数据挖掘在温室大棚上的应用研究
2017-12-15,,,
,, ,
(1.浙江大学城市学院 杭州市物联网技术与应用重点实验室,杭州 310015;2.浙江大学 计算机科学与技术学院,杭州 310015)
数据挖掘在温室大棚上的应用研究
郑增威1,陈汉群1,2,孙霖1,蔡建平1
(1.浙江大学城市学院杭州市物联网技术与应用重点实验室,杭州310015;2.浙江大学计算机科学与技术学院,杭州310015)
随着物联网的兴起,数据的积累速度、维度以及体积等也越来越大,成了真正的大数据范畴;在农业温室大棚中部署的大量各种各样的传感器产生了大量多源异构的传感数据,而且这些数据中存在需要清洗的各种脏乱数据;文章按照数据清洗,模型构建和模型应用3个部分进行详述,首先介绍数据清洗技术和多源异构数据的融合技术,然后列举了常见的预测模型构建方法并分别指出了每种方法的适用情况,最后对常见的应用领域进行了综述和总结,并提出了目前还存在的问题,以及对未来的展望。
数据挖掘;温室大棚;数据清洗;异构数据
0 引言
在云计算和大数据等新兴技术的兴起和完善,在农业培育领域也出现了相应的新技术,其中基于物联网技术的温室大棚栽培技术也开始在不断的发展。就实际的应用来看,物联网温室大棚技术主要是在温室里面布设多种传感器件、控制执行器以及由它们构成的滴管系统、变温系统、加湿系统和通风系统等。通过各种各样的传感器件将农业栽培活动过程中的海量环境信息和作物生长数据通过已有的互联网络传输至云端服务器进行处理、加工,然后再通过互联网传输到智能终端系统进行展示、智能化管理、电子化交易,对作物生长进行更加细粒度的控制。从而改变以往低效、粗放的农业行为,实现更加高效、节能、生态和安全的生产行为。
正由于物联网和各种传感信息获取技术的不断延伸和普及应用,使得温室栽培领域积累的数据爆发式的增长:数据增长速度越来越快、数据体积越来越大、数据结构和维度越来越复杂、数据的冗余量越来越多、数据处理和应用面临着越来越大的考验等[1]。各类格式的传感器无时无刻不在产生着大量的数据,空气温湿度、土壤温湿度、农作物的叶绿素值及其病害情况等数据持续不断的送往服务器并被存储在云端的数据仓库[2]中。如同互联网[3]一样,如今的温室大棚研究领域也已经积累了来自传感器的海量数据,这些数据的体积之大和结构之复杂单靠人工是无法进行全面而透彻的进行分析的,所以就需要引入数据挖掘相关的研究算法。
本文首先介绍了数据预处理的常见方法,包含数据清洗和多源异构数据的融合技术,然后对比了常见的模型构建的方法,最后简要列举了数据挖掘算法在温室大棚领域中比较常见的应用以及总结,并对后续算法研究中面临的问题进行了简要分析总结。
1 数据清洗
数据清洗是数据预处理的主要工作,它的目的是提高数据的质量,以便下一步模型建立。一般来说,在实际传感器中收集而来的原始数据很可能会含有很多的缺失值,也有可能包含各种数据噪音。这可能是因为传感器本身对一些异常值的处理方式不同,也有可能是在收集和录入数据时人为操作失误导致异常值的产生。这些情况都会导致数据出现不稳定性,模糊性,出现残缺数据、错误数据和重复数据等“脏数据”,对之后使用算法模型挖掘出有效的信息产生很大的困扰。因此,在进行模型建立之前,我们必须使用一些措施来对这些不符合要求的数据进行清洗,以便提高数据的质量。
正常情况数据清洗的第一个步骤就是对数据使用一些数学方法进行统计分析,通过一些图表来了解哪些数据是不合理的,同时也能够明白数据的基本情况。在分析完数据之后,需要对数据的缺失值进行处理。缺失值的产生有很多原因,可能是设备在收集的时候处理不当产生的,也有可能是人工录入数据的时候不小心看错或者是漏掉导致的。在处理的缺失值的时候首先应该判断缺失值的分布情况,然后根据不同的数据场景应用不同的处理方法。比较常用的缺失值处理方法有以下几种[4]。
1.1 中位数或均值替代法
使用均值来替代,这种方法的好处是:不会导致样本信息变少,而且操作起来也比较简单。但是有个缺点就是当缺失数据不是随机数据时会产生偏差。对于正常分布的数据可以使用均值代替,如果数据是倾斜的,使用中位数可能更好。
1.2 插补法
常见的插补法主要以以下几种:随机插补法,从总体中随机抽取某个样本代替缺失样本;多重插补法,通过变量之间的关系对缺失数据进行预测,利用蒙特卡洛方法生成多个完整的数据集,在对这些数据集进行分析,最后对分析结果进行汇总处理;热平台插补,指在非缺失数据集中找到一个与缺失值所在样本相似的样本(匹配样本),利用其中的观测值对缺失值进行插补,优点:简单易行,准确率较高,缺点:变量数量较多时,通常很难找到与需要插补样本完全相同的样本。但我们可以按照某些变量将数据分层,在层中对缺失值实用均值插补。
1.3 建模法
可以用回归、使用贝叶斯形式化方法的基于推理的工具或决策树归纳确定。例如,利用数据集中其他数据的属性,可以构造一棵判定树,来预测缺失值的值。
以上各种缺失值处理的方法各有优劣,在实际使用的时候需要根据具体情况,如数据的倾斜度、缺失值所占的比例和分布情况等来进行选取。正常来说,建模法由于是根据已有的值来预测缺失值,准确率更高,所以是比较常见的方法。
处理完缺失值后,数据中往往还会存在着异常值。从统计图形上来看,异常值通常也称为“离群点”。在处理异常值的时候,可以视算法特性而定,有些算法可能对异常值并不是很敏感,那么就可以不需要对其进行处理,而有的算法对这些“离群点”比较敏感,比如K-Means,KNN之类的算法,那么就需要对异常值进行处理了。当数据中可以明显观察出异常数据量比较少的时候是可以直接将它们删除掉,否则可以使用平均值替代法来进行操作,这种方法均有损失小,简单高效的优点。还有一种方式就是将异常值当做缺失值来进行处理,使用以上处理缺失值的方法来进行。
由于一些感知信息如大棚室温、土壤温度、空气湿度等并不是时刻在发生着变化,它们更多的是以小时为时间单位而发生变化,而传感器的数据采集频率正常是远没有这么久,这就导致了一个问题:数据存在极大的冗余性[2]。数据冗余性除了会增加模型的训练时间之外,还有会加大数据的传输量和带宽延迟。
在消除冗余数据方面,Jeffrey提出了基于管道的算法,根据原始数据的特性使用了两种不同的步骤进行处理,这种算法可以很好的处理数据的重复读取,降低冗余性[6]。Jeffrey在他的另一篇论文中提出一个基于时间相关的数据清洗策略,该策略使用一个可能性模型和来解决数据的泄露问题[4]。另外,Sarma 也介绍了一个管道算法来提高7去除冗余之后数据流的质量[8]。
2 异构信息融合方法
虽然我们在前文对数据进行过清洗,不过仍然存在问题就是数据的多源异构性。由于数据是来自各种各样的传感器,包括环境感知数据、作物生长数据等,这些数据从内容、格式上来分析都是不同的,因此如果想对这些数据进行下一个的加工就需要先对其进行融合,将数据格式融合统一之后才可以执行下一步的加工操作。由布设于温室环境中大量的传感器和执行器所构成的环境数据信息感知系统、作物生长信息感知系统以及滴管系统、变温系统和通风系统,将所采集的大量的农业信息数据通过网络传输到云端服务器进行加工处理,以帮助农民智能化农业生产活动,通过预警机制及时发现问题,准确知道发生问题的具体位置。实现以大量传感设备和执行设备为中心的智能化生产模式,通过各种自动化、智能化、远程控制的生产设备使得人从繁重的农务中解放出来。在上述系统中,主要的传感器设备包括温湿度传感器、酸碱性传感器、二氧化碳传感器和光照传感器等设备,运用这些传感器对温室环境进行侦测,所得结果数据类似如表1所示。将传感器传回来的各种数据通过仪表和各类显示走势图实时展示温室情况,对作物的生长环境进行实时监控以保证作物的健壮成长。
产生于不同种类的传感器件的各种各样的数据信息,对之后的数据加工有着很大的干扰,直接利用它们进行分析预测会导致结果模型不稳定,模型不够鲁棒,而且数据处理过程中由于要判断不一样的数据也会导致梳处理速度变慢。因此,可以使用数据融合技术对这些异构数据进行预处理,使其形成完整统一的数据,这样才可以继续下一步的预测模型构建,数据融合技术是数据预处理过程中的主要工作。
1991年,由美国(joint directors of laboratories, JDL)提出了一种数据融合模型[10],业界的大部分研究者都接受这个融合模型。当前,由于已有的大多数融合系统在实现的细节上还存在着诸多的不一致,所以很多学者还在寻求一种新的理想的模型框架。不过,幸运的是现有的一些工具或者方案可以符合一些功能上的要求,比如FLAMES系统、SceneGen[11]工具、MRS[12]工具等系统和工具。数据信息融合的研究设计到很多理论知识,从数据结构算法的角度来看,大概可以分为:人工智能方法和概率统计方法两个大类。其中人工智能方法中模糊理论神经网络、D-S 证据推理、Bayes 估计这3个占了融合算法的85%,另外粗糙集等机器、遗传算法、支持向量机学习方法也已经开始在信息融合中深入应用。常见的机器学习融合算法主要有表2所描述的几种。
除了从算法的角度进行分类之外,还可以从异构数据集成技术的角度来对数据融合方法进行分类,分为模式集成方法和数据复制方法。其中,模式集成方法主要思路是通过将所有的数据源集中成一个全局模式,用户在使用的时候可以基于全局模式来透明的访问每一个数据集里面的数据,中间件集成方法和联邦数据库是当下两种比较典型的模式集成方法[15],如表3所示。而数据复制方法的主要思想是通过将异构的数据集统一存放在中央数据库里面,其中,数据仓库是数据复制方法中比较受欢迎的一种方法。Hadley通过定义对数据语义的理解和映射,使用典型的关系型数据库对其做了新的定义[16],使用变量名作为数据表的列,具体的数据存放在二维表关系表的行里面,从而将多远异构数据融合存放在一个新的统一数据库里面[17]。
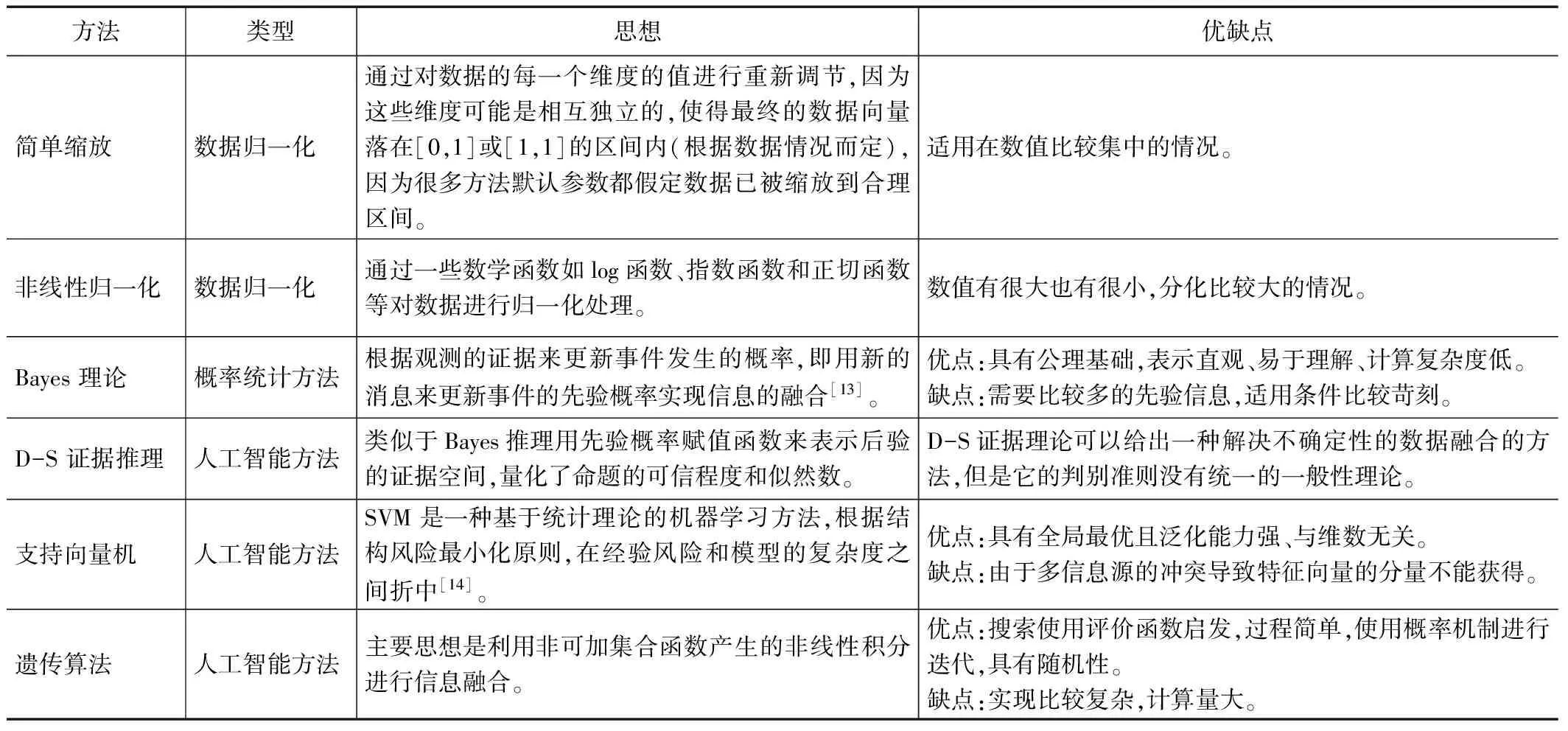
表2 常见的机器学习数据融合算法

表3 传统的异构数据集成工程技术
3 预测模型在温室大棚中的研究现状
3.1 模型构建方法
在处理完大量异构数据的预处理和信息融合等工作之后,接下来的任务就是进行植物生长预测模型的构建工作。模型构建的主要过程是在缺失的、海量的、随机和有杂音的数据中,通过一些数据挖掘算法分析出这些传感数据信息里面所包含的、潜在有价值的信息和知识的过程。由于温室作物栽培过程的一些特性:作物类型繁多,土壤种类复杂且不易检测,密度、水分和气候等多种因素之间相互影响影响,作物病害频繁发生且不断出现新的症象,这样就使得关于数据库与知识库具有多个维度、数据不完整、矩阵稀疏性高、数据量大、数据不确定、动态等特征,使得本来就复杂的传感数据变得更加的模糊不清。所以,在选择模型构建方法的时候,所选择的方法应该要适合与处理温室农业领域的相关数据特征。此外前面所提及的数据有领一个重要的特征,那就是它的测量方式往往是和当前时间互相挂钩的,因此在进行数据分析的时候,应该要尽量考虑时间方面的因素。模型构建的主要步骤如下所示[20](图1):

表4 智慧农业上常用的模型构建方法
1)数据定义:创建元数据,定义相关专业领域的情况,了解基础知识背景,理清用户的需求。这是创建数据质量改善方法和数据仓库的首要步骤。
2)数据准备:这一步是数据分析挖掘过程中的重要环节,需要对原始数据进行清洗和过滤操作,然后检验数据的一致性和完备性,其中,主要的工作是处理噪音数据,以及对缺失的数据进行填充。
3)模型构建:通过对比多种数据挖掘算法,选出符合要求的算法,然后确定最终的预测算法。
4)数据挖掘:利用前一步骤所选择的预测算法,从经过预处理的数据中分析出用户想要的信息,将这些信息提炼成某种特定的规则表达式,然后持久化存储。
5)知识评估:知识评估包含知识的解释、知识外推和预测模型的优化等等。将挖掘得到的知识以用户可以容易理解的方式展示出来,根据用户的需求对数据挖掘过程中的缪写步骤进行修改优化,直到符合用户的要求为止。
在智慧农业发展过程中,主要有以下表4所述的几种模型构建方法比较常见。

图1 数据挖掘过程
3.2 常见应用方向概述
在大棚农业系统中,由于土壤类型众多,作物品种复杂,病虫害发生频繁且病发症状不断变化,土壤营养成分、温湿度以及气候相互之间的关系和影响,仍然还有许多未知的规律还未被人类所发现。在前面介绍完数据清洗和数据融合技术等预处理技术以及常见的模型构建方法之后,本节主要介绍数据挖掘技术在大棚农业系统上的常见应用场景,主要有图2所示的几个应用。
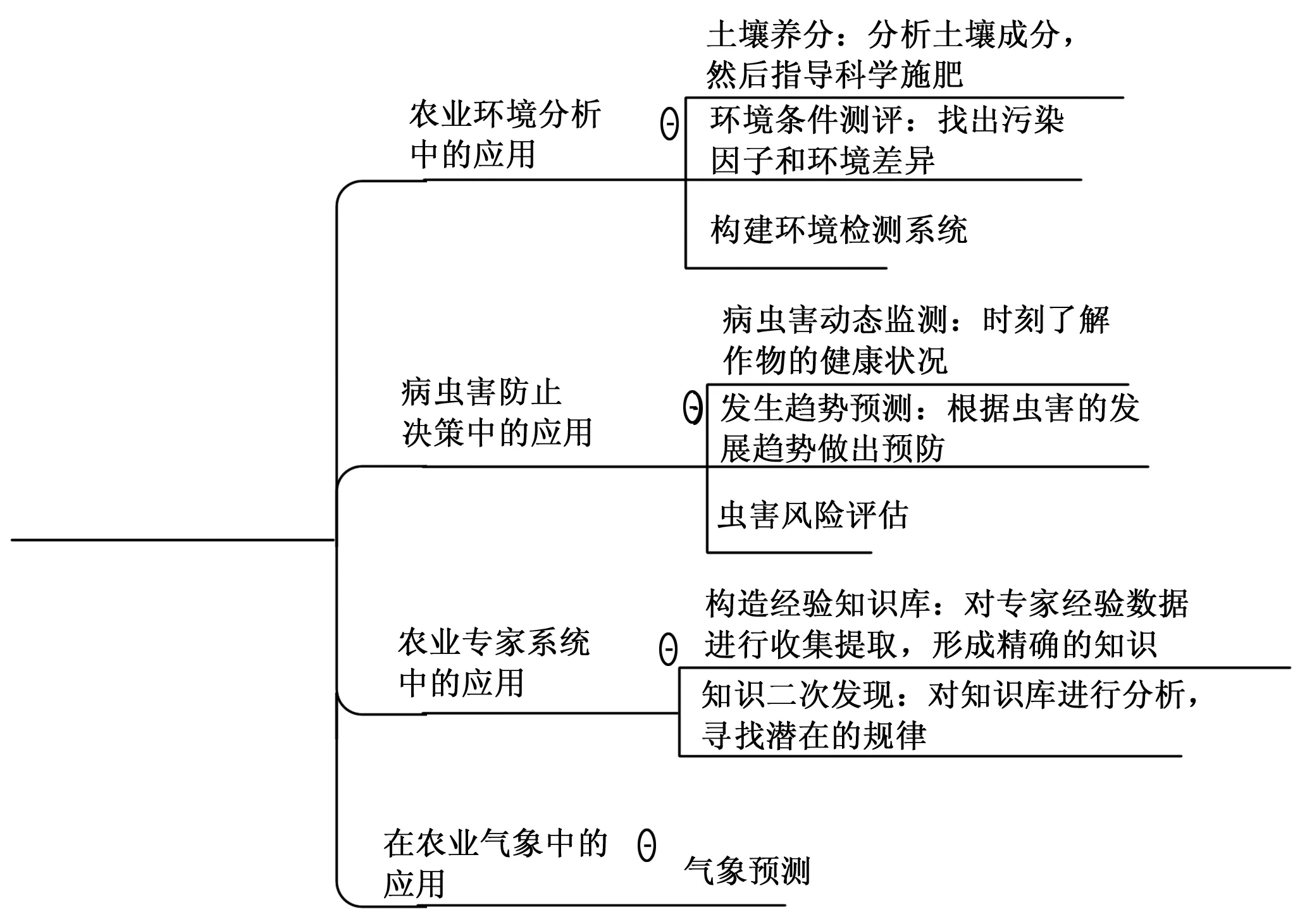
图2 数据挖掘在大棚农业上的应用
3.3 作物病害预测模型的实践研究
预测模型在大棚栽培的作物病害应用,归纳起来有这几种:发生趋势预测、风险评估病及其虫害动态监测等应用。温室作物里病害的发生条件受到了栽培耕作条件、农作物布局、气象条件和品种抗性等多种因素的作用,另外由于气候温度等的原因,所以病害的发生也与地理空间有一定的关联。预测模型能够用来预测在某个时间段内发生病害的概率,以及所发生的病害的乐行,从而为病害的预防治理决策提供参考支持。病虫害导致我国每年的经济损失达到了15~25%,因此研究病虫害的预测结果对农业的发展具有很大的意义。
关联规则挖掘(Association Rule Mining)最早是为了发现超市交易数据库中不同的商品之间的关系。它用于挖掘数据中隐含的练习,通过关联规则形式表示。Apriori算法是最有影响的挖掘关联规则的算法之一,该算法目前已应用于农业、商业、林业和教育等方面。Apriori算法通过分析事物之间的相互依赖关系,能发现和提取隐藏在在数据背后的有效知识,有助于人们认识和理解其中存在着的客观规律,具有很大的实用价值。Perrizo et al.通过使用Apriori算法,在支持度仍然比较低的情况下,通过寻找较高的置信度规则来预测温室中作物虫害的数量规模[25]。Wang et al.利用已收集的温室环境信息和Apriori算法提出了一个预测模型来构建实时的温室环境参数监测和植大棚作物虫害疾病监控系统[26]。Tripathy et al.使用关联规则挖掘技术发现了在温室环境温度18-20摄氏度,作物叶面湿度在7~10%,以及湿度处于70%或更高的时候是容易产生虫害的一个影响条件[27]。另外,Pratheepa et al.也发现了当温室环境最高温度处于28.3~33.1摄氏度,而最低温度处于 16.5~22.07 摄氏度并且相关湿度是在45.5~60%范围的时候,作物虫害事件的出现概率大大提高[28]。
3.4 专家决策支持系统的研究进展
大多数决策支持系统中的专家知识库是建立在相应领域的专家只是的基础上的,并且大棚农业领域中的专家只是多事经验性和描述性的,这就导致了很难使用数学模型对这些知识进行描述,所以专家决策支持系统存在着知识库中知识获取难度大、知识量少等难题。大棚农业生产支持决策系统是指以区域农业经济为研究对象,以农业可持续发展为决策目标,对大棚生产中的非结构化决策问题,通过提供温室环境和社会环境的背景资料协助明确问题、模型计算和列举可能发案等方式,为大棚生产的管理者做出正确决策提供帮助。
M.G.Hill et al.使用2008-2011年来自新西兰的四年的农场大棚数据,分别使用决策树、素朴贝叶斯、随机森林、支持向量机以及逻辑回归等数据挖掘技术在2008-2010三年的数据上构建了5个预测模型,然后预测2011年该年是否需要对猕猴桃作物进行农药喷洒。得出了每个模型各不一样的预测效果,其中决策树的准确率为49%,随机森林的准确率为98%,而朴素贝叶斯的准确率则为95%[29]。Sadok et al.提出了一个基于决策树算法的MASC模型,该模型将比较大而复杂的决策问题分解为一个个简单的以经济、社会和环境3个变量为维度的单元问题,产生32个重要的全局向量元素来评价作物系统[30]。Ellis et al.提出了包含数据库,地理信息系统,预测模型,知识库或专家系统,以及“混合”决策支持系统等元素的基于数据挖掘技术的决策支持工具,促进指导农林业发展,建议采纳和管理方面的决策过程,提高农林业同时实现环境保护和农业生产目标的能力[31]。Latika et al.使用数据挖掘技术构建了知识管理系统和OLAP在线分析系统[32]。
3.5 数据挖掘技术在植物生长过程中的预测
在我国传统农业的发展过程中,对于作物产量和果实质量的预测都是靠着果农的过往经验来进行预测的,特别是在环境气候因素与常年的情况偏离比较大的时候,这种人为预测的效果与实际值的偏差就更大了。当前在预测领域中,已经有不少的数据挖掘技术被付诸实践,如神经网络、遗传算法和高斯过程等技术,在各种预测领域中发挥着重要作用。其中使用数据挖掘进行预测的思路主要是从已有的各种数据中寻找潜在的模式和趋势的过程,目标是对大量的数据进行分类,从而发现新的信息。目前已有不少研究人员用相应的挖掘技术对大棚作物的成长过程进行了预测。
Georg et al.使用人工神经网络技术对小麦的产量进行预测,根据季节环境信息,土壤肥沃程度等数据预测的结果在误差允许的范围内,并且从环境和经济的角度实现了肥料的优化用法,提高了经济效益[33]。Cortet et al.根据法国东北部10年以来土壤中的生物肥料和矿物质等数据进行分析,发现生物尸体堆土壤中的磷成分有很大的影响,该论文使用数据挖掘技术验证了生物尸体对于维持土壤中的磷成分的方法是比较稳妥的[34]。贝叶斯分类技术是一种统计学分类方法,利用概率论统计知识进行分类的算法,具有分类简单、准确率高和速度快等优点。Shahinfar et al.使用朴素贝叶斯算法结合26个农场数据,对产量进行了精准的预测[35]。
3.6 本章小结
综合以上的概述来看,数据挖掘技术对该领域的数据分析主要还是停留在对经验数据的概率统计上,大部分的预测模型的预测准确性并不是很高,使用的预测算法主要是来自其他领域较为成熟的应用算法,各种算法的研发和应用仍然有待提高,缺少大棚农业上的特色算法的创新和研制,研究人员应该利用温室培植的独有特点,然后结合已有的成熟算法进一步改造或者创造出适合温室作物生产生长预测的模型算法。
4 总结
由于信息科学技术的高速发展,使得大棚农业也快速走上了信息化和智能化的道路。本文分别从数据预处理,模型构建和预测模型的应用。数据预处理主要包含了数据清洗和多源异构数据的融合两部分,然后分析比较了数据挖掘在温室大棚上常用的模型预测方法,最后对这些模型构建方法在农业大棚上的应用情况进行了分析了举例,阐述当前的研究状况。另外,从温室大棚和智慧农业的角度来说,目前仍然存在以下几个问题。
第一个问题体现在数据预处理方面的数据缺失,模糊问题。所以在未来,应该克服传感器在收集数据时候出现的数据丢失和模糊等问题,可以在保存数据的时候对其进行格式的验证等;第二个问题是数据异构性仍然是当前需要面对的一个问题,如果能够统一数据格式和传输协议,相信这个问题也是能够得到很好的解决;最后一个问题是预测模型的创新,研究人员应该着重于农业培植的独有特点,结合已有的成熟算法进一步改造或者创造出适合大棚农业作物生产生长预测的模型算法。
因此,我们应当在互联网+的时代下,把握机会努力发展智慧农业,克服以上的问题[36-38],让智慧农业变得更加的智慧,更加自动化,以便减少人力和物力等资源的耗费。
[1] 王元卓, 靳小龙, 程学旗. 网络大数据:现状与展望[J]. 计算机学报, 2013, 36(6):1125-1138.
[2] Abdullah A, Hussain A. Data mining a new pilot agriculture extension data warehouse[J]. Journal of Research & Practice in Information Technology, 2006, 38(3):229-249.
[3] Brin S, Page L. The anatomy of a large-scale hypertextual Web search engine[A]. International Conference on World Wide Web[C]. Elsevier Science Publishers B. V. 1998:107-117.
[4] Bertossi L, Kolahi S, Lakshmanan L V S. Data Cleaning and Query Answering with Matching Dependencies and Matching Functions[J]. Theory of Computing Systems, 2013, 52(3):441-482.
[5] Wang L, Xu L D, Bi Z, et al. Data Cleaning for RFID and WSN Integration[J]. IEEE Transactions on Industrial Informatics, 2014, 10(1):408-418.
[6] Jeffery S R, Alonso G, Franklin M J, et al. A Pipelined Framework for Online Cleaning of Sensor Data Streams[A]. International Conference on Data Engineering. DBLP[C]. 2006:140-140.
[7] Jeffery S R, Garofalakis M, Franklin M J. Adaptive cleaning for RFID data streams[A]. International Conference on Very Large Data Bases[C]. Seoul, Korea, 2006:163-174.
[8] Sarma A D, Jeffery S R, Franklin M J, et al. Estimating data stream quality for object-detection applications[J]. Technical Report, 2006.
[9] 李治强, 苗放. 多源异构数据整合在信用系统中的应用研究[J]. 计算机技术与发展, 2007, 17(2):172-174.
[10] Dasarathy B V. Revisions to the JDL data fusion model[J]. Proceedings of SPIE - The International Society for Optical Engineering, 1999, 3719:430-441.
[11] Mehta C, Srimathveeravalli G, Kesavadas T. An approach to design and development of decentralized data fusion simulator[A]. Winter Simulation Conference[C]. IEEE, 2005:7 pp.
[12] Vanhamme L, Van d B A, Van H S. Improved method for accurate and efficient quantification of MRS data with use of prior knowledge[J]. 1997, 129(1):35-43.
[13] Zhang J, Kang D K, Silvescu A, et al. Learning accurate and concise naive Bayes classifiers from attribute value taxonomies and data[J]. Knowledge and Information Systems, 2006, 9(2):157-179.
[14] Shevade S K, Keerthi S S, Bhattacharyya C, et al. Improvements to the SMO algorithm for SVM regression[J]. IEEE Transactions on Neural Networks, 2000, 11(5):1188-93.
[15] 李晓丽. 异构数据集成技术在物联网中的研究与应用[D]. 北京:北京邮电大学, 2013.
[16] Grolemund G, Wickham H. A Cognitive Interpretation of Data Analysis[J]. International Statistical Review, 2014, 82(2):184-204.
[17] Wickham H. Tidy data[J]. Journal of Statistical Software, 2014, 059.
[18] 朱好好. 异构数据融合中间件的研究与应用[D]. 武汉:华中科技大学, 2012.
[19] Delgado G, Aranda V, Calero J, et al. Using fuzzy data mining to evaluate survey data from olive grove cultivation.[J]. Computers & Electronics in Agriculture, 2009, 65(1):99-113.
[20] Fernandez Martinez R,Martinez-de-Pison Ascacibar F J, Pernia Espinoza A V, et al. Predictive modelling in grape berry weight during maturation process: comparison of data mining, statistical and artificial intelligence techniques[J]. Spanish Journal of Agricultural Research 2011 9(4), 1156-1167.
[21] Wu X, Kumar V, Ross Quinlan J, et al. Top 10 algorithms in data mining[J]. Knowledge and Information Systems, 2008, 14(1):1-37.
[22] Tsang I W, Kwok J T, Cheung P M. Core Vector Machines: Fast SVM Training on Very Large Data Sets[J]. Journal of Machine Learning Research, 2005, 6(1):363-392.
[23] Ahmed S, Coenen F, Leng P. Tree-based partitioning of date for association rule mining[J]. Knowledge and Information Systems, 2006, 10(3):315-331.
[24] Caruana R, Niculescu-Mizil A. An empirical comparison of supervised learning algorithms[A]. International Conference on Machine Learning[C]. ACM, 2006:161-168.
[25] Perrizo W, Ding Q, Ding Q, et al. Deriving High Confidence Rules from Spatial Data Using Peano Count Trees.[J]. Lecture Notes in Computer Science, 2001, 2118:91-102.
[26] Wang X F, Wang Z, Zhang S W, et al. Monitoring and Discrimination of Plant Disease and Insect Pests based on agricultural IOT[A]. International Conference on Information Technology and Management Innovation[C]. 2015.
[27] Tripathy A K, Adinarayana J, Vijayalakshmi K, et al. Knowledge discovery and Leaf Spot dynamics of groundnut crop through wireless sensor network and data mining techniques[J]. Computers & Electronics in Agriculture, 2014, 107(107):104-114.
[28] Pratheepa M, Verghese, Abraham, Bheemanna, H. Weighted Association rule mining for the occurrence of the insect pest Helicoverpa armigera(Hubner) related with abiotic factors on cotton[A]. International Conference on Computing For Sustainable Global Development[C]. 2016.
[29] Hill M G, Connolly P G, Reutemann P, et al. The use of data mining to assist crop protection decisions on kiwifruit in New Zealand[J]. Computers & Electronics in Agriculture, 2014, 108:250-257.
[30] Sadok W, Angevin F, Bergez J E, et al. MASC, a qualitative multi-attribute decision model for ex ante assessment of the sustainability of cropping systems.[J]. Agronomy for Sustainable Development, 2009, 29(3):447-461.
[31] Ellis E A, Bentrup G, Schoeneberger M M. Computer-based tools for decision support in agroforestry: Current state and future needs[J]. Agroforestry Systems, 2004, 61(1):401-421.
[32] Latika Sharma, Nitu Mehta. Data Mining Techniques: A Tool For Knowledge Management System In Agriculture[J]. International Journal of Scientific & Technology Research, 2012, 1(5):67-73.
[33] Rub G, Kruse R, Schneider M, et al. Data Mining with Neural Networks for Wheat Yield Prediction[J]. Lecture Notes in Computer Science, 2008, 5077:47-56.
[34] Cortet J, Kocev D, Ducobu C, et al. Using data mining to predict soil quality after application of biosolids in agriculture.[J]. Journal of Environmental Quality, 2011, 40(6):1972-1982.
[35] Shahinfar S, Page D, Guenther J, et al. Prediction of insemination outcomes in Holstein dairy cattle using alternative machine learning algorithms[J]. Journal of Dairy Science, 2014, 97(2):731-42.
[36] Qiang Y, Xindong W. 10 challenging problems in data mining research[J]. International Journal of Information Technology & Decision Making, 2006,5(4):597-604.
[37] Ojha T, Misra S, Raghuwanshi N S. Wireless sensor networks for agriculture: The state-of-the-art in practice and future challenges[J]. Computers & Electronics in Agriculture, 2015, 118(3):66-84.
ApplicationofDataMininginGreenhouse
Zheng Zengwei1, Chen Hanqun1,2, Sun Lin1, Cai Jianping1
(1.Hangzhou Key Laboratory for IoT Technology &Application, Zhejiang University City College, Hangzhou 310015,China;2.School of Computer Science and Technology, Zhejiang University, Hangzhou 310015,China)
With the rise of the Internet of Things, data accumulation speed, dimension and volume are also growing, and has become a real big data category. The large variety of sensors deployed in agricultural greenhouses produces a large number of multi-source heterogeneous sensing data, and there are various types of dirty data that need to be cleaned. In this paper, data cleaning, model building and model application are described in detail. Firstly, data cleaning technology and multi-source heterogeneous data fusion technology are introduced. Then, common forecasting model construction methods are listed. Finally, common application fields are introduced. Summarizes and puts forward the existing problems, as well as the prospect of the future.
data mining; greenhouse; data clean; heterogeneous data
2017-04-08;
2017-05-23。
杭州市农业科研主动设计项目(20162012A06);杭州市农业科研自主申报项目(20170432B30);杭州市物联网技术与应用重点实验室及杭州市农业科研主动设计项目(20162012A06)。
郑增威(1969-),男,教授,主要从事数据挖掘、普适计算、物联网技术等方向的研究。
孙 霖(1979-),男,博士,主要从事数据挖掘、普适计算、物联网技术等方向的研究。
1671-4598(2017)11-0123-06
10.16526/j.cnki.11-4762/tp.2017.11.032
TP312
A
