该模型从领域外语料库和社交媒体中未标注的文本中训练。联合模型包含两个功能。一个是跨领域学习,另外一个是半监督学习。该模型可以调整每个句子深度学习的学习率。
对于跨领域学习,Sun,Kashima和Ueda等人运用不同领域的相似度,提出了一种多任务学习模型,从真实的文本数据中自动发现任务之间的相似关系[2]。他们通过测量不同任务权重的相似度来迭代学习任务的相关性,且收敛分析表明结果合理的收敛性。本文的跨领域学习模型基于域的相似度学习通用领域信息,使用领域外句子和社交网络域内语料库之间的相似度来调整域外语料库中每个句子的学习率。
对于半监督学习,以前的许多工作都集中于预测置信度上。本文设计了一个基于半监督的置信度模型,该模型可以通过自我训练来识别域内未标注的命名实体。
2 相关工作
本文通过深度学习的跨领域学习和半监督学习对中文社交媒体命名实体进行识别,下面就简要地介绍一下中文社交媒体的命名实体识别,跨领域学习和半监督学习。
2.1 中文社交媒体的命名实体识别
本文是对中文社交媒体文本中人名、机构名和地名命名实体进行识别。单个实体指的是文本中的一个名称或名词。对于单个命名实体的识别的主要方法是将其作为一个序列标记的任务[3]。由于社交媒体文本的不规范和噪音多对其中的命名实体识别具有挑战。例如,中文社交媒体文本中有许多缩写和错别字。此外,中文文本没有类似英文中明确的边界标示符。但该任务具有的挑战性和实用性,引起人们越来越多兴趣。例如,Peng和Dredze研究了几种映射的方法并提出基于词向量模型的命名实体识别[4];乔维和姜维等使用分词的方法来改善对命名实体的识别[5~6]。
2.2 跨领域学习
跨领域学习[7]需要利用辅助领域语料库来帮助改善社交媒体命名实体识别。以下几点是跨领域学习需要引起重视的原因。首先,每个领域都很难获取足够的标注文本,因为人工标注需要花费很多人力和时间。第二,可能不知道测试数据所属的领域,所以必须考虑域的自适应性。在许多自然语言处理任务中,如果没有设计合适的跨领域学习方法,用不同领域的数据进行测试时结果会大幅下降,幸运的是,有很多开创性的工作。例如,通过提取跨领域特征的方法来改善多领域适应性问题,通过训练多个领域的数据改善域的适应性。使用高斯核函数和多项式核函数计算任务的相似度,用余弦相似度来度量不同领域自适应的相似性[8~12]。
2.3 半监督学习
在许多自然语言处理任务中,标注的文本是小量的且有限的,然而海量文本是未经标注的。手动标注将花费大量的时间和人力,所以重点是探索一种如何利用未标注数据进行自然语言处理的方法。很多半监督和无监督的模型都可以利用。例如,通过 self-training,co-training,tri-training算法选择最可靠的训练数据。有人基于self-training算法的置信度来选择合适的训练数据;有的使用两种模型选取置信度来对未标注的句子训练。有人对原始领域未标注的数据进行训练来选取较高的置信度。有人使用两种分类器来选择最大置信度区间。还有的人评估可靠性的预测并选择最可靠的预测。
3 模型及理论
首先建立一个双向的长短期记忆网络(bidi⁃rectional long short term memory neural network,BILSTM),并结合转移概率形成最大间距的神经网络(max margin neural network,MMNN)结构输出模型作为基本模型。然后提出了对中文社交媒体的跨领域和半监督联合模型来进行命名实体识别。在介绍联合模型之前本文将系统的介绍跨领域学习模型和半监督学习模型。
3.1 BILSTM-MMNN
3.1.1 转移概率
本文将转移概率应用于BILSTM-MMNN并作为基本模型。最大间距准则直接影响模型决策边界的鲁棒性,这也使得扩展到统一模型上更加容易。
定义结构化的间距损失函数:
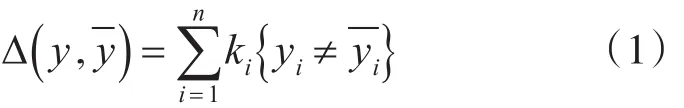
其中k是损失率
对于一个给定的句子序列x,预测最高得分的标签序列为
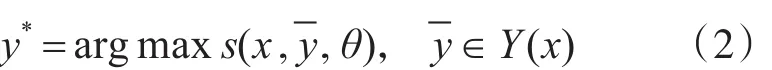

结合转移概率,我们将得分函数写成如下形式:

其中 f∧(ti|x)表示句子x中ti在参数∧的概率,A表示转移概率矩阵,n表示句子x的长度。 f∧(ti|x)的计算公式如下
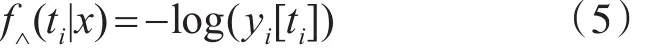
3.1.2 字向量和位置向量
词分割对中文文本处理非常的重要[1,3]。Peng和Dredze研究了三种向量的方法对中文社交媒体文本中命名实体的识别,分别是词向量、字向量和字的位置向量[4]。结果表明字的位置向量得到最好的结果。因此本文的模型中选择了字的位置向量。对于字的位置向量,它基于字向量同时也考虑了字的上下文,需要分割词来获得字的位置。
3.2 跨领域学习模型
由于社交媒体领域语料库和辅助领域语料库存在差异,因此需要确定辅助领域的句子与社交媒体领域语料库的相似度。对于跨领域学习,本文直接对社交媒体领域和辅助领域的数据进行训练。但是,对于不同领域的句子需要使用不同的学习率。因此,学习率用相似度函数自动调整。输入句子x的学习率的计算公式如下

其中α0是社交媒体领域内句子固定的学习率,func( )x,IN 表示域内语料IN和句子x的相似度,取值范围0~1之间。
在本文的模型中,考虑了三个不同的函数来计算相似度,分别为交叉熵、高斯核函数和多项式核函数。
交叉熵考虑的是句子 x=w1…wn和域内n-gram语言模型之间的关系[14]。交叉熵的相似度计算如下
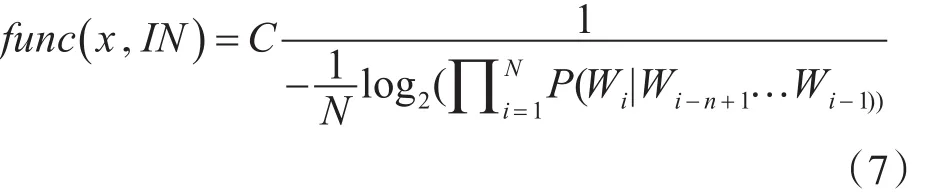
其中C是用于调整相似度的常数。
高斯核函数计算相似度的公式如下所示
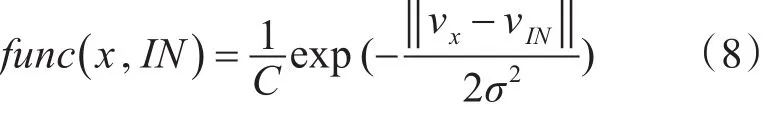
其中C是调整相似度的常数,σ是高斯核函数的方差,vIN和vx分别表示域内数据IN和句子x的词向量,首先使用了word2vec来对大量未注释的社交媒体的文本进行训练并获取每个字的位置向量。句子向量是句子中字向量的平均值。语料库矢量是语料库中句子向量的平均值。
多项式核函数相似度计算公式如下所示:

常数C,向量vIN和vx同高斯核函数定义一样。如果d=1,则多项式核函数为cosθ,其中θ是向量vIN和vx在欧式空间的夹角。
3.3 半监督学习模型
由于手动标注需要花费大量的时间和人力,因此需要尝试利用未标注的文本来帮助解决命名实体识别的训练数据。半监督学习方法的主要目的是在未标注的文本中选取最大置信度预测[15]。本文提出了一种基于句子置信度的半监督学习模型,该模型基于BLSTM-MMNN算法判定决策边界。因此,模型中句子的置信度是基于决策边界的。本文中预测指的是具有最高的得分的标签序列,其得分大于其它可能的标签序列得分。对于句子x,预测最高得分的标签序列由式(2)知:

第二高得分的标签序列为

因此句子的置信度定义如下:
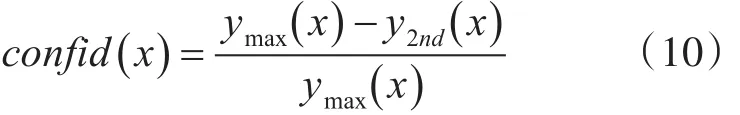
由式(10)可知在最高得分序列的决策间距是否大于第二高得分的序列,这样预测将更加准确。
由上式可知本文的半监督学习函数是动态的,因为每次迭代之前都需要计算每个句子的置信度。根据置信度公式可知句子的置信度在不同在迭代次数时不同。在t次迭代时未标注的句子x的学习率计算如下

其中at0表示在t次迭代域内句子的学习率,
confid(x ,t)在t次迭代时句子x的置信度。
3.4 联合模型
在本文的统一模型中,在t次迭代后每个句子x的学习率αt()x计算公式如下
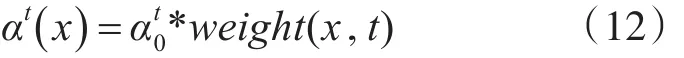
其中权重weight(x,t)是用于调整句子 x的学习率,权重weight( )x,t定义公式如下
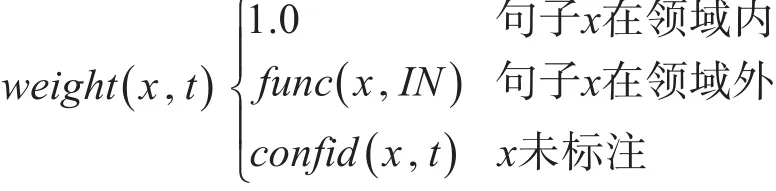
其中func(x ,IN ) 表示领域外句子x和域内语料库IN之间的相似度,confid(x ,t)是在t次迭代未标注句子x的置信度。
4 实验结果及分析
为了证明本文模型的有效性,我们在数据集上进行了命名实体识别实验。
4.1 数据集
用于域内的命名实体识别语料库由标注的新浪微博信息组成。该语料库包含人名,机构名,专有名词,地名的名称和名词。对于领域外语料库,使用第六届SIGHAN研讨会上进行中文处理的MSR语料库。SIGHAN语料库包含人名、机构名和地名三种类型命名实体,是使用中文社交媒体未标注的文本从新浪微博爬取的,而且文本用中文字的分词系统Jieba进行分词。详细的微博命名实体识别语料库如图表2所示,对于SIGHAN语料库详细信息见表3。
4.2 基线数据分析
本文构建了两个基线,与提出的联合模型进行比较。第一个是在微博语料库中训练和测试的BiLSTM-MMNN模型。第二个是对辅助领域数据进行预训练,然后对微博数据进行训练。为了方便起见,使用BiLSTM-MMNN,BILSTM-MMNN+辅助领域和域内数据合并训练来表示两个基线。
4.3 参数设置
预训练嵌入词向量采用了word2vec中的skip-Gram模型。没有负采样,其它采用默认设置。本文使用bigram特征:CnCn+1(n =-2,-1,0,1)andC-1C1。使用窗口方法从词特征向量中提取较高级别的特征。模型训练使用引入L2正则的随机梯度下降法。对于模型中的参数,词向量的窗口大小为5。词向量维度、特征向量维度和隐藏向量维度均为100。k损失率为0.2,并且超参数L2为0.000001,对于学习率,默认学习率α0为0.1衰减率为0.95。在统一模型中设置学习率α0=0.05,并且在BILSTM-MMNN+所有数据合并模型中α0=0.003。进行了10次迭代训练并选择最佳预测用于测试。
4.4 结果及分析
表1显示了在命名实体识别任务中对命名实体和名词识别准确率、召回率、F1值,考虑了未登录词的召回率。可看出跨领域和半监督学习改善了命名实体识别,联合模型效果明显,还可以看出外领域数据有助于改善未登录词的召回率。

表1 在测试数据中命名实体和名词的识别结果
对于跨域学习,对三个相似度函数进行实验:交叉熵,高斯核函数,和多项式核函数。对于所有的相似度函数,设置调整幅度常数C=1。对于交叉熵,使用tri-gram语言模型,对于高斯核函数设置方差σ=1,对于多项式核函数,尝试对d取不同的值发现当d=1时在命名实体识别任务中效果显著。通过比较三个相似度函数,发现多项式核函数在d=1时取得最好的结果,因此多项式核函数选择在d=1作为跨域学习函数的相似度计算。因为数据集SIGHAN中只包含名称,模型在名称识别中有很大的提高,但在名词识别却改善不大,后期处理结合跨领域学习函数和基于BiLSTM-MMNN模型的结果。该过程将保持对BiLSTM-MMNN对名词识别的预测,再用跨领域学习模型来调整名称实体预测。名称和名词实体处理前和处理后的F1值如表4所示。

图1 未标注数据是标注数据不同倍数时的F1值

表2 详细的微博命名实体识别语料

表3 SIGHAN命名实体识别语料

表4 处理前和处理后结果的对比
对于中文社交媒体文本中海量的未标注的句子和标注的句子有很大的不同。首先选择具有最高相似度的句子。为了避免选定的句子没有实体,使用基本模型来测试并选择具有/不具有实体句子的比例。图一表示未标注数据是标注数据不同倍数下的F1值,可以看出随着未标注数据的增多改善了F1值,但并不是未标注数据越多越好,实验发现当倍数为5时效果最好。因为每次迭代之前需要预测未标注的句子,使用了预训练BiL⁃STM-MMNN模型的参数来初始化我们半监督学习函数中的参数。
因为统一模型使用SIGHAN语料库,它也面临跨域学习函数相同的问题,使用相同的后续过程结合联合模型和半监督学习的结果。因为联合模型可以利用领域外的数据和域内未标注的数据,而半监督学习需要未标注的数据。基于半监督学习函数的预测建立联合模型,为了显示联合模型的优势,我们比较了原始跨域学习函数和统一模型,结果如表5所示。

表5 跨领域模型和联合模型实验结果的比较
5 结语
本文提出了中文社交媒体命名实体识别的联合模型,并对跨领域学习模型和半监督学习模型进行详细阐述。基于相似度可以从领域外语料库学习域外信息,基于半监督的置信度模型,该模型通过自我学习来训练域内未标注的文本。该模型大大减小了标注语料且实验表明该模型改善了中文社交媒体的命名实体识别的效果。
[1]Peng N,Dredze M.Improving Named Entity Recognition for Chinese Social Media with Word Segmentation Repre⁃sentation Learning[C]//Meeting of the Association for Computational Linguistics,2016:149-155.
[2]Sun X,Kashima H Ueda N.Large-Scale Personalized Hu⁃man Activity Recognition Using Online Multitask Leaning[J].IEEE Transactions on Knowledge and data Engineer⁃ing,2013,25(11):2551-2563.
[3]汤步洲.序列标注问题的监督学习方法及应用[D].哈尔滨:哈尔滨工业大学,2011.TANG Buzhou.Squence Labeling:Supervised Learning and Applications[D].Harbin:Harbin Institute of Technol⁃ogy,2011.
[4]Peng N,Dredze M.Named Entity Recognition for Chinese Social Media with Jointly Trained Embeddings[C]//Con⁃ference on Empirical Methods in Natural Language Pro⁃cessing.Association for Computational Linguistics,2011:355-362.
[5]乔维,孙茂松.基于M~3N的中文分词与命名实体识别一体化[J].清华大学学报(自然科学版),2010(5):758-762,767.QIAO Wei,SUN Maosong.Joint Chinese word segmenta⁃tion and named entity recognition based on max-margin Markov networks[J].Journal of Tsinghua University(Sci⁃ence and Technology),2010(5):758-762,767.
[6]姜维.统计中文词法分析及其强化学习机制的研究[D].哈尔滨:哈尔滨工业大学,2007.JIANG Wei.Statistical Chinese Lexical Analysis and Its Reinforcement Learning Mechanism[D].Harbin:Harbin Institute of Technology,2007.
[7]黎航宇.跨领域、跨风格命名实体识别技术研究[D].北京:北京邮电大学,2015.LI Hangyu.Cross-Domain and cross-style Chinese Named Entity Recognition[D].Beijing:Beijing University of Posts and Telecommunications,2015.
[8]张洪刚,李焕.基于双向长短时记忆模型的中文分词方法[J].华南理工大学学报(自然科学版),2017,(3):61-67.ZHANG Honggang,LI Huan.Chinese Word Segmentation Method on the Basis of Bidirectional Long-Short Term Memory Model[J].Journal of South China University of Technology(Natural Science Edition),2017,(3):61-67.
[9]张英.基于深度神经网络的微博短文本情感分析研究[D].郑州:中原工学院,2017.ZHANG Ying.The Depath neural network For Microblog Short Text Sentiment Analysis Study[D].Zhengzhou:Zhongyuan University of Technology,2017.
[10]黄积杨.基于双向LSTMN神经网络的中文分词研究分析[D].南京:南京大学,2016.HUANG Jiyang.Chinese Word Segmentation Analysis based on Bidirectional LSTMN Recurrent Neural Network[D].Nanjing:Nan Jing University,2016.
[11]李剑风.融合外部知识的中文命名实体识别研究及其医疗领域应用[D].哈尔滨:哈尔滨工业大学,2016.LI Jianfeng.Research on Chinese name-d entity recogni⁃tion with external knowledge and application in medical field[D].Harbin:Harbin Institute of Technology,2016.
[12]Axelrod A,He X,Gao J.Domain adaptation via psudo in-domain data selection[C]//Conference on Empirical Methods in Natural Language Processing, 2015:548-554.
[13]王洪亮.基于词向量聚类的中文微博产品命名实体识别[J].兰州理工大学学报,2017(1):104-110.HUANG Hongliang.Named entity recognition of Chinese microblog product based on word-vector clustering[J].Journal of Lanzhou University of Technology,2017(1):104-110.
[14]Le J,Niu Z D.Chinese Named Entity Recognition Using Improved Bi-gram Model Based on Dynamic Program⁃ming[J].Knowledge Engineering and Management,2014:441-451.
[15]夏大伟.基于自训练的决策式依存句法分析技术的研究[D].沈阳:沈阳航空航天大学,2015.XIA Dawei.Transition-Based Dependency parser Com⁃bining With Self-Training[D].Shenyang:Shenyang Aerospace University,2015.
Named Entity Recognition in Chinese Social Media Base on the Unified Model
YI Li1HUANG Peng1,2PENG YANBING1CHENG Guang3
(1.Fiberhome Software Science and Technology Co.Ltd,Nanjing 210019)(2.Wuhan Research Institute of Posts and Telecommunications,Wuhan 430074)(3.Department of Computer Science and Engineering,Southeast University,Nanjing 210096)
Named Entity Recognition(NER)in Chinese social media is important with the development of the internet.Previ⁃ous methods focus on in-domain supervised learning which is limited by the rare annotated data.However,there are enough corpora in formal domains and massive in-domain unannotated texts which can be used to improve the task.A unified model which can learn from out-of-domain corpora and in-domain unannotated texts is proposed,the unified model contains two major functions,one is for cross-domain learning and the other is for semi-supervised learning.Cross-domain leaning function can learn out-of-domain in⁃formation based on domain similarity.Semi-Supervised learning function can learn in-domain unannotated information by self-train⁃ing.Both learning functions outperform existing methods for NER in Chinese social media.Used unified model to experiment get a better result and decrease the workload of manual tagged corpus.
named entity recognition,social media,cross domain leaning,domain similarity,semi-supervised learning,self-training
Class Number TP391
TP391
10.3969/j.issn.1672-9722.2017.12.017
2017年6月7日,
2017年7月10日
国家高技术研究发展计划(863计划)(编号:2015AA015603);国家自然科学基金项目(编号:61602114)资助。
易黎,女,硕士,中级工程师,研究方向:大数据分析。黄鹏,男,硕士研究生,研究方向:数据挖掘、自然语言处理。彭艳兵,男,博士,高级工程师,研究方向:移动嵌入式、网络安全。程光,男,博士,教授,研究方向:网络行为学。
