基于用电信息大数据平台在用户群体中的应用分析
2017-12-07马飞,王勇,郭伟
马 飞,王 勇,郭 伟
(北京汇通金财信息科技有限公司,北京 100053)
基于用电信息大数据平台在用户群体中的应用分析
马 飞,王 勇,郭 伟
(北京汇通金财信息科技有限公司,北京 100053)
近年,大数据技术已经在国民生产生活各个领域取得了巨大的经济和社会价值。电力行业数据是大数据应用的重要领域之一,用电数据具有自身鲜明的行业特点,其中蕴藏着丰富的商业价值和社会价值。本文介绍了如何运用大数据平台进行数据采集、存储和数据挖掘,通过具体场景分析了大数据技术在用户用电信息中的具体应用,从而改善用户体验,提高企业运营竞争力。
大数据;Hadoop;Hbase;Spark;数据挖掘;用电信息
0 引言
2016年3月16日全国两会发布《中华人民共和国国民经济和社会发展第十三个五年规划纲要》,纲要提出实施国家大数据战略,把大数据作为基础性战略资源,全面实施促进大数据发展行动,加快推动数据资源共享开放和开发应用,助力产业转型升级和社会治理创新。深化大数据在各行业的创新应用,探索与传统产业协同发展新业态新模式,加快完善大数据产业链。加快海量数据采集、存储、清洗、分析发掘、可视化、安全与隐私保护等领域关键技术攻关。促进大数据软硬件产品发展。完善大数据产业公共服务支撑体系和生态体系,加强标准体系和质量技术基础建设[1]。
1 国网公司大数据应用介绍
大数据作为重要的战略资源已经在全球范围内达成共识,国家电网是世界领先的电力能源企业,在国内也是率先实施大数据运用的重要企业之一。促进电力行业的大数据应用,有着重要的现实意义。
2015年,国网公司《国家电网公司大数据应用指导意见》明确了大数据应用顶层设计和应用计划,涉及三大领域35项典型应用场景,并正式启动企业级大数据平台的研发的试点工作。在电网生产、经营管理和优质服务3大领域全面推进大数据应用建设,构建服务于政府决策、社会用户、管理提升、安全保电等应用,提升公司数据应用水平,深化数据价值挖掘,创新服务模式,截至2016年累计建成74个应用,计划2017年新建85个应用。同年,国家电网公司发布《信息通信新技术推动智能电网和“一强三优”现代公司创新发展行动计划》,加快推进“大云物移”等新技术在智能电网和公司经营管理中的创新应用,推动电网向全球能源互联网发展[2]。
2 用电信息大数据平台介绍
2.1 用电信息大数据平台关键技术
用电信息大数据平台采用目前主流的 Hadoop大数据体系架构设计开发,采用hive作为数据仓库来进行数据分析,hbase作为nosql数据库进行数据实时查询和存储,zookeeper作为分布式应用协调服务,spark作为数据挖掘和机器学习工具,sqoop进行数据迁移。
2.1.1 Hadoop介绍
Google的三大论文奠定了现在风靡全球的大数据理论基础。HDFS是 Google《The Google File System》的开源实现,MapReduce是《MapReduce:Simplified Data Processing on Large Clusters》的开源实现。Hadoop则是项目的总称,主要是由HDFS和MapReduce组成。HDFS为海量的数据提供了分布式文件存储,MapReduce则是一个编程模型,为海量数据提供了并行计算框架。
2.1.1.1 Hdfs介绍
Hdfs是一个开源的分布式文件系统,属于Hadoop的核心模块,设计理念是采用一台或多台机器来保存 metadata,剩下的机器则用来保存数据。HDFS采用master/slave主从架构。一个HDFS集群是由一个Namenode和一定数目的Datanode组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。
从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组 Datanode上。Namenode执行文件系统的名字空间操作。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在 Namenode的统一调度下进行数据块的创建、删除和复制[3]。

图1 Hdfs架构图Fig.1 Hdfs architecture diagram
2.1.1.2 MapReduce介绍
MapReduce是一个基于集群的高性能编程模型,用于处理海量T级数据的并行计算。其核心处理模型是,用户首先创建一个Map函数处理一个基于 key/value pair的数据集合,输出中间的基于key/value pair的数据集合;然后再创建一个Reduce函数用来合并所有的具有相同中间 key值的中间value值。
采用MapReduce架构的程序能够在大量的普通PC机上实现并行化处理。这个系统在运行时只关心:如何分割输入数据,在大量计算机组成的集群上的调度,集群中计算机的错误处理,管理集群中计算机之间必要的通信。采用MapReduce架构可以使那些没有并行计算和分布式处理系统开发经验的程序员有效利用分布式系统的丰富资源[4]。
2.1.2 Hbase
Hbase是Google《Bigtable: A Distributed Storage System for Structured Data》论文的开源实现,是一个分布式的、面向列的开源数据库,HBase中的所有数据文件都存储在Hadoop HDFS文件系统上。是一个开源,面向列,适合存储海量非结构化数据或半结构化数据的分布式存储系统。Hbase支持上百亿行,上百万列的大表存储,支持 PB级的数据存储和快速查询。
2.1.3 Hive
Hive是基于Hadoop的一个数据仓库工具,以普通程序员熟悉的SQL风格进行数据统计和分析。Hive将HDFS上结构化的数据文件映射为一张数据库表,采用HQL语音进行查询和处理。HQL底层处理则被转换为MapReduce任务进行运行,所以无法实现实时交互查询,Hive主要针对的是OLAP应用。
2.1.4 Spark
Spark是基于内存的并行化计算框架,极大提高了大数据环境下数据处理的实时性。核心数据模型是弹性分布式数据集RDD。相比于Mapreduce计算模型,Spark将中间输出结果缓存在在内存中,从而不再需要读写HDFS。Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
2.1.5 Sqoop
Sqoop主要用于在Hadoop(Hive)与传统的关系数据库中传递数据,可以很方便的将关系型数据库中的数据导进到HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2.1.6 数据平台技术架构图
数据平台技术框架图如图2所示。
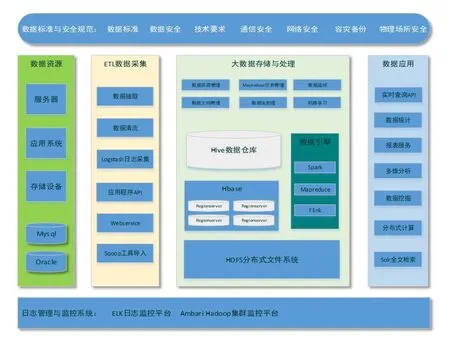
图2 信息大数据平台技术架构图Fig.2 Information big data platform technology architecture
2.2 用电信息大数据平台处理流程
2.2.1 数据采集
大数据平台采取定制的ETL应用和sqoop两种方式实现数据采集。现网账单数据来自各个省市的营销平台,数据来源多样,数据格式各个省市也不相同。采用ETL应用完成数据抽取、数据清洗和数据加载工作。使用hbase api直接插入数据库。对于历史数据,则采取sqoop直接从oracle导入Hbase。
2.2.2 数据存储
用户用电信息具有以下特点:
(1)数据量大,一个省一年用电信息大约1亿多,全国一年用电信息接近40亿条数据。
(2)数据稳定,采集到的用电数据不存在更新删除操作,主要用来用户的查询和后台统计分析。
(3)数据之间无复杂的关联关系,比较适合nosql数据库存储。
经过技术选项,采用 hbase进行数据的实时存储数据库,测试实验证明,对于亿级数据查询,响应毫秒级别。
2.2.3 数据处理
数据采集和数据存储都是为数据统计和数据挖掘做准备,数据挖掘的过程就是从大量的数据中通过算法搜索隐含在其中的、人们事先不知道的但又是潜在的有用信息和知识的过程。对于实时性需求不高的统计分析,采用Hive进行统计计算,比如计算年度总电量,年度用电排名等场景。对于需要数据挖掘和比较复杂的统计分析,则采用 mapreduce和 spark进行结合,运用各种数据模型和挖掘算法进行具体分析。
2.2.4 数据展现
成果的展示是大数据应用的最后一步。如果分析的结果无法正确的展现,有可能会误导用户和决策者。各种各样的数据可视化技术是大数据展示的有效方式。
3 用电信息大数据在用户应用场景分析
2013年《中国电力大数据白皮书》中指出,电力大数据的特征可以概括为3V3E。其中的3E分别是指数据即能量(Energy)、数据即交互(Exchange)、数据即共情(Empathy)。数据即共情指出,企业的根本目的在于创造客户,创造需求。用电信息数据联系到千家万户,推动企业应用以客户为中心,本质就是对电力用户的终极关怀。通过对电力用户需求的充分挖掘和满足,建立情感联系,为广大电力用户提供更加优质、安全、可靠的电力服务[5]。
3.1 趣味账单
简单点的用电账单统计分析,我们可以绘制家庭、小区、城市的全天、季度、年度用电曲线。复杂一点的统计,比如年度最高用电是那天,那个月份用电最高,一天那个时段是用电高峰,用电消费排位等,可以采用hive进行月度或年度统计,使枯燥的数据变得生动有趣,提高用户使用兴趣,增加产品使用粘度。
3.2 用电数据预测
对于普通家庭用户来说,日用电数据一般随季节进行波动,总体上表现比较平稳,采用时间序列预测法中的季节趋势预测未来的用电数据。对即将欠费的用户及时发送信息进行温馨提醒,这对于预付费用户,可以极大提高用户用电体验度,防止由于欠费导致突然停电的风险。
季节趋势预测法根据经济事物每年重复出现的周期性季节变动指数,预测其季节性变动趋势[6]。具体到用电信息数据,我们采用按照月、年的用电信息数据进行季节趋势预测,进行未来的用电数据预测。
3.3 营销智能分析系统
3.3.1 用电信息特征值提取
由于用户的用电量及用电行为不同,为了实现精准营销,需要细化用户。
根据居民用电变化趋势、用电量、用户基本信息、峰值、谷值、欠费记录、缴费情况作为特征值进行大数据挖掘、聚类分析。挖掘客户用电行为特征,识别高价值客户和高风险欠费客户。
特征值提取:
用电变化趋势:以年为单位,计算用户的年用电量的年增长率。
用电量:一定程度上反应用户的经济状况,经济状况良好的用户,用电量较大。反之,则用电量较小。
贡献度:根据用户缴费进行区间加权计算。
信誉度:主要针对用户的欠费和违规用电、恶意盗电等情况。可以以此建立用户的征信体系。欠费金额和欠费次数两个维度进行考核[7]。
通过K-Means聚类算法将用户划分为不同的客户群,对不同的客户群进行不同的营销方案,针对性的提高服务能力。
3.3.2 Spark MLlib K-Means算法简介
K-means 聚类算法原理。
聚类分析是一个无监督学习(Unsupervised Learning)过程,一般是用来对数据对象按照其特征属性进行分组,经常被应用在客户分群,欺诈检测,图像分析等领域[8]。K-means 应该是最有名并且最经常使用的聚类算法了,其原理比较容易理解,并且聚类效果良好,有着广泛的使用。
和诸多机器学习算法一样,K-means 算法也是一个迭代式的算法,其主要步骤如下:
第一步,选择 K 个点作为初始聚类中心。
第二步,计算其余所有点到聚类中心的距离,并把每个点划分到离它最近的聚类中心所在的聚类中去。在这里,衡量距离一般有多个函数可以选择,最常用的是欧几里得距离(Euclidean Distance),也叫欧式距离。公式如下:
其中C代表中心点,X代表任意一个非中心点。
第三步,重新计算每个聚类中所有点的平均值,并将其作为新的聚类中心点。
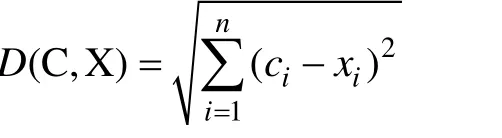
最后,重复(二),(三)步的过程,直至聚类中心不再发生改变,或者算法达到预定的迭代次数,又或聚类中心的改变小于预先设定的阀值。
Spark MLlib K-means 算法的实现在初始聚类点的选择上,借鉴了一个叫 K-means||的类 K-means++实现。K-means++ 算法在初始点选择上遵循一个基本原则: 初始聚类中心点相互之间的距离应该尽可能的远。基本步骤如下[9]:
第一步,从数据集X中随机选择一个点作为第一个初始点。
第二步,计算数据集中所有点与最新选择的中心点的距离 D(x)。
第四部,重复(二),(三)步过程,直到 K 个初始点选择完成。
聚类算法多次迭代示意图[10]。
3.4 客户用户信用等级
信用等级各个行业都有自己特有的计算方式,对于用户用电数据来说,建立一套特有的用电信用等级系统,可以有效的分配客户资源,对一些风险进行提取防控,我们以用户贡献度和欠费时长两个指标进行考核[11]。
3.5 电力地图
最著名的电力大数据应用就是美国的“洛杉矶电力地图”。美国加州大学洛杉矶分校、洛杉矶水电部及政府规划办公室共同开发了洛杉矶电力地图,将街区面积、建设时间、居民平均收入等信息集合在一起,归结分析社会各群体的用电特征,为城市发展和电网建设提供准确、直观、有效的规划测算依据[12]。
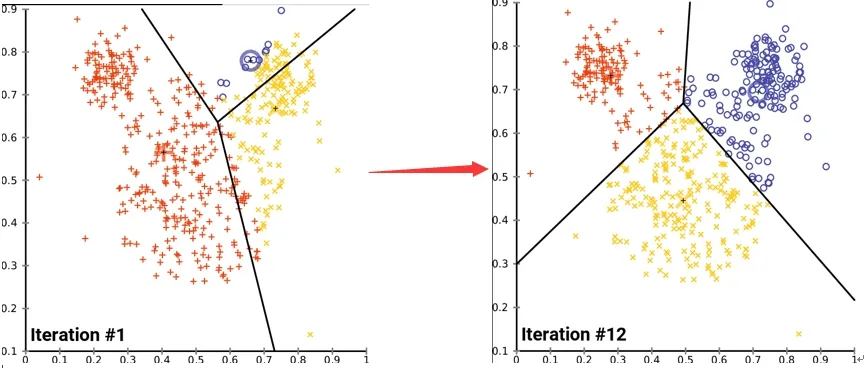
图3 聚类算法示意图Fig.3 Diagram of clustering algorithm
具体到用电信息大数据平台而言,由于平台存储了全国各个省市的居民用电信息。则可以描述各个国家以及各个省市的用电地图。通过用电地图发现稳定增长的用电区域和用户群体,从而为该区域的用户提供精准营销等商业活动。
4 结语
本文基于普通家庭用户用电信息,采用主流大数据存储、大数据挖掘技术,对具体的业务进行了应用分析。探讨了如何利用大数据,为用户提供更加智慧便捷的服务,进一步深化、挖掘了潜在的社会和商业价值。为企业提升服务水平和精细化营销提供数据参考,从而提升企业经济效益。
[1] 中华人民共和国国民经济和社会发展第十三个五年规划纲要(2016).
[2] 国家电网. 国家电网公司大数据应用指导意见2013.
[3] Apache, Hadoop分布式文件系统: 架构和设计2013.
[4] Alex, Google MapReduce中文版2010.
[5] 中国电机工程学会电力信息化专业委员会. 中国电力大数据发展白皮书2013.
[6] 杨颖. 运用季节和趋势模型预测用电负荷[J]. 电力需求侧管理, 2004, 6(3): 22-24.
[7] 肖乃慎, 李博, 孔德诗. 大数据背景下的电网客户用电行为分析系统设计[J]. 电子设计工程, 2015.3.
[8] 孙志伟, 大数据环境下用电行为分析的研究2015.3.
[9] 李玉波, 杨余旺, 唐浩,等. 基于Spark的K-means安全区间更新优化算法[J]. 计算机技术与发展, 2017, 27(8): 1-6.
[10] Wikipedia, k-means clustering--Standard algorithm (2017).
[11] 程丽冰. 大数据时代的电力客户分群管理应用研究[D]. 华南理工大学, 2016.
[12] 沈玉玲, 吕燕, 陈瑞峰. 基于大数据技术的电力用户行为分析及应用现状[J]. 电气自动化, 2016, 38(3):50-52.
Application Analysis in User Groups Based on Electricity Information Big Data Platform
MA fei1, WANG yong2, GUO wei3
(Beijing huitong jincai information technology Co., Ltd., Beijing 100053, China)
In recent years, big data technology has made great economic and social value in all fields of national production and life. Electricity industry is one of the important areas of big data, electricity big data has its own distinctive industry characteristics, electricity information data contains rich commercial value and social value. This paper introduces how to use big data platform for data acquisition, storage and data mining, through specific scene analysis of large data technology application in electric information of users, so as to improve the user experience,improve the competitiveness of enterprises.
Big data; Hadoop; Hbase; Spark; Data mining; Electricity information
TP311.13
A
10.3969/j.issn.1003-6970.2017.11.026
本文著录格式:马飞,王勇,郭伟. 基于用电信息大数据平台在用户群体中的应用分析[J]. 软件,2017,38(11):132-136
马飞(1981-),男,本科,北京汇通金财信息科技有限公司,主要研究方向:大数据;王勇(1982-),男,北京汇通金财信息科技有限公司,主要研究方向:互联网+电力营销服务、互联网技术;郭伟(1981-),男,国网新疆电力科学研究院,研究方向:电力营销、供电服务、互联网+电力营销服务。
