基于邻域粗糙集的连续值分布式数据属性约简
2017-12-20胡军,王凯
胡 军,王 凯
(重庆邮电大学 计算智能重庆市重点实验室,重庆 400065)

基于邻域粗糙集的连续值分布式数据属性约简
胡 军,王 凯
(重庆邮电大学 计算智能重庆市重点实验室,重庆 400065)
为了去除系统中的冗余属性,保持系统的分类能力,研究了连续值分布式数据的属性约简。给出了连续值分布式决策信息系统中邻域粗糙集的定义,讨论了分布式连续值决策信息系统中正域计算的可分解性。以保持分布式决策信息系统的正域不变为前提,探讨了分布式决策信息系统中属性的可约性,提出了分布式连续值决策信息系统的属性约简算法。为了验证该算法的有效性,在7份数据集上进行了3组实验。实验使用提出的算法对分布式数据进行属性约简,进而采用加权集成的方式进行分类测试。实验结果表明,该算法能够有效去除连续值分布式数据中的冗余属性,使得约简后的连续值分布式数据的集成分类能力与约简前相差不大,甚至更高。
连续值;分布式数据;属性约简;邻域粗糙集;分布式决策信息系统
0 引 言
随着计算机网络的高速发展,数据往往并不集中存储在一个数据库中,而是分布在网络中的多个存储结点上。传统的数据挖掘方法在处理分布存储的数据时,需要将这些数据进行集中,才能进行有效处理。然而,在很多实际问题中,由于带宽的限制、隐私保护等原因,将数据进行集中处理往往是不可行或者是不可能的。针对该问题,研究者进行了许多有益的尝试,并在分布式分类,聚类,关联规则挖掘等方面取得了初步成果[1-7]。
属性约简作为数据挖掘的一种预处理手段,它能够从条件属性集中删除冗余的属性,提高知识获取的速率[8]。文献[9]基于条件信息熵,提出了垂直分布多决策表的近似约简方法,该方法并行计算各局部站点相应的条件信息熵,在网络内部传送部分等价类,最终得到垂直分布多决策表的近似约简,理论分析和实验结果都表明,该算法能够明显减少网络通信代价。文献[10]提出了安全的集合求交集算法和安全的矩阵相加算法,设计了基于可辨识矩阵的属性约简算法,解决了垂直分布和水平分布数据集的属性约简问题,具有隐私保护的特点。文献[11]基于半诚实的第三方、交换加密技术及相对知识粒度的概念,解决了垂直分布数据在隐私保护下的属性约简问题。这些方法分别基于减少网络通讯代价和隐私保护的目的,从传统粗糙集的角度,以信息粒度的融合的方式提出了属性约简方法。
为了简化分布式数据,同时不降低分布式数据的分类能力,文献[12]研究了分布式环境下的粗糙集理论,定义了分布式决策信息系统,并基于此提出了分布式决策信息系统的属性约简算法。该算法最大程度地降低了网络的通信代价,并能保证约简后的分布式决策信息系统的分类能力与约简前基本相当。但是,该方法仅适用于符号型分布式数据的属性约简问题,对于连续值、混合型等形式的分布式数据却不适用。针对该问题,本文继续了文献[12]的研究工作,给出了分布式连续值决策信息系统的定义,提出了分布式连续值决策信息系统的属性约简算法,并使用分类集成的方法验证了该算法能够有效地约简分布式连续值决策信息系统的冗余属性,且不降低其分类能力。
1 基本概念
1.1 邻域粗糙集
邻域粗糙集模型通过将经典粗糙集中的等价关系拓展成邻域关系,从而解决了经典粗糙集模型不能处理连续值的问题,其定义如下[13]。
定义1IS=(U,A,Δ,δ)是一个信息表,U是一个有限非空的样本集合,称为论域;A是非空属性集;Δ是一个距离函数;δ是一个距离阈值,δ≥0;对于∀xi∈U,∀B⊆A,xi相对于属性子集B的邻域记为δB(xi)={xj∈U|ΔB(xi,xj)≤δ}。
对于每个样本子集X⊆U,根据属性子集B可确定X的上近似集和下近似集分别为B-(X)={xi∈U|δB(xi)∩X≠∅},B-(X)={xi∈U|δB(xi)⊆X}。
如果将定义1中的非空属性集A划分为条件属性集C和决策属性集D,即A=C∪D,则定义1中的信息表就成为一个决策信息表。
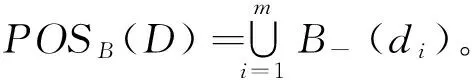
对于信息表及决策信息表中的距离函数Δ,可以选用的距离函数有曼哈顿距离,欧氏距离,切比雪夫距离等,其中,欧式距离在实际应用中最为常见。距离阈值δ和属性子集B决定了邻域样本集合,对于确定的属性子集,δ越大,每个样本的邻域集合越大;δ越小,每个样本的邻域集合也就越小。因此,选择一个合适的δ对连续值数据的属性约简非常重要。
1.2 分布式邻域粗糙集
文献[12]中提出了分布式决策信息系统的概念,并给出了分布式决策信息系统的属性约简算法,为分布式数据的知识约简提供了方法。但是,文献[12]仅讨论了属性值是符号值的情况,下面给出当属性值为连续值时分布式邻域粗糙集的定义。
令Γ={S1,S2,…,Sn}是一个分布式连续值决策信息系统,其中,Si=(Ui,Ci∪D,Δ,δ)是一个决策表。分布式决策信息系统存在有2种情况:①基于实例分布的(又称为水平分布);②基于属性分布的(又称为垂直分布)。这里主要研究基于属性分布的连续值决策信息系统。
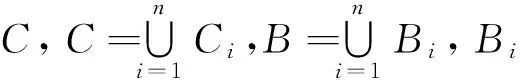
D相对于条件属性子集B的正域为POSB(D)={x∈U|∃Si∈Γ∧dj∈U/D(δBi(x)⊆dj)}。
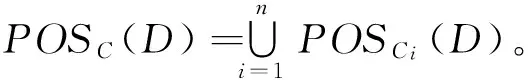
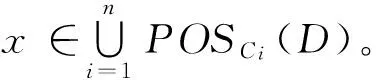
由定理1可知,分布式连续值决策信息系统的正域可以通过子决策表的正域来间接计算。
2 分布式连续值决策信息系统的属性约简
属性约简能够删除数据中冗余的属性,提高后续数据处理的效率,常常作为数据挖掘,机器学习,模式识别等的一种数据预处理手段。下面将基于前面提出的分布式邻域粗糙集研究分布式连续值决策信息系统的属性约简。
定理2分布式连续值决策信息系统Γ={S1,S2,…,Sn},Φ和Ψ是Γ的2个子集。如果Φ⊆Ψ,那么,POSΦ(D)⊆POSΨ(D)。
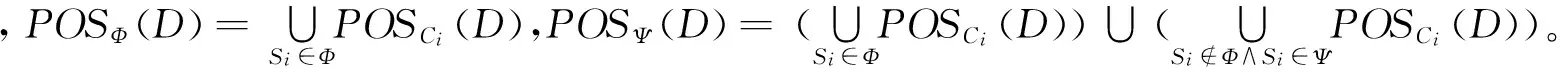
根据定理2可知,如果在一个分布式连续值决策信息系统中增加一个决策表,则其正域将会增大或保持不变。相反,如果从一个分布式连续值决策信息系统中删除一个决策表,则其正域将会减少或保持不变。
定义4对于一个分布式连续值决策信息系统Γ={S1,S2,…,Sn},若POSΓ-{Si}(D)=POSΓ(D),则相对于Γ,子决策表Si是可约简的;否则是不可约简的。
定理3对于一个分布式连续值决策信息系统Γ={S1,S2,…,Sn},如果POSCi(D)⊆POSΓ-{Si}(D),则子决策表Si是可约简的。
证明由定理1知,POSΓ(D)=POSCi(D)∪POSΓ-{Si}(D)。如果POSCi(D)⊆POSΓ-{Si}(D),则POSΓ(D)=POSΓ-{Si}(D),即Si是可约简的。
定理4对于一个分布式连续值决策信息系统Γ={S1,S2,…,Sn},当且仅当∃x∈U(x∈POSCi(D)∧x∉POSΓ-{Si}(D)),子决策表Si是不可约简的。
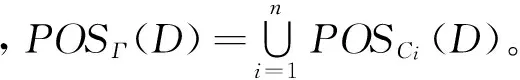

定理5对于一个分布式连续值决策信息系统Γ={S1,S2,…,Sn},a是子决策表Si的一个属性。在Si中,如果a是可约简的,则在Γ中,a也是可约简的。
证明在Si中,如果a是可约简的。即从Si中删除属性a后,其正域保持不变。由定理1,Γ的正域是各子决策表正域的并集,则Γ的正域也保持不变,即在Γ中a也是可约简的。
然而,定理5的逆并不成立,即如果a是Si中不可约简的,而a不一定是Γ中不可约简的。这即是说去掉一个子决策表中的一个属性可能会导致子决策表的正域减少,但不一定导致整个信息系统的正域也减少。
定义6Γ={S1,S2,…,Sn}是一个分布式连续值决策信息系统,Θ={T1,T2,…,Tn}是Γ的一个子系统,其中,∀Ti∈Θ(∃Sj∈Γ(Ti⊆Sj))。当满足以下2个条件时,相对于决策属性集D,Θ是Γ的一个约简子系统。
①POSΘ(D)=POSΓ(D);

根据定义5和定义6可知,一个分布式连续值决策信息系统Γ的约简子系统Θ与Γ具有相同的分类能力,而从Θ中删除任何一个属性都将降低其分类能力。基于此可以给出分布式连续值决策信息系统的属性约简算法。
算法:分布式连续值决策信息系统属性约简算法。
输入:Γ={S1,S2,…,Sn},δ
输出:约简后的分布式连续值决策信息系统Θ
1:令Θ=Γ
2:for每一个决策信息表Si∈Γdo
3: for每一个条件属性a∈Sido
5: 从Γ中删除a
6: end if
7: end for
8:end for
对于给定的分布式连续值决策信息系统Γ,根据算法依次遍历Γ中的决策信息表Si中的所有属性,如果某个属性满足定义5的条件,则删除该属性,否则保留该属性。直至遍历完所有决策信息表的所有属性,即可得到一个约简的子系统。下面通过一个实例来说明算法的执行过程。
表1是一个分布式连续值决策信息系统Γ,Γ中有2个决策信息表,分别是S1和S2,其中,S1有3个连续值条件属性(C1={a1,a2,a3}),S2有2个连续值条件属性(C2={a4,a5}),类别是决策属性。
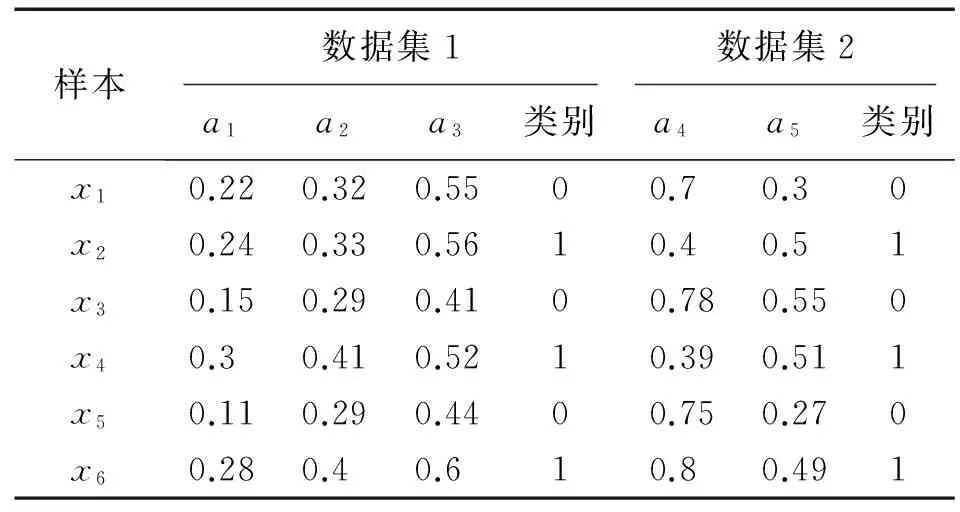
表1 分布式连续值决策信息系统Tab.1 Distributed continuous-valued decision information system
首先对Γ进行归一化处理,然后根据约简算法对Γ进行属性约简,具体过程如下。其中,距离度量公式采用欧式距离,距离阈值δ为0.3。
对于数据集1:
δC1(x1)={x1,x2},δC1(x2)={x1,x2},
δC1(x3)={x3,x5},δC1(x4)={x4},
δC1(x5)={x3,x5},δC1(x6)={x6},
U/D={{x1,x3,x5},{x2,x4,x6}}。
由定义2可得POSC1(D)={x3,x4,x5,x6}。
对于数据集2:
δC2(x1)={x1,x5},δC2(x2)={x2,x4},
δC2(x3)={x3,x6},δC2(x4)={x2,x4},
δC2(x5)={x1,x5},δC2(x6)={x3,x6},
U/D={{x1,x3,x5},{x2,x4,x6}}。
由定义2可得POSC2(D)={x1,x2,x4,x5}。
由定理1可得POSΓ(D)=POSC1(D)∪POSC2(D)={x1,x2,x3,x4,x5,x6}。
依据属性约简的定义对每一个决策表中的属性进行判断。
例如对于数据集1,若删除属性a1,则
δC1-{a1}(x1)={x1,x2},δC1-{a1}(x2)={x1,x2},
δC1-{a1}(x3)={x3,x5},δC1-{a1}(x4)={x4},
δC1-{a1}(x5)={x3,x5},δC1-{a1}(x6)={x6}。
POSC1-{a1}(D)={x3,x4,x5,x6}。
可以发现,POSΓ(D)={x1,x2,x3,x4,x5,x6}保持不变,因此,根据约简的定义属性a1是可约的。
按照同样的方法依次对剩余的属性进行判断,可以发现a3也是可约的,而a2、a4和a5是不可约的。因此,Γ约简后的属性子集是{a2,a4,a5}。
3 实验结果及分析
为了验证本文设计的算法的有效性,这里设计了3组对比实验,每组实验分别进行10次。实验框架如图1所示,具有n个数据站点的分布式数据集首先使用本文提出的算法进行约简,然后将约简后的各数据子集分别进行训练得到相应的分类器,最后通过加权集成验证属性约简对系统分类性能的影响。
在进行加权集成时,权重计算公式选用集成学习算法boosting中常用的计算公式[14],目的是使准确率高的分类器获得较大权重,权重公式为

(1)
(1)式中,准确率为十折交叉验证得到的准确率,错误率=1-准确率。
对于待分类样本,将不同分类器上样本的同类别概率加权求和,确定概率最大的类别为该样本的最终类别,计算公式为
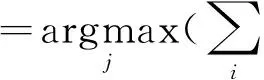
(2)
(2)式中,xij为分类器i计算的样本x属于类别j的概率。
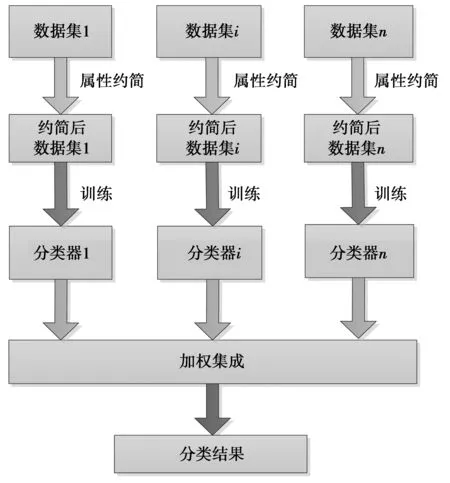
图1 实验框架图Fig.1 Experiment Framework
实验所用7份数据集下载于UCI机器学习数据库(http://archive.ics.uci.edu/ml/index.html),各数据集如表2所示。为了模拟分布式决策信息系统,各数据集被随机分割成n份。实验中距离函数采用常用的欧式距离,阈值δ的设定参考了文献[13]得出的最优阈值区间,具体选用的阈值为[0.1,1]。
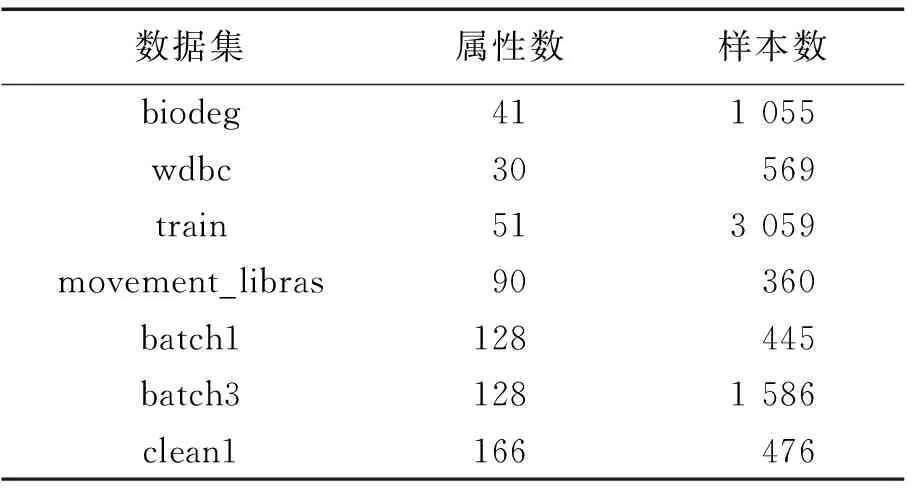
表2 数据集Tab.2 Datasets
图2是当n分别取3,4,5时得到的具有n个数据站点的分布式连续值决策信息系统约简后属性总数的均值与约简前属性总数的对比。从图2中可以看出,3组实验的所有数据集,在使用本文提出的约简算法后,都有不同程度的简化。其中,数据集batch1和batch3的约简程度最大。
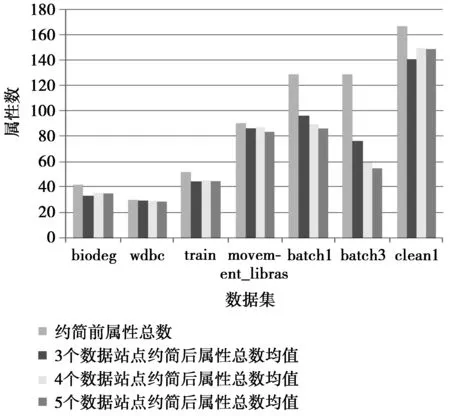
图2 3组实验属性约简前后属性数对比Fig.2 Comparison of attribute number between before and after attribute reduction in three groups
图3—图5分别是当n分别取3,4和5时,10份分布式数据在约简前后的集成正确率的均值对比图,其中,使用的决策树和支持向量机(support vector machine,SVM)算法分别来自于机器学习库scikit-learn中的分类回归树CART和使用线性核函数的LinearSVM,但是将CART的默认评价标准参数基尼系数修改为信息增益,LinearSVM的默认参数不做修改。从图3—图5中可以发现,各分布式数据使用本文提出的约简算法进行属性约简后,当使用决策树算法进行分类集成时,系统分类性能比约简前的结果要好一些或者相差不大;当使用SVM算法进行分类集成分类性能与约简前差别很小,但在数据集movement_libras上的差别较大。由于本文的约简算法删除了各分布式数据集的冗余属性,从而使得各分布式数据集受到冗余属性对知识发现产生的影响降低。所以,当使用决策树这种适用性较好的算法进行分类集成时,得到了约简后分布式数据集的分类集成结果优于约简前或者与约简前相差不大的结果。当使用线性核函数SVM算法进行分类集成时,也得到了系统的分类性能与约简前相差不大的结果,但分布式数据集movement_libras在约简后的集成结果较差。究其原因,主要是各数据子集的分类正确率大多低于50%,使用加权投票时其权重为负值,使得集成分类效果较差。所以,对于分布式数据,如果存在单个数据子集的分类能力较差的情况,将影响系统整体的分类能力。
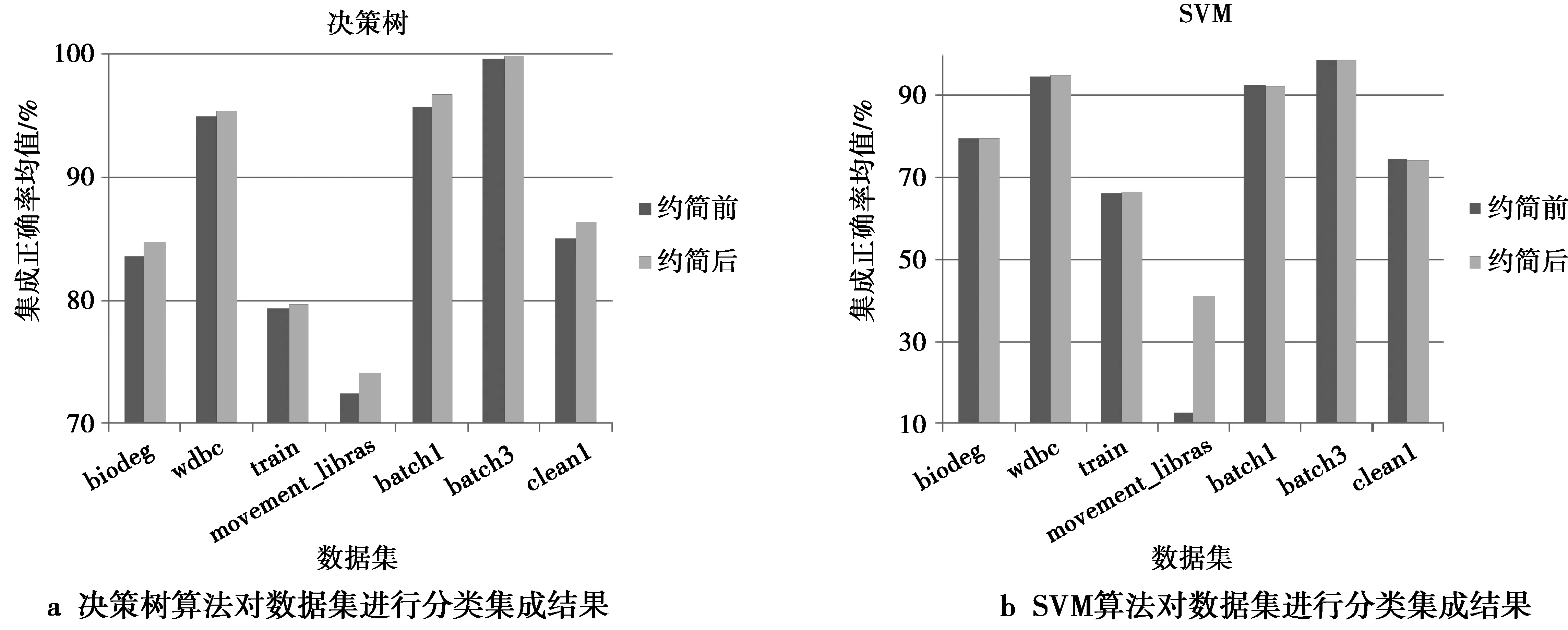
图3 n=3时不同的分类算法对属性约简前后的数据集进行加权集成的结果对比Fig.3 Comparison of weighted integration results between before and after attribute reduction when n=3
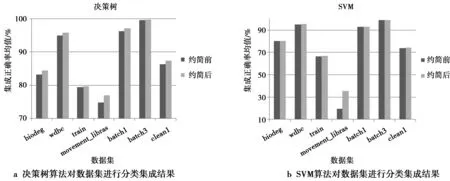
图4 n=4时不同的分类算法对属性约简前后的数据集进行加权集成的结果对比Fig.4 Comparison of weighted integration results between before and after attribute reduction when n=4
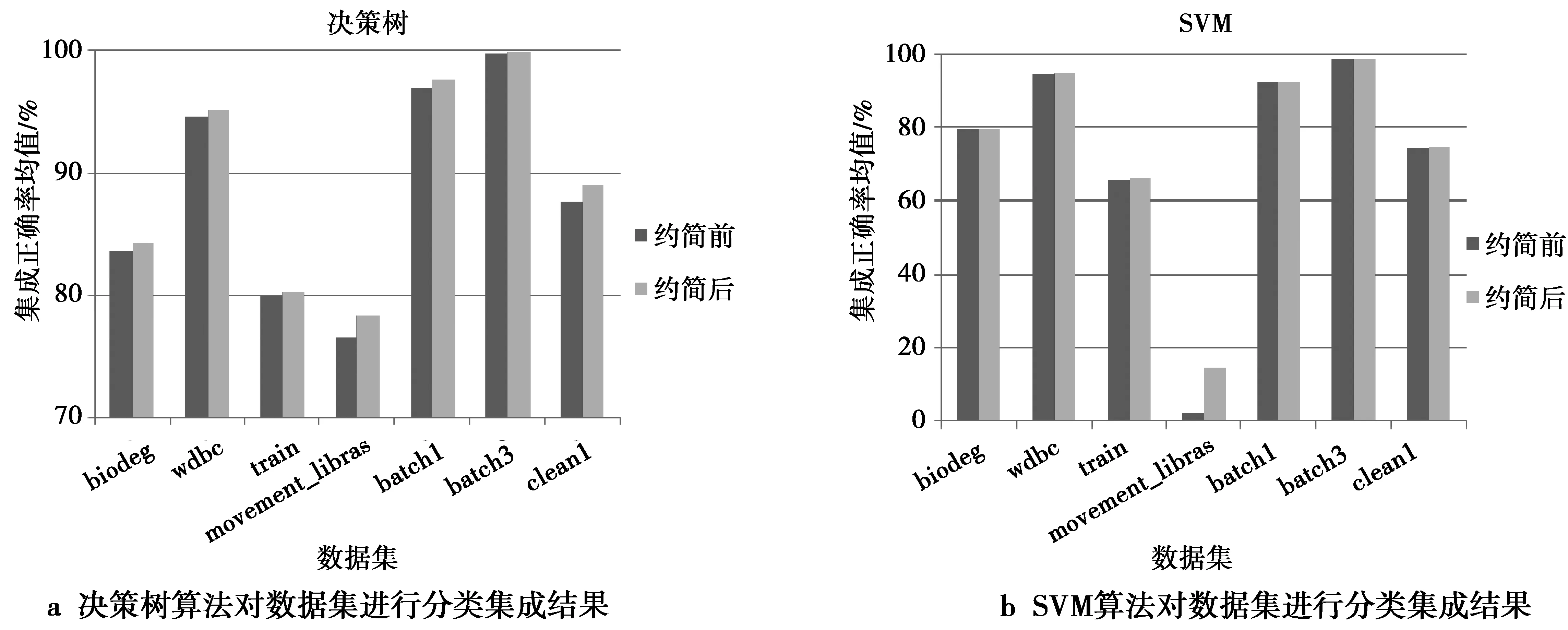
图5 n=5时不同的分类算法对属性约简前后的数据集进行加权集成的结果对比Fig.5 Comparison of weighted integration results between before and after attribute reduction when n=5
4 结束语
本文给出了分布式连续值决策信息系统中邻域粗糙集的定义,并基于此提出了属性分布连续值决策信息系统的属性约简算法。实验证明,该算法能有效去除系统中的冗余属性,并使得约简后的系统具有与原系统相当的分类能力,解决了连续值分布式数据属性约简问题。由于邻域粗糙集受阈值δ的影响较大,如何从理论上选取合适的阈值是一个有待研究的问题,这将是本文未来的研究工作。
[1] RAJASEGARAR S, LECHIE C, PALANISWAMI M. Hyperspherical cluster based distributed anomaly detection in wireless sensor networks[J]. Journal of Parallel and Distributed Computing, 2014, 74(1): 1833-1847.
[2] KALELI C, POLAT H. Privacy-preserving naive bayesian classifier-based recommendations on distributed data[J]. Computational Intelligence, 2015, 31(1): 47-68.
[3] TABORRI J, ROSSI S, PALERMO E, et al. A HMM distributed classifier to control robotic knee module of an active orthosis[C]// Proceedings of the 2015 IEEE International Conference on Rehabilitation Robotics. Piscataway: IEEE, 2015: 277-282.
[4] DIDOVYK A, KANAKOV O I, LVANCHENKO M V, et al. Distributed classifier based on genetically engineered bacterial cell cultures[J]. ACS Synthetic Biology, 2014, 4(1): 72-82.
[5] LEIVA L A, VIDAL E. Warped k-means: an algorithm to cluster sequentially-distributed data[J]. Information Sciences, 2013(237): 196-210.
[6] RUI M E, HACKER T, RONG C. A new approach for accurate distributed cluster analysis for big data: competitive k-means[J]. International Journal of Big Data Intelligence, 2014, 1(1-2): 50-64.
[7] ASHOK V G, NAVULURI K, ALHAFDHI A, et al. Dataless data mining: association rules-based distributed privacy-preserving data mining[C]// Proceedings of 12th International Conference on Information Technology-New Generations. Piscataway: IEEE, 2015: 615-620.
[8] PAWLAK Z. Rough sets[J]. International Journal of Parallel and Programming, 1982, 11(5): 341-356.
[9] 杨明,杨萍.垂直分布多决策表下基于条件信息熵的近似约简[J].控制与决策,2008,23(10):1103-1108.
YANG M, YANG P. Approximate reduction based on conditional information entropy over vertically partitioned multi-decision table[J]. Control and Decision, 2008, 23(10): 1103-1108.
[10] ZHOU Z Y, HUANG L S, Yun Y Y. Privacy preserving attribute reduction based on rough set[C]// Luo Q. Proceedings of the Second International Workshop on Knowledge Discovery and Data Mining. Piscataway: IEEE, 2009: 202-206.
[11] YE M Q, HU X G, WU C R. Privacy preserving attribute reduction for vertically partitioned data[C]// Proceedings of the 2010 International Conference on Artificial Intelligence and Computational Intelligence. Piscataway: IEEE, 2010: 320-324.
[12] HU J, PEDRYCZ W, WANG G Y, et al. Rough sets in distributed decision information systems[J]. Knowledge-Based Systems, 2016(94): 13-22.
[13] HU Q H, YU D R, LIU J F, et al. Neighborhood rough set based heterogeneous feature subset selection[J]. Information Sciences, 2008, 178(18): 3577-3594.
[14] FREUND Y, SCHAPIRE R E. A decision-theoretic generalization of on-line learning and an application to boosting[J]. Journal of Computer and System Sciences, 1997(55): 119-139.
s:The National Natural Science Foundation of China(61472056, 61379114); The Social Science Foundation of the Chinese Education Commission(15XJA630003); The Scientific and Technological Research Program of Chongqing Municipal Education Commission (KJ1500416); The Chongqing Research Program of Basic Research and Frontier Technology (cstc2017jcyjAX0406)
Neighborhoodroughsetbasedattributereductionforcontinuous-valueddistributeddata
HU Jun,WANG Kai
Chongqing Key Laboratory of Computational Intelligence,Chongqing University of Posts and Telecommunications, Chongqing 400065, P.R. China)
In order to reduce the redundant attributes in a system, and keep the classification ability of the system unchanged, the attribute reduction of continuous-valued distributed data is studied in this paper. Firstly, the definition of neighborhood rough set in distributed continuous-valued decision information system is given, and it is proved that the positive region of distributed continuous-valued decision information system is additive. Then, the reducibility of attributes in distributed decision information system is discussed based on the precondition that the positive region of the system remains unchanged, and the attribute reduction algorithm of distributed continuous-valued decision information system is proposed. Finally, three groups of experiment are conducted on seven sets of data to prove the effectiveness of the algorithm proposed in this paper. In the experiments, a distributed continuous-valued distributed data is reduced by the algorithm proposed in this paper, and then the weighted integration method is used to test the classification ability of the reduced data. The experimental results show that the algorithm can effectively remove the redundant attributes of continuous-valued distributed data and keep the classification ability of reduced data the same as the data before reduction, or even better.
continuous-valued; distributed data; attribute reduction; neighborhood rough sets; distributed decision information system
10.3979/j.issn.1673-825X.2017.06.012
2017-01-05
2017-09-15
胡 军 hujun@cqupt.edu.cn
国家自然科学基金(61472056, 61379114); 教育部人文社科规划项目(15XJA630003);重庆市教委科学技术研究项目(KJ1500416);重庆市基础科学与前沿技术研究(cstc2017jcyjAX0406)
TP18
A
1673-825X(2017)06-0785-07

胡 军(1977 -),男,湖北监利人,副教授,博士,研究方向为粗糙集、粒计算。E-mail:hujun@cqupt.edu.cn。

王 凯(1992 -),男,河南汝南人,硕士研究生,研究方向为智能信息处理。E-mail:1575929189@qq.com。
(编辑:刘 勇)
