基于相对熵的数据流概念漂移检测算法
2018-01-03杨帆张永,2*
杨 帆 张 永,2*
1(辽宁师范大学计算机与信息技术学院 辽宁 大连 116081) 2(计算机软件新技术国家重点实验室(南京大学) 江苏 南京 210023)
基于相对熵的数据流概念漂移检测算法
杨 帆1张 永1,2*
1(辽宁师范大学计算机与信息技术学院 辽宁 大连 116081)2(计算机软件新技术国家重点实验室(南京大学) 江苏 南京 210023)
针对数据流中出现的概念漂移问题,采用决策树作为分类器,提出一种基于相对熵的数据流概念漂移检测算法。提出的算法将分类器的准确率与相对熵作为判断该数据块是否发生概念漂移的标准。通过5个数据集对该方法进行验证,该算法在其中4个数据集上都获得了最优的结果,在另一个数据集上获得了次优结果。实验结果表明采用该方法不仅能够有效地检测概念漂移的发生,而且还能提高分类器的准确率。
数据流 概念漂移 相对熵 决策树
0 引 言
数据流挖掘是当前数据挖掘领域的研究热点之一,已经成功地应用于诸多领域,如医学、金融分析、生物分析、股票分析、社交网络、市场营销等。数据流是由许多领域产生的具有实时性、未知性、海量性等特点的数据[1]。数据流的挖掘主要是通过在已经产生的数据流中挖掘有效的、有价值的潜在信息,从而预测未知的或即将到来的数据。数据流分析不仅给算法应用带来了时间和空间的挑战,而且为丰富数据挖掘理论和方法提供了新的可能。
如何高效地分类数据流是机器学习中一个重要的挑战。目前,数据流分类的主要模型有决策树、贝叶斯、BP神经网络、KNN、支持向量机等单分类器模型和多分类器模型[2-4]。但在实际应用中,数据流中隐含的一些知识或概念也可能随着环境变化和时间推移而发生改变,导致了概念漂移现象的发生[5]。
目前大多数的概念漂移检测仅仅以准确率与时间窗口大小为判断标准,很少考虑前后数据块概率分布的差异性。本文在准确率的基础之上,充分考虑了数据块间概率分布的差异性,提出了一种基于相对熵的数据流概念漂移检测算法。该算法通过计算相邻数据块间的相对熵来体现概率分布的差异性,同时本算法中的分类器只有在判断可能漂移或者是漂移的情况下才更新分类器模型,从而减少了内存占用。
1 相关工作
典型的学习方法,对于处理固定任务或者是分类概率不变的数据时,无需考虑实时更新分类器的问题。但是,对于数据流而言,当前输入的数据可能与前面数据间存在目标概念上的变化,这种变化引起了概念漂移现象。因此,在对数据流的分类过程中,为了适应概念漂移现象,必须不断更新分类模型。概念漂移现象通常体现为以下三种漂移形式[6-8]:渐进式漂移、突变式漂移与抽样变化(数据类分布变化)。
针对概念漂移现象,国内外学者已经提出了一些解决方案。例如,Hulten等[9]基于快速决策树(VFDT)提出了适应概念的快速决策树(CVFDT)方法,采用窗口大小固定的方式替换子树,并且周期性检查数据流中存在的概念漂移;Li等[10]提出了单类增量快速决策树(OCVFDT),对不同类型的概念漂移进行处理;Scholkopf等[11]提出了单类支持向量机(OCSVM),通过设置目标类(将多数类变成二分类)判断概念漂移情况;Bicego等[12]提出了加权的单类支持向量机(WOCSVM),采用设置权值的方式优化OCSVM; Krawczyk等[13]提出了增量式单类支持向量机(IOCSVM),在WOCSVM的基础之上加入了遗忘机制,处理带有概念漂移情况的数据流。
2 基于相对熵的概念漂移检测算法
2.1 相对熵
相对熵又称KL散度,是衡量两个概率分布差异的一种方法。通常用概率分布p来表示真实分布,q表示拟合真实分布。从信息论的角度看,相对熵表示用概率分布q来拟合真实分布p所产生的信息损耗。
对于一个随机变量X=(x1,x2,…,xn),用p(x)、q(x)分别代表取值为xi(i=1,2,…,n)时的两个随机变量的概率分布,则p对q的相对熵可描述为:

(1)
相对熵具有两个性质:(1) 非负性,即D(p‖q)≥0;(2) 不对称性,即D(p‖q)≠D(q‖p)。
根据式(1)易知,对于一个稳定、有序的数据流而言,前后相邻数据块的相对熵值非常小。但是对于非平稳、无序的数据流而言,相对熵的值则会增大。若两个概率分布完全相同,则相对熵值为0。
综上所述:相对熵非常适合判断数据流的概念漂移;若数据流中出现了非平稳、无序的概率分布,相对熵会增大,则数据流发生了概念漂移;若数据流处于相对平稳的分布状态,相对熵的值会非常小甚至接近于0,则没有发生概念漂移。
2.2 算法思想
针对数据流产生的概念漂移问题,本文提出了一种基于相对熵的概念漂移检测方法。很多研究者在对数据流中概念漂移检测时,将分类器分类的准确率作为判断概念漂移的标准,很少考虑数据块间的概率分布变化。而本文提出的算法从准确率和相对熵两个方面来判断数据流中是否产生了概念漂移现象。
本文提出算法的主要思想如下:首先,对第一块数据进行初始化,创建决策树模型;其次,用上一块的分类器模型作为当前块的分类器,根据式(1)求得对应的叶子节点的相对熵;再次,对求得的当前块的准确率与相对熵设置置信区间,进而判断当前块是否发生概念漂移。判断结果有三种情况[10]:(1) 明确发生概念漂移;(2) 可能发生概念漂移;(3) 没有发生概念漂移。最后,对可能发生漂移与确定发生概念漂移的当前块重新训练分类器。
在创建决策树模型时,根据信息增益率,即信息增益与分裂信息量的比值,求得具有最大价值的属性作为根节点,以此类推递归创建决策树。当数据块较大时,决策树分类易产生过拟合现象。因此,对决策树进行适当剪枝,以减少分类的误分类率。
算法首先对第一个数据块进行训练,建立决策树cptree1。用cptree1测试下一个block,求出相对熵KL与准确率ACCi值,与置信区间进行比较。如果没有发生漂移,则继续测试一个block。若发生漂移或者可能漂移的情况,对当前数据块的大小折半用当前分类器进行测试,求得相对熵KL与准确率right_rate,若仍然存在漂移或者可能漂移的情况,则判断为漂移或者可能漂移,产生漂移情况说明数据发生了类别或属性动态的变化。更新分类器,测试下一个数据块。
2.3 基于相对熵的概念漂移检测算法
基于上述思想,本文提出了基于相对熵的概念漂移检测算法KLDT,将分类器的分类准确率与相对熵的值作为概念漂移的评判标准,如下算法所示。
算法:基于相对熵的概念漂移检测算法KLDT
输入:数据流S
输出:输出概念漂移数据块
步骤1初始化:
选取S1个样本作为训练样本;
构建决策树ctree1;
对ctree1剪枝生成cpree1,Tcurr=cpree1;
得出准确率Acci;
步骤2对连续到达的数据块Si(i∈2,…,n):
用Tcurr对Si进行预测
计算Si的准确率Acci;
根据式(1)计算Si与Si-1的相对熵D(pi-1‖pi);
进行KS检验
对Acci与D(pi-1‖pi)进行KS检验,得到H0;
对结果进行判断;
若Acci与D(pi-1‖pi)的KS检验中H0同时为1,则判断为产生漂移,用Si重新训练分类器模型,得到Tcurr,返回步骤2;
否则,返回步骤2。
3 实验结果与分析
本文采用的数据集为使用MOA合成的数据集。MOA是一个用于在线数据流学习的开源环境,许多研究者都是用MOA作为数据生成器。数据集情况如表1所示,共包括5个数据集:SEA[9]数据集、HyperPlane数据集、RBF数据集、LED数据集、ELEC数据集。其中SEA数据集噪声取10%,RBF的质心数量取50,LED数据集噪声取10%,HyperPlane数据集噪声取5%,选择了一个真实数据集ELEC数据集,ELEC是通过电力市场中电价的变化反映市场供应问题。
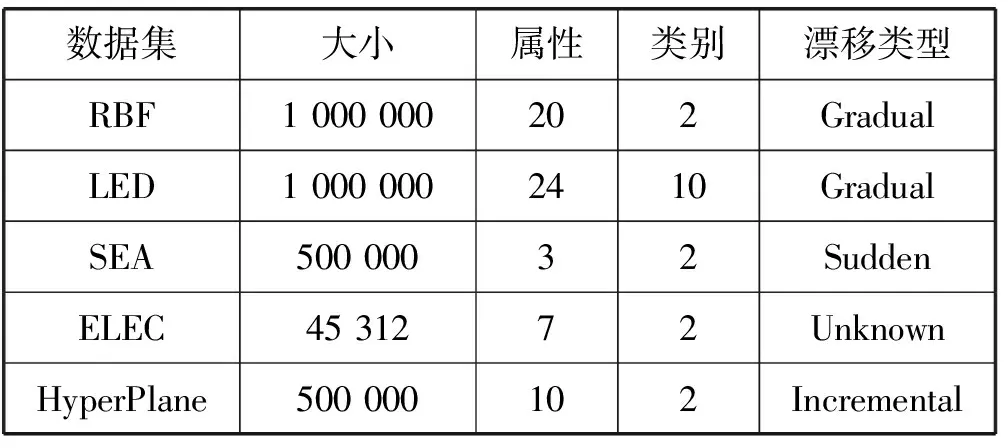
表1 实验数据集
为了验证本文提出算法KLDT的有效性,分别与OCVFDT[10]、IOCSVM[13]、WOCSVM[12]算法进行了对比。OCVFDT通过设置目标类来区分是否发生了概念漂移。IOCSVM通过对数据块设置权值,随着数据块的不断增加对权值添加遗忘机制,最后判断概念漂移情况。WOCSVM通过对训练数据设置权值,进而对未知数据和未知异常数据进行检测进而判断概念漂移。
在进行对实验中,每个数据块的大小均取2 500。KLDT算法以准确率与相对熵为判断标准。本实验由于每个数据集的性质以及属性不同,所以将决策树作为分类器对每个数据集进行分类的准确率大有不同。实验结果如表2所示。
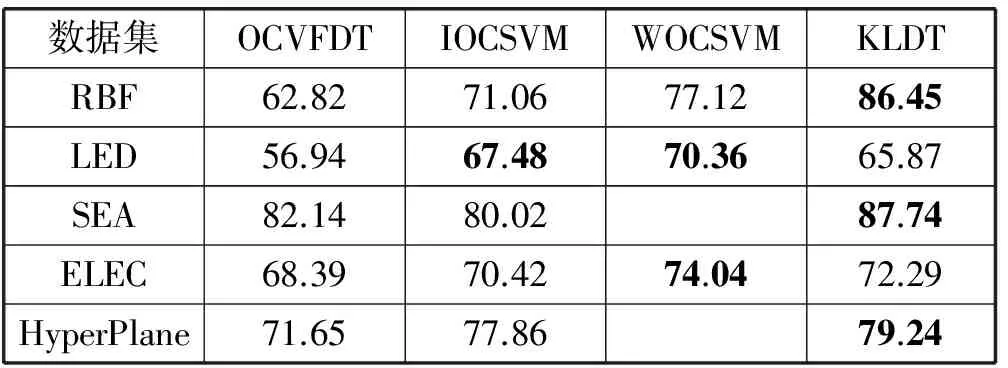
表2 不同算法准确率对比 %
根据表2可以看出,本实验的准确率相比OCVFDT算法准确率均有很大的提升;相比IOCVFDT算法在LED数据集的准确率并没有提高;相比WOCSVM算法而言,在LED与ELEC数据集的准确率略低。
为了使该方法更具有泛化性,本文进行了数次实验。其中数据块的大小分别设为100、200、500、1 000、1 500、2 000、2 500和5 000。实验结果如表3所示。

表3 不同块大小的准确率 %
根据表3可以看出,在RBF、LED、SEA、HyperPlane数据集上,当数据块大小为5 000时,提出的算法获得了最优准确率。只有当ELEC数据集在数据块为100时准确率最高,而在数据块为5 000时却是次优解。具体情况如图1-图5所示。

图1 RBF数据集的准确率

图2 LED数据集的准确率

图3 SEA数据集的准确率
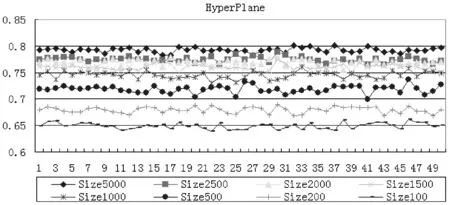
图4 HyperPlane数据集的准确率

图5 ELEC数据集的准确率
图1-图5可以看出准确率的波动并不是非常大,主要是因为若产生概念漂移或者是确定发生概念漂移,分类器都得到了及时的更新。根据图1-图5不同块大小的准确率,可以看出当数据块大小为5 000个数据时准确率特别的高,而数据块大小为100个数据时具有最低的准确率。当数据块较小时对概念漂移比较敏感,所以准确率较低,而当数据块相对较大时,对概念漂移不是特别敏感,则准确率相对较高。相反的是,图3所示的准确率在数据块相对较小时,具有较高的准确率。表2中当数据块为2 500个数据时的准确率相比WOCSVM较低,当数据块大小取500、200、100个数据时则高出WOCSVM算法的准确率。
4 结 语
本文提出了一种基于相对熵的数据流概念漂移检测算法。本文将决策树作为分类器,根据判定条件不断地更新分类器。相比增量式学习减少了内存的使用。在判定条件中并不是单一地选择准确率,而是增加了相对熵。根据相对熵的非负性和非对称性的性质,可以判定相对熵适用于检测数据流中存在的概念漂移问题。然而,本文的算法还有不足的地方,并不能同时适应多种概念漂移特征,快速、准确地检测数据流中概念漂移的问题仍然是今后研究的重点。
[1] 丁剑,韩萌,李娟.概念漂移数据流挖掘算法综述[J].计算机科学,2016,43(12):24-29.
[2] Lomax S,Vadera S A.Survey of cost-sensitive decision tree induction algorithms[J].ACM Computing Surveys,2013,45(2):1-35.
[3] Song G,Ye Y,Zhang H,et al.Dynamic Clustering Forest:An ensemble framework to efficiently classify textual data stream with concept drift[J].Information Sciences,2016,357:125-143.
[4] Marseguerra M.Early detection of gradual concept drifts by text categorization and Support Vector Machine techniques:The TRIO algorithm[J].Reliability Engineering and System Safety,2014,129:1-9.
[5] 王涛,李舟军,颜跃进,等.数据流挖掘分类综述[J].计算机研究与发展,2007,44(11):1809-1815.
[6] 李培培.数据流中概念漂移检测与分类方法研究[D].合肥:合肥工业大学,2012.
[7] Wu X D,Li P P,Hu X G.Learning from concept drifting data streams with unlabeled data[J].Neurocomputing,2012,92:145-155.
[8] 姚远.海量动态数据流分类方法研究[D].大连:大连理工大学,2013.
[9] Hulten G,Spencer L,Domingos P.Mining time-changing data streams[C]//Proceedings of the seventh ACM SIGKDD international conference on knowledge discovery and data mining,2001:97-106.
[10] Li C,Zhang Y,Li X.One-class very fast decision tree for one-class classification of data streams[C]//Proceedings of the Third International Workshop on Knowledge Discovery from Sensor Data,2009:79-86.
[11] Scholkopf B,Smola A J.Learning with kernels:support vector machines regularization and beyond[M].MIT Press,2001.
[12] Bicego M,Figueiredo M A T.Soft clustering using weighted one-class support vector machines[J].Pattern Recognition,2009,42(1):27-32.
[13] Krawczyk B,Wozniak M.Incremental one-class bagging for streaming and evolving big data[C]//Proceedings of the 2015 IEEE BigDataSE,2015:193-198.
ADATAFLOWCONCEPTUALDRIFTDETECTIONALGORITHMBASEDONRELATIVEENTROPY
Yang Fan1Zhang Yong1,2*
1(SchoolofComputerandInformationTechnology,LiaoningNormalUniversity,Dalian116081,Liaoning,China)2(StateKeyLabforNovelSoftwareTechnology,NanjingUniversity,Nanjing210023,Jiangsu,China)
Aiming at the problem of concept drift in data stream, this paper proposed a conceptual drift detection algorithm based on relative entropy based on decision tree as a classifier. The proposed algorithm combined the accuracy and relative entropy of the classifier as a criterion for judging whether the data block was drilled or not. The method was verified by 5 data sets. The algorithm obtained the optimal result on the four data sets, and the suboptimal result was obtained on the other data set. The experimental results showed that this method not only detected the occurrence of concept drift effectively, but also improved the accuracy of the classifier.
Data stream Concept drift Relative entropy Decision tree
2016-12-17。国家自然科学基金面上项目(61373127)。杨帆,硕士生,主研领域:机器学习。张永,副教授。
TP311
A
10.3969/j.issn.1000-386x.2017.12.049
