基于字典学习和Fisher判别稀疏表示的行人重识别方法*
2017-12-15张见威林文钊邱隆庆
张见威 林文钊 邱隆庆
(华南理工大学 计算机科学与工程学院, 广东 广州 510006)
基于字典学习和Fisher判别稀疏表示的行人重识别方法*
张见威 林文钊 邱隆庆
(华南理工大学 计算机科学与工程学院, 广东 广州 510006)
针对目前的字典学习方法对不同摄像机视角行人特征的联系考虑不足的问题,提出了一种新的基于字典学习和Fisher判别稀疏表示的行人重识别方法.该方法考虑不同场景中同一行人的特征应该具有相似的稀疏表示,提出行人重识别离散度函数的概念,加入约束稀疏表示的正则化项,最大化不同行人稀疏表示的类间离散度,同时最小化同一行人稀疏表示的类内离散度,通过学习到的字典得到具较强区分识别能力的稀疏表示.在公开数据集VIPeR、PRID 450s和CAVIAR4REID上的实验表明,文中方法的识别率高于目前基于字典学习的行人重识别方法.
行人重识别;Fisher 判别;字典学习;稀疏表示;离散度
行人重识别是视频监控等领域的关键问题.由于拍摄场景不同常出现光照和尺度变化、视角多样性、目标遮挡等问题,如何提高识别率仍是一个难题.目前常见的一些行人重识别方法,包括度量学习[1- 2]、特征学习[3- 5],受不同摄像机和场景条件变化的影响,提取的图像特征或学习的距离度量的表示能力有限.度量学习的主要目标是通过训练样本学习出一个能有效反映不同摄像头下行人样本的距离函数,Hirzer等[1]介绍了一种基于LMNN(Large Margin Nearest Neighbor)分类思想,即根据不同场景的图像对,学习马氏度量矩阵用以分类.Pedagadi等[6]介绍了一种非监督PCA(Principle Component Analysis)与监督LFDA(Local Fisher Discriminative Analysis)相结合对原始高维特征降维的方法.特征学习方法旨在提取图像有区分度的特征表示,例如Symmetry-Driven特征提取[3]和显著性特征提取[4,7- 8].然而在匹配过程中,没有用到不同区域(即拍摄场景)关于行人特征之间的判别信息,而这些身份判别信息对提高分类器的性能是很重要的.由于不同摄像机存在分辨率、成像角度、光照的差异,同一个人在不同摄像机所成图像中的外观变化比较大,直接从图像中提取颜色、纹理等特征不可靠,因此学习到的特征或度量矩阵的表示能力有限.
基于字典学习的方法近年来受到广泛关注,并且应用到行人重识别上取得了显著效果.字典学习旨在从训练样本中学习一组能够很好地表示样本的字典原子.经典的字典学习方法KSVD[9]目标是学习一个过完备字典D,使给定的特征样本能够获得其稀疏表示.字典D虽然能够很好地表示训练样本,但KSVD不适合用来分类,因为字典D均等地
表示训练样本,是没有判别性的.基于KSVD,Mairal等[10]在字典学习框架上增加了判别重建约束,使字典具有判别性能.最近,Li等[11]提出的CPDL模型以及Liu等[12]提出的SSCDL模型在进行行人重识别时识别率有较大提高.CPDL模型考虑了图像层和图像块层的匹配,约束不同区域的同一个人特征有相似的稀疏表示.SSCDL是基于图像块的字典学习,约束两个区域中属于同一人的图像块对有相似的稀疏表示,但没有利用不同类间的判别信息.Kodiron等[13]基于迭代图拉普拉斯规则化项的字典学习方法是非监督模型,提出了非监督下不同区域特征的软对应关系和迭代更新这种对应关系的想法,但不能扩展到监督模型.
本研究提出一种新的基于字典学习和Fisher判别稀疏表示的行人重识别方法,充分利用了不同行人的身份判别信息,通过加入基于Fisher判别的稀疏系数约束项,能够学习到判别性能更优的字典,使图像特征有更好的稀疏表示;并在公开数据集上对该方法的识别率进行实验验证.
1 方法
1.1 行人重识别离散度函数的构建
文中提出行人重识别离散度函数的概念,并给出构建方法.设有m个类别(文中为m个不同行人)样本集,样本稀疏系数表示为Y=[Y1Y2…Ym],其中Yi∈Rk×ni,ni为第i类样本个数,k为样本维度.记Y的类内离散度矩阵为SW(Y),类间离散度矩阵为SB(Y).SW(Y)和SB(Y)定义为
(1)
(2)
其中,mi和m分别为Yi和Y的均值向量.基于Fisher判别的思想,最大化类间离散度,同时最小化类内离散度,直观上,定义离散度函数
f(Y)=tr(SW(Y))-tr(SB(Y)).
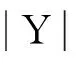
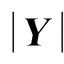
(3)



(4)
其中,为了得到稀疏系数Y的总体均值和各类别样本均值,而定义了矩阵W和B:
Wi,=1iW·1iWT/ni,1iW∈Rni×1,
B=1B·1BT/2m,1B∈R2m×1,
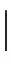
1.2 目标函数的构建
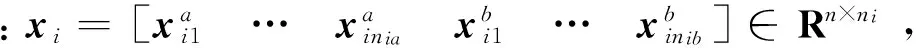
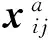
传统字典学习旨在学习一个使每个训练样本xi在其上具有稀疏表示的字典D,其框架为
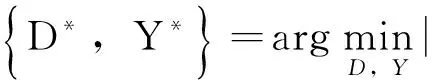
(5)
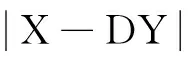
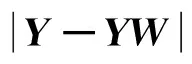
(6)
式中α、λ、η为正则项系数,通过加入约束稀疏系数Y的正则项f(Y),能够学习到判别性能较好的字典D,即用字典得到同一行人的稀疏系数很相似,而不同行人间的系数差距较大.
1.3 最优化问题求解
[14]中的优化过程,本节采用迭代优化方法对目标函数(式(6))进行优化,每次迭代包含两个步骤.
(1)固定字典D,求系数Y
这一步假设字典D固定,更新稀疏系数Y,目标函数(式(6))简化为求解Y=[y1y2…ym]的稀疏编码问题,更新yi时,假设yj(j≠i)固定.目标函数(式(6))简化为
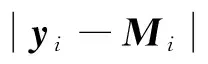
(7)
(2)固定系数Y,求字典D
固定稀疏系数Y,式(6)中的目标函数简化为
(8)
一般要求字典D中的每一列di都是一个单位向量,式(8)是一个二次规划问题,可用文献[16]中的MFL算法逐列更新字典.整个迭代优化算法见算法1.

输出:稀疏系数Y和字典D.
1)初始化字典D;
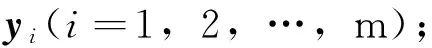
3)固定系数Y,使用MFL算法[16]逐列更新字典原子di(i=1,2,…,k);
2 匹配过程
训练得到字典D后,可求得测试数据的稀疏表示系数,求解稀疏系数的方法很多,包括匹配跟踪(MP)算法、正交匹配跟踪(OMP)算法和LASSO[17]算法.参考CPDL[11]、DLILR[13]等字典学习方法中的距离匹配方法,文中用余弦距离进行匹配.
(9)
(10)
这是一个简单的最小二乘问题,问题的解可近似为
3 实验
3.1 数据集
本研究在3个公开数据集(VIPeR数据集[18]、PRID 450s数据集[19]和CAVIAR数据集[20])下进行实验.VIPeR数据集是行人重识别广泛使用的数据集,由632对行人图像组成,每对图像来自不同的摄像机场景.由于不同摄像头存在光照变化、成像角度不同、姿态不同和物体遮挡等问题,提高VIPeR数据集识别率难度较大.图1展示了不同摄像头拍摄行人图像的差异.
文中采用文献[3]中分配好的训练样本和测试样本,即每次随机选取数据集一半(316对行人图像)作为训练数据,另外一半(316对)作为测试数据.测试数据中一个摄像头的所有图像作为Probe集,而另一个摄像头的所有图像作为Gallery集,统计10次实验的平均结果.

图1 VIPeR数据集中图像Fig.1 Illustration of images in VIPeR dataset
PRID 450s数据集参照了VIPeR数据集的形式从PRID 2011数据集[21]中挑选成对行人图像,而且行人样本数多于PRID 2011数据集.包含450对图像,每对图像属于同一个人,分别来自不同的摄像头,图像高度在100到150像素之间不等.文中参考Farenzena等[3]和Lisanti等[22]的实验方法,每次实验随机选择其中的一半即225对行人图像作为训练样本,对其余的另一半进行测试,共进行10次实验,统计平均结果.PRID 450s数据集下人在图像中的位置不稳定,并且人较小,部分有遮挡.图2是PRID 450s数据集的部分图像对.

图2 PRID 450s数据集中图像Fig.2 Illustration of images in PRID 450s dataset
CAVIAR4REID来自于原始的CAVIAR数据集,原本用于行人跟踪和匹配算法的评价.现在用于行人重识别的CAVIARa数据集中共有72个行人的多幅图像,其中的50个人分别在两个不同的摄像头下各有10张图像,另外的22个人只在其中的一个摄像头下有10张图像,而且图像之间的大小、分辨率、拍摄角度、人物姿态不尽相同,该数据集的主要难度在于低分辨率及分辨率的变化,图3是CAVIAR4REID数据集的图像示例.同样每次实验随机选择其中的一半即36个行人的部分图像作为学习字典的训练样本,对其余的另一半进行测试,共进行10次实验并统计平均结果.

图3 CAVIAR4REID数据集中图像Fig.3 Illustration of images in CAVIAR4REID dataset
3.2 特征
目前的行人重识别方法中,把颜色、纹理和空间信息相结合的特征描述是主要的研究趋势.文中采用文献[23]中介绍的特征,即颜色直方图、HOG[24]和LBP[25]组成的5 138维的特征向量.
3.2.1 颜色直方图
颜色特征属于图像的基础特征,比较有代表性的是颜色直方图.一幅图像的全局颜色直方图包含各种颜色值在该图像中出现的频数,而统计时分割的颜色值区间的密度决定了颜色直方图信息的精细程度.图像中像素的重要程度是不同的,为了体现图像像素的空间位置信息以及增加直方图的合理性、鲁棒性,对不同像素点在直方图中的频数贡献进行加权,常用方式有局部加权、分块加权、前景加权、背景加权等.
3.2.2 方向梯度直方图
图像识别领域的纹理特征种类很多,最具代表性的是HOG(Histogram of Oriented Gradients,方向梯度直方图).HOG特征是通过对待检测图像进行密集扫描的窗口计算梯度方向直方图得到.图像中行人的外观形状有较强的边缘形状规律,可以由梯度方向和梯度强度来表示.
3.2.3 局部二值模式
LBP(Local Binary Pattern,局部二值模式)是一种描述图像局部纹理特征的算子,具有旋转不变性和灰度不变性等显著优点.LBP算子的值通过与周围领域的像素值比较得到,首先分析固定窗口区域的特征,再利用统计法作整体特征提取.LBP算子不受灰度尺度的影响,对光照变化有较好的鲁棒性.
3.3 评估指标
本节实验中关于行人重识别性能的评测采用CMC(Cumulative Matching Characteristic)曲线作为评测准则,CMC曲线的横坐标是排名分数,纵坐标是识别率.曲线中每个点对应着排名分数和识别率,如Rank-R的识别率为P,表示正确的目标排在排序结果前R个的概率为P.通常评估算法在CMC曲线第一个点的识别率(Rank- 1).为了进一步评估文中算法的性能,实验中另外给出了文中方法与部分重识别方法在Rank- 1的盒形图(Boxplot).盒形图是利用数据中的5个统计量:最小值、第一四分位数、中位数、第三四分位数与最大值来描述数据的一种方法,可以用来大致判断数据的分布形态.
3.4 参数设置
训练过程中的参数α控制稀疏系数的大小,α越大,所得到的稀疏系数取值越小.实际经验中α取值在0.000 1与0.1之间.对于算法1中的正则项系数α、λ和η,文中通过采用3折交叉验证,估计λ=1、η=1、α=0.000 1.固定λ和η的值时,α在0.000 1与0.005之间波动对识别率影响不大.
文中算法中另一个重要的参数是字典大小k,直观上我们觉得字典太小会使得训练所得到的字典原子不具备很好的判别性能.如果字典太大,又可能造成图像之间共有的字典原子很少,难以基于共有的字典原子来完成图像的相似度匹配.参照DLILR[13]方法,文中算法字典大小k取256.为了探讨字典大小对文中算法的影响,文中分别取不同大小字典的原子在数据集VIPeR和PRID 450s上进行实验.对于两个数据集,随机取一半行人图像作为训练集,另外一半行人图像作为测试数据.重复10次实验,最后将10次实验Rank- 1匹配率的平均值作为实验结果.图4展示PRID 450s数据集下不同字典大小的Rank- 1识别率(VIPeR数据集也有类似的结果).相应地,文中算法字典大小k取256.
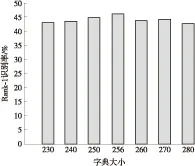
图4 PRID 450s数据集下不同字典大小的Rank- 1识别率
Fig.4 Rank- 1 matching rates of different dictionary size on PRID 450s dataset
3.5 实验结果
将文中方法与3类(度量学习方法、特征学习方法和字典学习方法)行人重识别方法进行比较.度量学习方法包括LF[6]、PCCA[26]和eBiCov[27].特征学习方法包括SDALF[3]、ISR[15]、eSDC[7]和GTS[4].字典学习方法包括CPDL[11]、SSCDL[12]以及DLILR[13].VIPeR数据集下文中方法与其他行人重识别方法的CMC曲线如图5所示,各方法在Rank- 1/5/10/20的识别率如表1所示.
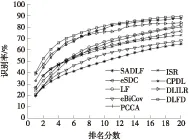
图5 VIPeR数据集下不同方法CMC曲线比较
Fig.5 Comparison of CMC curves of various methods on VIPeR dataset
表1 VIPeR数据集下不同方法的识别率
Table 1 Recognition rate of various methods on VIPeR dataset
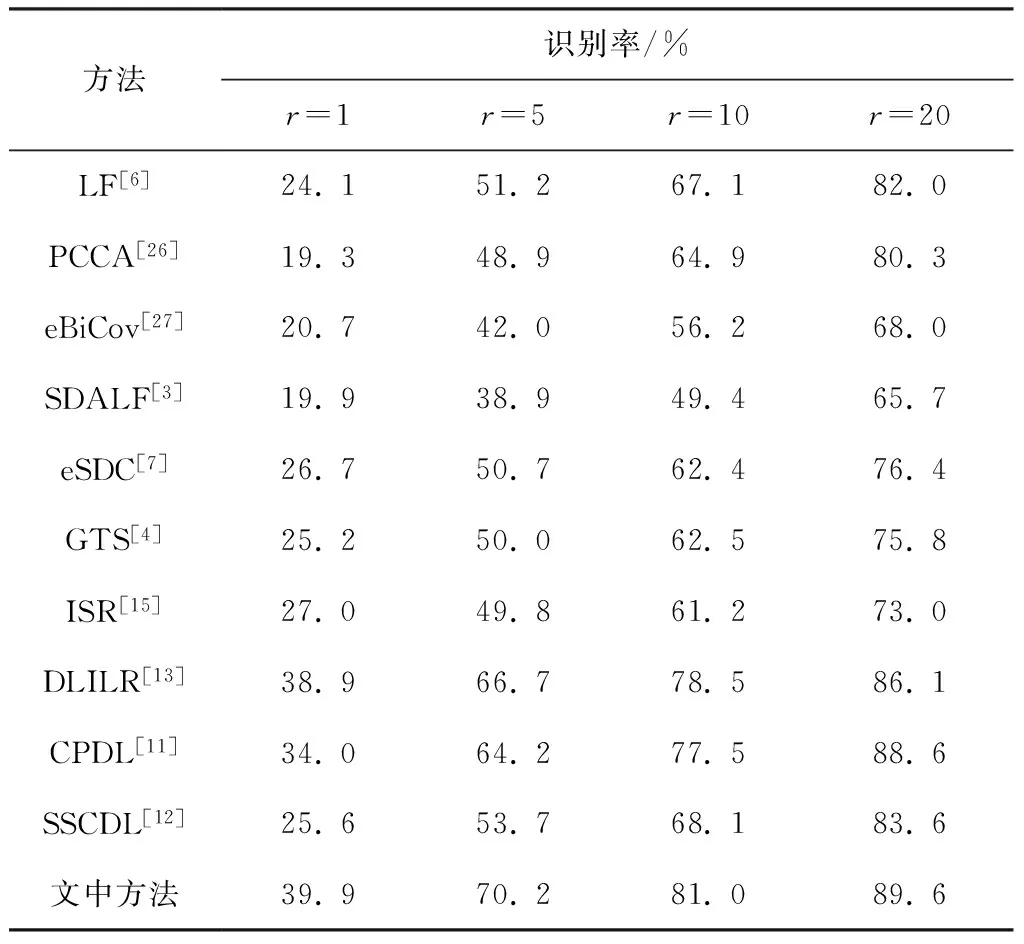
方法识别率/%r=1r=5r=10r=20LF[6]24.151.267.182.0PCCA[26]19.348.964.980.3eBiCov[27]20.742.056.268.0SDALF[3]19.938.949.465.7eSDC[7]26.750.762.476.4GTS[4]25.250.062.575.8ISR[15]27.049.861.273.0DLILR[13]38.966.778.586.1CPDL[11]34.064.277.588.6SSCDL[12]25.653.768.183.6文中方法39.970.281.089.6
从表中数据可看出,相对于度量学习和特征学习,基于字典学习的行人重识别方法能够得到更高的识别率,如CPDL和DLILR在Rank- 1/5/10/20的准确率,表明字典具有较好的判别性能.文中算法以较大差距高于基于特征学习[3- 4,7,15]和度量学习[6,26- 27]重识别方法的识别率,展示了文中提出的离散度函数对提高识别率有较好效果.另外,在Rank- 1文中方法均高于基于字典学习[11- 13]的重识别方法.
PRID 450s数据集下文中方法与部分重识别方法的CMC曲线如图6所示,不同方法在Rank- 1/5/10/20的准确率如表2所示.
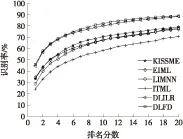
图6 PRID 450s数据集下不同方法CMC曲线比较
Fig.6 Comparison of CMC curves of various methods on PRID 450s dataset
表2 PRID 450 s数据集下不同方法的识别率
Table 2 Recognition rate of various methods on PRID 450 s dataset
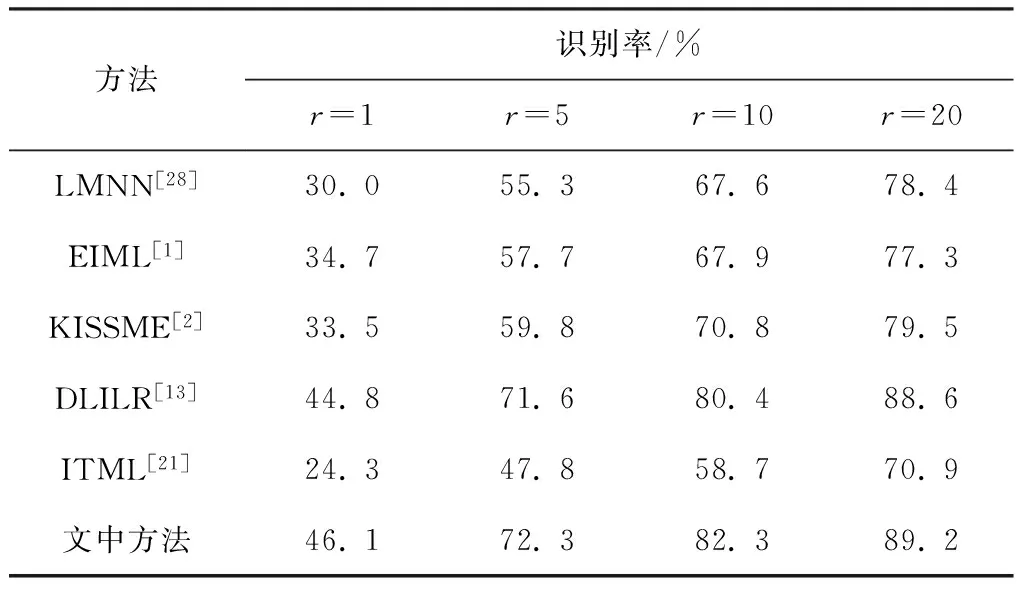
方法识别率/%r=1r=5r=10r=20LMNN[28]30.055.367.678.4EIML[1]34.757.767.977.3KISSME[2]33.559.870.879.5DLILR[13]44.871.680.488.6ITML[21]24.347.858.770.9文中方法46.172.382.389.2
与VIPeR数据集结果相似,文中方法识别率相对于基于度量学习和特征学习重识别方法的识别率有了较大提高,再次显示了文中构造的离散度函数的优势.而对于基于字典学习的重识别方法DLILR,把PRID 450s特征直接代入代码中,分别取几组不同的参数(稀疏约束项和拉普拉斯图规则化项的约束系数),取平均识别率最高的一组作为实验的参数,从表2可看出,文中方法识别率仍高于DLILR.
各方法在CAVIAR4REID数据集下的CMC曲线如图7所示,在Rank- 1/5/10/20的识别率如表3所示.
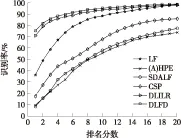
图7 CAVIAR4REID数据集下不同方法CMC曲线比较
Fig.7 Comparison of CMC curves of various methods on CAVIAR4REID dataset
表3 CAVIAR4REID数据集下不同方法的识别率
Table 3 Recognition rate of various methods on CAVIAR4REID dataset
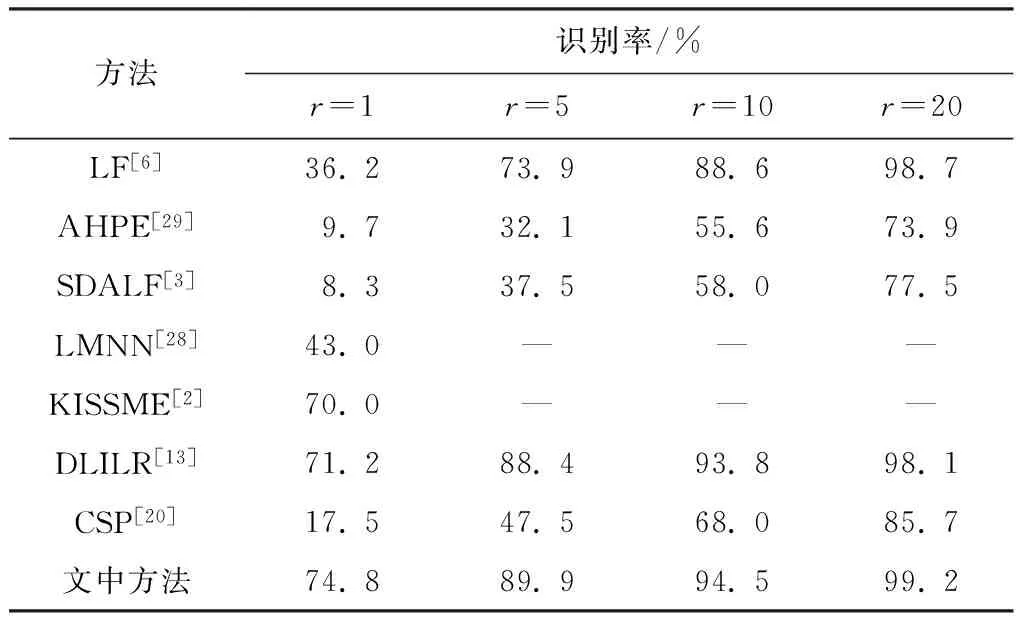
方法识别率/%r=1r=5r=10r=20LF[6]36.273.988.698.7AHPE[29]9.732.155.673.9SDALF[3]8.337.558.077.5LMNN[28]43.0———KISSME[2]70.0———DLILR[13]71.288.493.898.1CSP[20]17.547.568.085.7文中方法74.889.994.599.2
表中是针对多幅图像的实验结果,即在摄像头A和摄像头B下各取5张图像作为Gallery集和Probe集进行匹配.表3中,在Rank- 1文中方法以约3%的差距高于DLILR方法,展示中文提出的最大化类间离散度、最小化类内离散度方法的有效性;同时也表明文中方法在字典学习领域有一定优势.图8是Rank- 1盒形图(Boxplot)的比较,可见文中方法与DLILR方法10次实验的Rank- 1取值都相对集中在中位线附近,没有出现异常点.
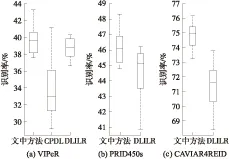
图8 不同数据集下盒形图比较Fig.8 Comparison of Boxplot on various datasets
根据实验结果可得,文中提出的模型可以高效运行,在时间复杂度上与DLILR方法具有可比性.例如,在3.30 GHz Intel CPU、8 GB内存、Matlab R2013a开发环境的台式机下,文中方法计算一幅图像特征的稀疏系数仅用0.034 s,DLILR方法花费0.023 s.而在图像匹配阶段,只需计算两幅图像稀疏系数的余弦距离.
4 结论
文中提出一种新的基于Fisher判别稀疏表示和字典学习行人重识别方法.利用字典学习的优势得到更好表示特征的稀疏系数.该方法充分考虑行人的身份判别信息,通过加入约束稀疏表示的正则化项,最大化不同类别行人稀疏系数的类间离散度,最小化同类别行人稀疏系数的类内离散度.充分利用两个不同区域图像特征间的联系,能够学习具有较好判别性能的字典.在公开数据集上的实验结果验证了该方法识别率高于目前基于字典学习的重识别方法的识别率.
参考文献:
[1] HIRZER M,ROTH P M,BISCHOF H.Person re-identification by efficient impostor-based metric learning [C]∥IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance.Beijing:IEEE Computer Society,2012:203- 208.
[2] LOSTINGER M,HIRZER M,WOHLHART P.Larg scale metric learning from equivalence constraints [C]∥ Computer Vision and Pattern Recognition.[S.l.]:IEEE,2012:2288- 2295.
[3] FARENZENA M,BAZZANI L,PERINA A.Person re-identification by symmetry-driven accumulation of local features[C]∥ Computer Vision and Pattern Recognition.[S.l.]:IEEE,2010:2360- 2367.
[4] WANG H,GONG S,XIANG T.Unsupervised learning of generative topic saliency for person re-identification [C]∥British Machine Vision Conference.[S.l.]:BMVA Press,2014:531- 543.
[5] ZHAO R,OUYANG W,WANG X.Learning mid-level filters for person re-identification [C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE Computer Society,2014:144- 151.
[6] PEDAGADI S,ORWELL J,VELASTIN S,BOGHOSSIAN B.Local fisher discriminant analysis for pedestrian re-identification [C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Washington:IEEE Computer Society,2013:3318- 3325.
[7] ZHAO R,OUYANG W,WANG X.Unsupervised salience learning for person re-identification [C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Portland:IEEE,2013:3586- 3593.
[8] ZHAO R,OUYANG W,WANG X.Person re-identification by salience matching [C]∥Proceedings of the IEEE International Conference on Computer Vision.Sydney:IEEE Computer Society,2013:2528- 2535.
[9] AHARON M,ELAD M,BRUCKSTEIN A.K-SVD :an algorithm for designing overcomplete dictionaries for sparse representation [J].IEEE Transactions on Signal Processing,2006,54(11):4311- 4322.
[10] MAIRAL J,BACH F,PONCE J,et al.Learning discriminative dictionaries for local image analysis [C]∥Computer Vision and Pattern Recognition.Anchorage:IEEE,2008:1- 8.
[11] LI S,LI K,FU Y.Cross-view projective dictionary learning for person re-identification [C]∥Proceedings of the 24th International Joint Conference on Artificial Intelligence(IJCAI).Buenos Aires:IEEE,2015:2155- 2161.
[12] LIU X,SONG M,TAO D,et al.Semi-supervised Coupled Dictionary Learning for Person Re-identification [C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Columbus:[s.n.],2014:3550- 3557.
[13] KODIRON E,XIANG T,GONG S.Dictionary learning with Iterative Laplacian Regularisation for unsupervised person re-identification [C]∥British Machine Vision Conference.[S.l.]:BMVA Press,2015:3- 8.
[14] YANG M,ZHANG L,FENG X,et al.Fisher discrimination dictionary learning for sparse representation [C]∥ 2011 International Conference on Computer Vision.Barcelona:IEEE,2011:543- 550.
[15] ROSASCO L,VERRI A,SANTORO M,et al.Iterative projection methods for structured sparsity regularization [Z].MIT Technical Reports,MIT-CSAIL-TR-2009-050,CBCL-282,2009:18- 47.
[16] YANG M,ZHANG L,YANG J,et al.Metaface learning for sparse representation based face recognition [C]∥IEEE International Conference on Image Processing.Hong Kong:IEEE,2010:1601- 1604.
[17] TIBSHIRANI R.Regression shrinkage and selection via the lasso [J].Journal of the Royal Statistical Society.Series B (Methodological),2011,73:273- 282.
[18] GRAY D,BRENNAN S,TAO H.Evaluating appearance models for recognition,reacquisition,and tracking [C]∥IEEE International Workshop on Performance Evaluation for Tracking and Surveillance (PETS).Rio de Janeiro:IEEE,2007:41- 47.
[19] ROTH P,HIRZER M,KOESTINGER M,et al.Mahalanobis distance learning for person re-identification [M]∥Person Re-Identification.London:Springer,2014:247- 267.
[20] CHENG D,CRISTANI M,STOPPA M,et al.Custom Pictorial structures for re-identification [C]∥Proceedings of the 22th British Machine Vision Conference.[S.l.]:BMVA,2011:1- 6
[21] DAVIS J,KULIS B,JAIN P,et al.Information-theoretic metric learning [C]∥Proceedings of the Twenty-Fourth International Conference on Machine Learning.Oregon:[s.n.],2007:209- 216.
[22] LISANIT G,MASI I,BAGDANOVa A,et al.Person re-identification by iterative re-weighted sparse ranking [J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2015,37(8):1629- 1642.
[23] LISANTI G,MASI I,DEL B.Matching people across camera views using kernel canonical correlation analysis [C]∥Proceedings of the International Conference on Distributed Smart Cameras.New York:ACM,2014:1- 6.
[24] DALAR N,TRIGGS B.Histograms of oriented gradients for human detection [C]∥2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05).San Diego:IEEE,2005:886- 893.
[25] AHONEN T,HADID A,PIETIKAINEN M.Face description with local binary patterns:Application to face recognition [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28(12):2037- 2041.
[26] MIGNON A,JURIE F.Pcca:A new approach for distance learning from sparse pairwise constraints [C]∥Computer Vision and Pattern Recognition.Aalmstad:IEEE,2012:2666- 2672.
[27] MA B,SU Y,JURIE F.Bicov:a novel image representation for person re-identification and face verification [C]∥Proceedings of the 2012 British Machive Vision Conference.Guildford:[s.n.],2012:231- 239.
[28] WEINBERGER K,SSUL L,BLITZER J.Distance Metric Learning for Large Margin Nearest Neighbor Classification [J].Journal of Machine Learning Research,2006,10(1):207- 244.
[29] BAZZANI L,CRISTANI M,PERINA A,et al.Multiple-shot person re-identification by chromatic and epitomic analyses [J].Pattern Recognition Letters,2012,33(7):898- 903.
PedestrianRe-IdentificationontheBasisofDictionaryLearningandFisherDiscriminationSparseRepresentation
ZHANGJian-weiLINWen-zhaoQIULong-qing
(School of Computer Science and Engineering, South China University of Technology, Guangzhou 510006, Guangdong, China)
In order to overcome the inadequate consideration of the existing dictionary learning taken into the connection of pedestrian features of different camera views, a new pedestrian re-identification method is proposed on the basis of dictionary learning and Fisher discrimination sparse representation. By considering the similar sparse representation of features of the same pedestrian in different scenes, the concept of pedestrian re-identification scatter function is put forward through adding a regularization term that constrains the sparse representation. The regularization term aims at maximizing the between-class scatter of the sparse representation of different pedestrians, and minimizing the within-class scatter of the sparse representation of the same pedestrian. Thus, sparse representation with strong discrimination ability can be obtained via dictionary learning. Experimental results on VIPeR, PRID 450s and CAVIAR4REID datasets indicate that the recognition rate of the proposed method is higher than that of other dictionary learning-based pedestrian re-identification methods.
pedestrian re-identification; Fisher discrimination; dictionary learning; sparse representation; scatter
2016- 09- 08
国家自然科学基金资助项目(61472145);广东省科技计划项目(2016B090918042)
*Foundationitems: Supported by the National Nutural Science Foundation of China(61472145) and the Science and Technology Planning Project of Guangdong Province(2016B090918042)
张见威(1969-),女,副教授,主要从事医学图像分析与识别、视频智能分析、图像配准及行人重识别研究. E-mail:jwzhang@scut.edu.cn
1000- 565X(2017)07- 0055- 08
TP 391.4
10.3969/j.issn.1000-565X.2017.07.008
