基于SIFT的说话人唇动识别
2017-11-15马新军吴晨晨仲乾元李园园
马新军,吴晨晨,仲乾元,李园园
(哈尔滨工业大学(深圳) 机电工程与自动化学院,广东 深圳 518055)(*通信作者电子邮箱870715761@qq.com)
基于SIFT的说话人唇动识别
马新军,吴晨晨*,仲乾元,李园园
(哈尔滨工业大学(深圳) 机电工程与自动化学院,广东 深圳 518055)(*通信作者电子邮箱870715761@qq.com)
针对唇部特征提取维度过高以及对尺度空间敏感的问题,提出了一种基于尺度不变特征变换(SIFT)算法作特征提取来进行说话人身份认证的技术。首先,提出了一种简单的视频帧图片规整算法,将不同长度的唇动视频规整到同一的长度,提取出具有代表性的唇动图片;然后,提出一种在SIFT关键点的基础上,进行纹理和运动特征的提取算法,并经过主成分分析(PCA)算法的整合,最终得到具有代表性的唇动特征进行认证;最后,根据所得到的特征,提出了一种简单的分类算法。实验结果显示,和常见的局部二元模式(LBP)特征和方向梯度直方图(HOG)特征相比较,该特征提取算法的错误接受率(FAR)和错误拒绝率(FRR)表现更佳。说明整个说话人唇动特征识别算法是有效的,能够得到较为理想的结果。
唇部特征;尺度不变特征变换;特征提取;说话人识别
0 引言
近年来越来越多的研究表明生物认证技术比传统的身份认证具有更好的安全性与简便性。唇动身份认证原来作为语音认证的辅助信息,现在已经独立出来成为一种新的认证手段,唯一性和准确性都得到了研究的证明[1-2]。唇动身份认证系统主要由四部分组成:在已建立的数据库的基础上,首先对获取的图像进行人脸的定位,进而作唇部定位;然后对得到的图片进行预处理;再进行特征提取;最后根据所得到的特征分类得出结果,即完成整个说话人唇动识别研究。
人脸检测方面Yang等[3]提出了基于马赛克图进行人脸检测的方法。Kouzani等[4]利用人工神经网络分别对人脸的眼睛、鼻子和嘴等器官进行检测。Sirohey[5]通过使用人脸边缘信息和椭圆拟合的方法,从复杂的背景中分割定位出人脸区域。Miao等[6]从输入图像中提取面部器官水平方向的马赛克边缘,将各段边缘的“重心”与“重心”模板进行匹配,再通过灰度和边缘特征进行验证以实现人脸的检测。梁路宏等[7]给出了一种基于多关联模板匹配的人脸检测方法。自Viola和Jones首次将Adaboost算法用于人脸检测以来,由于其性能和速度优势,成为一种主流的人脸检测算法。由于其应用的广泛性和实用性,本文采用Adaboost算法作为人脸定位的算法。
人脸的定位完成后,常见的唇部定位方法主要为对图像灰度投影的峰值进行分析,进而通过颜色空间变换,对唇部区域进行加强,再经过阈值的分割得到所需的唇部区域[8]。本文提出根据人脸各部分的大致比例关系给出一种唇部的粗定位算法,该算法计算简单,同时可以保证唇部边缘的一些运动与纹理特征不会被忽略。
图片的预处理工作,是在前期对图片进行处理,减少噪声、遮挡、光照不均等影响,使得特征提取能够得到更加稳定准确的特征向量。本文在尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)算法[9-11]的基础上,进行算法的改进与调整。由于算法本身已包含高斯去噪功能,并且实验的光照条件变化不大,因此对于图像的预处理算法不作过多的讨论。
完成唇部定位与预处理之后,特征提取是关乎到整个认证系统稳定性与准确率的重要部分。目前的唇部特征提取主要分为三类:1)唇部的纹理特征;2)唇部的几何特征;3)唇部的运动特征。纹理特征方法主要有:经典的PCA算法、推广的核主成分分析算法(Kernel-based Principal Component Analysis, KPCA)、二维主元素分析算法,核心都是提取高维特征空间中的线性鉴别特征,即原始输入空间中的非线性鉴别特征,但PCA存在着面对非线性特质无能为力,以及可能会忽略重要的投影方向等缺点。Ahonen等[12]使用局部二元模式(Local Binary Pattern, LBP)来提取脸部图像的纹理特征,对脸部区域进行分块计算各分块LBP直方图,并将它们连接起来作为表情识别的特征。LBP特征具有较好的光照鲁棒性,但是作为一种静态特征,无法具有代表性地来表征动态的特征。几何特征主要有唇部的长宽高等人工提取的特征,对于唇部的轮廓Kass等[13]在第一届国际视觉会议上提出了Snake模型。关于运动特征:光流法作为常用的运动图像处理方法,利用图像序列中像素在时间域上的变化以及相邻帧图片间的相关性来找到上一帧图片与当前帧的对应关系,从而得到物体的运动信息,但存在着运算量大的问题。Singh等[14]提出三正交平面窗口,唇动的运动特征能够在一个时空体积内进行表征。本文给出了一种在SFIT基础上的特征提取算法,既有运动的表述,又有纹理的描述,同时对于旋转变化具有一定的鲁棒性。
对所提取的特征进行分类的算法目前也有很多研究成果。高斯混合模型(Gaussian Mixture Model, GMM)[15]是唇动识别和认证领域的一种常用的分类算法,算法简单,但在数据较多的情况下分类结果不是很理想;Adaboost和PCA-LDA(Principal Component Analysis and Linear Discriminant Analysis),支持向量机(Support Vector Manhine, SVM)算法在唇动认证中也是较为常用的分类算法;Yang等[16]提出了自调节分类面支持向量机(Self-adjusting Classification-plane SVM, SCSVM)方法,通过学习过完备的稀疏特征,可以在高维特征空间提高特征的线性可分性,大大降低了训练分类器的时间和空间消耗。基于深度学习的特征提取和分类算法是目前最为先进的算法,主流的深度学习模型包括自动编码器、受限波尔兹曼机、深度信念网络、卷积神经网络等。Krizhevsky等[17]通过这种方式,成功将其应用于手写数字识别、语音识别、基于内容检索等领域。本文在之前所得到的唇动特征基础上,提出一种简单的分类算法,既满足了分类的精确性,同时计算量小,实时性较好,在数据库较大时也可以和神经网络的分类算法相结合。
1 帧图片提取
在唇动视频中,录像的帧率一般为30 frame/s,如果直接将视频产生的所有帧图片都作为下一步特征提取的数据库,不仅会有大量的噪声干扰在其中,还会有大量的数据冗余,从而会加大系统的计算量并影响其鲁棒性与运算的实时性,最终降低系统认证的准确率与效率。文献[18]分析了动态时间规整算法(Dynamic Time Warping, DTW),本文给出了一种基于时间序列的动态图片提取算法,在相邻的时间段里找到帧间灰度变化最大的图片作为代表性图片。该算法不仅可以减少计算量,同时可以增强整个系统对于说话人语速变化的鲁棒性。具体实行过程如下。
1)令唇动视频所产生的帧图片的数量为X。
2)如果X的数量小于20,说明说话者说话的时间小于1 s,作为认证而言,说话长度明显过短,提示唇动视频所提供的帧图片数量过少,无法进行认证。
3)如果 20≤X≤60,选取第3张图片作为所提取的第1张帧图片,选取倒数第3张图片作为第12张帧图片。A=⎣(X-10)/10」和B=「(X-10)/10⎤将依次作为选取图片的数量间隔,每一幅帧图片的大小为M*N,在每个间隔中,用式(1)选取所要的帧图片:

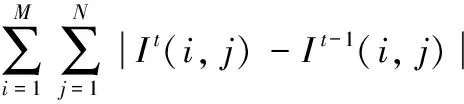
(1)
其中:It(i,j)表示第t帧图片I在点(i,j)处的灰度值;Pic表示在间隔内,和相邻帧图片比较,灰度值变化最大的图片。
4)如果 60 5)如果480 通过上述的算法,可以从唇动视频所产生的大量帧图片中提取12张代表图片。 在被测试者的两段视频帧图片中用上述算法提取的代表图片如下,第一遍段视频用正常语速说“你好”,第二遍张大嘴巴放慢语速复述。 从图1中可以看出在语速和不同口型的情况下,所提取的12张图片其对应的序列及口型都有很强的相似性与代表性。该算法对于说话者语速的变化和口型大小的改变都有很强的鲁棒性,并能够为后面特征的提取打下良好的基础。 图1 视频代表图片 SIFT算法第一次由Lowe[19]提出,是一种广泛应用于图像处理的算法,具有良好的尺度不变性和对旋转的抵抗性。Bakshi等[20]曾将SIFT算法用在唇印的认证与对比中,并取得了很好的效果。 SIFT算法所提出的关键点的描述方式,作为一种局部特征,对于光照、旋转、噪声与尺度的变化都不敏感,因此在这基础上进行物体的认证和识别,都具有很强的抗干扰性和针对性。这种局部特征检测算法概括地讲,就是通过在不同的尺度空间中得到关键点描述子,再对关键点进行匹配的方法,SIFT算法的流程如图2所示。 图2 SIFT算法流程 2.1 基于SIFT的目标匹配与认证 从图3、4中可以看出,经过参数的调整后,SIFT算法所提取的关键点个数明显变多,但是在唇部轮廓变化较大的情况下,误匹配点的个数也有所增加。因此在后面的特征提取中增加了消除重复关键点和PCA降维的步骤。图5展现的是不同人不同尺寸的图片的SIFT匹配结果,可以看到两幅图片的匹配点数明显减少且明显存在匹配错误点。 图3 测试者未经参数调整的SIFT匹配示例图 图4 测试者经参数调整后的SIFT匹配示例图 图5 经参数调整后的不同人唇部图片SIFT匹配示例图 综合实验结果可以看出不同的人的唇部无论出于何种口型,能够匹配的关键点个数远少于同一个人的唇部所能匹配的关键点的个数。因此,将采用测试样本与数据库样本的关键点匹配个数的比值作为判断是否为同一个人的有效依据。 如图6所示,用已提到过的帧图片提取算法将数据库中所存放的同一个人所说同一句话(比如说了3遍)的12幅帧图片一一进行SIFT匹配,共可以匹配3次,将匹配点的个数求平均值得到A1,A2,…,A12,将其存储起来。然后将测试样本与数据库中的任意样本进行SIFT匹配,得到匹配点的个数B1,B2,…,B12。设置阈值θ=0.4,i=1, 2,…,12。如果Bi/Ai<θ,则计数标志flag+1,为了防止系统的误判断并降低噪声图片带来的干扰,设置当flag的值大于2时,判定为不是用户本人。通过调节阈值θ的大小,可以调整错误拒绝率和错误接受率的大小。θ值越大错误接受率越小但错误拒绝率越大,θ值越小错误接受率越大但错误拒绝率越小。 图6 目标匹配原理 2.2 基于SIFT的新的特征提取算法 如图7所示,首先对数据库中的样本(即12幅帧图片)相邻的图片进行SIFT匹配,得到匹配的关键点。提出的特征提取算法就是在这些关键点的基础上得到的。 图7 相邻序列间匹配关键点 具体的特征提取算法如下。 1)对于任意两帧图片之间匹配得到的关键点P1,P2: 用式(2)来计算关键点P1,P2的运动矢量幅值: (2) 其中:(ip1,jp1)为关键点P1的坐标位置;(ip2,jp2)为关键点P2的位置坐标。 用式(3)来计算关键点P1,P2的运动矢量的方向: f2=tan-1[(jp1-jp2)/(ip1-ip2)] (3) 对于每一对匹配的关键点,通过这种方式可以得到二维的特征向量F=(f1,f2)。 2)对于图像中每一个关键点,选取4×4的窗口,如图8所示。图8中每一个小方格代表着一个像素点,圆点代表所得到的关键点的位置,其周围4×4的像素点的运动特征矢量方向由箭头所表示,该矢量幅值的大小表示其矢量的大小。最后将计算所得到16个矢量归类统计到8个主要的方向上去,作为最后得到的8维特征向量。具体的计算方法由式(4)和(5)给出: 梯度幅值: m(x,y)= (4) 其中L(x,y)表示在点(x,y)处的灰度值。 梯度方向: (5) 通过上述的算法,可以得到8维的特征向量R。 图8 关键点周围运动矢量特征图 3) 对于图像中每对匹配的关键点,选取4×4的窗口,对4×4窗口中对应位置的灰度值做差取绝对值,然后将这16个值求和,如图9所示。 即: (6) 其中I1和I2分别代表相邻的两幅帧图片中对应点的灰度值。 图9 对应位置的灰度差绝对值 4)综上所述,对于每一个匹配的关键点,可以得到一个11维的特征向量T={F,R,G}。这11维向量中包含了唇部的运动信息F,唇部周围的纹理信息R,以及灰度的变化信息G。假设最终得到的匹配点个数为n,对最终得到的特征矩阵M采用PCA降维到11维,得到11维特征向量Z。Z特征比LBP等常见的纹理信息具有更强的针对性和规律性,比Snake算法所提取的轮廓特征具有更少的模型依赖性和更强的鲁棒性。 图10所展示的是两名测试者说同一段话所提取的特征矢量的曲线图。灰度变化累计值的值较大,为了能看出其变化趋势,在曲线图中只画出特征F和特征R。 从图10中可以看出,本文所提出的这种特征提取方法能够很好地表征说话人的说话特征,具有很强个人特征以及区别性,可以很容易地进行分类。 2.3 基于所提取特征的分类算法 以往的分类方法,由于得到的图像特征并不明显,因此常用SVM、神经网络、隐马尔可夫模型等算法对其进行分类,这些算法需要较大的数据库来训练,同时运算量大,计算起来十分复杂。根据前面所得到的特征,本文通过简单的比较方法进行二分类,也能得到很好的实验效果。具体的实现方法如下: 1)通过式(7)得到数据库中唇动视频中所提取的唇动特征的平均值: (7) 2)再用相同的方法将测试样本的唇动特征Z提取出来; 3)设置阈值θ1,θ2,其中θ2=1/θ1。θ1的值越大越大错误接受率越小但错误拒绝率越大。本文中θ1取0.7,θ2取1.42。 令t=z/zmean如果t<θ1或者t>θ2,则令计数标志flag+1,为了防止误判断,flag的值大于2时,则判断该用户所说的不是这段话。 图10 不同测试者说同一段话的特征值曲线 2.4 说话者唇部特征识别流程 进行说话者唇部特征识别的流程如图11所示。首先对数据库样本进行人脸定位与唇部定位,然后进行帧图片的选取,对选取的帧图片进行SIFT匹配,在此基础上,提取特征并记录匹配结果。对测试样本采用同样的步骤,最终根据本文提出的验证与分类方法,将输出结果与数据库中的结果比较,得出判定结果。 图11 说话者唇动识别示意图 3.1 数据库的搭建 1) 视频数据库的基本参数如下:视频格式为AVI;颜色空间为YUY2;输出大小为640×480;视频输出帧率为30 frame/s。 2) 视频数据库的搭建如下。 采样人数:50人; 采样环境:正常的日光灯照明,人脸位置相对固定,无遮掩,无大角度旋转,无模糊、胡须,光照角度变化等复杂条件设置;采样过程:接受采样的样本,分别以正常语速重复短句“你好”,以及数字1~9等不同的长短句各4遍,再分别以较慢语速张大口型的情况重复各4遍。 3.2 实验结果 表1展示了本实验在不同唇动视频中获得的Z特征的错误接受率(False Acceptance Rate, FAR)和错误拒绝率(False Rejection Rate, FRR),以及在相同条件下LBP和HOG特征的FAR和FRR值。图12展示本文算法在不同的θ和θ1值时,FAR和FRR值的变化情况。 表1 三种特征得到的FAR和FRR 本文介绍了一种针对动态视频所产生的帧图片的提取算法。这种算法可以增强对于语速变化、口型大小变化以及照明变化的鲁棒性。SIFT算法被引进到了说话者唇动识别中,在参数调整后有很好的表现。在SIFT算法的基础上提出了一种新的唇动特征提取方法,这种方法既包含纹理特征又包含运动特征,可以准确地描述说话人唇动的一系列特征。最后,在匹配点与所提取的特征的基础上,分别提出了一种验证与分类的算法,方法简单,计算量小,与常用的LBP和HOG特征相比较可以得到更为准确和有效的结果,实现说话人的唇部特征识别。在后面的实验中可以添加图像预处理的算法,将多种特征提取方法相结合以及引入神经网络来增强系统的稳定性和适应性。 图12 本文算法不同θ和θ1值时的FAR和FRR曲线 References) [1] KANAK A, ERZIN E, YEMEZ Y, et al. Joint audio-video processing for biometric speaker identification [C]// Proceedings of the 2003 IEEE International Conference on Multimedia and Expo. Washington, DC: IEEE Computer Society, 2003, 3: 561-564. [2] CETINGUL H E, YEMEZ Y, ERZIN E, et al. Discriminative analysis of lip motion features for speaker identification and speech-reading [J]. IEEE Transactions on Image Processing, 2006, 15(10): 2879-2891. [3] YANG G, HUANG T S. Human face detection in complex background [J]. Pattern Recognition, 1994, 27(1): 53-63. [4] KOUZANI A Z, HE F, SAMMUT K. Commonsense knowledge-based face detection [C]// Proceedings of the 1997 IEEE International Conference on Intelligent Engineering Systems. Piscataway, NJ: IEEE, 2002: 215-220. [5] SIROHEY S A. Human face segmentation and identification [EB/OL]. [2017- 01- 09]. https://www.researchgate.net/publication/2698964_Human_Face_Segmentation_and_Identification. [6] MIAO J, YIN B, WANG K, et al. A hierachical multiscale and multiangle system for human face detection in a complex background using gravity-center template [J]. Pattern Recognition, 1999, 32(10): 1237-1248. [7] 梁路宏,艾海舟,何克忠,等.基于多关联模板匹配的人脸检测[J].软件学报,2001,12(1):94-102.(LIANG L H, AI H Z, HE K Z, et al. Face detection based on multi-association template matching [J]. Journal of Software, 2001, 12(1): 94-102.) [8] GRITZMAN A D, RUBIN D M, PANTANOWITZ A, et al. Comparison of colour transforms used in lip segmentation algorithms [J]. Signal, Image and Video Processing, 2015, 9(4): 947-957. [9] NEERU N, KAUR L. Modified SIFT descriptors for face recognition under different emotions [EB/OL]. [2016- 12- 09]. https://www.researchgate.net/publication/294279428_Modified_SIFT_Descriptors_for_Face_Recognition_under_Different_Emotions. [10] KIRCHNER M R. Automatic thresholding of SIFT descriptors [C]// Proceedings of the 2016 IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2016: 291-295. [11] 许佳佳,张叶,张赫.基于改进Harris-SIFT算子的快速图像配准算法[J].电子测量与仪器学报,2015,29(1):48-54.(XU J J, ZHANG Y, ZHANG H. Fast image registration algorithm based on improved Harris-SIFT descriptor [J]. Journal of Electronic Measurement and Instrumentation, 2015, 29(1): 48-54. [12] AHONEN T, HADID A, PIETIKAINEN M. Face recognition with local binary patterns [C]// European Conference on Computer Vision, LNCS 3021. Berlin: Springer, 2004: 469-481. [13] KASS M, WITKIN A, TERZOPOULOS D. Snakes: active contour model [EB/OL]. [2016- 12- 06]. http://webdocs.cs.ualberta.ca/~nray1/CMPUT617/Snake/kass_snake.pdf. [14] SINGH P, LAXMI V, GAUR M S. Speaker identification using optimal lip biometrics [C]// Proceedings of the 2012 5th IAPR International Conference on Biometrics. Piscataway, NJ: IEEE, 2012: 472-477. [15] SAEED U. Person identification using behavioral features from lip motion [C]// IEEE International Conference on Automatic Face & Gesture Recognition & Workshops. Piscataway, NJ: IEEE, 2011: 155-160. [16] YANG J, YU K, GONG Y, et al. Linear spatial pyramid matching using sparse coding for image classification [C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 1794-1801. [17] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [EB/OL]. [2016- 11- 27]. http://www.cs.toronto.edu/~hinton/absps/imagenet.pdf?WT.mc_id=Blog_MachLearn_General_DI. [18] 杨洁,康宁.动态时间规整DTW算法的研究[J].科技与创新,2016(4):11-12.(YANG J, KANG N. Research on dynamic time regular DTW algorithm [J]. Science and Technology & Innovation, 2016(4): 11-12.) [19] LOWE D G. Distinctive image features from scale-invarient keypoints [J]. International Journal of Computer Vision, 2004, 60(2): 91-110. [20] BAKSHI S, RAMAN R, SA P K. Lip pattern recognition based on local feature extraction [C]// Proceedings of the 2011 Annual IEEE India Conference. Piscataway, NJ: IEEE, 2012: 1-4. LipmotionrecognitionofspeakerbasedonSIFT MA Xinjun, WU Chenchen*, ZHONG Qianyuan, LI Yuanyuan (CollegeofMechanicalEngineeringandAutomation,HarbinInstituteofTechnology(Shenzhen),ShenzhenGuangdong518055,China) Aiming at the problem that the lip feature dimension is too high and sensitive to the scale space, a technique based on the Scale-Invariant Feature Transform (SIFT) algorithm was proposed to carry out the speaker authentication. Firstly, a simple video frame image neat algorithm was proposed to adjust the length of the lip video to the same length, and the representative lip motion pictures were extracted. Then, a new algorithm based on key points of SIFT was proposed to extract the texture and motion features. After the integration of Principal Component Analysis (PCA) algorithm, the typical lip motion features were obtained for authentication. Finally, a simple classification algorithm was presented according to the obtained features. The experimental results show that compared to the common Local Binary Pattern (LBP) feature and the Histogram of Oriental Gradient (HOG) feature, the False Acceptance Rate (FAR) and False Rejection Rate (FRR) of the proposed feature extraction algorithm are better, which proves that the whole speaker lip motion recognition algorithm is effective and can get the ideal results. lip feature; Scale-Invariant Feature Transform (SIFT); feature extraction; speaker authentication 2017- 03- 09; 2017- 05- 24。 国家自然科学基金资助项目(51677035);深圳市基础研究项目(JCYJ20150513151706580);深圳市科技计划项目(GRCK2016082611021550)。 马新军(1972—),男,新疆石河子人,副教授,博士,主要研究方向:图像处理及模式识别、智能汽车及智能驾驶、生物识别; 吴晨晨(1993—),女,河南濮阳人,硕士研究生,主要研究方向:模式识别; 仲乾元(1990—),男,江苏徐州人,硕士研究生,主要研究方向:模式识别; 李园园(1993—),女,河南许昌人,硕士研究生,主要研究方向:模式识别。 1001- 9081(2017)09- 2694- 06 10.11772/j.issn.1001- 9081.2017.09.2694 TP391.41 A This work is partially supported by the National Natural Science Foundation of China (51677035), the Fundamental Research Project of Shenzhen (JCYJ20150513151706580), the Science and Technology Plan Project of Shenzhen (GRCK2016082611021550). MAXinjun, born in 1972, Ph. D., associate professor. His research interests include image processing and pattern recognition, intelligent vehicle and intelligent driving, biological identification. WUChenchen, born in 1993, M. S. candidate. Her research interests include pattern recognition. ZHONGQianyuan, born in 1990, M. S. candidate. His research interests include pattern recognition. LIYuanyuan, born in 1993, M. S. candidate. Her research interests include pattern recognition.
2 基于SIFT算法的特征提取和匹配模型












3 说话者唇部特征识别实验结果

4 结语

