数据发布中k-匿名隐私保护技术研究
2017-12-07吴伟明谷勇浩
岳 思,吴伟明,谷勇浩
(1. 北京邮电大学计算机学院 智能通信软件与多媒体北京市重点实验室,北京 100876;2. 国家电网公司信息通信分公司,北京 100761)
数据发布中k-匿名隐私保护技术研究
岳 思,吴伟明,谷勇浩
(1. 北京邮电大学计算机学院 智能通信软件与多媒体北京市重点实验室,北京 100876;2. 国家电网公司信息通信分公司,北京 100761)
随着互联网技术的迅猛发展,隐私保护已成为社会以及机构越来越关心的问题,数据挖掘技术的应用使得隐私泄露问题日益突出,隐私保护是目前数据发布中隐私泄露控制技术研究的热点问题之一,而 K-匿名是近年来隐私保护研究的热点。本文介绍了K-匿名的基本概念,阐述了泛化与隐匿技术,研究了基于datafly的多维属性泛化 K-匿名模型,并对该模型的基本原理、缺点进行分析,做出了相应的改进,在数据预处理阶段增加泛化层限制并且在准标识符属性选取时引入近似度分析,并对改进后的 K-匿名进行实验,实验结果证明改进有效提高了处理后的数据精度。
数据发布;隐私保护;K-匿名;泛化与隐匿;datafly
0 引言
随着 Internet技术、大容量存储技术的迅猛发展以及数据共享范围的逐步扩大,数据的自动采集和发布越来越频繁,信息共享较以前来得更为容易和方便;但另一方面,以信息共享与数据挖掘为目的的数据发布过程中隐私泄露问题也日益突出,因此如何在实现信息共享的同时,有效地保护私有敏感信息不被泄漏就显得尤为重要。数据发布者在发布数据前需要对数据集进行敏感信息的保护处理工作,数据发布中隐私保护对象主要是用户敏感信息与个体间的关联关系,因此,破坏这种关联关系是数据发布过程隐私保护的主要研究问题[1]。
目前解决该问题的方法主要有以下三种(1)匿名。有的机构为了保护个人隐私不被泄露,常常对姓名身份证号等能表示一个用户的显示标识符进行删除或者加密,但是攻击者可以通过用户的其他信息,例如生日、性别、年龄等从其他渠道获取的个人信息进行链接,从而推断出用户的隐私数据。(2)数据扰乱。对初始数据进行扭曲、扰乱、随机化之后再进行挖掘,尽管这种方法能够保证结果的整体统计性,但一般是以破坏数据的真实性和完整性为代价[2]。(3)数据加密。基于密码的隐私保护技术,主要利用非对称加密机制形成交互计算的协议,实现无信息泄露的分布式安全计算,以支持分布式环境中隐私保持的挖掘工作,例如安全两方或多方计算问题,但该方法需要过多的计算资源。
为了弥补以上三种方法的不足,1998年,P.Samarati和L.seweney在PODS国际会议上提出了K-匿名的概念,这一技术得到了广泛关注。2002年,L.seweney又进一步提出了K-匿名隐私保护模型,同年他又论述了通过泛化和隐匿的方法来实现这一技术。然而,目前如何通过匿名化技术更为高效的实现发布数据的隐私保护,仍然是业界当前研究的重要课题,本文旨在通过分析数据发布隐私保护中匿名化的基本原理和实现技术,在研究K-匿名的传统实现算法-datafly算法的基础上,进一步对基于多维属性泛化的K-匿名隐私保护模型做出了改进,引入近似度分析并通过对不同的准标识符属性的泛化树增加限制达到满足不同数据需求的效果,使数据表能够尽快的满足K-匿名,并且提高处理后数据的可用性。
1 K-匿名的相关概念
1.1 属性划分
假设数据发布者持有的信息为数据表T(A1,A2,A3…An),表中的每条记录表示一个用户的基本信息,如姓名、籍贯、年龄、性别、健康状况等。如表1所示。
数据表中的属性按功能可分为互不相交的四种。
(1)标识符(Identifier)
能够唯一标识个体身份的属性或属性集合,如表T中的身份证号、姓名等,在数据发布前,一般要将这些显示标识符属性删除、屏蔽或者加密,以达到保护这些私有属性的目的。

表1 数据表T实例Tab.1 Ta ble T
(2)准标识符(Quasi- Identifier)
能与其它数据表进行链接从而能够标识一个个体的属性或者属性集合。表中的属性都可以为准标识符,准标识符的选择取决于外部链接的数据表,同一张表对于不同的外部表可能有不同的准标识符[2]。
(3)敏感属性(sensitive attribute)
即敏感信息,数据发布时需要保密,如疾病,薪水,婚姻状况等。
(4)非敏感属性(Non- sensitive attribute)
可公开的属性,又称普通属性,如表中的年龄。
1.2 链接攻击
链接攻击是从发布的数据中获取隐私数据最常见的方法之一。攻击人员利用从其他渠道获取的数据和包含隐私信息的发布的匿名表进行链接,从而推断出隐私数据,造成了隐私泄露[4]。
例如攻击者获得选民表如表 2,以及以上去除标识符的个人信息表表 1,这里(sex、age、zip、Provice)可以构成准标识符,攻击者根据准标识符进行链接,就可以推断出李青患有肺炎这一敏感信息。
1.3 K-匿名的定义
K-匿名隐私模型要求每条记录(属于一个个体)在公布的数据中与其他至少K-1条记录无法被区分开来[6]。因此,知道被攻击者的准标识符属性值的攻击者,是不能够将这条记录与其他至少K-1个数据记录区分开。这被称为身份攻击防范。具有相同准标识符值的记录构成一个等价类,即k-匿名实现了同一等价类内的记录无法区分开来。
2 多维属性泛化K-匿名的基本实现方法
K-匿名隐私模型目前主要是通过隐匿和泛化来实现,不同于一般的扭曲、扰乱和随机化等方法,该方法仅隐藏数据细节,能够使数据在发布前后保持一致性和真实性。
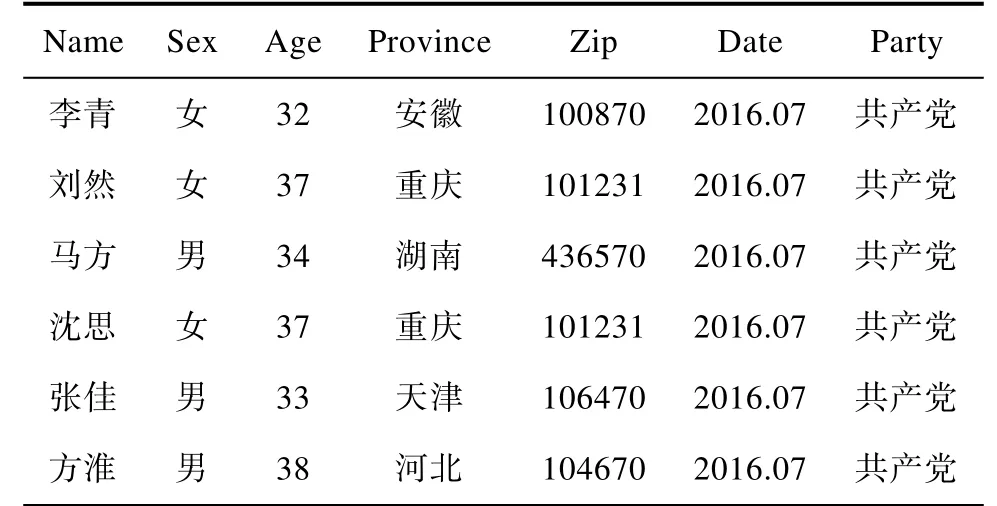
表2 选民信息表Tab.2 T able voter
2.1 隐匿与泛化
在 K-匿名隐私保护模型中单独使用隐匿的情况比较少,一般采用泛化技术或者泛化和隐匿相结合使用。在k-匿名过程中,若某些记录无法满足匿名要求,一般就会采取隐匿的技术,从而很好的保证发布数据的安全性。隐匿是指把匿名表中的数据直接删除,采取这样的方式会直接减少匿名表中的数据,但是在某些情况可以减少需要进行泛化数据的数量,减少泛化的数据损失,达到相对比较好的匿名效果[7]。
泛化指用一个不明确的、更一般的,但是忠实于原值的值来代替原值。泛化可分为两种:值泛化和域泛化。
域泛化是指将一个给定的属性域泛化成一般域。如属性ZIP原始域Z0={100870,100871,100876,100875,101230,101231,101231}被泛化成 Z1={10087*,1012*},以便在语义上表达一个较大的范围。经过连续多次泛化形成的域泛化层次结构称之为域泛化层,记为DGHA。

值泛化是指原始属性域中的每个值直接泛化成一般域中的惟一值,如图1所示。值泛化关系同样决定了值泛化层的存在,记为VGHA。
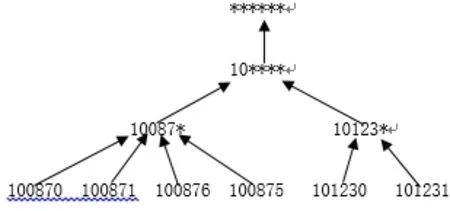
图1 Z ip的值泛化图Fig.1 The generalization of Zip
2.2 多维属性泛化K-匿名的基本实现
当前K-匿名的主要实现方式是泛化和隐匿,泛化的基本思想是用更一般的值或者模糊的值取代原始属性值,但语义上与原始值保持一致。目前在k-匿名中常用datafly算法来实现泛化。但在进行泛化之前,对于要进行匿名化的数据表先进行预处理,具体步骤如下。
(1)数据持有者标明待发布数据表中可用于发布的属性和元组;
(2)数据持有者对待发布数据表中的属性按照上述的类别划分标识符、准标识符等。
(3)数据持有者根据需求为待发布数据表指定一个K值。
(4)对表格进行删除含有空值和非法值的元组等一系列工作。
(5)生成每个准标示符组别中的属性的泛化树。
待发布数据表经过上述一系列的预处理之后,K-匿名模型便进入了算法的核心部分:泛化和隐匿,在此我们选取了最为经典的 Datafly算法进行泛化处理。首先,对该数据表进行K-匿名检测,若该表满足K-匿名则直接输出,如不满足则对该表数据采取以下操作。
(1)统计各准标识符属性的取值个数即对准表示属性值域的大小统计。
(2)选取出统计值中最大的准标识符属性进行一个层级的泛化。
(3)系统对泛化后的表格进行 K-匿名检测。如果泛化后的数据表符合K-匿名检测,那么此表将作为输出结果被系统输出;如果此表格没能符合K-匿名检测,系统将继续对前面所选取的准标识符属性进行泛化和K-匿名满足性的检验,直到该表满足K-匿名模型为止。
(4)最后,经泛化后满足 K-匿名检验的数据表将会以输出结果的形式被输出。
至此输出的数据表就是经过处理后满足 K-匿名的结果,但根据上述的操作流程不难看出,该方法存在一个比较大的问题,在被泛化属性的选取方面太过单一,在整个泛化过程中,被泛化的准标识符属性始终为最初数据表中取值最多的那个,但随着泛化的进行,几轮泛化之后该属性很有可能已经不再是当前表中取值最多的那个准标识符属性,若继续对该属性进行泛化使得该数据表难以尽快满足K-匿名,同时很容易造成过度泛化降低泛化后的数据表的可用性。
因此,目前最常见的还是基于多维属性泛化的K-匿名,即为了避免被泛化的准标识符属性的选取过于单一,将泛化属性的选取融入到K-匿名的循环检验当中。在泛化属性的选取上,基于多属性泛化的 K-匿名算法不仅只在泛化起始时对被泛化属性进行挑选,而是在每次泛化和K-匿名检验后,系统都会重新选取被泛化的准标识符属性,这样就可以减少数据表在匿名处理的过程中被过度泛化,提高了泛化后数据的可用性。
3 多维属性泛化K-匿名的改进与实现
3.1 对K-匿名的改进
因在上述K-匿名的实现过程中,我们不难发现,这一算法在进行匿名化的过程中存在以下不足:缺乏对取值最多的属性不唯一的考虑。为了解决这个问题,当前常用的有以下两种方法。一种是随机选取,即在取值最多的属性之中随机选取出一个准标识符属性作为被泛化的属性,另一种是使用熵的方式来选取被泛化的准标识符属性。不过,这两种方式都有其一定的局限性。其中,随机选取的方式易造成数据表的过度泛化,基于熵的选取方式计算量太大且需要有专业人员对各准标识符属性进行评估,操作起来十分耗时。
针对上述问题,本文改进了多维属性泛化的K-匿名算法,在泛化属性的选取等方面进行了相应的改进,引入了近似度分析。无论是经典的Datafly算法还是多维属性泛化的K-匿名算法,在选取被泛化的准标识符属性这一环节,如果数据表包含大量的准标识符属性,很容易出现取值最多的准标识符属性不止一个的情况,这种情况下如果不做进一步处理,系统一般都会默认为随机选取。不过,为了使数据表尽早的满足 K-匿名且考虑到数据发布环节中可能存在的背景知识攻击,这里引入了近似度的概念。准标识符属性的近似度即一准标识符属性中所包含的值之间的离散程度, 近似度越低,属性取值分布的越均匀,K-匿名越容易提早完成;反之,近似度越髙,属性分布的越分散,K-匿名越不好达成,遭到背景知识攻击等威胁的几率也会相应增加。而各属性的近似度可以通过求解各属性的标准差来进行衡量,具体的计算步骤如下所示:
(1)统计给定表中准标识符属性各值在表中的出现频次;
(2)求出该准标识符属性各取值的出现概率和该属性取值的平均概率;
(3)求出该准标识符属性的方差和标准差;
(4)对所得方差开平方,所得的标准差即为该准标识符属性的近似度。
除此之外,为了满足不同的需求,在数据预处理阶段,构建泛化树是增加泛化层的限制,。根据上述K-匿名的概念以及实现原理,不难看出,通过对不同的准标识符属性进行不同层级的泛化,满足K-匿名要求的处理后的数据表可以有多种,但根据第三方对于数据的要求,不同的处理结果数据的可用性也不尽相同。例如对常见的医疗信息进行匿名处理,若第三方要分析某种疾病与年龄之间存在的联系,若处理后的数据表将年龄泛化到了非常模糊的层级,而保留了相对准确一些的地域属性,那么输出的结果其实并不能满足该统计的需求。
因此,在进行匿名处理的过程中,根据第三方不同的需求,对于处理后的数据也有着不同程度的要求,对于这一问题,我们可以通过约束各准标识符属性的泛化层次以保证匿名泛化表能够满足特定数据分析任务对匿名泛化表数据质量的要求,主要就是在数据预处理阶段,生成各个准标识符属性的泛化树之后,根据数据需求对每一颗泛化树做出泛化层的限制,调整泛化树。如上述例子中可以要求年龄最高只能泛化到10代、20代等10岁唯一值域区间的层级,而对地域不加以限制,从而提高处理后的数据的可用性。
3.2 基于多维属性泛化的K-匿名的实现
通过上述对多维属性泛化K-匿名的改进策略,得到了改进后的基于多维属性泛化的K-匿名,具体实现如图2所示。
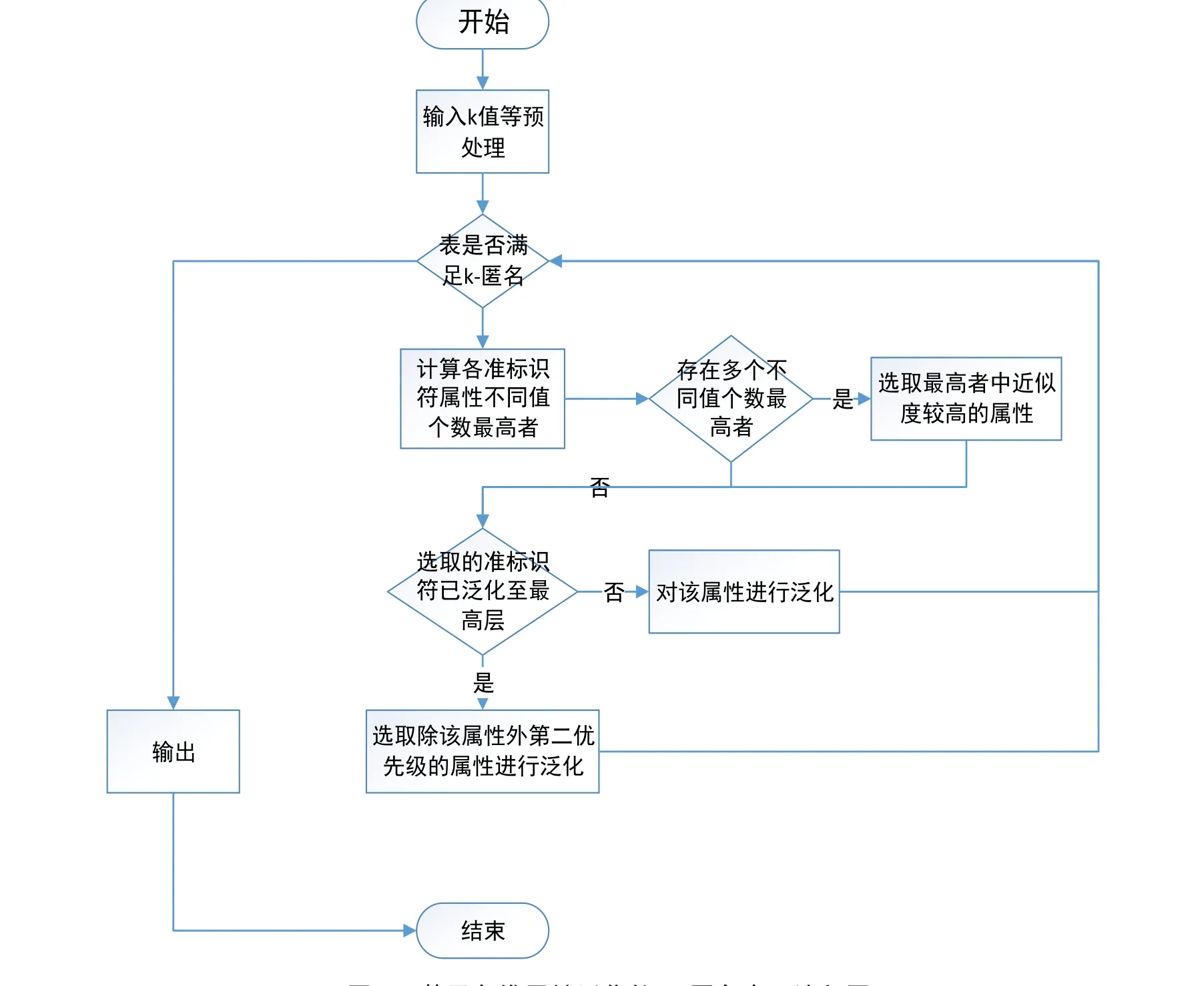
图2 基于多维属性泛化的K-匿名实现流程图Fig.2 Flow chart of K- anonymous implementation based on multidimensional attribute generalization
首先,在输入方面,我们需要给定一个数据表PT,一个准标识符属性集合、一个泛化层度K、各准标识符属性的泛化层次限制以及各准标识符属性的域泛化层次树。此外,我们还需保证给定表 PT中的元组个数是大于等于给定的泛化层度K。
接下来,我们要对给定的数据表PT进行K-匿名检验,即计算表中每个等价组中所包含的元组数,检测该表中是否存在元组个数小于K的等价组。其中,如果给定的数据表PT无小于K个元组的等价组,即表格满足K-匿名。那么系统会直接将给定的表格输出。如果给定的数据表没能通过 K-匿名检验,那么系统会对其采取以下操作:
(1)对各准标示符属性的取值个数进行统计即对准标识符属性值域大小进行统计。
(2)选取出统计值中最大的准标识符属性,若值不唯一,对这几个准标识符进行近似度分析计算,对近似度值较高的准标识符进行泛化。
(3)判断选取出的值中最大的准标识符属性当前是否已经泛化到最高层,若没有泛化到最高层,则对该属性进行的泛化,若已泛化到最高层则选取次优先级的属性进行泛化。
(4)系统对泛化后的表格进行K-匿名检测。如果泛化后的数据表符合K-匿名检测,那么此表将作为输出结果被系统输出;如果此表格没能符合K-匿名检测,系统将继续对前面所选取的准标识符属性进行泛化和 K-匿名满足性的检验,直到该表满足K-匿名模型为止。
(5)最后,经泛化后满足K-匿名检验的数据表将会以输出结果的形式被输出。
4 实验结果分析
在前面对于K-匿名的论述中可以看到,在数据发布环节使用 K-匿名对数据进行匿名处理的目的就是既能保护用户的敏感信息不被泄露,又能保证处理后的数据的可用性。因此在对K-匿名进行评价时,我们习惯采用处理后的数据精度作为衡量的标准,泛化后数据精度的度量也可以说是对于泛化后数据相较于原数据的损失程度的度量。当前较为常用度量方式有三种,他们分别是基于泛化层级的精度度量标准、基于惩罚值的数据辨识度度量标准以及基于熵的度量标准。
本文所采用的度量标准是Precision度量公式:

由K-匿名模型的创始人之一Sweeney L提出并命名,其中,Hi表示准标示符属i的泛化层级树的高度,h表示准标示符属性 i所泛化到的层级,Na表示准表示符属性的数目。这一度量标准是通过对比泛化后数据表和初始数据表中各准标示符属性的泛化层次来计算泛化后数据的信息损失程度。
本实验选用了Adult数据集中的Adult.test文本文件作为数据样本,分别对基于原始datafly算法的K-匿名以及引入近似度分析、泛化层次限制的改进后的基于多属性泛化的K-匿名进行了实验,使用上述Precision度量公式,计算随着选取K值的不同,分别使用这两种方法处理后的的数据精度,实验结果如图3所示。

图3 实验结果图Fig.3 Experimental result chart
可以看到,这两种方法随着K值的增大,处理后数据的数据精度逐渐变低,此外相较于基于datafly的K-匿名,改进后的基于多维属性泛化的K-匿名在数据精度方面也有了一定的提高,从而在达到对用户进行隐私保护目的的同时,提高了处理后数据表的可用性,验证了本文提出的改进的有效性。
[1] 王平水, 王建东. 匿名化隐私保护技术综述[J]. 小型微型计算机系, 2011(02).
[2] 岑婷婷, 韩建民, 王基一, 李细雨. 隐私保护中K-匿名模型的综述[J]. 计算机工程与应用. 2008(04).
[3] 李晖, 牛犇, 李维皓.移动互联网服务中的隐私保护机制[J].中兴通讯技术. 2015(03).
[4] 张雪松, 徐勇. K-匿名隐私保护相关技术的研究[J]. 电子世界. 2012(05).
[5] 朱玉, 赵桐, 王珊. 面向查询服务的数据隐私保护算法[J].计算机学报. 2010(08).
[6] 王波, 杨静. 数据发布中的个性化隐私匿名技术研究[J].计算机科学. 2012(04).
[7] 何贤芒. 隐私保护中K-匿名算法和匿名技术研究[D]. 复旦大学 2011.
[8] 宋金玲. K-匿名隐私保护模型中与匿名数据相关的关键问题研究[D]. 燕山大学 2012.
[9] 任向民. 基于K-匿名的隐私保护方法研究[D]. 哈尔滨工程大学, 2012.
[10] 刘坚. K-匿名隐私保护问题的研究[D]. 东华大学, 2010.
[11] Zakerzadeh H, Aggarwal C C, Barker K. Privacy-preserving big data publishing[C]// International Conference on Scientific and Statistical Database Management. ACM, 2015: 26.
[12] M. Xue, P. Karras, C. Ra_ssi, J. Vaidya, and K.-L.Tan,Anonymizing set-valued data by nonreciprocal recoding,"KDD, 2012.
[13] M. E. Nergiz, M. Atzori, and C. Clifton, Hiding the presence of individuals from shared databases," SIGMOD, 2007.
Research on K-anonymous Privacy Protection Technology in the Data Release
YUE Si, WU Wei-ming, GU Yong-hao
(1. School of Computer Science, Beijing University of Post and Telecommunications, Beijing Key Laboratory of intelligent communication software and multimedia ,Beijing 100876, China; 2. National Power Grid Corp information and communication branch, Beijing 100761, China)
With the rapid development of Internet technology, individuals and institutions are increasingly concerned about the issue of privacy protection. With the application of data mining technology, privacy leakage is becoming more and more serious. Privacy protection is one of the hot topics in the research of privacy leakage control technology in Data Publishing, and K- anonymous is the hotspot of privacy protection research in recent years. This paper introduces the basic concept of K- anonymous, expounds the generalization and hidden technology, introduces the multidimensional attribute generalization K- anonymous model based on Datafly, and the basic principle and the disadvantages of the model are analyzed. In addition, the corresponding improvement is made, the generalization layer is limited in the data preprocessing stage, and the approximation analysis is introduced in the selection of the identifier attribute, and the improved K- anonymity experiment is carried out. The experimental results show that the improved method effectively improves the accuracy of the processed data.
Data release; Privacy protection; K-Anonymous; Generalization and Concealment; Datafly
TP309
A
10.3969/j.issn.1003-6970.2017.11.002
本文著录格式:岳思,吴伟明,谷勇浩. 数据发布中k-匿名隐私保护技术研究[J]. 软件,2017,38(11):12-17
国家自然科学基金项目资助(61173017,61370195);工信部通信软科学项目资助(2014-R-42,2015-R-29);国网科技项目(SGTYHT/15-JS-191)
岳思(1994-),女,研究生,移动互联网。
吴伟明,教授,主要研究方向:现代网络通信。
