基于被引片段识别的科技文摘综述
2017-12-15李纲徐健余辉马亚雪
李纲 徐健 余辉 马亚雪
[摘要][目的/意义]基于被引片段识别的科技文摘生成是文献计量学、信息检索和自然语言处理等领域共同关注的研究问题。通过梳理相关成果,可为后续研究提供借鉴。[方法/过程]本文首先介绍被引片段概念,进而从被引片段识别与分类、文摘生成与评价等步骤对相关研究进行综述。[结果/结论]当前被引片段识别总体上可以分为机器学习和检索两类,分面判定还存在标准不一致的问题,摘要生成与评估方法相关研究较欠缺。
[关键词]被引片段;科技摘要;引文上下文
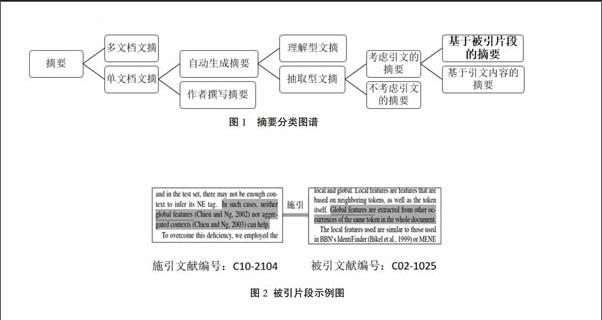
科研工作者在科学研究活动中通常需要阅读大量科技文献以了解研究领域现状。在当前学术论文数量与日俱增的情况下,通过阅读科技文献的摘要将大幅度减小科研工作者阅读文献的压力。当前科技文献摘要的形成过程可分为作者撰写和自动生成两种方式。前者虽然能精准地概括文章的核心内容,但由于其是从作者角度而非读者角度完成的,因此很难客观地反映该文对学界的贡献与影响。自动文摘作为一种自动凝练目标文献核心内容的方法,具有效率高和客观性强的特点,因而在信息检索与信息抽取等领域具有广泛的应用。按照摘要与原文的关系的不同,自动文摘技术可分为抽取型文摘和理解型文摘,后者受当前语义理解和自然语言处理技术限制较大,所以目前关于自动文摘的研究主要集中在抽取型文摘上嘲。传统抽取型摘要的做法是计算目标文献中各句子重要性并选取若干关键句生成文摘,这样生成的摘要同样不能从读者角度反映该文的影响力。于是,越来越多的研究者尝试从引文角度考虑该问题闱。基于引文的摘要技术的基本概念是引文内容,又称引文上下文(citation context),包含了对被引文献的介绍与述评,从读者角度揭示了被引文章对学界的影响。当前,如何通过引文上下文生成摘要存在直接法与间接法两种思路,前者对目标文献的引文句进行组织进而完成摘要生成,后者需从被引文献中识别出被引片段并对其进行融合,生成最终的摘要。为方便对本文所评述自动摘要方式有直观的理解,笔者归纳了摘要的种类并绘制摘要的分类图谱,如图1所示。
引文上下文是指引文标记所处的上下文,当前广泛用于引用动机识别、主题识别、信息检索、文档聚类等领域。直接使用引文上下文生成单文档文摘最早开始于2008年Qazvinian等的研究,作者对被引文献的引文上下文进行聚类与排序,从而生成被引文献的摘要。Kaplan等将指代消解(corefcrenee resolver)应用于引文上下文的抽取,实验证明该方法相比于其他方法在抽取引文上下文时效果更优,抽取出的内容可进一步用于文摘生成。HUE21等将引文句视为文献的使用上下文,并将之与结构上下文组成混合引文上下文开展基于影响点的文摘研究。直接利用引文上下文生成文摘目前已有较多的成果,但引文上下文中除包含对被引文献的介绍和评述外还包含了施引者的观点,因此有学者指出直接使用引文上下文的文摘存在主题偏移和信息缺失的问题,因此基于被引片段的文摘生成受到越来越多研究者的关注。
基于被引片段的文摘研究最早开始于文献“GeneratingImpact-Based Summaries for Scientific Literature”,與直接使用引文上下文生成摘要相比,这种方式生成的摘要来自于原文,从而避免了主题偏移的问题。Mei利用文章的所有引文上下文构建其影响模型,在原文中寻找能反映该影响的句子,并加以组织生成文摘。Cohan通过对被引片段进行聚类,从各类簇中抽取重要性较高的几个句子形成文摘。在web of knowledge、Google Scholar平台上以检索式“cited spans summary”“reference text spans summary”等为关键词进行检索,发现相关结果并不多,大量的成果集中于2014TAC和2016CL-SciSumm的会议论文上。同时,国内针对被引片段的自动文摘相关成果则更加少。通过查找相关文献进行扩充,通过人工阅读共得到相关文献26篇。当前基于被引片段的文摘步骤可概括为两步:首先从被引文献中识别并抽取被引片段,并判定其在语篇中的功能;其次,从被引文献中抽取若干句子本文通过文献。本文首先用实例介绍被引片段的概念,接着以两次文摘比赛的步骤归纳与评述该领域研究现状,以期为后续相关研究提供借鉴。
1被引片段概念
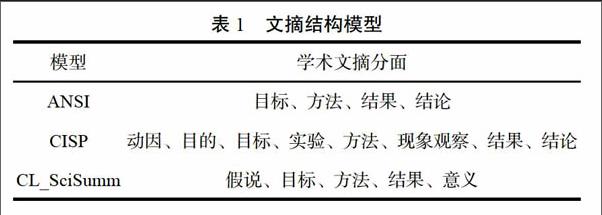
在引文分析领域,“被引片段”是一个崭新的概念,是引文内容分析未来发展的重要的研究方向。单篇文献会包含多个研究主题,而其他文献在引用它时仅仅是因为某个主题。施引者会引用其认定对自己研究有参考价值的内容,这部分内容正是本文所述的被引片段(Cited Spans or Reference Span)。一般认为,在一次引用过程中被引片段与引文上下文具有对应关系,相比于被引频次,被引片段更清晰与具体地说明了该文献对学界的贡献与影响,图2用实例说明被引片段的概念:
在图2中,施引文献C10-2104中被标注的句子就是引文上下文,文献C02-1025中被标注的句子为被引片段。文献C10-2104因为需要对“global features”来源进行说明而引用了文献C02-2105。此时,文献C02-1025中关于“global features”的描述语句“Global features are extracted from other occurrences of the same token in the whole document”则可称为对应的被引片段。在这次引用过程中,文献C02-1025中关于“global feature”的研究对文献C10-2104具有一定参考价值与借鉴意义。在单次引用中,被引片段从内容角度揭示了该文献被引用的原因,反映了该文献对后续研究的借鉴作用。通过组织与整合某篇文献的多个被引片段,即可全面地评估其对学界的影响,进而生成摘要。
2被引片段识别与分类
2.1被引片段识别endprint
被引片段识别就是从被引文献中寻找与引文上下文相对应的那部分内容,识别结果可以是句子的一个片段、也可以是一个整句或者若干连续句子的集合。目前被引片段的识别方法总体上可以分为:基于信息检索的方法、基于机器学习的方法两类。
2.1.1基于信息检索的方法
基于信息检索的方法将被引文献中的句子按照与引文上下文的相似性或重要性进行排序,选择排名最靠前的句子作为被引片段。基于相似性的方法认为被引文献中与某引文上下文中相似度越高的句子越可能是其对应的被引片段。例如,Molla通过扩充句子规模、增加句子上下文窗口的方式对传统的TF-IDF公式进行改进计算引文上下文与被引句之间的余弦相似度,并选取最相似的三句话作为被引片段。Cohan利用向量空间模型计算引文上下文与被引文献中各句子的相似性,并将基于伪相关反馈的重排序技术引入到被引片段识别过程中。日本学者Nomoto将引文上下文视为问题,而被引文献中的句子为待选答案,被引片段的识别就转化为问答系统的问题。该方法将基于单层神经网络预测的相似性和基于词袋模型计算的余弦相似性进行融合,进而定位被引片段。而基于重要性的排序方法则认为,句子在被引文献中越重要则其越有可能被其他文献引用。例如,Klamp提出一种改进的关键句识别算法(Textrank),将引文上下文与句子的相似性最为句子的初始权重,经过随机游走过程确定被引文献中句子的重要性并进行排序。
由上可知,无论是基于相似度计算还是基于重要性排序,基于信息检索的被引片段识别方法过程简单,效率较高。但是将被引片段识别问题转化为信息检索问题在理论上还缺乏一定的依据,关于相似性与重要性的假设也需进一步推敲。笔者认为,只有从语义理解的角度对被引文献与引文上下文间的关系进行探索才能更精准地寻找被引片段。此外,这种方法在操作过程中还存在两个问题:第一是排名前几位的句子在位置上不一定相邻,这不符合被引片段连续几个句子的特征,第二是被引片段选取的门槛难以确定。
2.1.2基于机器学习的方法
相较于基于信息检索的识别方法,更多研究者使用机器学习方法来识别和抽取被引片段。按照实现方法的不同,该方法又可分为分类学习方法(Classification)和排序学习(Learning to rank)的方法。前者将被引片段识别问题转化为句子的二元分类问题,即被引文献中所有句子被判定为匹配与不匹配两个类别,所有匹配的句子被即被视为被引片段。目前常用的分类方法有支持向量机,朴素贝叶斯,常用的分类特征有位置特征和相似度特征。后者则融合多种排序特征对句子进行排序,Cao等和Lu等学者分别利用SVMRANK和RANKLIB工具进行此方面的探索。
综上所述,无论是基于分类学习的方法还是基于排序学习的方法,均可以有效利用多种信息作为特征进行学习,但都存在一个较大的问题:类别不均衡。在寻找引文上下文的过程中,被引文献中仅少数几个句子被标注为被引片段,正负例比率较低使该方法识别占少数的被引片段比较困难。此外,分类器可能将被引文献中的所有句子都判定为非被引片段,同时也有可能将几十甚至几百个句子都判定为被引片段,这将大大降低该方法的可用性。此外,也有学者通过人工定义抽取规则,实现被引片段的识别。该方法具有较高的执行效率,过程易于理解,但在实际操作过程中相关启发式规则的归纳费时费力,且规则覆盖范圍有限,从而使得该方法具有过适应性(over-fitting)。
2.1.3被引片段识别评价
被引片段识别结果的评价根据粒度可分为句子和单词两个层面,前者通过计算系统识别出的被引片段和人工标注结果之间重合度(Overlap)完成,后者则使用ROUGE完成,具体指标有准确率,召回率和F1值。目前各研究团队被引片段识别结果与人工标注的结果有很大的差异,以2016年JCDL举办的CL-SciSumm比赛为例,目前关于被引片段识别的准确率最高仅为12%。这说明当前关于被引片段研究还不成熟,需要就被引片段理论与特征开展进一步探究。
2.2被引片段分类
被引片段分类的目的是形成结构化的文摘,下面分别介绍文摘结构相关理论、被引片段分类及其评估过程。
2.2.1文摘结构相关理论
作者在撰写科技文献的摘要时,需注意其分面逻辑性(即先写什么后写什么)以提高文摘质量和主题表达能力。同样地,在自动文摘生成过程中,也要按照一定的标准对备选句子进行分类、组织与筛选。结构化文摘通过收集有关目标文献各方面信息生成文摘,使得对目标文摘描述具有全面性和简洁性。目前,国内情报学领域期刊如现代图书情报技术、图书情报工作等均要求作者投稿时提交结构化摘要,这也是目前学术文摘规范未来发展的趋势。当前主流的文摘结构表示模型主要有ANSI模型、CISP模型等(具体情况见表1)。其中ANSI模型是从摘要的结构进行划分文摘分面的,而CISP是从正文撰写角度进行摘要分面划分。2016年CL-SciSumm比赛将文摘分面定义为假说、目标、方法、结果、意义五类,参赛者需判定前一步骤识别出的被引片段的类别。
从表1中可以看出,当前关于文摘结构分面尚未有统一的标准,这与各学科研究内容与研究模式有一定关系。此外,对于一些观点类、评述类的文献来说,上述偏实验研究类论文的文摘结构也并不适合。
2.2.2被引片段分类研究
被引片段作为最终摘要内容的来源,需要判定其在整个摘要结构中的功能,该过程可视为一个多元分类问题。笔者认为,既然被引片段来自于被引文献,则其分类与基于正文的学术文摘结构识别当属具有相关之处。Guo等分别利用支持向量机算法实现了基于文本内容特征的文摘语句分类。Yamamoto等在分类特征的选取上考虑了动词时态、语句位置等信息。白光祖等针对不同类别建立特征词集,研究小样本情形下学术文摘类别判定问题。具体到被引片段分类上,Lu等在被引片段分类过程中,使用了正文和引文中文本与其所在章节标题的用词信息。Malenfant等认为被引片段与其对应引文的类别是一样的,因此可根据引文类别推断被引片段的类别。Li等使用多个分类器进行投票以提高分类准确率。在实际引用过程中,方法、结果类引用较多,而意义、假说部分的内容引用次数较少,针对被引片段分布偏斜问题主要解决方法有基于分类器算法的改进和训练集的重构。与其他多分类问题一样,被引片段分类的评价指标主要是各个类别Precise-Recall和F-measure指标。此外,整体层面的评价指标有正确率,各类别性能的宏平均和微平均等。endprint
3文摘生成与评估
3.1文摘生成
目前,基于被引片段的文摘基本思路可概括为:为被引文献中的每句话进行重要性打分,通过一定策略抽取重要性较高的句子生成满足长度条件的摘要。在句子重要性打分方面,Mei等利用所有引文句和原文推测文献影响力模型,该模型可以视为被引片段集合,之后计算文中各句子与该模型的KL距离作为句子重要性值。Cao等提出一种改进的流形排序算法,该方法将文献内部句子问相似性与引文句间相似性的值进行线性融合,通过随机游走过程迭代计算每个句子权重并从中选择最重要的句子。陈海华等使用支持向量回归(SVR)方法融合位置、长度、相似性特征预测文献中各句子重要性得分。Li等计算文献中各句包括基于层次主题模型(HLDA)的相似度、句子长度、句子位置等在内的5种数值特征,利用线性加权的方式计算句子重要性。Saggion等用向量空间模型表示标题、摘要、全文、引文句等文本,利用线性回归模型对包括相似性、位置、重要性等特征参数进行学习。系统生成的摘要不仅仅要求内容全面,而且要求简洁,冗余信息少,基于被引片段的科技文摘赛事一般将之设置为选择性任务。值得注意的是,当前大多数研究并未严格使用识别出的被引片段与其类别生成结构化摘要,该部分研究还比较欠缺。
自动摘要的长度一般设定为固定句子数或字符数,这与具体任务要求有关。例如2016年CL-SciSumm比赛官方要求目标摘要字数为250个字符,而有的学者将长度设置为若干句子数目。还有的学者考虑了目标文献本身长度按比例设置摘要长度。在实际生成摘要的过程中,存在若干用词相同、语义相近的句子組成摘要的情形,此时就需要结合一定的去重策略筛除语义冗余的句子,使摘要尽可能全面的覆盖文章的各个方面。当前很多研究利用最大边缘算法(Maximum Marginal Relevance,MMR)通过计算待选句子和已选句子的相似度,选择超过某阈值的句子生成摘要。针对自然语言中多词一义的问题刘天祎等指出要结合相关知识库才能更好地实现语义层面的去重。
3.2文摘评估
摘要评估是针对系统生成摘要的长度、全面性、真实性、可读性等方面的评判。具体而言,文摘评价标准的制定可以分为主观评测和基于标准结果的两种情况,前者需要人工阅读系统生成的文摘并给出评价。后者需要提前定义目标文献文摘的参考答案(Golden standards),一般而言由原文作者撰写的摘要和人工生成两种,通过对比该参考答案与系统生成文摘的相似性进行文摘质量的评价。文摘领域的评价指标一般使用ROUGE,该方法基于N元词共现信息计算系统生成文摘和人工生成文摘的匹配程度,包括ROUGE-N、ROUGE-L、ROUGE-W、ROUGE-SU四种评测标准。
目前几乎所有的评价方案均只限于内容的完备性和准确性上,关于摘要连贯性、可读性等方面还未有较好的评估方案。在今后的研究中,应考虑引入用户对生成摘要的质量反馈机制,提高生成摘要的连贯性和可读性。
4结语
当前关于被引片段文摘的研究多集中在微软亚洲研究院组织的比赛上,而学界对于被引片段概念的了解与接受程度普遍较低,从而导致相关研究比较少,国内研究则更是少之又少。本文按步骤对基于被引片段文摘技术进行深入分析与探讨,从而对整体研究进行述评。研究发现,当前相关研究及其应用中还存在若干问题与困难。具体如下:被引片段识别与分类是该领域研究的主流,然而对被引片段概念、特征等在理论层面的探讨较少,目前被引片段标注过程不规范,并未经过多人标注;相关研究表明零被引文献也是有价值的,但该文摘方法不太适合零被引和低被引的情况,同时也存在某文献被引片段过于集中导致文摘覆盖面低的问题(例如,文献的方法被引用了若干次,而文献的结果部分无人引用);相比于网页,学术文献一般在10页到30页之间,将如此长篇幅的文本压缩成不到300个单词的文摘,其压缩比例和困难程度均比较大,从目前研究来看,机器生成文摘与人工生成文摘差异较大,效果并不能使人满意;自动文摘最终的用户是读者,不仅要对信息进行浓缩还要保障其可读性和可理解性,这种抽取型文摘仅仅是若干句子的集合,句子顺序混乱与句子间逻辑缺乏,相关研究缺乏用户对文摘质量的反馈。
当前,关于被引片段的自动文摘研究受到文献计量、信息检索、自然语言处理、文本挖掘等领域的共同关注。相关研究尚处于起步阶段,尚存较多待解决问题,未来研究中应着重剖析被引片段概念的内涵,优化其识别与分类的方法,设计更加科学合理的文摘结构,同时考虑被引片段范围集中的问题,生成更加全面、客观的摘要,引入读者对文摘的反馈机制,带动该项研究实用性水平的提升。endprint
