RFID 数据在供应链中的过滤算法研究
2018-01-02刘峰
刘 峰
(吉林化工学院,信息与控制工程学院,吉林 132011)
RFID 数据在供应链中的过滤算法研究
刘 峰
(吉林化工学院,信息与控制工程学院,吉林 132011)
无线射频识别技术已经被认为是供应链管理中必不可少的功能,特别是对于零售商们做出决策的数据收集能力。然而,许多错误的读数却可能导致完全相反的决定。在本文中,我们提出7种模型及其匹配算法用以过滤那些原始数据,以便管理者能够在供应链管理中更好地使用收集到的RFID数据。
RFID;数据过滤;多数投票法;隐马尔可夫链
0 引言
RFID彻底改革了供应链管理,因为它帮助零售商决定在正确的时间、正确的地点提供正确的产品。首先,RFID能够使整个供应链流程对读写器可见而标签却不必在直接的视线范围内。其次,识别的特性使 RFID可用于扫描托盘上的集装箱,这就给企业提供了商品数量的信息——有多少商品、多少次被交付。第三,不久就能够看到 RFID在其它技术不能适用的环境中使用。此外,它还能够用于有人身危险的地方来代替人类的工作。
现在,RFID大规模实施的主要障碍是它会产生超过30%的标签读取的错误[1]。就此而言,基于这些数据做出的决策不可能是有效的。这些挑战可能是由于传送的数据只是原始数据而没有经过过滤这种情况造成的,错误读数的原因可能是信号折射和偏转、衰减、多点输入多点输出、读写器的精确度[2]。
许多推荐的解决方案被提出用于过滤这些错误的读数,这样做的一个重要原因是为了使这些原始数据仍然保持原状。许多学者在著作中都很重视基于滑动窗口的方法,他们相信增加 RFID的读取频率将会降低错误读数的比率。在做这项工作的时候,Y Bai移除噪音、清除副本[3],而Shawn R. Jeffery则认为环境状况是决定滑动窗口大小最复杂的因素[4],所以他们提供了SMURF(自适应平滑过滤)来改善RFID所处环境的动力学状况[5]。然而,有时读写器的读出数据一直无效,或者信号强度不足以生成足够的正确数据,在这种意义上,以上方法都是不够的。如果那样的话,即使能够提供自适应的窗口大小,错误读数仍然不能消除。其他一些学者也在RFID的中间件中利用系统结构来解析、过滤和聚合数据[6,7,8]。
在本文中,我们提出7种模型及其匹配算法用以过滤那些原始数据,以便管理者能够在供应链管理中更好地使用收集到的RFID数据。
1 模型 1、2、3[9,10]
在这些模型中,我们假设关注的对象在一个传送带上传送,两台读写器位于传送带两边,每个对象安装三个标签。
模型1算法:
1、两台读写器就对象的存在进行多数投票。因为是两台读
写器读取对象的3个标签,所以应该得到6个读数。如果6个读数中超过3个相同,我就选取其(‘0’或‘1’)作为它的读数。
2、如果以上规则不能有效,也就是说出现3对3的矛盾读数,我们将依赖于更好的读写器,意即这台读写器在前10个读数当中提供一致的读数。在那种情况下,这台读写器将最有可能给我们提供可靠的读数。
3、如果很不幸,两台读写器两次出现同样的状况,那么我们只采用后一次读数循环的数据。
模型2算法:
1、在本算法中,我们不做多数投票。对于每一个对象,我们在三个嵌入式标签中使用一个较好的,只对较好的标签比较两者读数。如果来自两台读写器的读数相同,可以认为是关注对象的存在形成了相同的读数。
2、如果两台读写器对于较好的标签读数不同,我们取第二个标签作为目标读数并比较标签二的两个读数。如果两台读写器对于标签二的读数相同,可以认为是关注对象的存在形成了相同的读数。
3、如果两台读写器对于标签二读数不同,我们取第三个标签作为目标读数并比较标签三的两个读数。如果两台读写器对于标签三的读数相同,可以认为是关注对象的存在形成了相同的读数。
模型3算法:
1、两台读写器就对象的存在进行多数投票。因为是两台读写器读取对象的3个标签,所以应该得到6个读数。如果6个读数中超过3个相同,我就选取其(‘0’或‘1’)作为它的读数。
2、如果以上规则不能有效,也就是说出现3对3的矛盾读数,我们将依赖于更好的读写器,意即这台读写器在前10个读数当中提供一致的读数。在那种情况下,这台读写器将最有可能给我们提供可靠的读数。
3、如果很不幸,两台读写器两次出现同样的状况,那么我们只采用后一次循环的数据。
4、在我们通过标签得到足够的读数后,我们可以用隐马尔可夫链模拟整个过程,以使读数的结果能够得到优化。
我们知道,在隐马尔可夫模型中,状态不是直接可见的,但依赖于状态的输出是可见的。并且在这个独特的过程中,我们知道一个存在的标签趋向于将存在的标签纳入它的邻域内。因此,我们有下列假设,如图1所示。

图1 隐马尔可夫模型Fig.1 Hidden markov model
使用以上三个模型,我们对1000个读取对象读取10次来模拟错误读取率,并且我们也包含了三个标签一直在或不在读取对象当中的情况。此外,对于读数准确率的三种概率为0.4、0.7和0.9,这样结果就有9种可能的组合。
通过结果图我们看到,模型3在三种模型里性能最佳,这是由于它能够纠正不可能的读数这种特性。图中所示三种模型都显示出随着概率的增长而错误读取率降低的趋势,这应该是合理的,因为读写器的准确率是错误读取率的直接影响因素。随着读写器读到更少的错误数据,结果可以更好。还可以看出,当读写器的读数准确率都达到0.5以上时,模型3几乎不会提供任何错误读数。绝大多数时间都是非常好的结果,读写器读数正确而不是错误。而与模型2比起来,模型1确实更优,因为我们对于错误读数设想的几乎所有情况它都能明确执行,除了读写器的读数准确率都低于50%这种情况。在这种情况下,两台读写器给出的结果可能还不如我们只是弹出一枚硬币,然后随机选择存在或不存在的结果。然而,虽然它是一种非常糟糕的情况,在实践中这种情况却几乎不能发生,因为读写器读数准确率都低于50%的环境很少见,并且对于正确性使用多数投票的方法比依赖于更好的读写器进行随机选择要好。

图2 错误读取率Fig.2 False reading rate
而且,从图中还可以看到,对于模型1和模型2来说,P2与P3、P4与P5、P7与P8这几种情况下错误读取率情况几乎完全一样,这主要是因为它们被置于这样的条件下:两台读写器都修改它们的读数准确率,以便无论每一个的选择是什么,它们对于选择的概率组合应该是一样的。仅举一例:P1假设读写器1读数准确率为0.4,读写器2为0.7;而P2是另一种情况,即读写器2读数准确率为0.4,读写器1为0.7。从常识上来说我们也应该知道,它们是一样的。
对于推荐的隐马尔可夫链,我们置于这样的假设下:如果前一个标签存在,下一个很可能是存在的。做到这一点有切实可行的办法——在供应链系统的正规环境下,我们总是看到标签和物品被整齐的排列,以便能够在传送带上更好的传送,而且大多数时候它们连续出现。在供应链系统环境下,这是一个合理的假设。然后,在这种情况下,我们用维特比算法计算隐马尔可夫链提供的读写器读数的统计结果。
2 模型A、B、C、D[9,10]
在这些模型中,我们同样假设关注的对象在一个传送带上传送,两台读写器位于传送带两边,每个对象安装两个标签。但是,这两个标签不同,一个是嵌入对象的目标标签,另一个是带有我们能够准确处理的连续编号的标签,在托盘上。
对于托盘上的带有连续编号的标签,我们可以用这种方式处理:我们把一个连续编号的读数与它相邻的读数进行比较,如果可比我们就记为存在的1,如果不可比我们就记为不存在的0。例如,如果我们得到前后标签的读数为{77,1000,79},我们应该意识到中间的读数是错的,所以我们把托盘标签看作不存在。既然我们能够准确处理托盘标签,研究它就是有意义的,因为它将必然减少该系统正向错误读数(即读数显示存在而标签其实并不在读写器读取范围内)。
模型A算法:
1、读写器根据两个标签的相同读数判定存在。如果读写器从两个标签获得的两个读数是相同的结果,就可以认为确实是相同的结果。
2、如果以上的结果是存在,那么我们检测托盘标签的连续编号。如果相邻比较中连续编号越界,则仍然表示不存在。
3、否则,随机选择0或1。
模型B算法:
1、读写器根据两个标签的相同读数判定存在。如果读写器从两个标签获得的两个读数是相同的结果,就可以认为确实是相同的结果。
2、不再查阅连续编号,只是随机选择0或1。
模型C算法:
1、两台读写器根据两个目标标签的相同读数判定存在。如果两台读写器从目标标签获得的两个读数是相同的结果,就可以认为确实是相同的结果。
2、如果以上条件无效,两台读写器根据两个托盘标签的相同读数判定存在。如果两台读写器从托盘标签获得的两个读数是相同的结果,就可以认为确实是相同的结果。
3、如果以上的结果是存在,那么我们检测托盘标签的连续编号。如果相邻比较中连续编号越界,则仍然表示不存在。
4、否则,在0.25至1的概率范围内随机选择状态。
模型D算法:
1、两台读写器根据两个目标标签的相同读数判定存在。如果两台读写器从目标标签获得的两个读数是相同的结果,就可以认为确实是相同的结果。
2、如果以上条件无效,两台读写器根据两个托盘标签的相同读数判定存在。如果两台读写器从托盘标签获得的两个读数是相同的结果,就可以认为确实是相同的结果。
3、否则,在0.25至 1的概率范围内随机选择状态。
为了模拟模型a、b、c、d,我们使用四个准确性概率如下所示:
p=[0.8 0.85 0.9 0.95]
意为如果标签在读写器的扫描范围内确实存在,在第一个例子中读写器将其读为存在的概率是0.8,其他的也一样。
在模型a和b中,将只考虑一台读写器,而在模型c和d中,则包括两台读写器和两个标签。作为更一般的情况,我们设置存在和不存在为 0.5和0.5,并假设两个标签存在或不存在都处于同样的环境中,也就是说如果关注目标存在,那么两个标签在读写器读取范围内都存在,而如果关注目标不存在,那么两个标签在读写器读取范围内都不存在。并且,我们还会运行系统10次,每次1000个读数,以便给出一个更稳定的结果。
正向错误图显示,在那些存在正向错误读数的实例中,带有连续编号的模型总是比那些不带的要好。这是因为,当关注对象不存在而读写器显示 1时,将被连续的托盘标签纠正,也就是说每当两台读写器就对象的存在取得一致时,它们必定会查阅连续编号来检验是否为真。而且,我们已经知道我们能够准确处理连续编号或者连续标签,所以显然我们可以清除正向意义上的错误数据。相比于一台读写器,两台读写器总是更好,正像模型c和模型d在正向读取率上胜过模型a和模型b。这一点很容易检验,因为如果有两台读写器,随着读写器准确率增加,它们读数错误的可能性更小。这种现象的原因与模型1、2、3中所提到的一样。
从负向错误图来看,在那些存在负向的错误读数(即读数显示不存在而标签其实在读写器读取范围内)的实例中,带有连续编号的模型几乎与那些不带的性能相同。这一点应该很清楚,因为连续编号与负向的错误读数无关。也就是说,连续标签所做的工作就是当不存在时纠正存在标志。然而我们能看到,当两台读写器都指明不存在时,我们不需要去查阅连续编号。在那种情况下,对于读数的最终结果不会改变太多。而且,他们也显示出随着读写器准确率增加而减少的趋势。
通过所有的性能分析图可以断定,带有连续编号的模型在存在错误读数的情况下总是比那些不带的要好,并且模型c是四个模型中最好的一个。这是由于模型c不仅使用两台读写器增加发现不正确的可能性,而且查阅托盘上的连续编号,更易于找到错误的正向读取。而且,随着读写器准确率的提高,它们的性能趋同。
3 结论
可以看到,错误读取率是 RFID大范围应用最大的难题,它不仅影响管理者的决策,而且极大地影响商品的利润,因为它给使用者提供的是不可靠的原始数据,无论对于现在的决策还是将来的使用都无法消除。
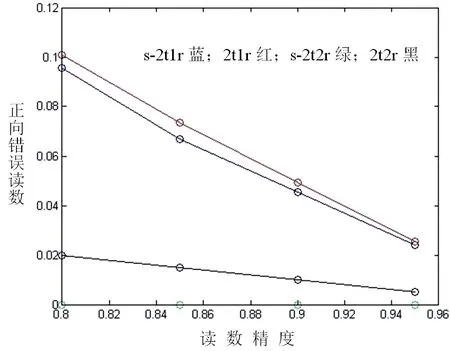
图3 正向错误读取率Fig.3 False positive reading rate
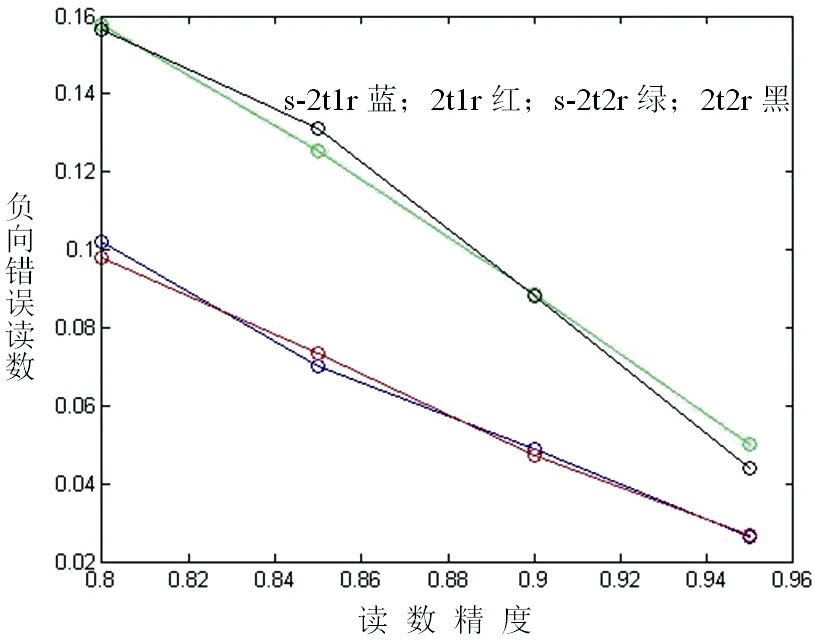
图4 负向错误读取率Fig.4 False negative reading rate

图5 错误读取率Fig.5 False reading rate
本文所示,我们提供7种模型来给出关于读数准确率情况的实例。前三个模型,模型 1、模型 2和模型 3,我们比较了三个标签和两台阅读器的情况。显然,对最终结果做多数投票比选择更好的标签对于决定标签是否存在要更好。而且,我们提供了一种隐马尔可夫链模型来处理选择的数据。因为当一个对象存在时,就在它旁边的下一个对象应该也存在的可能性更大,所以我们所做的就是使用这种转换概率来对真实情况做最准确的推测,即用维特比算法计算正确的读数。并且,从仿真结果我们完全能够确信,使用这种隐马尔可夫链模型我们能够取得更好的读数准确率。
在随后的例子中,我们以比较连续的托盘标签的方法模拟了四种其他的模型,其中标签所带连续编码我们能够准确处理。通过模拟一台读写器和两个标签的情况,两台读写器和两个标签的情况,我们最终确定,对于正向读取的情况,连续编号确实能够提高读数准确率。然而,对于负向读取就不是这样了,因为我们从来没有对不存在的情况查阅连续编码。在比较了四种情况之后,我们得出结论:两台读写器和两个带有连续编号的托盘标签能够在实际当中给出最全面的结果。
但是,之前的例子都是基于这种假设:两台读写器相互独立,所以他们不会影响彼此的结果。如果它们在时间或空间的上相互关联,或者如果我们考虑信号的多重路径,那么在这种情况下,它们将得到改善,结果也将更佳。
[1] S.R.Jeffwey, et al. A pipeline framework for online cleaning of sensor data streams[C]//ICDE, 2006.
[2] Y.F.Niederman, et al. Examining RFID applications in supply chain management[J]. Commun: ACM, 2009, 46(2): 586-593.
[3] BAI Yi-jian, et al. Efficiently filtering RFID data streams[C]//Clean DB, 2006.
[4] Shawn R.Jeffery, et al. Adaptive cleaning for RFID data streams[C]//VLDB, 2006.
[5] 尚明, 蒋泰, 李立宪. RFID中间件数据过滤方法研究[J].广西科学院学报, 2014, 30(1): 47-50.
[6] 孙红, 厉彦刚, 陈世平. RFID中间件数据处理研究[J]. 上海理工大学学报, 2014, 36(3): 234-238.
[7] 曹国瑞, 解岩. 基于RFID的计量器具物资标签批量读取算法. 科技通报, 2015, 31(8): 30-32.
[8] 罗元剑, 姜建国, 王思叶等. 基于有限状态机的RFID流数据过滤与清理技术. 软件学报, 2014, 25(8): 1713-1728.
[9] TU Yu-ju, Selwyn Piramuthu. A decision-support model for filtering RFID read data in supply chain[C]//IEEE Transactions on system, man, and cybernetics, 2010.
[10] 贾红梅, 李文杰. 面向仓储管理的RFID数据过滤模型研究.计算机应用与软件, 2014, 31(2): 74-76.
RFID Data Filtering Algorithm in Supply Chain
LIU Feng
(College of information and control engineering, Jilin Institute of Chemical Technology, Jilin 132011, China)
Radio-frequency identification technology has been regarded as an essential role in supply chain management especially for its data collection capability for retailers to make decisions. However, lots of false readings could result in totally opposite resolutions. In this paper, we present seven models and their corresponding algorithms to filter these raw data so that managers can make good use of collected RFID data in supply chain management.
RFID; DataFiltering; Vote for majorities; Hidden markov chain
TP312
A
10.3969/j.issn.1003-6970.2017.12.021
本文著录格式:刘峰. RFID数据在供应链中的过滤算法研究[J]. 软件,2017,38(12):110-114
吉林省教育厅重点项目(吉教科合字[2014]第343号)
刘峰(1970-),男,讲师,计算机技术及应用。
