基于SVM的电信诈骗行为特征识别方法
2018-01-02吉涵之马宇宸李静林
吉涵之,马宇宸,李 爽,李静林
(1. 北京市第十三中学,北京 100009;2. 北京邮电大学网络技术研究院,北京 100876)
基于SVM的电信诈骗行为特征识别方法
吉涵之1,马宇宸2,李 爽2,李静林2
(1. 北京市第十三中学,北京 100009;2. 北京邮电大学网络技术研究院,北京 100876)
电信诈骗行为种类繁多,受害人分布广,对其预防存在困难。针对电信诈骗手段开始向最新电信技术和系统漏洞的充分利用演进这种趋势,论文提出通过通信记录数据去发现电信诈骗通话行为与普通用户的通话行为的行为特征差异,并结合用户属性,使用支持向量机(SVM)这一机器学习手段进行电信诈骗行为的学习,进而完成电信诈骗行为的识别,以辅助拦截电信诈骗号码。论文分析了诈骗行为的规律,提出了行为特征的抽取方法及基于SVM的行为识别系统构建方法,最终通过实际样本数据的训练和测试,验证了这一方法的可行性。
大数据;机器学习;支持向量机;电信诈骗
0 引言
随着移动电信网和移动互联网的快速发展和电信资费的逐步下降,中国快速进入信息化时代。现代电信技术一方面为人民群众带来了沟通的便利,另一方面也容易被犯罪分子利用,使用身份冒充、电话改号等手段,利用受害人对银行业务不熟悉、对政府机关流程不熟悉、甚至沟通之间的时间差等,对受害人进行欺骗、恐吓,骗取受害人的资金。近年来,电信诈骗犯罪从最初技术水平较低的身份冒充向最新电信技术和电信系统漏洞的充分利用演进。如2009年开始利用VoIP技术进行诈骗,2013年则开始通过改号软件跨境犯罪,2014年开始大规模利用伪基站发送诈骗短信,2015年以后则开始使用综合手段进行诈骗[1]。由于电信诈骗手段多样,且电信诈骗的跨地域甚至跨国家特性,导致受害人分散广,个案金额小,预防和打击的难度非常大。
近年来国家已经开始推行手机实名制,以希望从源头控制电信诈骗。但是仍然会存在使用改号软件跨国犯罪、冒用别人身份证件购买电话号卡等防不胜防的问题。同时,互联网公司也通过众包方式,通过手机安全软件标注诈骗电话,并取得了不错的效果。但是,由于以上方法一般仅能在案发后起到作用,因此仍具有局限性和滞后性。由于诈骗电话在实施成功诈骗之前,一般存在一定搜索被害者、与被害者多次电话交互的过程,因此,随着大量的案例积累,及电信大数据处理能力和手段的提升,可以通过电信通话过程产生的话单大数据去发现电信诈骗通话行为与普通用户的通话行为的行为特征差异,并利用这种差异进行电信诈骗行为的挖掘,以期在电信诈骗完成前对电信诈骗行为进行识别和拦截。
1 电信诈骗行为分析现状
从直观上,电信诈骗电话由于需要通过大量盲拨锁定被害人,因此其拨打频率、通话时间等的行为规律与普通用户应该有一定差异。2015年周国民[1]等对一些用户的通话行为进行了统计分析,发现通话时间频率、通话时间间隔、同一对象通话次数频率、通话周期和通话间隔相关性等具有较为明显的规律性,但由于样本数量有限,未能明确普通用户和诈骗用户的行为规律差异。2016年10月,360公司发布了《2016诈骗电话态势与特征分析报告》[2]。在这一报告中,360对众包标注结果进行了数据挖掘分析。报告中指出,全国范围内,诈骗电话的异地呼叫率平均为 68.8%,全国 81.6%的城市用户接听诈骗电话的异地呼叫率在85%以上,西藏、青海、内蒙古、宁夏等地区,诈骗电话的异地呼叫率甚至达到了90%以上。这意味着诈骗电话具有较为明显的异地呼叫特性,长途电话数量较本地电话数量为多。报告显示,手机诈骗号码的生存周期约为 54.5天,连续活跃周期为 3.8天,单日单号平均呼出诈骗电话次数为 189次,诈骗成功率为 0.28%,一次成功诈骗所需平均呼叫次数为357次,完成一次成功诈骗平均需 1.9天;生存期长说明手机号码具有较长的潜伏期,但由于手机号码诈骗成功率较高,因此手机诈骗号码激活后搜寻骗诈目标的时间短,活跃周期短,但是完成一次诈骗的时间较长。而境外诈骗号码的生存周期约为36.4天,连续活跃周期为 36天,单日单号平均呼出诈骗电话次数则达到5076次,诈骗成功率为0.07%,一次成功诈骗所需平均呼叫次数为1429次,完成一次成功诈骗平均需0.3天;这意味着由于诈骗成功率低,境外诈骗电话需要长时间的活跃以搜寻诈骗目标,但完成一次诈骗的时间很短。平均下来,诈骗电话号码的生存周期约为57.6天,连续活跃周期为7.6天,单日单号平均呼出诈骗电话次数为 185次,诈骗成功率为0.1%,一次成功诈骗所需平均呼叫次数为1000次,完成一次成功诈骗平均需 5.4天。这意味着诈骗电话一般会具有较为明显的生存期和活跃期,且活跃期中的平均呼叫数量较高。同时,统计显示,约92.7%的诈骗电话是骗子打给用户的,而约 7.3%的诈骗电话是用户主动打给骗子的。手机诈骗号码有9.8%的用户主动打出,固话诈骗号码有4.7%是用户主动打出的。这意味着诈骗电话具有较高的单向性,呼出电话数量明显高于呼入电话。360公司的研究报告表明,电信诈骗电话的通话行为与普通用户的通话行为确实存在一定的差异性,如果能对这些差异进行认知学习,在电信诈骗成功之前识别出电信诈骗企图是有可能的。
从电信诈骗识别的方法上,传统应用较为广泛的分类模型主要包括决策树模型和朴素贝叶斯模型。文献[3]和[4]分别使用这两种模型进行了电信欺诈行为分类分析。但由于这两种模型都假设样本的各个属性间具有独立性,而这种假设在现实的环境中难以存在,因此其分类的结果难以应用到实际系统中。目前,业界提出的可采用的另一种监督式学习方法是支持向量机(SVM:Support Vector Machine)。SVM 通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。SVM的优点是它提供了一种避开高维度空间的方法,可以直接借助于空间内的核函数,将线性不可分情况转化为线性可分的问题,再利用对线性可分的问题的求解方法直接解出对应的高维空间的问题。文献[5]提出采用 SVM 进行电信客户欺诈检测,但该文选取的用户特征仅局限在通话次数和时长,难以全面的体现出诈骗用户的特征。同时,其测试验证没有使用实际数据,其取得的极高的准确率仅针对测试数据,难以实际应用。
针对以上问题,本文提出了一种电信诈骗行为分析系统,通过分析电信诈骗行为规律构造电信诈骗行为的特征属性集,并通过SVM进行训练,最终形成电信诈骗行为识别器。
2 电信诈骗行为特征样本构建
电信用户的呼叫记录主要包括通话开始时间、计费号码、对方号码、呼叫类型、通话地点、对方地点、通话时长、通话类型、费用等信息,但是这些信息类型差异大,衡量尺度和单位不一,如果不经过预处理,难以呈现出电信用户行为特征,也难以通过SVM训练进行分类。因此,需要对电信用户的呼叫记录进行预处理,形成特征属性,并构建为可用于SVM训练的电信诈骗行为特征样本数据。
诈骗电话的用户行为复杂,根据电信诈骗行为分析的现有研究成果可以看到,诈骗行为的特征不仅仅体现在诈骗电话通话的次数、时长特征,还表现在通话地域的聚集特性,长途甚至国际漫游通话类型的聚集特性等,考虑到通话记录的参数内容和诈骗电话行为特征规律,本文定义了电信诈骗行为特征样本的数据结构,如表1所示。
时间粒度的确定比较复杂,时间粒度太小,无法体现出用户的行为特征,将会造成大量的误判。时间粒度太大,将会导致用户的行为特征细节被统计特征掩盖,同样会造成误判。
本文分析了电信用户呼叫记录中各种属性的分布规律,其中每小时平均呼叫次数如图1所示,每小时平均呼叫次数的频度分布如图2所示。
从诈骗电话和正常电话的平均呼叫次数可以看到,诈骗电话的平均呼叫次数在早7~8点开始与普通电话平均呼叫次数产生较大差异,12点左右回落,13点开始再次攀升,18点左右再次回落,并在 19点~20点左右产生一个小波峰。这种规律性的波动现象与工作日的正常上下班及休息时间类似。
从呼叫的频度可以看到,接近80%的普通用户的呼叫频度为平均每小时1次,98.88%的普通用户呼叫频度在平均每小时3次以内。而诈骗电话的呼叫频度的分布较普通用户要更宽,仅有60.68%的诈骗电话呼叫频度在平均每小时3次以内,93.45%的诈骗电话呼叫频度在平均每小时20次以内。这意味着诈骗电话的呼叫频度比正常电话频度要高很多。
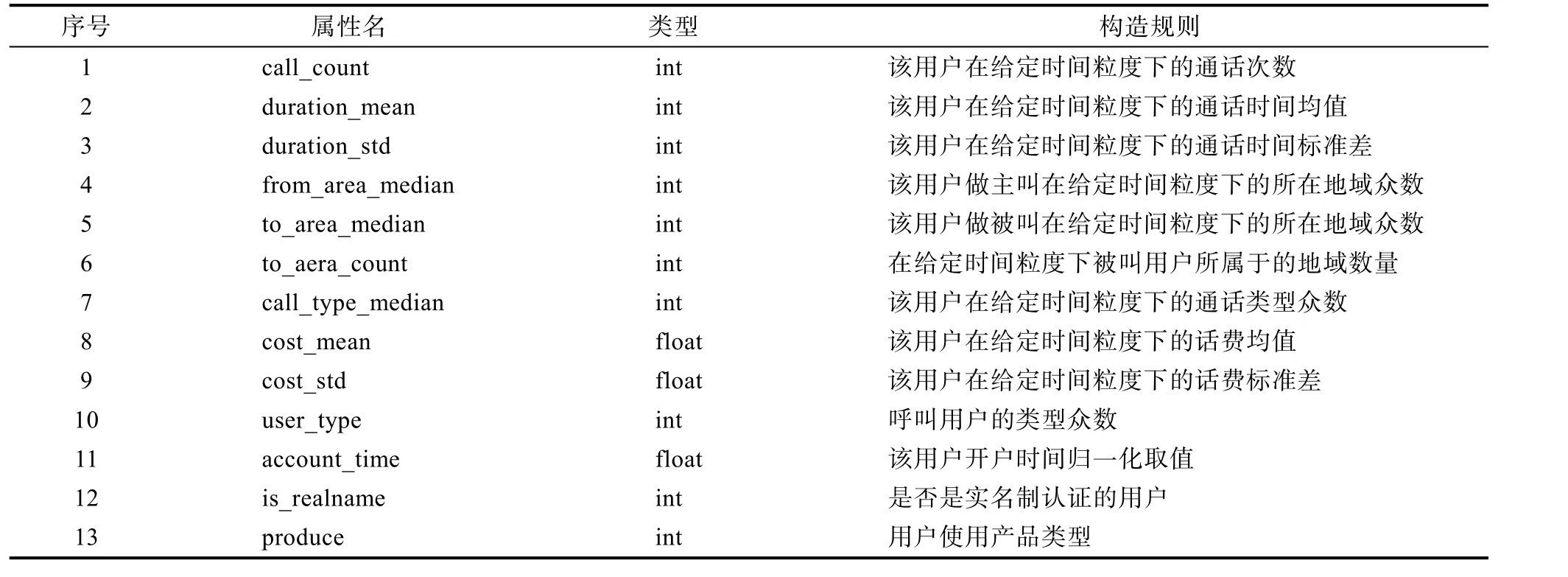
表1 电信诈骗行为特征样本数据结构Tab.1 Telecom Fraud Behavior Features
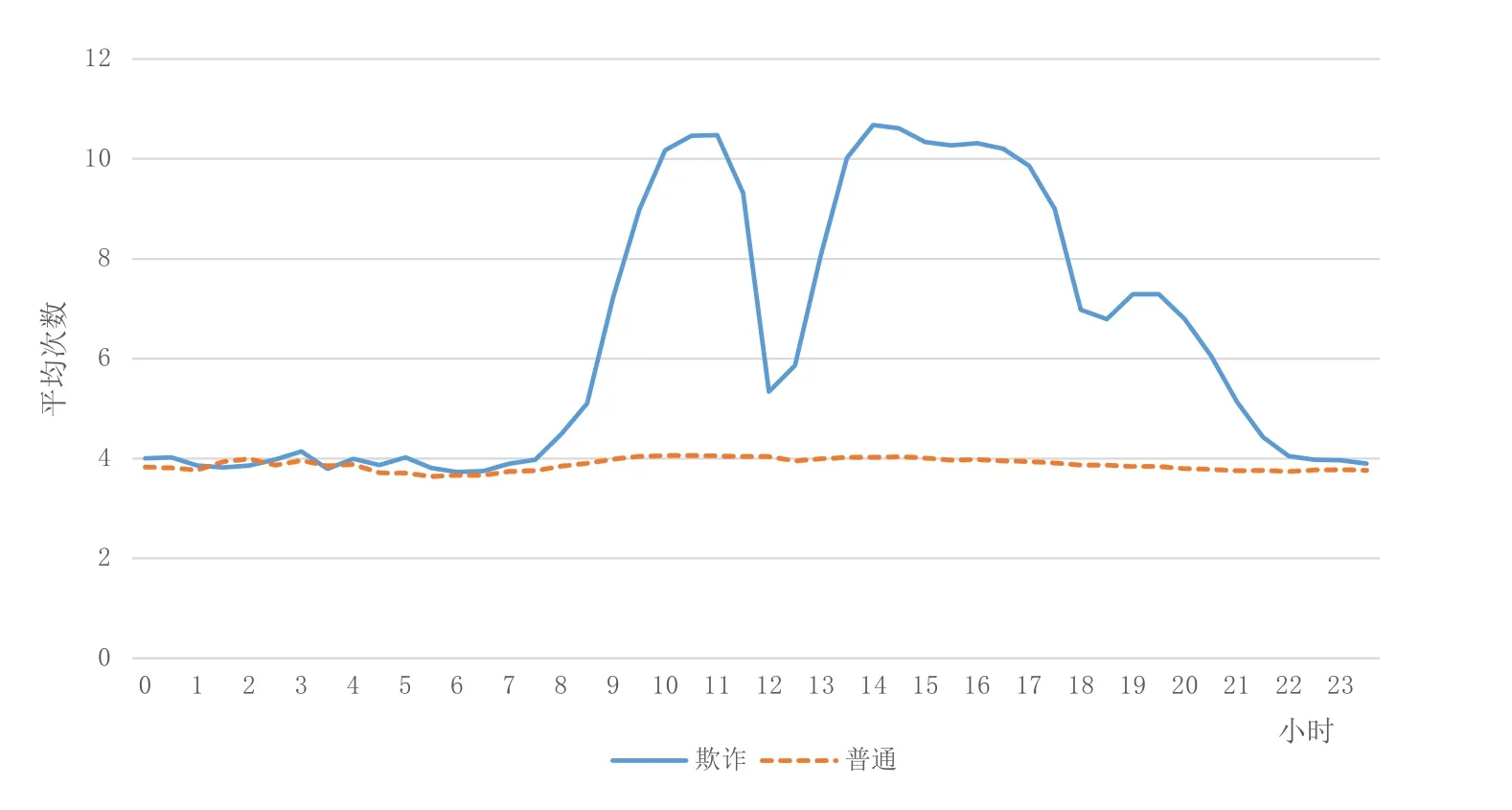
图1 平均呼叫次数Fig.1 Call numbers per hour
基于这些特征的分析可以看到,为了更好地体现电信诈骗与普通用户的行为差异,可以将一天划分为上午和下午两个时间段,取差异较为明显的时间区间选取特征片段。同时,由于诈骗电话呼叫频度比普通电话大,较长的时间段能够累积足够多的呼叫频次、时长等统计特征,减小分类误差。
3 电信诈骗行为特征分类器实现方法
3.1 行为特征分类器总体结构
电信诈骗行为特征分类器的结构主要划分为数据清洗、特征数据构建、分类训练与评价三个模块,如图3所示。
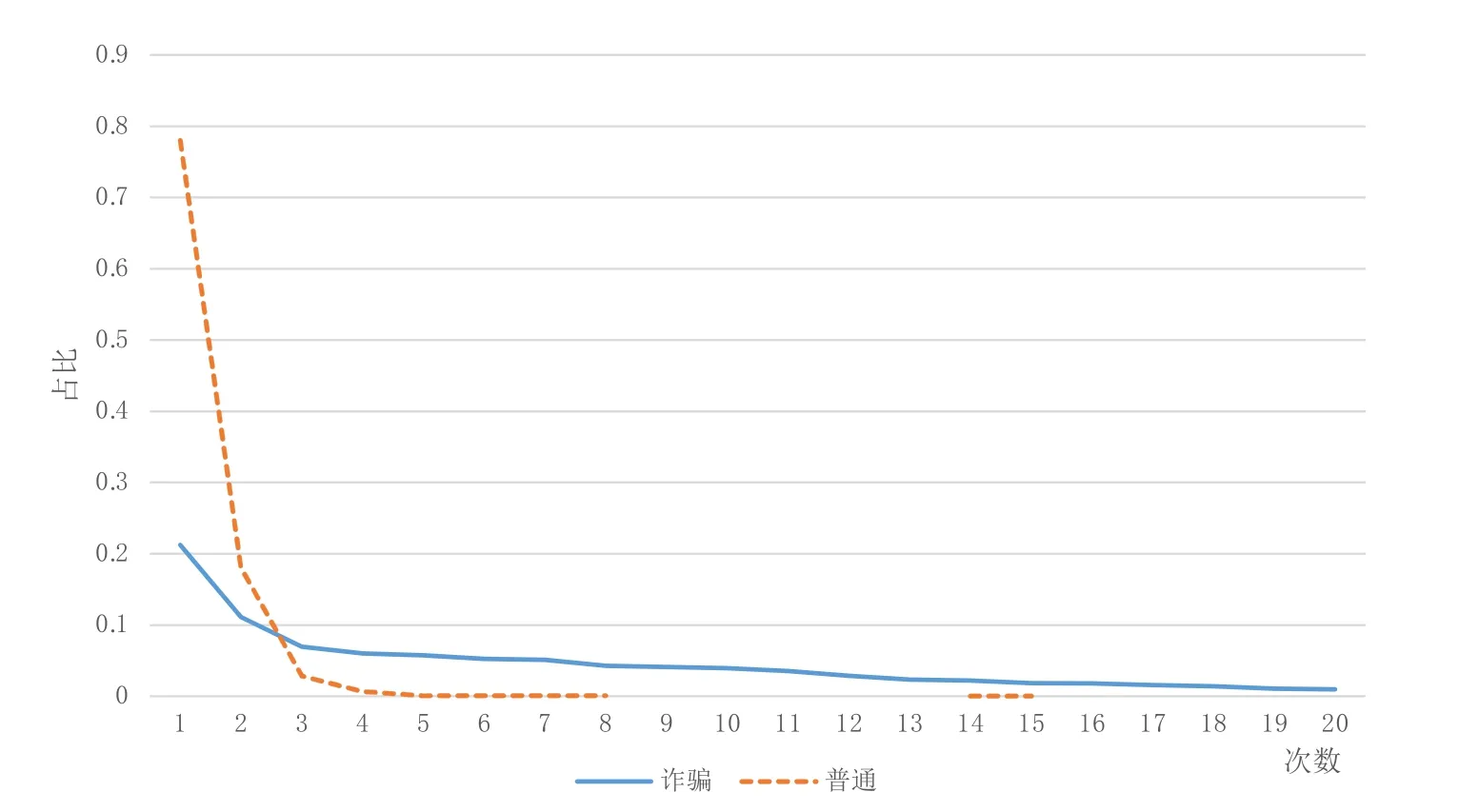
图2 呼叫频度Fig.2 Call frequency
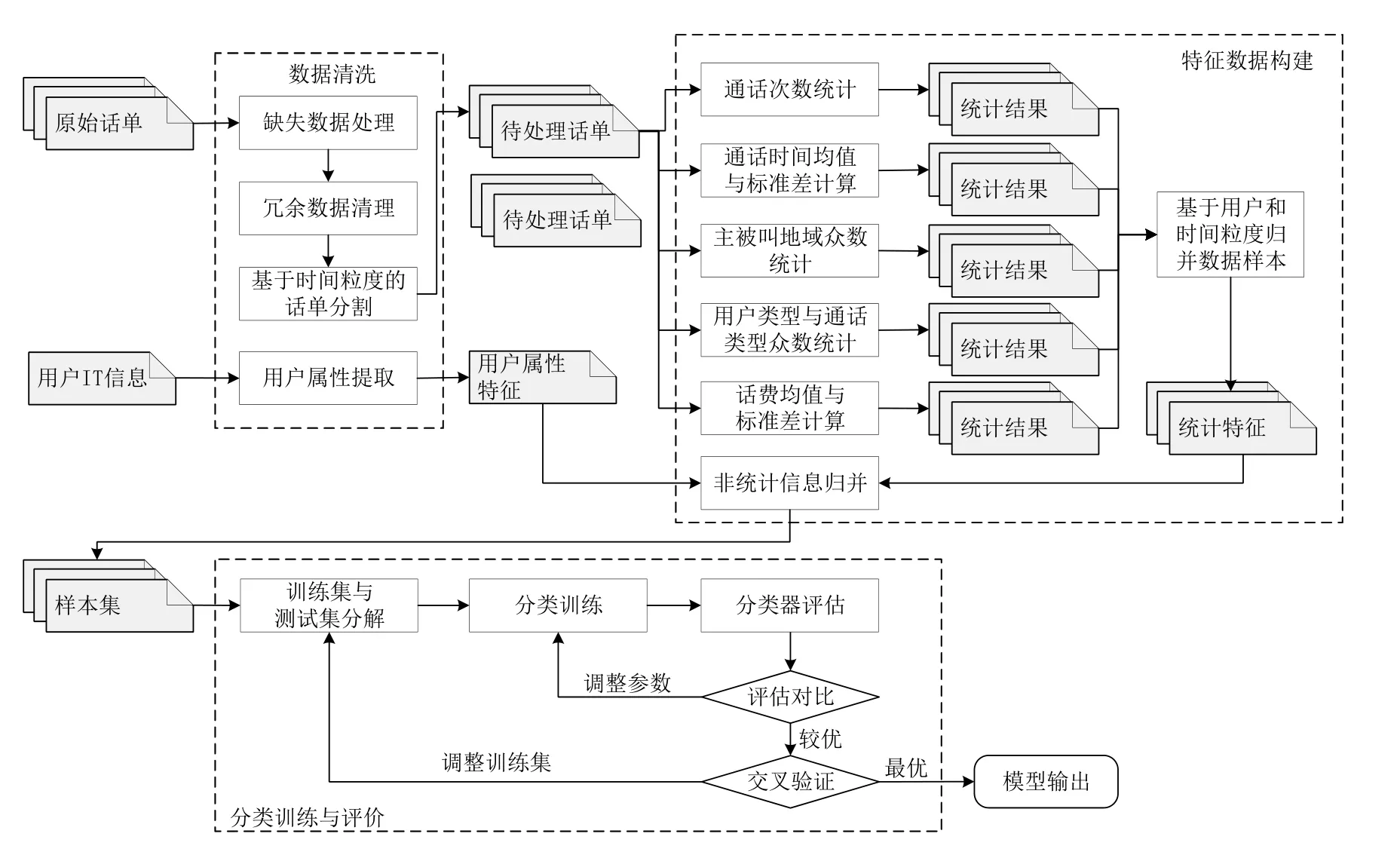
图3 电信诈骗行为特征分类器Fig.3 Telecom fraud behavior features classifier
数据清洗功能主要根据数据源的类型进行设置。本文根据原始话单和用户IT信息的差异,设置了两种数据清洗功能。第一种针对原始话单数据,首先进行缺失数据处理、冗余数据清理等操作,并根据时间粒度需求完成数据分割形成待处理话单,以进行统计分析。第二种针对用户IT信息,提取用户固有的开户时间、是否实名认证、用户使用产品类型等信息,并进行归一化处理。
特征数据构建功能则根据分类训练需求,对数据清洗后的待处理话单数据进行样本特征值处理,并根据时间粒度归并数据样本,形成统计特征。之后,将统计特征和以用户属性特征为代表的非统计特征进行整合,形成可用于训练和验证的样本集。
分类训练与评价功能中的训练集与测试集分解模块,首先按照 10%诈骗电话样本,90%普通电话样本的方式构建多份训练集与测试集,供后继学习评估使用。之后,分类训练模块使用选择的训练集对SVM模型进行分类训练。训练得到的分类器将在分类器评估模块中,使用选择的测试集进行测试评估。分类器评估模块通过多次调整 SVM 参数获得该分类器在不同输入参数下训练得到的准确率(Accuracy)、查全率(Recall)、查准率(Precision),并根据评估结果进行对比,选择准确率、查全率、查准率都较优的模型。同时,为了避免过拟合,分类器评估模块还将进行交叉验证,即控制训练集与测试集分解模块分解出不同的训练集与测试集供分类训练和分类器评估使用,从而获得最优的SVM分类器模型。
3.2 基于SVM的分类训练与评价功能设计
本文选用SVM实现分类器。SVM核函数类型主要有线性(Linear)内核、多项式(Poly)内核、径向基(RBF)内核、Sigmoid核等共4种。本文选择RBF内核,因为RBF核函数包容性很强,无论是多少数据量,不管数据高维还是低维,RBF内核均可以使用。同时RBF核函数可以将样本映射到一个更高维的空间,因此可以用于线性不可分的环境。本文构建的样本集中,各种特征差异较大,显然是线性不可分的,较为适合使用RBF核函数。使用样本集进行的初步验证表明,RBF内核在分类准确性上确实比其他内核具有较为明显的优势。
本文采用Scikit-Learn机器学习库实现SVM分类器,其中最重要的有两个参数,C和Gamma。C是分类器训练过程中对错误项的惩罚参数,C取值越小,泛化能力越强,但容易欠拟合;C取值越大,对训练样本间的差异利用的更全面,但容易过拟合,泛化能力越差。而Gamma则决定了样本集映射到特征空间后的分布,Gamma越小,训练准确率会提高,但泛化能力可能会减弱。为了提高电信诈骗行为特征分类器的准确率和对新数据的识别能力,需要通过实验仔细选择 C和 Gamma的取值。本文基于Scikit-Learn实现SVM分类器,Scikit-Learn开发库中,Gamma默认使用1/n-features,C默认使用1。由于本文采用了13个特征参数,因此将Gamma的寻优范围设置为0.01~0.15,将C的寻优范围设置为1~100,先根据不同参数组合所得的评价结果,缩小参数选择范围,之后本文引入随机参数寻优(RandomizedSearchCV)完成分类器评估,辅助进行 C和Gamma参数的调整,以确定最优值。同时,由于对固定测试集的反复学习容易导致模型陷入过拟合,降低分类器的泛化能力,因此,本文在分类器评估模块中使用 5折交叉验证(Cross-Validation)对训练完成的分类器进行检测,以避免陷入过拟合。
4 电信诈骗行为特征分类结果分析
本文从采用准确率(Accuracy)、查准率(Precision)、查全率(Recall)三个指标对电信诈骗行为特征分类进行评价。
本文首先对线性(Linear)内核、多项式(Poly)内核、径向基(RBF)内核等不同内核的指标计算结果进行了验证,如图4所示。图中,横轴是degree取值,纵轴是准确率、查准率、查全率的取值。从验证结果可以看到,不管是准确率、查准率还是查全率,RBF内核的效果都比线性内核和多项式内核效果要好。这验证了对用户行为分类这种指标较难线性划分的场景下,使用径向基内核是合适的选择。
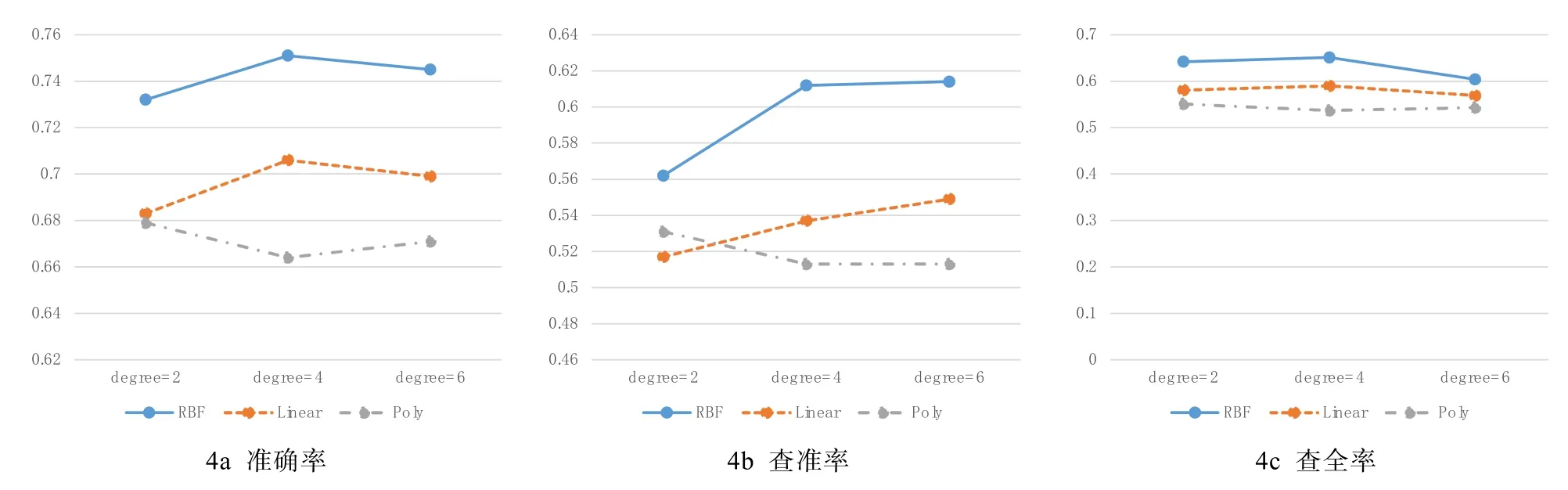
图4 不同内核SVM分类性能对比Fig.4 Different kernal based SVM classifier comparation
本文从采用准确率(Accuracy)、查准率(Precision)、查全率(Recall)三个指标对电信诈骗行为特征分类器的训练结果进行了验证,如图5所示。图5a是参数C取值为30时,不同的Gamma参数取值对准确率、查准率、查全率的影响。图5b是参数Gamma为0.07时,不同的C参数取值对准确率、查准率、查全率的影响。
从验证结果可以看到,Gamma参数在0.05~0.07左右取值,C参数在30左右,分类效果最好。随着Gamma参数和C参数的取值变化,准确率、查准率、查全率的效果也在交替变化。整体准确率在74%左右,整体查准率在 73%~76%左右,整体查全率在72%左右。本文提出的基于SVM的分类器能够满足电信诈骗行为筛选需求。
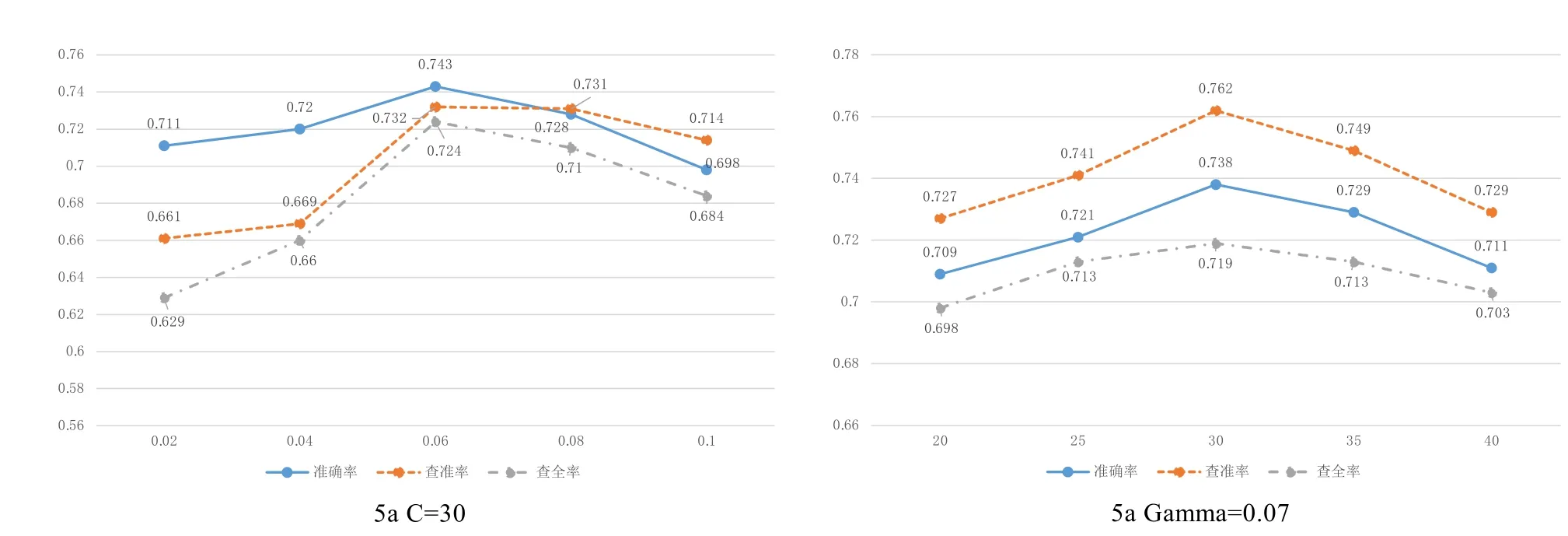
图5 不同参数SVM分类性能对比Fig.5 Different attributes based SVM classifier comparation
5 结论
本文分析了电信诈骗的行为规律,给出了一种基于话单记录等电信数据,通过SVM等机器学习手段,对电信诈骗行为识别的方法,完成了电信诈骗行为分类器的设计,并基于Scikit-Learn完成了分类器的实现,探讨了SVM相关参数的选择方法。最后根据实际数据的试验验证了分类器的性能。
未来可以进一步对电信诈骗行为特征样本数据的结构进行调整,引入更丰富的和更有区分度的特征,以进一步提高分类器的准确性。
[1] 周国民, 陈光宣, 周银座. 基于CDR分析的电信诈骗用户行为研究[J]. 信息安全与通信保密, 2015 (11): 114-118.ZHOU Guomin, CHEN Guangxuan,ZHOU Yinzuo. User Behavior in Telecommunication Fraud based on CDR Analysis[J]. Information Security and Communications Privacy,2015 (11): 114-118. (in Chinese)
[2] 360手机卫士, 360互联网安全中心. 2016诈骗电话态势与特征分析报告[OL]. [2016-10-31]. http://zt.360.cn/1101061855.php?dtid=1101062366&did=490128109360Security, 360 Internet Security Center. 360 Telecomm Fraud Situation and Feature Analysis Report [OL]. [2016-10-31]. http://zt.360.cn/1101061855.php?dtid=1101062366&did=490128109
[3] 360手机卫士, 360互联网安全中心. 2016诈骗电话活动规律与行为特征分析报告[OL]. [2016-10-31]. http://zt.360.cn/1101061855.php?dtid=1101062366&did=490106344360Secu rity, 360 Internet Security Center. 360 Telecomm Fraud Activity Pattern and Behavioral Characteristics Report[OL]. [2016-10-31]. http://zt.360.cn/1101061855.php?dtid=1101062366&did=490106344
[4] 许婷. 基于话单挖掘的可视化人物关系分析系统的设计与实现[D]. 黑龙江省哈尔滨市:哈尔滨工业大学,2014年.Xu Ting. The Design and Implementation of Visualization Character Relationship Analysis System Based on Mining of Call Records. Harbin, Heilongjiang Province: Harbin Institute of Technology, 2014.
[5] 张秀玲. 数据挖掘技术在电信客户欺诈分析中的应用[D].北京市: 中国石油大学, 2006年.Zhang Xiuling. Data Mining Techniques Applied to a Telecommunication Anti-fraud System[D]. Beijing: China University of Petroleum, 2006.
[6] 张瑜. 支持向量机在电信客户欺诈检测的应用研究[D].湖南省长沙市: 长沙理工大学,2010年.Zhang Yu. Study of SVM application to Customer Fraud Detection in Telecommunication [D]. Changsha, Hunan Province: Changsha University of Science&Technology,2010.
SVM Based Telecom Fraud Behavior Identification Method
JI Han-zhi1, MA Yu-chen2, LI Shuang2, LI Jing-lin2
(1. Beijing no.13 middle school, Beijing 100009, China; 2. Beijing University of Posts and Telecommunications Institute of Network Technology, Beijing 100876, China)
Telecomm Fraud is difficult to prevent because of the various categories and the widely distributed victims. This paper puts forward a SVM based Machine-Learning method to deal with the Telecomm Fraud technology trends, such as the utilization of newest telecommunication technology and the system vulnerabilities. The method used the call logs, which contained behavioral characteristics of the fraud users and common users, and combined with users’ properties to train a SVM based behavior classifier. The categorized results can help to distinguish the frauds and identify the fraud phone numbers. The paper analyzes the regular pattern of the behaviors of telecom fraud, put forward the extraction method of behavior characteristics and present the SVM-based behavior identification system. Finally, the feasibility of this method is verified by the actual sample dataset.
Big data; Machine learning; Support vector machine; Telecomm fraud
TP391.4
A
10.3969/j.issn.1003-6970.2017.12.020
本文著录格式:吉涵之,马宇宸,李爽,等. 基于SVM的电信诈骗行为特征识别方法[J]. 软件,2017,38(12):104-109
国家自然科学基金(61571066)
吉涵之,女,主要研究方向:数据挖掘;马宇宸(1994-),男,主要研究方向:深度学习与机器学习;李爽(1993-),女,主要研究方向:机器学习。
李静林,副教授,主要研究方向:融合网络与服务。
