基于卷积神经网络的自然背景字符识别
2018-01-03彭志文
郁 松 彭志文
(中南大学软件学院 湖南 长沙 410075)
基于卷积神经网络的自然背景字符识别
郁 松 彭志文
(中南大学软件学院 湖南 长沙 410075)
随着计算机视觉技术的发展,自然背景中字符的识别在图片检索、视频检索、无人车识别周围场景信息等领域都扮演了不可或缺的角色。相对于手写字符、打印字符的识别,自然背景字符的识别有着光照强度变化大、背景纹理复杂、字体样式和颜色多变等特点,这都给识别带来了巨大的挑战。主要是基于LeNet-5的网络结构设计了一种适合于识别自然背景字符的卷积神经网络,由于在这一领域以往的研究工作的基准数据集是较小的数据集(Chars74K-15),为了便于比较,实验也是基于同样的数据集。但因为卷积神经网络是在巨大数据量的驱动下才会有良好的效果,因此还提出了一种预处理方式和fine-tune相结合用于解决自然背景字符图片数据量较小的问题。
自然背景字符识别 卷积神经网络 图像分类
0 引 言
在计算机视觉领域,许多问题都得到了良好的解决,比如人脸检测和手写字符的识别。尽管目前存在很多有用的方法和应用来解决文本的识别,例如已经运用于商业的产品OCR[1]在扫描文本的识别中取得了巨大的成功。由于字体、光照、背景、视角等较为复杂的外部因素的影响,自然背景文本的识别依然存在着很多挑战和待解决的问题。这一研究内容主要包括文本的检测和定位、字符的分割和字符的识别。本文的主要研究工作是对于字符的识别。
目前对于解决这一问题的方法主要分为2大类[2]:基于区域聚合的方法和目标识别的方法。基于区域聚合的方法[1,3]主要应用了二值化和图像分割,所以这些方法运行较快,但是在低分辨率或者存在噪声的情况下并不适用。而基于目标识别的方法[15]是将自然背景下字符的识别当做一般的图像分类任务来进行处理,一般步骤就是从图片中提取特征来训练分类器,并完成分类任务,这需要大量的经验知识和设计恰当的特征。第二种方法的使用较为普遍。
很多字符特征的提取方法被证明在用于提高字符识别准确率上具有良好的效果。这些方法主要可以分为基于先验知识人工设计的特征和基于深度学习自动提取的特征。方向梯度直方图(HOG)特征在物体检测中是很有效的,并且也被广泛使用,因此也被[4-5]用来表示自然场景中字符的特征。一些方法认为可以通过考虑图像的空间与结构信息来提高HOG特征的效果,Epshtein[6]提出了用邻近区域的梯度方向分布代替单一的梯度方向。Yi等[5]基于HOG提出了全局采样的GHOG,能够对字符结构进行更好的建模。Shi等[7]提出了基于局部区域的树状特征,这个特征原本是用来进行人脸检测,文献[7]的方法中用来表示字符特征。Lee等[2]认为如果将输入图像分割成相等大小的区域,并且在每一个子区域提取方向梯度信息,但并不是每一个子区域都包含有效信息,因此提出了一种方法:首先提取随机区域内的10种不同特征,随后使用SVM进行训练,得到这10种特征对于字符识别的影响权重,然后取权重最大的前K个特征作为字符的特征。
以往的研究大多是基于人工设计的特征,设计这些特征需要良好的先验知识,而且不一定适用于所有的自然背景的情况。因此本文针对以上问题基于LeNet-5[10]进行了改进,该CNN模型可以有效提取自然背景下字符的特征。主要的改进方面是增加了卷积层和卷积核的数量,这是因为LeNet-5只是识别手写数字,而自然背景的字符识别需要识别62个种类,因此需要学习更多的特征。并且将sigmoid激活函数改为了ReLu(Rectified Linear Units),这样减少了训练的收敛时间[11]。还在某些层增加了dropout[11],这是为了保证特征的稀疏性。输入图片增加了感兴趣区域提取和二值化等预处理过程,使该卷积神经网络结构可以适应训练数据较小的情况,并且通过实验结果说明了数据扩充的可行性。然后在数据扩充的方法之上训练出最终的CNN模型用于自然背景字符的分类。
1 CNN总体框架和所采用的方法
本节主要是说明了数据集和经过实验得出的最佳的CNN整体结构,还描述了提出的2种数据处理的方法:基于直方图和grabcut的数据预处理和数据扩充。预处理是为了应对数据量较小的情况并且验证数据扩充的可行性。数据扩充是为了提升最终训练所得到模型的识别准确率,也为数据量较小的情况下提供了一定的解决思路。
1.1 数据集说明
本文研究内容所使用的数据集是Chars74K[12],该数据集包括64类字符,其中包括英文字母(A-Z,a-z)和阿拉伯数字(0~9),总共74 000张左右。但是自然背景下的字符只有12 503张,其中4 798张图片较为模糊,其余的图片是手写字符(3 410张)和根据电脑的字体合成的字符(62 992张),图1从这3类数据中各选了9张作为示意。
图1 从左往右依次是自然背景字符、手写字符、电脑合成字符
在自然背景图片这一子数据集中,每一类字符的分布并不是均匀的,以往基于这个数据集的研究工作[5,8-9]都倾向于使用Chars74K-15,即每一类有15个训练样本和15个测试样本,总共1 860张图片。为了方便比较实验结果,本文的实验内容也同样是基于Chars74K-15。
若是直接基于930张训练图片来训练本文所设计的卷积神经网络,则效果不理想,在测试集上只有44%的准确率。这是因为和基于手工设计的特征不同,CNN是通过大量的训练数据来学习特征的,而较少数据量时不容易达到好的效果,但是在具有大量数据的条件之下,CNN相对于手工设计的特征可以提取到更为准确的特征而到达更好的分类效果。一些方法,比如文献[8]用了12 000张自然背景字符图片做为训练集,文献[13]用了2 200 000张带标签的训练数据集。然而得到如此规模的数据集是比较困难的。因此本文提出了一种数据预处理的方式对Chars74K-15进行预处理,然后再基于现有的合成字符图片数据集进行CNN的预训练,最后再对预处理之后的Chars74K-15进行fine-tune训练,这样可以使识别率达到比较良好的效果。
1.2 预处理过程
预处理的目的主要是排除背景、光照等干扰因素,使预处理之后的图片特征和合成的字符图片较为类似。首先使用GrabCut算法[14]提取自然背景字符图片的前景,也就是字符本身,这是CNN的分类依据。由于对字符进行分类,只需要关注图像的纹理与边缘特征,所以忽略色彩特征,将三通道的彩色图像变成单通道的灰度图像,这也同样减少了无关特征的干扰。接着可以计算灰度图像的直方图,根据图1中自然背景字符图片的特点可以得知,其中字符的像素是占整幅图片大部分,由此可以在直方图中找到某个像素范围,经过多次实验本文将范围设为24。若在这个范围内的像素所占的比例是最大的,则最有可能是属于字符的像素。最后将这个范围内的像素设置为0,范围外的像素设置为255,进行腐蚀操作后即可得到与合成字符图片特征较为类似的预处理后的自然背景字符图片。整个过程如图2所示。有些情况下字符所属的像素不一定就是直方图中最“广阔”的山脉,背景像素有时候也可能占据图片的大部分。这时候需要根据计算公式来决定该范围内的像素是否属于图片中的字符:
1A(P)
(1)
式中:A=[pi-a,pi+a],p是待选像素范围的中值,pi是灰度图像边界像素的均值,a是根据实验得出的经验值,本文中设置为12。若指示函数的值等于1,则说明待选的像素范围很可能是属于背景,则需要继续查找另外的像素范围。若等于0,待选像素范围是正确的可能性较大。图2的第3行和第4行分别表示了不使用指示函数和使用指示函数的区别。
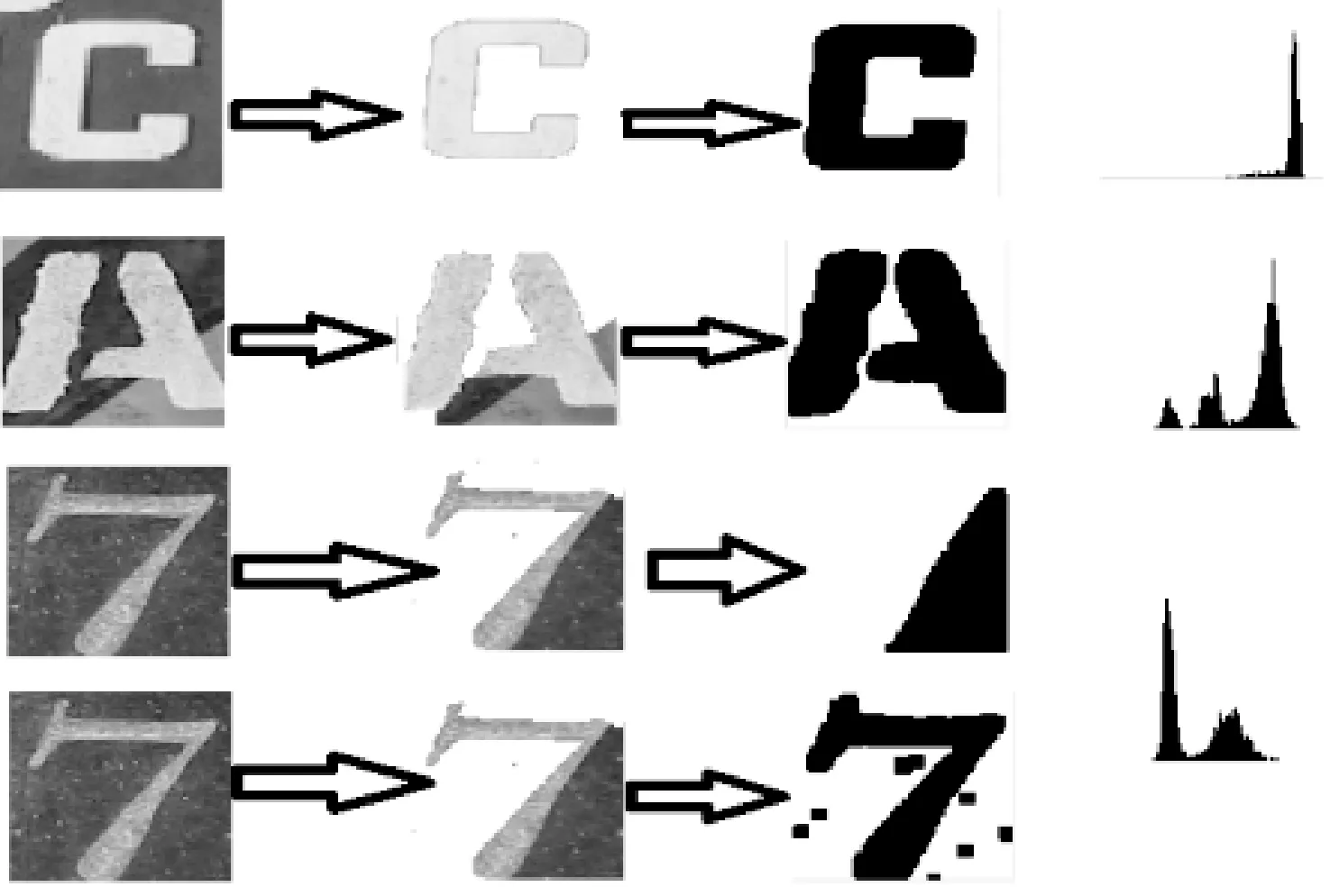
图2 从左到右依次是原图、提取前景后的灰度图、二值化图像、灰度图像的直方图
1.3 CNN的结构
图3描述了本文中的卷积神经网络结构:CNN总共有10层,其中卷积层6层,全连接层1层,采样层2层,还有最后一层是softmax层。前8层都会产生相应的特征映射图。通常来说,随着卷积层数的增加,分类的准确率会相应提高,但是也会带来相应问题,比如训练时间和需要训练的参数的增长。如果保持数据量不变,盲目地增加卷积层层数,这会导致模型过于复杂,反而还会带来过拟合的问题。为了确定最佳的卷积层层数,本文保持CNN其他参数和结构不变,分别在具有不同卷积层层数(分别是3、4、5、6、7层)的模型上进行了训练,当层数为6、7时测试错误率最低,详细的实验结果在第3节给出。
如图3所示,除了采样层与上层之间的连接参数不需要在训练中学习,其他层与上层之间的连接参数都需要学习,所以总共有8层参数需要学习。最后的全连接层会输出一个500维的向量,softmax层将这一向量作为输入,然后计算测试图片分别属于这62个类的概率分布,softmax使用交叉熵损失函数(cross-entropy)来计算每一次预测的loss值大小。常用的loss值计算的函数还有hinge loss,但是hinge loss计算的值是无标定的,很难对所有类进行判定。而通过cross-entropy所得的值可以对所有类都进行判定,它会给出对每一个类的预测概率。采样层的主要作用是降维,在本文中,采样层将上一层每一个2×2区域内的最大值作为采样值。CNN中的采样算法有最大采样和均值采样,实验显示采用最大采样错误率可以降低1.2%左右。Dropout[11]会出现在全连接层的后面,它的主要作用是防止过拟合,dropout有一定的概率抑制它的上一层的神经元的激活。在本文的实验中,加了dropout错误率降低了8%左右。文献[11]使用了局部响应归一化层(LRN),因为本文对输入的图片数据进行了归一化处理,所以并没有使用LRN层,实验证明使用了LRN层之后,错误率提高了2%左右。
在图3中,第1个卷积层由20个特征图组成,每一个特征图的大小为28×28,每个神经元的局部感受野大小为3×3×1。第2个卷积层由20个特征图组成,每一个特征图的大小为28×28,神经元局部感受野的大小为3×3×20。第3个卷积层由50个特征图组成,每一个特征图的大小为14×14,神经元局部感受野的大小为3×3×20。第4~6个卷积层有由50个特征图组成,每一个特征图的大小为14×14,神经元局部感受野的大小都为3×3×50。全连接层有500个神经元。对于所有的卷积层来说,同一个特征图中的神经元与上一层的连接参数都是相同的,称为“权值共享”,而不同特征图的神经元与上一层的连接参数是不同的,这样是为了可以提取不同的特征。
本文基于LeNet-5的改进除了增加卷积层、减少局部感受野与增加卷积核(与上一层进行卷积操作形成特征图)之外,还增加了填充像素,目的是为了在不断的卷积过程中,保证特征图的空间大小不改变。因为,实验发现当卷积层从6层增加到7层的时候正确率反而降低了2%左右。原因如图4所示,在第6层时,特征图已经变成4×4,第7层的局部感受野是3×3,会造成特征的丢失,LeNet-5的卷积层数目只有2层,因而无填充像素并不会影响。
2 CNN的训练过程
在LeNet-5中输入图片的大小为28×28,本文在此基础上还实验了25×25、32×32、50×50这3种尺寸作为输入图片的大小。发现32×32、50×50使准确率分别降低了1.6%和4.6%,25×25和28×28几乎没有差别。所以实验还是采用和LeNet-5一样的输入图片尺寸。为了防止过拟合,有些方法会将输入图片随机裁剪成多块。这一步预处理在本次实验中并不适用,因为在某些分类任务中的目标物体不一定就在图片正中的位置,裁剪有利于保证位移不变性。而实验中所用的数据集字符都在中心位置,所以只采用了镜像操作来扩大数据量,若是使用了裁剪,错误率会提高3.6%左右。鉴于HOG和SIFT被普遍使用在目标检测和目标识别领域,这两种特征可以很好地描述图像信息。因此本文也提取了Chars74K中的自然背景图片的HOG特征图和SIFT特征图(如图5所示)分别作为CNN模型的训练集,并且将训练结果和自然背景图片作为训练集的结果相比较,比较结果分别为63.4%、31.8%、66.6%。其中,采用SIFT训练的识别率最低,采用原图训练的识别率最高。由此可见,CNN模型并不适合采用对原图进行特征提取后的图片作为训练集。

图5 从左至右依次是原图、HOG特征图、SIFT特征图
表1所示实验过程中训练了不同层数的CNN结构:model1只有3层卷积层,model2到model5依次增加1层卷积层。在第一层最大采样层(MAX_POOL)之前的所有卷积层有20个卷积核,之后的所有卷积层有50个卷积核。
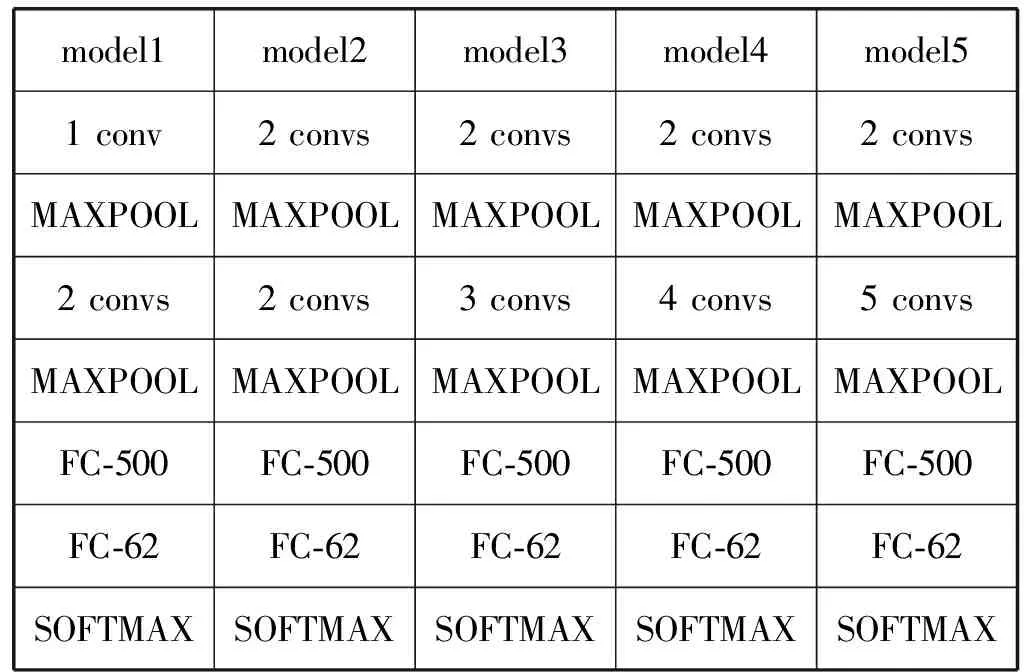
表1 CNN结构简单示意

(2)
Wt+1=Wt+Vt+1
(3)
CNN中激活函数的选择对于收敛速度和训练效果也是一个很重要的影响因素,本文在model4上实验了ReLu和sigmoid两种激活函数,如图6所示。可知,在500次迭代的训练过程中,无论是测试准确率的提高还是训练loss值的收敛速度,使用ReLu激活函数的效果都要优于sigmoid激活函数,因此本文在实验中是将ReLu作为激活函数。因为它相对于sigmoid来说有单侧抑制、稀疏激活性、避免过大的计算开销等优点。
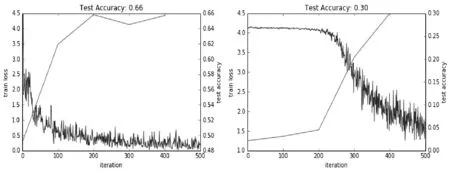
图6 左边为使用ReLu函数的效果,右边为使用sigmoid函数的效果
表1中的每一个CNN结构都会基于3组不同的数据集进行训练和测试,数据集分别是Chars74K中所有的自然背景图片、Chars74K-15和预处理后的Chars74K-15。还会在后两组数据集上采用fine-tune的方式进行训练,fine-tune是基于Chars74K中的电脑合成字符。接着会在实验最优的CNN结构中改变最后一层的卷积核个数进行训练和测试。最后会将合成字符图片进行如2.3节所述的扩充处理,将得到62 992张图片作为训练集进行字符分类训练。通过以上过程主要是想说明如下4点:
(1) 数据量的大小对CNN训练效果的影响。
(2) 基于本文提出的预处理方式,对于针对小数据集Chars74K-15训练效果的提高。
(3) 在数据量较少的情况下,fine-tune对于提高准确率有较大的作用。其中fine-tune是指基于另外已有的数据集训练出一个模型(初始化CNN中的参数),在此预模型上针对需要完成分类任务的数据集再进行训练(微调CNN中的参数)。
(4) 在Chars74K-15数据集上,卷积层层数以及卷积核个数对分类效果的影响。
3 实验结果分析
首先要验证数据量的大小对于CNN的影响,实验将在表1所示的5个CNN模型上分别对Chars74K的自然背景图片(11 883张训练图片,620张测试图片)和Chars74K-15进行训练,其中Chars74K-15是从每个类中选出训练集和测试集各15张图片,实验结果如图7所示。在所有的模型中基于Chars74K训练的准确率都要优于基于Chars74K-15训练的准确率,并且随着卷积层层数的增加浅色长条会缓慢增长(从model1的62.3%到model4的66.6%),但是在model5会下降1.8%左右。深色长条则一直呈现波动的趋势,在model5的时候,训练时候的loss是0.000 2,而测试的loss是4.93,这说明在基于Chars74K-15训练时可能发生了过拟合。所以基于适当的CNN结构,数据量的增加会提高分类的准确率,但是层数过多会导致模型需训练的参数增加,模型复杂度提高,从而也可能引起过拟合的现象。
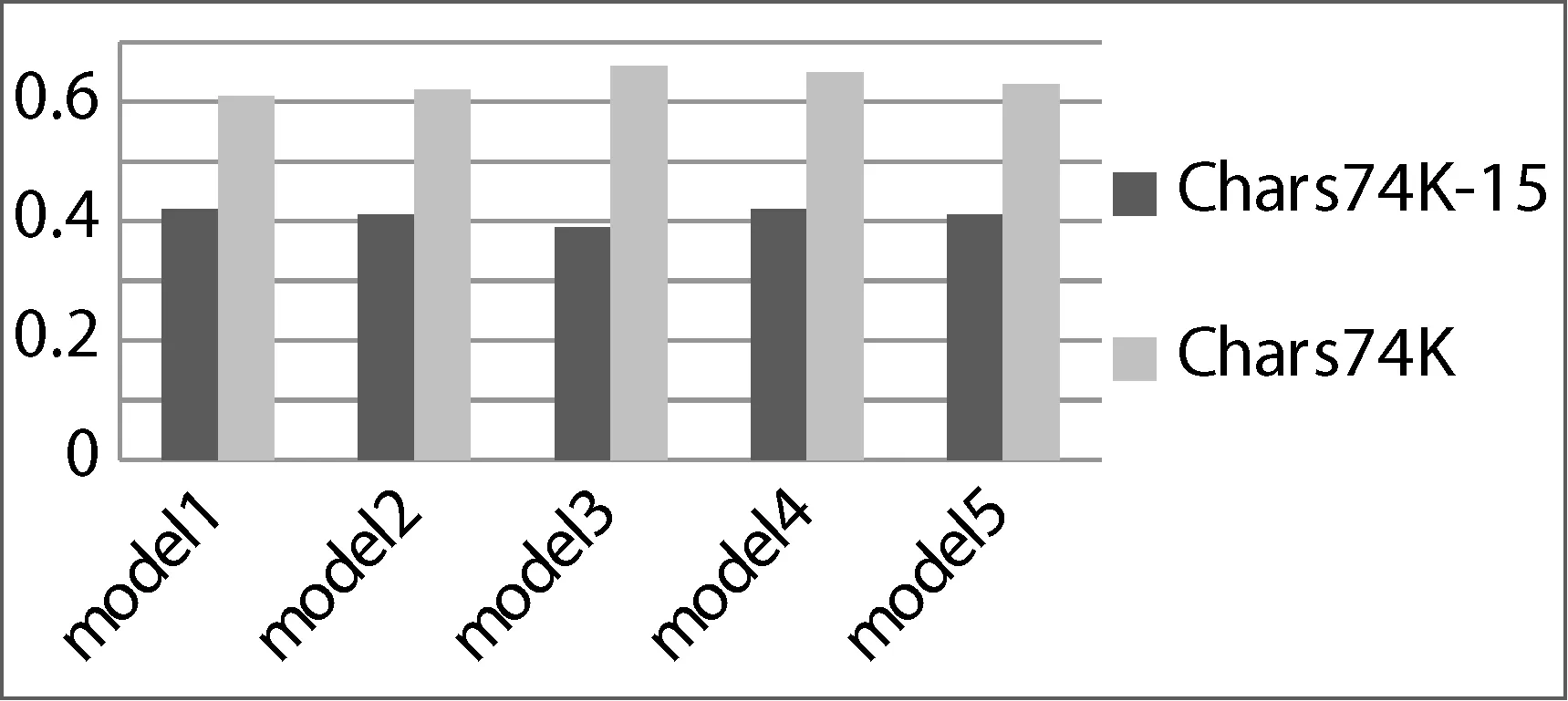
图7 Chars74K、Chars74K-15在不同模型上的实验结果
接着在所有的CNN模型上实验了在第2.1节中提出来的预处理对于Chars74K-15的影响,实验结果如图8所示。

图8 预处理对于Chars74K-15的影响
由图8可知预处理对于准确率的提高有比较明显的作用,平均提高了12%左右。这是因为经过预处理后的图像排除了背景,光照强弱等无关因素的影响,CNN更容易从中提取到与分类更加相关的特征。虽然一定程度上提高了准确率,但实验过程中准确率最高为58.7%(model5),还是低于在Chars74K上训练的效果。为了在不增加自然背景字符图片数据量的前提下进一步提高准确率,可以利用合成的字符图片进行预训练,然后基于训练好的模型再在预处理之后的Chars74K-15上进行fine-tune训练,和直接基于Chars74K训练效果的比较如图9所示,总体上准确率并没有大的区别。如果Chars74K-15只进行了fine-tune训练而没有经过预处理,效果虽然比图7(直接训练)平均有8%的提高,但没有预处理之后再进行fine-tune训练的准确率高。
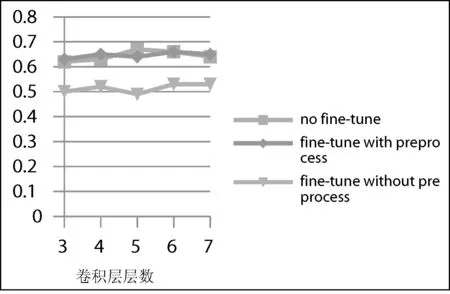
图9 Chars74K直接训练、预处理后Chars74K-15的fine-tune训练和未预处理的Chars74K-15的fine-tune训练
所以预处理和fine-tune对于Chars74K-15数据集的分类准确率的提高起到了一定的作用,fine-tune的方式可以有效缓解CNN的结构比较深的时候难以训练的问题,而且还有一个优于采用直接训练方式的地方,如图10所示。和图6左边进行对比采用fine-tune的方式在收敛速度上优于直接训练。
图10 直接基于Chars74K-15训练
结合准确率和计算效率考虑,实验选用model4作为最终的CNN结构,并测试卷积核数目的改变对于fine-tune训练预处理后的Chars74K-15影响,实验结果如表2所示。实验结果显示的规律和前面的比较一致,在一定的范围内,增加卷积层或者卷积核的个数准确率也会相应的提高,但是一旦达到某个临界值,增加卷积层或卷积核个数便不再有帮助。

表2 不同卷积核数目的准确率
表3是本文的方法和其它方法的比较,其中文献[8]中提出的方法比较好,因为该方法使用了额外的自然背景字符图片数据集,通过预训练的模型再进行了fine-tune所以有目前最好的效果。
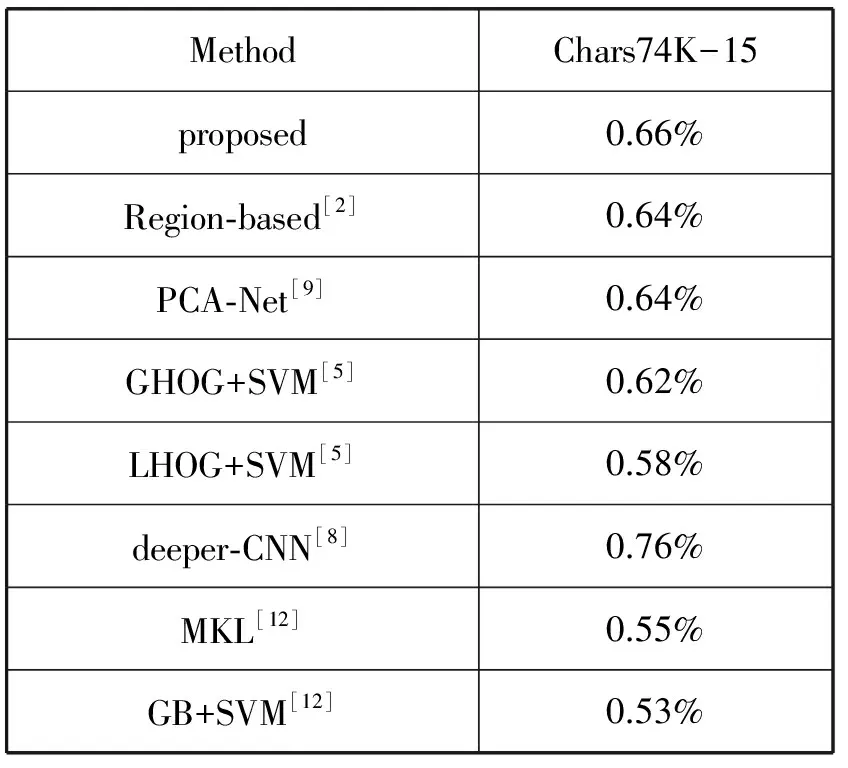
表3 不同的方法在Chars74K-15上的比较
通过CNN可以进行比较准确的分类,是因为可以通过不断的卷积、采样操作来提取图片的特征和降维,并且通过随机梯度下降的方式筛选出本质的特征,过程如图11所示。其中中间的图选取的是第一层卷积层中的16个特征映射图,右边选取的是最后的采样层中的49个特征映射图,CNN从底层到顶层提取到的特征是从具体到抽象,稠密到稀疏的过程,这样有利于提高分类的准确性。

图11 字符“m”在model4中的特征映射图
训练迭代过程中的示意图,如图12所示。右边的图纵坐标代表分类标签,横坐标代表训练的迭代次数,像素值越高代表属于哪个类的可能性越大。在字母“w”这个例子中,在训练迭代的过程中,CNN在32(表示“w”)和58(表示“W”)两个类别间跳动。而对于特征比较明显的字符,比如“m”,就会一直稳定在48这一正确的分类上。图11中显示的是经过预处理之后的字符图片。

图12 训练迭代时预测概率的变化
4 结 语
本文主要研究了训练样本数据量大小、卷积层层数、卷积核个数以及训练方法对于Chars74K-15分类效果的影响。虽然在大数据背景下可以对CNN分类效果的提高起到较大的作用,但带标签的数据的获取比较困难,所以本文提出了一种预处理的方式和一个CNN结构模型,并进行实验做出验证,在不需要更多自然背景图片的情况下,也可以取得比较良好的效果。但是基于预处理的方式也有一定的局限性,当字符分割比较规整、字符主体和背景的对比度较高时,后续的CNN训练才会有比较良好提高作用。并且像数字“0”和字母“O”,数字“1”和字母“l”,还有一些字母的大小写,本身区别就不大,分类效果自然不会很好。解决这个问题可以结合整个字符串的上下文环境来进行考虑。
[1] Neumann L,Matas J.Real-time scene text localization and recognition[C]//Computer Vision and Pattern Recognition.IEEE,2012:3538-3545.
[2] Lee C Y,Bhardwaj A,Di W,et al.Region-Based Discriminative Feature Pooling for Scene Text Recognition[C]//Computer Vision and Pattern Recognition.IEEE,2014:4050-4057.
[3] Kita K,Wakahara T.Binarization of Color Characters in Scene Images Using k-means Clustering and Support Vector Machines[C]//International Conference on Pattern Recognition,ICPR 2010,Istanbul,Turkey,23-26 August.DBLP,2010:3183-3186.
[4] Zhang D,Wang D H,Wang H.Scene text recognition using sparse coding based features[C]//IEEE International Conference on Image Processing.IEEE,2014:1066-1070.
[5] Yi C,Yang X,Tian Y.Feature Representations for Scene Text Character Recognition:A Comparative Study[C]//International Conference on Document Analysis and Recognition.IEEE Computer Society,2013:907-911.
[6] Epshtein B,Ofek E,Wexler Y.Detecting text in natural scenes with stroke width transform[C]//IEEE Conference on Computer Vision & Pattern Recognition,2010:2963-2970.
[7] Shi C,Wang C,Xiao B,et al.Scene Text Recognition Using Part-Based Tree-Structured Character Detection[C]//Computer Vision and Pattern Recognition.IEEE,2013:2961-2968.
[8] Zhang Y.Scene text recognition with deeper convolutional neural networks[C]//2015 IEEE International Conference on Image Processing (ICIP),2015:2384-2388.
[9] Chen C,Wang D H,Wang H.Scene character recognition using PCANet[C]//International Conference on Internet Multimedia Computing and Service.ACM,2015:1-4.
[10] Lécun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.
[11] Krizhevsky A,Sutskever I,Hinton G E.Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems,2012:1097-1105.
[12] Campos T E D,Babu B R,Varma M.Character Recognition in Natural Images[C]//Visapp 2009-Proceedings of the Fourth International Conference on Computer Vision Theory and Applications,Lisboa,Portugal,February,2009:273-280.
[13] Bissacco A,Cummins M,Netzer Y,et al.PhotoOCR:Reading Text in Uncontrolled Conditions[C]//IEEE International Conference on Computer Vision.IEEE,2013:785-792.
[14] Rother C,Kolmogorov V,Blake A.“GrabCut”:interactive foreground extraction using iterated graph cuts[J].Acm Transactions on Graphics,2004,23(3):309-314.
[15] Dan C,Meier U,Schmidhuber J.Multi-column deep neural networks for image classification[C]//IEEE Conference on Computer Vision & Pattern Recognition,2012:3642-3649.
NATURALBACKGROUNDCHARACTERRECOGNITIONBASEDONCONVOLUTIONALNEURALNETWORK
Yu Song Peng Zhiwen
(SchoolofSoftware,CentralSouthUniversity,Changsha410075,Hunan,China)
With the development of the computer vision technology, the recognition of characters in natural background plays an indispensable role in the fields of picture retrieval, video retrieval and unmanned vehicle recognition. Compared to the recognition of handwritten characters and printed characters, the natural scene characters have many different features. For example, the variation of light intensity, complex background texture, the variation of font’s style and color. All these features bring a huge challenge to the recognition. The paper raised a CNN which can recognize natural scene characters effectively. Most of the past research is based on Chars74K-15 which does not contain many images. In order to compare with the past, we used the same data set. Because of the large amount of data on training the CNN, we raised a preprocessing method with fine-tune to solve the problem of lacking data.
Recognition of scene characters Convolutional neural network Image classification
2017-02-11。郁松,副教授,主研领域:图像处理,数据挖掘。彭志文,硕士。
TP391.4
A
10.3969/j.issn.1000-386x.2017.12.044
