基于数据挖掘的4G用户投诉预测
2017-12-26陈秀敏许向东黄毅华于文
陈秀敏,许向东,黄毅华,于文
(1.中国电信股份有限公司广州研究院,广东 广州 510630;2.北京师范大学珠海分校,广东 珠海 519085)
基于数据挖掘的4G用户投诉预测
陈秀敏1,许向东1,黄毅华1,于文2
(1.中国电信股份有限公司广州研究院,广东 广州 510630;2.北京师范大学珠海分校,广东 珠海 519085)
4G网络运营中,存在性能指标虽好,但仍有用户感知差而投诉的问题,性能指标不能正确反映用户的真实感知。因此,提出了一种基于数据挖掘的4G用户投诉预警的方法,首先根据投诉工单对投诉类型进行分类,并提出各个类型的用户特征的提取方法,然后利用数据挖掘预测投诉用户。该方法可快速分析出用户投诉的原因,或在用户投诉之前便发现并解决问题,提升4G用户体验。
数据挖掘 4G用户感知 投诉类型 预测模型
1 引言
随着移动互联网业务的迅猛发展,4 G相比2G/3G,网络速度更快、效率更高、兼容性更强、自动调节能力和适应性更强、数据处理灵活性更高,因此各大运营商都投入了大量的资源用于4G业务的发展。然而,随着产品类型趋同,运营商急需将网络运维管理的焦点从网络质量转移到以客户为中心的客户体验,改善用户感知已成为运营商亟待解决的问题。用户感知是终端用户对一些服务质量或整体网络的感受,万用户投诉比是评价用户感知的一个重要方面,如果能及时预测用户的投诉情况,在投诉事件发生前就能采取有效措施,必然能提升客户的体验满意度,增加用户黏度。
在实际网络运营中,许多潜在有用的信息被海量的、有噪声的、随机的、模糊的实际应用数据所掩盖,传统的分析方法往往不易察觉,数据挖掘技术可以很好地解决以上难题。本文主要研究并开发了一个预测4G用户投诉的框架,可根据以往用户的数据,采用不同分类算法,预测一个4G用户是否会进行投诉,同时,总结了4G用户投诉预测所需的有效特征值。
2 4G用户投诉预测模型的选择
4G用户投诉预测模型的选择,需要考虑以下问题:一是当前网络运营数据有MR(测量报告)、无线CDR(呼叫详细话单)、无线性能指标、计费话单、核心网CHR(历史呼叫记录)、业务DPI(深度包解析)等大量数据记录,但不可以直接用于建模,需要进行关联串接提取建模所需特征;二是模型特征确定后,存在数据不平衡、用户数据空缺等问题,需要对建模数据进行预处理;三是模型的算法非常多,如何选择合适模型算法对预测效果至关重要,为解决以上问题,本文采用CRISP-DM流程来规范模型的搭建,共分为6个阶段。
CRISP-DM全称为Cross-Industry Standard Process for Data Mining,也就是“跨行业数据挖掘标准流程”[2],该模型于1999年由欧盟机构联合起草,经过十几年的发展,如今已经成为事实上的行业标准,在各种数据挖掘过程模型中占据领先位置,调查显示,CRISP-DM的数据挖掘流程为多数数据挖掘工具所采用,比例在50%以上。
本文在这个模型的基础上(如图1所示),结合本项目特点,总结出适合4G用户投诉预测的数据挖掘过程如下:
(1)业务理解/商业理解(Business Understanding):理解项目目标,首先从业务的角度理解项目需求,再将项目需求转化为数据挖掘问题,即预测4G用户是否投诉。
(2)数据理解(Data Understanding):收集包含31个特征值的4G用户的原始数据,并且通过对数据的相关性进行分析等初步处理来熟悉数据。
(3)数据准备(Data Preparation):通过对上一阶段收集的数据进行分析,共整理出如表1所示的31个特征值,详见第3节。
(4)建模(Modeling):选择和应用不同的学习算法和模型技术,将模型参数调整到最佳的数值,详见第4节。
(5)评估(Evaluation):采用正规技术评审和正规审查等方法,检查构造模型的开展顺序,并充分地考虑所有重要业务问题以确保模型能够完成挖掘目标。
(6)部署(Deployment):将模型应到大规模的实际数据中。
在上述6个阶段中,前3个阶段主要依靠网络优化和行业运营经验来完成,数据准备阶段是前3个阶段的初步成果,同时也是整个数据挖掘的基础,如果这个阶段出现问题,后面所有的工作都会受到影响。而建模阶段是关键,选择不同的算法或不同的参数往往对预测结果影响较大,模型的评估方法也会在模型的求解过程中应用。因此,数据准备和建模中的关键问题将分别在下面两节中详细阐述。一般情况下,前5个阶段通常需要不断地循环以找到最优方案,如图1所示,评估阶段结束标志着一个成熟的数据挖掘流程已经形成。

图1 跨行业数据挖掘标准流程[3]
3 数据准备
数据准备阶段主要对原始的用户数据进行处理,通过采集无线MR、无线CDR、无线性能指标、计费话单、核心网CHR、业务DPI等数据、分析数据特点、用户端到端数据(无线、核心网及互联网)的关联及串接,如图2所示,进而转化成和4G用户投诉预测(无信号或信号弱)相关的特征值,如表1所示。
在用户的投诉中,无信号或信号弱所占的比例比较大,也是本文研究的重点,对其他如速率慢、掉线、应用打不开和有信号无法使用等方面投诉的预测,也可以使用类似的方法和过程。

图2 端到端数据关联串接

表1 4G用户投诉预测(无信号或信号弱)所需特征值
在特征值提取的过程中,主要考虑投诉现象的平均次数、持续时长、发生频度、位置集中度以及异常时长占比等因素,通过均值、方差、分位值、百分比、百分比区间、TOP N、变异系数等7个维度,完成了用户每日数据的汇聚,根据全省周申告用户数与活跃用户的比例设置建模数据中投诉用户数据的占比。
值得注意的是,此阶段总结的31个特征值,只是根据领域专家的经验,从业务的角度对数据进行分析而得出的。在后期的建模过程中,有些技术在数据形成上有特殊要求,因此需要在此基础上对特征值进行进一步选择或提取。
4 建模
通过前面的业务理解、数据理解和数据准备阶段,用户的特征值已经确定(如表1所示),本阶段的主要任务是根据这些特征值,选择适当的分类算法及参数,使预测结果达到最优。
训练过程往往不是仅使用一种算法,而是采用多种算法,比较其训练结果来选择合适的算法。根据训练任务不同,训练算法可分为分类算法、回归算法以及聚类算法等。预测4G用户是否会产生某种类型的投诉,属于离散型的分类问题,训练样本包含对应的“标签”,即“投诉”与“不投诉”两类,所以在选择分类算法上,文章选择逻辑回归、决策树等4种算法。在使用算法进行数据训练之前,需要对源数据进行特征选择和数据预处理,本文采用递归特征消除(RFE)算法进行特征选择,采用SMOTE算法和处理缺失值数据集对不规则数据进行预处理。整个框架如图3所示,左侧是模型创建的流程,根据不同的算法,可创建不同的模型;右侧是模型使用的流程,即对用户是否投诉进行预测。接下来的几节详细描述了建模过程的每个步骤。
数据挖掘的数据集一般分成两部分,训练集用于训练模型,测试集用于验证模型。本文采用广泛使用的十折交叉验证(详见第4.4节),即将数据集分成10份,训练集占9/10,测试集占1/10。为了说明特征选择和数据预处理对分类结果的影响,后面几小节统一采用了逻辑回归算法进行分类,主要评价指标为F1值,有些使用了辅助指标精确率(Precision)和召回率(Recall)。分类算法和评价指标的详细介绍参见第4.3节和第4.4节。
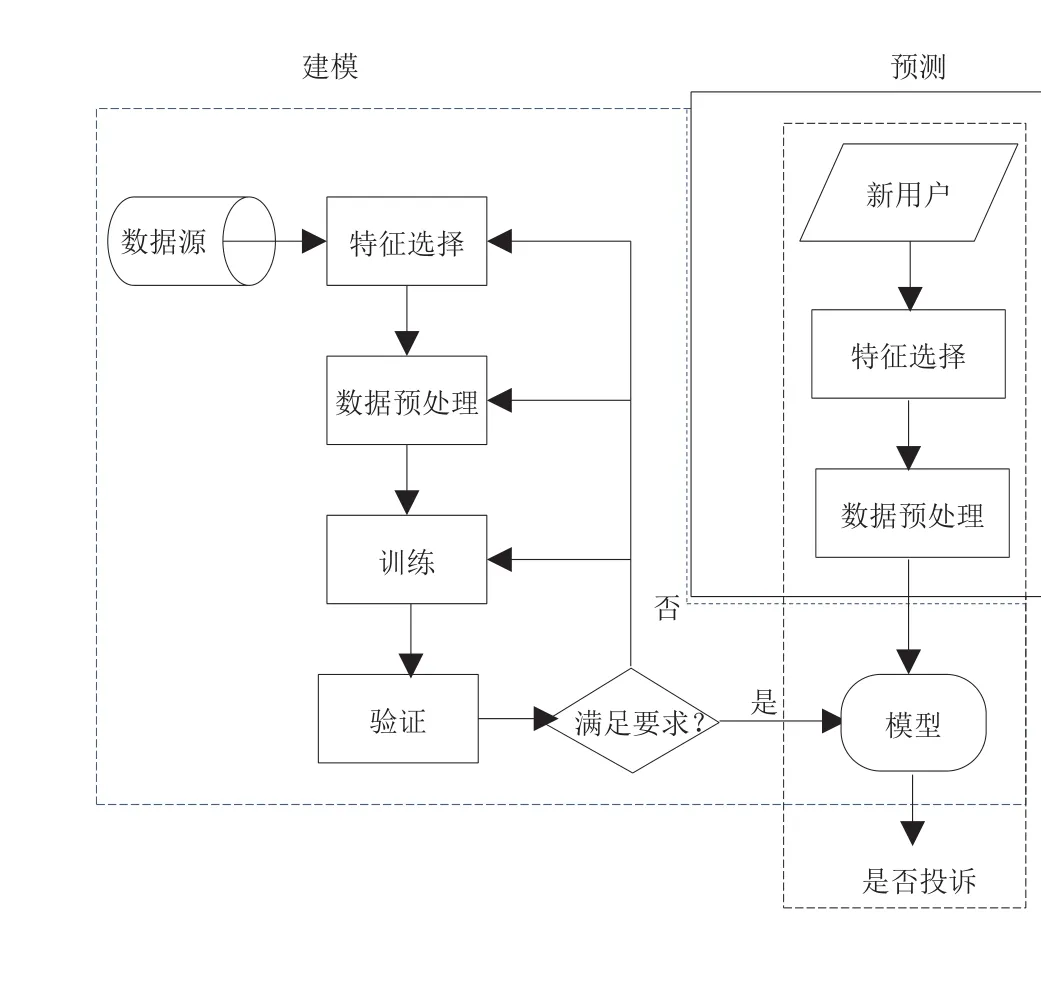
图3 4G用户投诉预测框架
4.1 特征选择
使用不同算法进行预测,用户的特征值对预测结果影响有可能不同,因此在建模时需要首先对特征值做进一步的选择或提取。
特征选择也叫特征子集选择(FSS, Feature Subset Selection),是指从已有的M个特征(Feature)中选择N个特征,使得系统的特定指标最优化。如果样本的特征值过多,会影响学习算法的性能,也会使分类器产生过拟合的现象。特征选择是数据挖掘中关键的数据预处理步骤,因此通常将其与其他数据预处理分开,单独进行研究。
最常用的产生特征子集的算法为搜索法,本文研究了其中的递归特征消除(RFE)算法,其主要思想是反复地构建模型,然后选出最好的特征(贪心算法),然后在剩余的特征上重复这个过程,直到所有特征都遍历了。这个过程中,特征被消除的次序就是特征的排序。将这种算法应用到4G用户数据,采用逻辑回归算法构建模型(逻辑回归算法的介绍见第4.3节),得到的最佳特征值个数为9个,如图4所示。当采用不同算法进行预测时,得到的最佳特征值可能会不同。

图4 使用递归特征消除算法进行特征选择的结果
4.2 数据预处理
4G用户数据中,正类(投诉数据,少数类)和反类(不投诉数据,多数类)数量的差别很大,存在类不平衡的问题,同时存在大量的缺失值,因此数据的预处理主要围绕着这两方面进行。
非平衡数据处理:一般采用欠采样(删除多数类的样本)、过采样(复制少数类的样本)或SMOTE(合成少数类样本)等方法。SMOTE可以看作是一种特殊的过采样技术,即把每个样本看成高维空间的一个点,然后用线段连接这个点到某个邻近的点,取线段上的某点作为合成的一个新的点(样本)。采用逻辑回归算法时,采用SMOTE算法对11月份及之前的数据进行非平衡数据处理和不进行处理对结果的影响如图5所示。从图中可以看出,先将数据进行平衡以后,对分类器的精确率影响不大,但召回率和F1值有明显提高。

图5 数据平衡处理结果对比
处理含有缺失值数据集的方法主要有以下几类:删除元组(删除有缺失值的样本);用平均值补齐;用中位数补齐;用众数补齐。
本文分别用上述几种方法处理缺失值,得出如图6所示的结果。从图中可以看出,删除有缺失值的样本后再进行预测效果最好,其他三种方法差别不大。但由于数据中有缺失值的样本较多,删除这些样本会丢失一些重要信息,并不能反映出数据的真实规律,因此本项目不适合采用这种方法。另外,根据删除有缺失值的样本后的数据训练的模型,不能对有缺失数据的新用户进行预测。
另外,不同特征值取值范围可能并不相同,如果不加处理,在分类的过程中,量纲较大的特征值往往主导了分类结果。为了改进分类的效果,解决数据指标之间的可比性的问题,需要进行数据标准化处理,本文将数据规约到了[0, 1]区间内。如图7所示,归一化处理后的分类结果有明显改善。

图6 缺失值处理结果对比

图7 数据归一化处理结果对比
4.3 训练算法
模型的训练师指采用适当的算法构造分类器的过程。本文分别采用了逻辑回归、决策树、随机森林和K邻近这4种具有分类功能的算法训练模型,下面简单介绍其主要原理。
虽然名字里带“回归”,但是逻辑回归常常用来分类,主要用于两分类问题(即输出只有两种,分别代表两个类别)。逻辑回归算法使用逻辑回归函数对数据进行拟合,其预测的值为,而xj为特征值,θj为未知的系数,n为特征值的个数。逻辑回归函数的值介于[0, 1]之间,如图8所示,使得其适合于拟合0~1分类问题。

图8 逻辑回归算法示意图
决策树是一种归纳学习算法,以实例为算法基础,其结果是以树表示的分类规则(if-then-else)。决策树算法采用由上向下的递归的方式在内部节点进行属性值的比较,并从该节点根据不同的属性值向下分支,而叶节点就是我们要学习划分的类。从根节点到叶节点的一条路径就对应着一条合取规则,整个决策树就对应着一组析取表达式规则。决策树算法是一类算法的总称,不同决策树算法的主要区别是怎样选择结点的属性使其分类能力达到最优,通常使用信息增益来衡量给定的属性区分训练样例的能力(例如ID3算法),而信息增益使用熵(Entropy)来刻画任意样例集的纯度。给定样例集S,如果目标属性具有c个不同的值,那么S相对于c个状态的分类的熵为其中pi是S中属于类别i的比例。信息增益,其中Value(A)是属性A所有可能值的集合,Sv是S中属性A的值为v的子集。
随机森林算法是用很多的决策树以随机的方式建立一个森林。随机森林中的每一棵决策树之间没有关联。算法在运行过程中分为两步:第一步是当有一个新的输入样本进入随机森林的时候,便让每一棵决策树分别进行一次投票判决,得出这个样本应该属于哪一类,第二步是统计哪一类被选择最多,就将被预测样本归为那一类。
KNN是最基本的基于实例的算法。该算法将所有的实例分别对应转换为n维空间中的点,用标准欧式距离定义一个实例的最近距离。KNN算法的思路是在特征空间中,如果一个样本的k个特征空间中最邻近的样本中的大多数属于某一个类别,则将该样本也归入这个类别。
4.4 模型的评估方法
模型的验证需要利用未参与建模的数据进行,这样才能得到比较准确的结果,交叉验证就是其中最常用的一种方法。常用的K折交叉验证,将样本集随机地分割成K个集,一个子集用来验证,另外K-1个子集的合集用来训练。交叉验证重复K次,每个子集验证一次,最终的结果为K次运行的结果的平均值。
模型的评价指标是数据挖掘过程中非常重要的一环。不同的数据挖掘问题有着不同的评价指标,而与算法的关系不是很明显。4G用户投诉预测属于数据挖掘中的分类问题,这类问题常用的评价指标有准确率(Acc, Accuracy)、精确率(P, Precision)、召回率(R, Recall)等,根据表2所示的混淆矩阵,这些指标定义如下:


表2 混淆矩阵
在本文中,准确率表示被正确预测的用户数占用户总数的比例;精确率表示预测的投诉用户有多少是真正的投诉用户;召回率表示所有的投诉用户中有多少能被模型正确地预测出来的比例。在4G用户投诉预测的过程中,由于错误地将投诉用户预测为非投诉用户的代价远远大于错误地将非投诉用户预测为投诉用户,一般的分类正确率、精确率和召回率难以判定一个模型的好坏,因此本文采用综合指标对模型进行评价。
4.5 结果及分析
使用上述4种算法对4G用户投诉进行预测,结果如表3所示。为了和后面的结果进行比较,这里使用了2折交叉验证。从表中可以看出,4种算法都取得了较好的预测效果。但是,取得这种结果的一个很重要的前提是,根据文献[5]中提出的建议,在数据预处理阶段,就利用SMOTE算法对整个数据集进行了平衡处理,然后将处理后的数据作为正常的数据集使用。

表3 不同算法对4G用户投诉的预测结果(对测试数据进行平衡处理)
然而,我们认为平衡处理后的数据与处理前有较大的差异,用处理后的数据集对模型进行验证并不能反映出模型真正的分类效果,因此修改了数据平衡的策略,只对训练数据进行平衡处理。由于数据类别的极度不平衡,如果采用广泛使用的十折交叉验证,测试数据中有可能不包含少数类(投诉数据),因此将训练数据和测试数据的比例修改为1:1。修改后的运行结果如表4所示:

表4 不同算法对4G用户投诉的预测结果(未对测试数据进行平衡处理)
从表中可以看出,逻辑回归算法的分类结果的召回率最高,如果将投诉用户错误地分类成非投诉用户的代价较高,应考虑采用这种算法。而随机森林的综合评价指标F1值最高,召回率和精确率也较其他算法有较好的表现,因此推荐使用这种算法。
5 结束语
数据挖掘可以用来解决预测4G用户是否投诉的问题,即通过机器学习算法搜索隐藏于大量运营数据中的特定属性的值。本文采用CRISP-DM流程,着重介绍数据准备和建模两个阶段的关键问题,并用实际运营数据检验模型,得出数据处理方法和不同模型算法对预测效果的影响。机器学习以大量用户的运营数据为经验,模拟或实现人类的学习行为,从而提高预测的正确率和准确率。
本文提出的模型在实际应用中,由于QoE会随网络及用户要求变化而波动,训练样本可以采集最新周期的数据,保证模型可以实时有效反应网络质量,发现网络问题。
[1] 王锐,严炎. 用户体验质量评估方法浅析[J]. 移动通信,2012,36(13): 57-60.
[2] Shearer C. The CRISP-DM model: the new blueprint for data mining[J]. Data Warehousing, 2000(5): 13-22.
[3] Harper G, Pickett S D. Methods for mining HTS data[J].Drug Discovery Today, 2006,11(15-16): 694.
[4] 钟鼎. 基于神经网络的4G用户感知预警模型构建和应用[J]. 电信技术, 2016(11): 76-78.
[5] Chawla N V, Bowyer K W, Hall L O, et al. SMOTE:synthetic minority over-sampling technique[J]. Journal of Artif i cial Intelligence Research, 2002,16(1): 321-357.
[6] SOLDANI D. Means and Methods for Collecting and Analyzing QoE Measurements in Wireless Networks[J].WoWMoM, 2006(5): 535.
[7] 杨宗长,徐继生,孙洪. 基于免疫算法的移动通信用户信用度评估研究[J]. 电子测量与仪器学报, 2009,23(8):105-110.
[8] LASALLE D, TERRY A BRITTON. Priceless: Turning Ordinary Products into Extraordinary Experiences[M].Boston: Harvard Business School Press, 2003.
[9] 王文婧,曲佰达,段然. 移动云计算用户QoE的模糊综合评价研究[J]. 互联网天地, 2015(1): 18-25.
[10] 林闯,胡杰,孔祥震. 用户体验质量(QoE)的模型与评价方法综述[J]. 计算机学报, 2012,35(1): 1-15. ★
Prediction of 4G User Complaints Based on Data Mining
CHEN Xiumin1, XU Xiangdong1, HUANG Yihua1, YU Wen2
(1. Guangzhou Research Institute of China Telecom Co., Ltd., Guangzhou 510630, China;2. Beijing Normal University Zhuhai Campus, Zhuhai 519085, China)
There is still the problem in the operation of 4G networks that users complain against the bad user perception, even though the performance metrics are satisfactory. In other words, the performance metrics can not re fl ect accurately represent the real perception of users. Therefore, a complaint warning method for 4G users based on data mining was put forward. Firstly, the types of complaints were classified according to complaint orders and the feature extraction methods for different types of users were presented. Then, the complaint user was predicted using data mining. The proposed method can fast find out the cause of user complaints or discover and solve the problem before the user complaint to enhance 4G user perception.
data mining 4G user perception type of complaint prediction model
10.3969/j.issn.1006-1010.2017.21.007
TN929.5
A
1006-1010(2017)21-0030-07
陈秀敏,许向东,黄毅华,等. 基于数据挖掘的4G用户投诉预测[J]. 移动通信, 2017,41(21): 30-36.
2017-09-27
黄耿东 huanggengdong@mbcom.cn

陈秀敏:硕士毕业于华南理工大学,现任职于中国电信股份有限公司广州研究院移动通信研究所,主要研究方向为无线网络优化及仪表应用与数据挖掘。

许向东:毕业于北京邮电大学,现任职于中国电信股份有限公司广州研究院,主要负责移动网络优化技术管理工作。

黄毅华:硕士毕业于中山大学,现任职于中国电信股份有限公司广州研究院,主要从事网络优化研究工作。
