基于相似度的多类别不完整云计算网络的聚类填充算法设计
2017-11-30周向军
周向军
(广东省外语艺术职业学院 信息学院,广东 广州 510640)
基于相似度的多类别不完整云计算网络的聚类填充算法设计
周向军
(广东省外语艺术职业学院 信息学院,广东 广州 510640)
传统基于概率分布的不完整数据聚类填充算法,未综合分析数据对象的类别属性,数据填充效率和精度较低。因此,本文提出一种新的聚类填充算法,利用近邻传播(AP)算法聚类不完整数据,采用元祖相似度算法对不同类别的不完整数据实施填充。通过数据挖掘方法获取多类别不完整云计算网络系统中的加权关联规则,实施常规缺失数据的填充,采用数据推荐筛选方案实施元组相似度运算,完成异常缺失数据的填充,最终获取完整的云计算网络数据集,提高云计算网络数据的有效利用率。实验表明,本文设计的聚类填充算法具有较高的填充效率和精度。
云计算网络;相似度聚类;元祖相似度算;加权关联规则
随着云计算网络应用价值的逐渐提升,云计算网络数据的数据缺失问题成为重点研究方向。不完整数据使云计算网络终端运行异常产生,容易引起采集数据全部或部分属性值缺失,大大降低了云计算网络的数据融合以及数据挖掘的效率和精度,削弱云计算网络的应用价值[1]。传统的基于概率分布的不完整数据聚类填充算法,采用总体数据集填充的方式处理不完整数据,没有综合分析数据对象的类别属性,使得数据填充效率和精度较低。相关学者已取得一些研究成果。赵亮等[2]提出一种基于分布式减法聚类的不完整数据填充算法,利用改进的减法聚类算法对整个数据集进行聚类,并结合云计算技术对聚类算法进行优化,该方法填充处理时间消耗较少,但聚类精度较差。李翠霞等[3]提出基于马氏距离的文本聚类算法。该算法在不需要先验知识的情况下,仅通过数学迭代即可得到聚类结果,具有较高的聚类精度,但计算时间较长。为了解决以上问题,本文提出基于相似度的多类别不完整云计算网络的聚类填充算法设计,从多类别不完整云计算网络数据集中分析数据缺失类型,采用加权关联规则完成常规型数据缺失的数据填充,采用基于元祖相似度的数据推荐筛选算法完成异常型缺失的数据填充,最终获取完整的云计算网络数据集。
1 聚类填充算法
1.1 基于AP的不完整数据聚类算法
近邻传播(Affinity propagation,AP)聚类算法中数据间的距离可采用任意度量方法。本文先采用AP聚类算法对多类别不完整云计算网络数据实施聚类,相同的簇里接收同一类数据,根据对应原则补充缺失数据,这样可成功屏蔽其他对象对填充值的不利影响,使填充值的精确性得到保障。
AP聚类算法是一种在数据点之间传递吸引度和归属度的算法。吸引度表示其它节点向中心节点的聚拢程度,节点k对节点i的吸引度是r(i,k),节点i向节点k聚拢,节点k是节点i的聚拢中心目标。归属度表示节点将其它节点作为中心节点的可能性。节点i相对于对另一节点k的归属度是a(i,k),节点k有向节点i靠近的趋势,则节点i可确定为另一节点k的中心目标。
为了不断提升聚类中心的精确度,AP聚类算法采用连续刷新吸引度矩阵R=[r(i,k)]和归属度矩阵A=[a(i,k)]完成AP聚类算法,吸引度矩阵R的刷新依据归属矩阵以及相似度矩阵的变化,用公式表示为
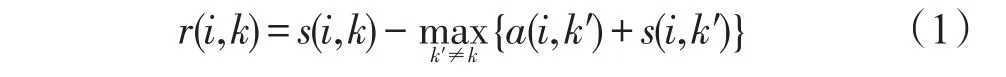
矩阵A的刷新依据吸引度矩阵可表示为

式中:点i与点k的相似度为s(i,k);点i对点k的吸引度是r(i,k);点i对点k的归属度是a(i,k)。如果i=k,则输入的偏向参数 p(k)设定s(k,k),随着p(k)增大,点k成为聚拢中心目标的可能性就越大且聚类个数增多[4];相反,聚类个数随着 p(k)的减小而减少。
多类别不完整云计算网络数据聚类,是在AP算法基础上完成的,具体过程为:
(1)设置多类别不完整云计算网络的数据集O由完整数据集C以及非完整数据集I构成。
(2)统一收集对完整数据集C中数据进行属性值的离散处理得到的数值。
(3)对数据集C的所有数据对象进行相似度矩阵S的求解。
(4)在式(1)和式(2)的基础上刷新吸引度R和归属度矩阵A,并将吸引度矩阵R以及归属度矩阵A设定为初始状态。
(5)当完成刷新后聚类中心处于稳定状态,终止运算[5],以免重复运算。
(6)当对角线值a(k,k)+r(k,k)>0时,数据点k会自发向聚类中心靠拢,而a(i,k)+r(i,k)成为数据点i归属聚类中心的可能性最大。
(7)当数据集C中数值属性处于不间断状态时,相似度的度量系数α与β可在其对应的簇中运算求得。
(8)如果将相似度最高的簇中心选为聚拢中心,也就是式(6)中求出的每个对应簇中数据的相似度,则需要将非完整数据集I的全部数据分配到相应的簇中。
采用AP聚类算法对云计算网络中的数据实施聚类后,对云计算网络数据不完整数据类别进行分类,也就是对数据缺失类别实施分类[6]。根据数据是否存在相关性,划分成常规缺失类别和异常缺失类别。采用加权关联规则可完成常规缺失类别数据的填充。
1.2 数据缺失类别判断
本文将云计算网络数据集内不含缺失值以及含有缺失值的变量(属性),分别当成完整变量以及非完整变量[7]。
设置A=(Aij)用于描述总体云计算网络数据,M=(Mij)用于描述缺失模型,Mij用于描述相关的Aij是否缺失,依据A的M条件分布描述数据缺失模型[8],则有 f(M|A,ϕ),ϕ 用于描述缺失值,A 中的完整变量和非完整变量分别是Aobs以及Amis。数据缺失类别有:
(1)常规缺失。若某数据的缺失同其它完整属性值存在一定的关联性,采用完整属性能够完成缺失值的预测,则该种缺失为常规性数据缺失,则有
(2)异常缺失。若某数据的缺失同其它属性间不存在关联性,无法通过完整属性预测缺失值,该种缺失则为异常型数据缺失,则有
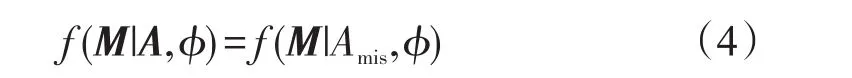
1.3 加权关联规则设计
关联规则的挖掘可塑造数据属性间的关联,基于关联规则可得到数据集缺失的数据属性值。本文基于用户对项目的感兴趣度不同[9-10],设置不同项目具有不同的权重,进而增强规则的价值度和填充的精度。
用二维表S描述云计算网络的关系数据集D,而含有缺失值的二维表S′用表1描述。
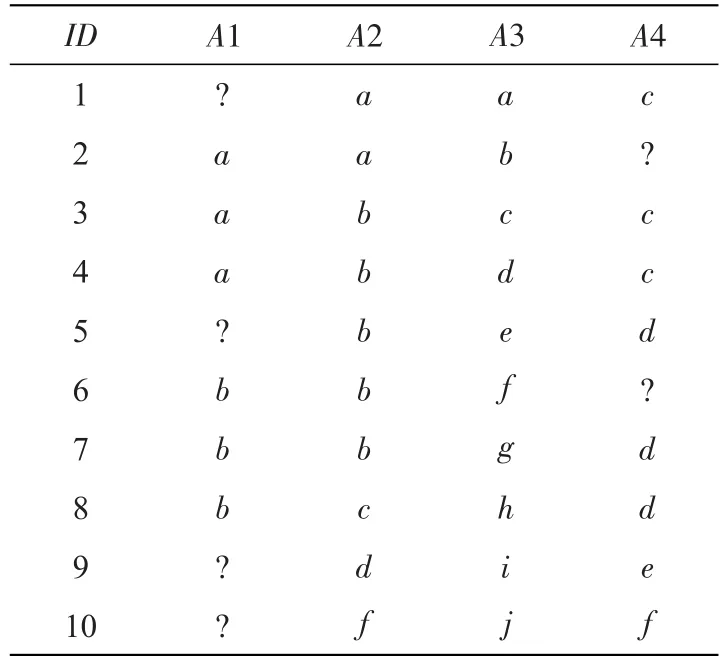
表1 不完整数据表S′Tab.1 Incomplete data tableS′
表1中的行称为元组(记录),列称为属性,行用于描述各列属性的可能取值。表S′中的“?”表示属性存在的缺失值。一个属性值称为一个项目,D内全部项目集称为全总项目集,用I={i1,i2,…,ik}描述。各项都是I的一个子集,则表1中的I可表示成:I={A1=a,A1=b,A1=c,A1=d,A2=a,A2=b,A2=c,A2=d,A2=f,A3=a,…,A3=j,A4=c,A4=d,A4=e,A4=f。W={ω1,ω2,…,ωk}是 I的权重集,ωj用于描述项目的权重,同时存在0≤ωj≤1,j={1,2,…,k}。设置 X={x1,x2,…,xp},Y={y1,y2,…,yq}是I的子集,同时存在X∩Y=∅,数据集D内项目集X的支持率以及置信度分别是Support(X)以及Confidence(X)。
设置项集加权的支持度是

加权关联规则X⇒Y的支持度是

加权关联规则的可信度是

将同时符合最小加权支持度以及最小加权可信度的条件作为加权关联规则。
1.4 加权关联规则的数据填充算法
设置表2中的用户检索规范是A1=a,用三个不同的表存放A1=a、A1=?以及剩余元组,在存放A1=a以及剩余元组的标准中实施关联规则检索[11],产生原始规则集,过滤掉规则集中的矛盾规则后,获取无歧义规则集,在无歧义规则集中填充缺失值,则获取A1的完整元组,实现数据的填充。
其中产生原始规则集后,挖掘出的规则为A2=b⇒A1=a以及 A2=b⇒A1=b,在 A2=b的情况下,A1需要对哪个值实施填充,应通过加权关联规则完成精确填充[12-13]。依据相关项目频率大小设置权值,A1=a,A1=b,A2=a,A2=b,A4=c项目权重分别是0.6、0.3、0.1、0.2以及 0.3。基于式(6)和(7)运算出加权置信度,进而判断 A2=b⇒A1=a哪条规则优先等级更高,则用该规则填充缺失值,并融入无歧义规则集中,最终获取完整元组,实现数据填充。
1.5 基于元组相似度的异常缺失数据填充算法
本文采用上小节分析的基于加权关联规则填充常规型缺失类别数据;采用数据推荐方案运算元组相似度,完成异常缺失类别数据的填充。
1.5.1 元组相似度的运算 相似矩阵是基于元组相似度运算组建的,依据目标元组集合确定相似元组,也就是与目标元组有同类项,但可能出现缺失值[14]。本文分别从确定相似元祖以及相似矩阵的运算两方面对目标元组的缺失值实施填充。
采用余弦相似度计算法求得两个元组的相似度。用N(u)以及N(v)分别表示记录u和v全部的非空项集,则u和v的余弦相似度运算式
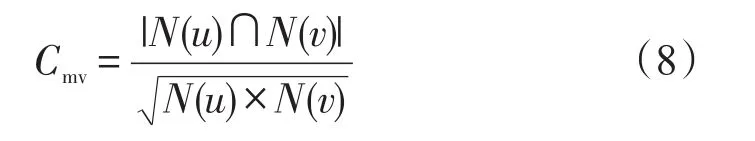
其中A1是填补表1中ID9属性值,在总数据表中确定ID9的同类项元组,基于该元组塑造项目元组顺序表,用表2描述。

表2 项目-元组的排列表Tab.2 List of items tuples
基于表2塑造一个4×4的矩阵,用式(9)描述,该矩阵的主对角线用于描述元组的关联[15],本文设置其值是0。如果元组中存在同类项,则每两项间增加1。以 A2=d为例,在元组中存在ID9、ID12、ID14,在矩阵中每两项增加1,则有

根据式(9)得到相似矩阵,式(9)形成的初始矩阵是式(8)的分支,再实施下一步的运算得到相似矩阵为

分析式(10)可得,ID12是与ID9最相似的元组,如果ID12中没有A1属性值,则再查看ID14的属性值。
1.5.2 异常缺失数据填充算法过程 基于元组相似度的数据填补方法的关键是建立相似矩阵,如算法1所示。
算法1 ArrayGen HinlcaRoq
Input:不完整数据集D
Output:完整数据集 D′
第一步:设置排列表S为项目元组
设置数组A为同类项组
For various Characteristics in D
If Characteristics not zero
For various Array benchmark
If Array.Characteristics==Characteristics Array ID->A,A->S
第二步:初始化矩阵
设置矩阵M为空项状态
For various Characteristics in S
If Id in S M[x][y]++
第三步:得到相似矩阵
For various engineer in D
For various engineer in M
//T(ID(x))T(ID(y))非缺失属性个数
M[x][y]=M[x][y]/T(ID(x))×T(ID(y))
第四步:补充缺失值
For various engineer in M
If M[x][y] is max and engineer.Characteristicsnot zero D Characteristics=engineer.Characteristics
2 实验分析
将某云计算网络数字图书馆采集的数据集当成实验数据集[16]。实验数据集的数据对象是个,各数据对象拥有30个属性。
2.1 基于AP的不完整数据聚类性能分析
通过聚类精度评估聚类效果,聚类精度为
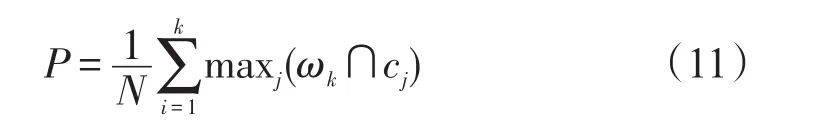
式中:ωk用于描述聚类后的第k个集;cj用于描述数据实际分类后的第 j个集。
(1)任意从原始数据集P内采集不同比例的数据对象,将这些数据中的局部属性值去掉,获取不完整数据集O和相对不完整数据C,结合得到的数据集,考察数据缺失率对AP算法精度的影响,如图1描述。

图1 不同数据缺失率下的数据聚类精度对比Fig.1 Comparison of data clustering accuracy under different data loss rates
分析图1可得,AP聚类算法对相同原始数据集P实施多次聚类,结果一致,精度始终为85%。对C实施聚类过程中,呈现波动变化,平均聚类精度也都在80%以上。对不完整数据集O实施聚类过程中,精确度下降明显。主要是因为,在数据不存在缺失的情况下,数据P完成较高水平聚类,不存在波动。对不完整数据进行聚类过程中,由于抽取过程呈现周期性,因此,得到的结果也成周期性波动,与事实符合,一旦存在较大程度缺失,会呈现明显的下降趋势。
(2)从原始数据集内采集不同数量的数据对象组成7个数据集,从这些数据集内任意采集8%的数据对象,将数据中的局部属性去掉,获取7个不完整数据集O和5个不完整数据C,获取不同数据量下AP的聚类精度,用图2描述。
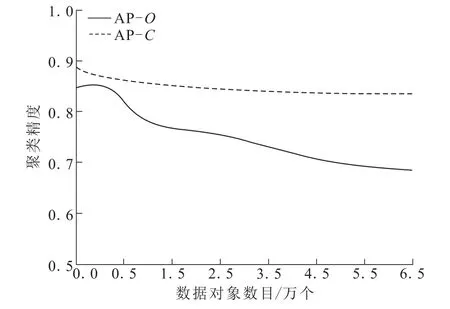
图2 不同数据对象量下的聚类精度对比Fig.2 Comparison of clustering accuracy under different data objects
分析图2可得,随着数据量逐渐提升,对C实施聚类的精度略微降低,但整体聚类精度高于83%,是一种精度较高的聚类算法。AP聚类算法对O的聚类精度比C低,但是也在50%以上,在严重缺少局部可识别的属性下,聚类也能满足一定的精度。说明在相似度的判断下,缺少的局部数据属性可以得到较好的补充,弥补了在属性缺失情况下,造成的聚类中心选取弊端。
2.2 算法软指标试验结果分析
检测本文算法在不同环境下的运行结果如图3所示。数据量不断增加情况下,本文算法在两种环境下的运行时间都不断增加。并且在单节点的运行时间随着数据呈现指数级提升,在云计算网络平台的运行时间远远低于单节点运行时间,在数据对象数目达到6.5万个时,算法的聚类时间仍小于0.7 h。说明本文算法在处理云计算网络中的大数据具有较高的效率。

图3 算法并行执行时间Fig.3 Parallel algorithm running time
利用符合指数d2分析本文算法的数据填充精度。d2可检测实际值同估测值间的相似度
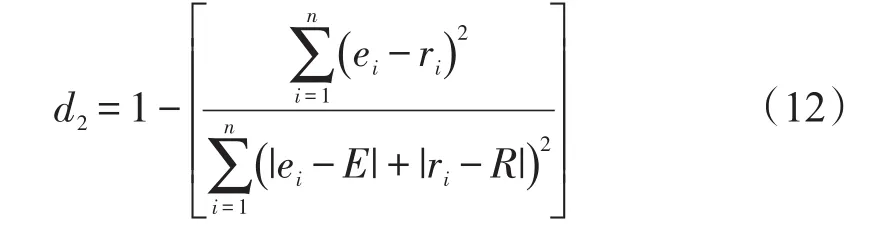
式中:n用于描述全部缺失值;ri用于描述第i行缺失值的实际值;ei用于描述第i行缺失值的预测值;R用于描述实际值的均值;E用于描述预测值ei(i=1,2,…,N)的均值。d2值越高,预测值同实际值越一致。
从原始数据集P内任意采集不同缺失比例的数据,将这些数据中的局部属性值去掉,得到不完整数据集O。实验对比分析本文算法、分布式减法聚类算法以及广义马氏聚类算法,在不同缺失率情况下的数据填充精度,结果用图4描述。
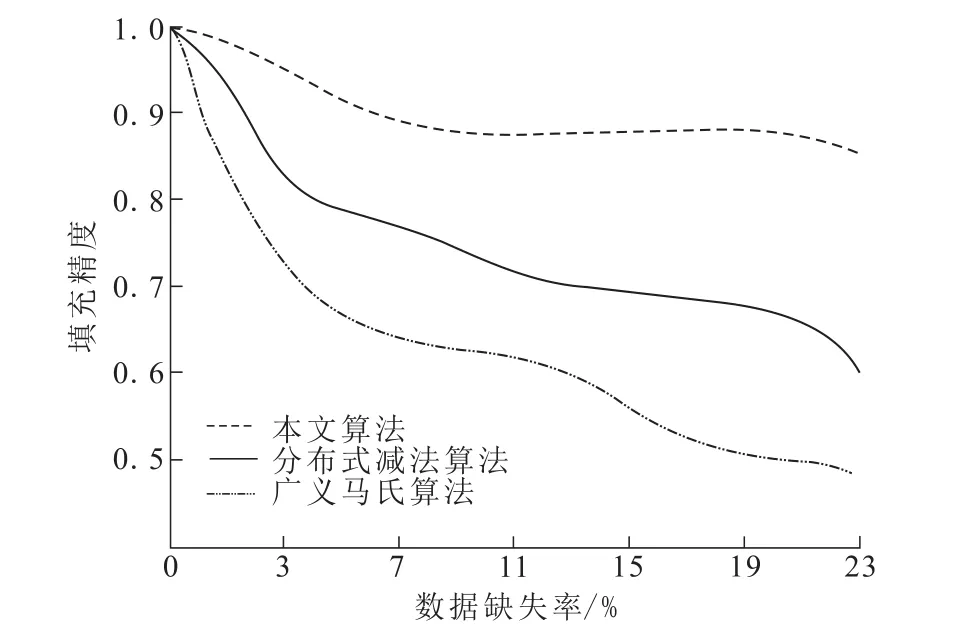
图4 算法在不同缺失率下的填充精度对比Fig.4 Comparison of filling accuracy at different loss rates
分析图4可得,随着数据缺失率不断增加,三种算法的数据填充精度均降低,本文算法始终保持较高的填充精度,在数据缺失率大于15%后,随着缺失数据量的增加,其他两种方法的填充精度出现了大幅度下降,但是本文算法始终保持平稳,对缺失率较高的数据集仍然具有较好的填充精度。
从原始数据集内采集不同数量的数据,获取不同数量的数据集。从这些数据集内任意采集9.5%的数据对象,将其局部属性去掉,得到7个不完整数据集O。分别采用三种算法对不同的数据集O进行聚类填充,结果如图5。随着数据量的不断增加,三种算法的填充精度也不断降低。当数据量高于5.5万个,则随着数据量的逐渐提升,分布式减法聚类算法和广义马氏聚类算法的填充精度呈现显著降低趋势,而本文算法的填充精度始终高于82%,说明本文算法填充云计算网络中的大规模数据,具有较高的优势。
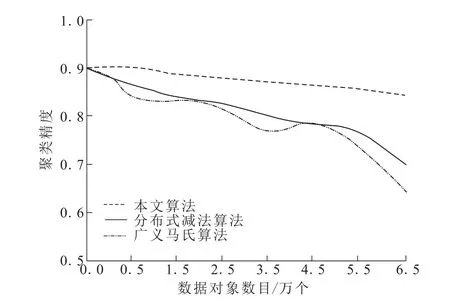
图5 不同算法在不同数据对象数量下的填充精度对比Fig.5 Comparison of filling accuracy of different algorithms under different number of data objects
3 结论
本文设计基于相似度的多类别不完整云计算网络的聚类填充算法,先采用AP算法对不完整数据实施聚类后,再采用基于元祖相似度的不完整数据填充算法,对不同类别的不完整数据实施填充,实验发现,本文所提算法在数据对象数目由0~6.5万个下,聚类精度始终在85%以上,且在数据对象数目达到6.5万个时,算法的聚类时间仍小于0.7小时,极大提高了云计算网络数据填充的效率和精度。
[1]康英健,马蕾.基于量子群聚类的云存储调度执行开销建模[J].科技通报,2015,31(8):87-89.
[2]赵亮,陈志奎,张清辰.基于分布式减法聚类的不完整数据填充算法[J].小型微型计算机系统,2015,36(7):1409-1414.
[3]李翠霞,谭营军,孔金生.基于马氏距离的文本聚类算法在自动阅卷系统中的应用[J].计算机应用与软件,2015,23(4):80-82.
[4]廉文武,傅凌玲,黄潮.云计算环境下数据弱关联挖掘模型的仿真[J].计算机仿真,2015,32(4):359-362.
[5]ZHANG Q,CHEN Z.A weighted kernel possibilistic cmeans algorithm based on cloud computing for clustering big data[J].International Journal of Communication Systems,2015,27(9):1378-1391.
[6]马华,胡志刚,张红宇,等.云计算环境下可信服务的个性化推荐框架[J].小型微型计算机系统,2014,35(5):967-972.
[7]WANG K,TAN J J,PAN N.Application of improved ant colony algorithm in the network cloud data clustering and intrusion detection[J].Applied Mechanicsamp;Materials,2015,713-715:2431-2434.
[8]樊同科.云环境下基于MapReduce的用户聚类研究与实现[J].电子设计工程,2016,24(10):35-37.
[9]潘少明,李红,汤戈.云计算下的空间统计数据点云聚类压缩算法[J].华中科技大学学报(自然科学版),2014,42(4):64-67.
[10]卫波,王晋东,张恒巍,等.基于加权多属性云的服务信任评估方法[J].计算机应用,2014,34(3):678-682.
[11]ZHANG S M,ZHAO S,WANG B Y.Research of power load curve clustering algorithm based on cloud computing and quantum particle swarm optimization[J].Power System Protectionamp;Control,2014,42(21):93-98.
[12]冷泳林,陈志奎,张清辰,等.不完整大数据的分布式聚类填充算法[J].计算机工程,2015,41(5):19-25.
[13]徐达宇,杨善林,罗贺,等.基于广义模糊软集理论的云计算资源需求组合预测研究[J].中国管理科学,2015,23(5):56-64.
[14]王兴茂,张兴明,吴毅涛,等.基于启发式聚类模型和类别相似度的协同过滤推荐算法[J].电子学报,2016,44(7):1708-1713.
[15]曾志,周永福,杜震洪,等.云环境下基于Entropy-KNN算法的节点选择策略[J].浙江大学学报(理学版),2015,42(3):359-364.
[16]郑伦川.云计算机环境资源配置技术研究[J].现代电子技术,2016,39(7):24-28.
Clustering filling algorithm design based on similar multiple categories and incomplete cloud computing network
ZHOU Xiangjun
(School of Informatics,Guangdong Teachers College of Foreign Language and Arts,Guangzhou 510640,China)
The traditional incomplete data filling algorithm based on probability distribution clustering is not able to be used to comprehensively analyze the objects’data,due to the low filling efficiency and accuracy.Therefore,a kind of cluster filling algorithm was put forward by using affinity propagation(AP)algorithm clustering incomplete data and filling different categories’incomplete data into Yuan Zuxiang algorithm.Computing weighted association rules in network system through the data mining,filled the routine missing data,data recommendation filtering scheme is used to calculate similarity.Then,abnormal missing data is filled and,finally the complete cloud computing data is obtained.Experimental results show that the clustering filling algorithm designed in this paper has higher filling efficiency and accuracy.
cloud computing network;similarity clustering;similarity calculation;weighted association rules
June 29,2017)
TP311
A
1674-1048(2017)04-0298-07
10.13988/j.ustl.2017.04.011
2017-06-29。
广东省外语艺术职业学院科研团队资助基金项目(2014KYTD03)。
周向军(1971—),男,广东汕头人,副教授。
