基于多视图半监督学习的图像识别
2017-12-20奚晓钰荆晓远
奚晓钰,吴 飞,荆晓远
(南京邮电大学 自动化学院,江苏 南京 210003)
基于多视图半监督学习的图像识别
奚晓钰,吴 飞,荆晓远
(南京邮电大学 自动化学院,江苏 南京 210003)
近年来多视图学习在各个研究应用领域引起了学者们的广泛关注。传统有监督的多视图学习在学习过程中只是使用了训练样本中少数的有标签样本,传统无监督的多视图学习反之利用了其中大量的无标签样本。相比于这两种方法,多视图半监督学习方法能够同时利用训练集中的有标签样本以及无标签样本,其学习目的是在多个视图里面少数有标签样本以及大量无标签样本的情况下,在改善有监督学习的泛化性能的同时,提高非监督学习的高效性。因此文中主要以半监督学习为研究手段,以多视图子空间特征抽取为研究目标,实现了其在图像识别领域的应用。在AR和Oxford Flowers17公共数据库上进行的实验,验证了所提出算法的有效性。
多视图学习;半监督学习;互补信息;冗余信息
0 引 言
在许多计算机视觉[1]应用中,同一物体可以在不同的角度[2]或者通过不同的传感器[3]观察,从而产生多个不同的甚至完全互异的样本。最近,越来越多的应用需要从视图间和视图内[4]两方面来进行分类。然而,因为来自不同视图的样本[5]会依附于完全不同的空间,不能相互比较,所以视图间和视图内的共同分类基本上是不能直接进行的。因此,之前大多数处理这个问题的方法都尝试去学习到一个多视图能够共享的公共空间[6],在这个公共空间里,来自多个视图的样本都可以相互比较。
TANG等在多视图方向提出特征选择算法(MVFS)[7],分别独立地对每个视图进行特征选择,并利用谱分析对每个视图加上约束,使多视图学习能够满足一致性的原则。该算法考虑了各个视图之间的相互关系,但在去除不同视图之间的冗余信息方面未加考虑。JING等提出了整体正交彩色图像识别方法(HOA)[8],其基于鉴别变换。通过将线性鉴别分析方法[9](LDA)和整体正交分析方法相结合,该方法利用Fisher准则[10]从彩色图像中分别抽取三种色彩(红、绿、蓝)的判别变换矩阵,并使之满足相互正交。但该方法也有缺陷,它在选择正交关系时直接依据固定的正交顺序,从而忽略了各个视图的差异性对最终识别效果的影响。
文中提出了基于多视图半监督学习(MVSSL)的图像识别方法,通过利用半监督学习方法[11]得到各个视图对应的投影矩阵[12],并使之按最优化的顺序进行相互正交。半监督学习方法是目前研究较多的用来解决传统有监督和无监督方法存在不足的技术。该方法不仅充分利用了多视图中的有标签和无标签样本,还有效去除了视图特征之间的冗余信息,从而提高了分类算法的效果。在AR[13]和Oxford Flowers17[14]公共数据库,通过实验对该算法的有效性进行验证。
1 多视图半监督学习(MVSSL)
为了同时利用有标记和未标记的数据,定义F为预测所有训练数据的标签矩阵。
F=[f1,f2,…,fn]T∈Rn×c
(1)
其中,fi∈Rc(1≤i≤n)是第i个样本的预测标签。
根据半监督学习的思想,F应同时满足在训练数据和图形模型S中基本真实标签的平滑性。因此,可以通过最小化以下目标函数获得F:

(2)
其中,U∈Rn×n为对角矩阵,并称为决策规则矩阵,其对角元素Uii是根据第i个数据点是否被标记来决定的。
采用广义的l2,1损耗,基于图的半监督分类学习框架可以重写为:
(3)

矩阵M的l2,1范数定义为:‖M‖2,1=

多视图半监督学习的目标函数可以表示为:

(4)

文中提出一种高效的迭代算法来解决该模型。首先将原始公式转换为以下可替代的公式:
(5)

2 鉴别特征正交变换
在JING提出的基于鉴别变换,用于识别整体正交彩色图像的方法HOA的基础上进行部分改进,对经过上面多视图半监督学习方法下获得的投影变换矩阵进行正交变换。
假设三种视图的样本数据已经得到,然后加入多视图半监督鉴别特征正交变换,下面是对多视图半监督鉴别分析(MVSSDA)方法的具体描述。
2.1 获得所有视图的半监督鉴别变换W1,W2,W3
基于上述转换得到的目标函数,利用迭代方法通过求解式(5)得到变换矩阵Wt,过程如下:
(1)随机初始化Ft,Wt和bt;

(3)更新Ft,Wt和bt。
分别单独对每个视图求出其相应的投影矩阵Wt,然后根据对每个样本向量在变换矩阵下的投影计算,求出每个视图分别对应的特征,再根据最近邻算法(这里使用特征余弦),分别求出每个视图对应的识别效果f(Wt),并从高到低排序为f(W1)>f(W2)>f(W3)。
2.2 更新W2
基于上述转换得到的目标函数,通过式(6)对W2进行更新。
(6)
2.3 更新W3
基于上述转换得到的目标函数,有:
(7)

MVSSDA算法描述如下:
步骤1:根据式(5)计算出所有视图训练样本的投影矩阵,根据识别效果,得到W1,W2,W3;
步骤2:根据式(6)更新投影矩阵W2;
步骤3:根据式(7)更新投影矩阵W3;
步骤4:分别对W1,W2,W3进行标准化;
步骤5:利用投影矩阵W1,W2,W3,将各个视图的所有样本进行相应的投影,并将得到的每个样本的多视图特征融合在一起;
步骤6:用余弦最近邻距离分类器对所有样本进行分类。
3 实 验
为验证文中提出算法的有效性,将选择公开人脸数据库AR和Oxford Flowers17作为实验数据库,这两个数据库都是模式识别领域验证算法常用的数据库。以整体正交变换分析(HOA)、多视图鉴别分析(MVDA)和多视图典型相关分析算法(MCCA)为对比方法,比较分类识别的效果。
3.1 数据库
公共彩色人脸数据库AR:该数据库包含102类,其中每一类有26张图片,为了便于实验处理,将图片提前处理成60*60的尺寸。考虑到数据库中包含光照、表情、姿势、位置等多种情况,为了对不同的变化产生识别结果的影响进行有效评价,从102类样本中每类选择12个具有代表性的样本作为训练集,剩余14个作为测试集。在半监督方法中,训练样本中一半为有标记,另一半的标记被隐藏,为无标记。图1给出包含某类的部分图片示例。

图1 AR数据库的样本图像
Oxford Flowers17是一个花的数据库,包含17种不同的花,每种花有80张图片。选用其中的40个样本做训练集,20个样本做测试集。在半监督方法中,训练样本中一半为有标记,另一半的标记被隐藏,为无标记。并从样本中提取出颜色、纹理、形状、HOG、SIFT、HSV等特征作为多个视图的特征。图2给出包含几类的部分图片示例。

图2 Oxford Flowers17数据库的样本图像
将MVSSDA算法与HOA、MVDA和MCCA进行对比。为了消除实验的偶然性,保证实验结果的准确性,分别在两个数据库上均做20次实验。
3.2 实验结果与分析
图3和图4分别给出了在AR和Oxford Flowers17两个数据库上MVSSDA算法和三种对比算法分别随机运行20次的识别率波动图。表1给出了这四种方法在两个库上对应的平均识别率和方差。
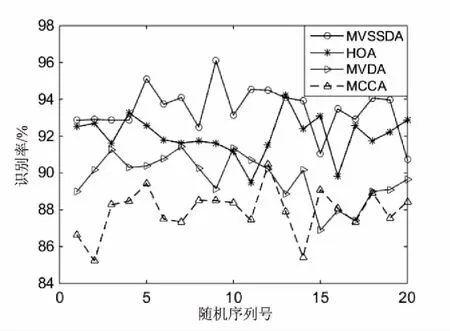
图3 AR数据库上的识别率

图4 Oxford Flowers17数据库上的识别率

方法识别率(均值和方差)/%AR库OxfordFlowers17MCCA88.76±8.0583.58±7.27MVDA90.18±6.2885.41±5.30HOA92.19±4.8387.67±4.64MVSSDA93.87±4.2489.48±3.68
从表1可以看出,MVSSDA有更好的分类性能。在公共彩色人脸数据库AR上,MVSSDA比MCCA、MVDA以及HOA的平均识别率提高了至少5.11%(93.87%-88.76%);在Oxford Flowers17数据库上,MVSSDA方法比其他三种方法的平均识别率提高了至少5.90%(89.48%-83.58%)。实验结果充分证明,MVSSDA算法能够有效地提高识别率。
4 结束语
结合半监督学习理论,并对各个视图的投影矩阵进行正交变换,提出一种基于多视图半监督鉴别分析的图像识别方法。该方法同时利用训练集中的有标签样本以及无标签样本,在多个视图里改善有监督学习的泛化性能的同时,提高了非监督学习的高效性。同时考虑到通过增加整体变换正交,将多视图之间的冗余信息去除,从而使得提取出的特征更具鉴别性。实验结果表明,通过与MCCA、MVDA以及HOA的对比,该方法有效地提高了特征识别率。
[1] 田启川,张润生.生物特征识别综述[J].计算机应用研究,2009,26(12):4401-4406.
[2] 周旭东.基于不同多视图数据场景的典型相关分析研究和应用[D].南京:南京航空航天大学,2013.
[3] XIONG N,SVENSSON P.Multi-sensor management for information fusion: issues and approaches[J].Information Fusion,2002,3(2):163-186.
[4] JING X Y,HU R,ZHU Y P,et al.Intra-view and inter-view supervised correlation analysis for multi-view feature learning[C]//Twenty-eighth AAAI conference on artificial intelligence.Québec City,Québec,Canada:AAAI Press,2014:1882-1889.
[5] 张建春.基于典型相关分析的多视图特征提取技术研究[D].南京:南京航空航天大学,2010.
[6] KAN M,SHAN S,ZHANG H,et al.Multi-view discriminant analysis[C]//European conference on computer vision.[s.l.]:[s.n.],2012:808-821.
[7] 兰 霞.半监督协同训练算法的研究[D].成都:四川师范大学,2011.
[8] JING X,LIU Q,LAN C,et al.Holistic orthogonal analysis of discriminant transforms for color face recognition[C]//International conference on image processing.[s.l.]:IEEE,2010:3841-3844.
[9] 赵振勇,王保华,王 力,等.人脸图像的特征提取[J].计算机技术与发展,2007,17(5):221-224.
[10] 聂祥飞.人脸识别综述[J].重庆三峡学院学报,2009,25(3):14-18.
[11] HU M,YANG Y,ZHANG H,et al.Multi-view semi-supervised learning for web image annotation[C]//Proceedings of the 23rd ACM international conference on multimedia.[s.l.]:ACM,2015:947-950.
[12] 边肇祺,张学工.模式识别[M].北京:清华大学出版社,1999.
[13] GAO W,CAO B,SHAN S,et al.The CAS-PEAL large-scale Chinese face database and baseline evaluations[J].IEEE Transactions on Systems,Man,and Cybernetics-Part A:Systems and Humans,2008,38(1):149-161.
[14] NILSBACK M E,ZISSERMAN A.A visual vocabulary for flower classification[C]//IEEE computer society conference on computer vision and pattern recognition.[s.l.]:IEEE,2006:1447-1454.
ImageRecognitionBasedonSemi-supervisedLearningofMulti-view
XI Xiao-yu,WU Fei,JING Xiao-yuan
(School of Automation,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
The multi-view learning has been paid extensive attention by researchers in various areas of research and applicaion in recent years.Traditional supervised multi-view learning uses only a small number of labeled samples among the training samples in its learning process,but traditional unsupervised multi-view learning utilizes a large number of unlabeled samples otherwise.Compared with both methods,the multi-view semi-supervised learning method can simultaneously use the labeled and unlabeled samples in the training set.Its objective is to improve the generalization of supervised learning and the efficiency of unsupervised learning when there are a small number of labeled samples and a large number of unlabeled samples in many views.In this paper,taking semi-supervised learning as the research mean and multi-view subspace feature extraction as the research object,its application in image recognition field is realized.Experiments are performed on AR and Oxford Flowers17 public databases to verify the validity of the proposed algorithm.
multi-view learning;semi-supervised learning;complementary information;redundant features
TP301.6
A
1673-629X(2017)12-0048-04
10.3969/j.issn.1673-629X.2017.12.011
2017-01-18
2017-05-19 < class="emphasis_bold">网络出版时间
时间:2017-09-27
国家自然科学基金资助项目(61272273)
奚晓钰(1992-),女,硕士研究生,研究方向为生物特征识别;荆晓远,教授,博士生导师,研究方向为模式识别、图像与信号处理、信息安全、机器学习与数据挖掘。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170927.0959.064.html
