时空特征局部保持的运动视频关键帧提取
2017-11-15石念峰侯小静
石念峰,侯小静,张 平
(1.洛阳理工学院 计算机与信息工程学院,河南 洛阳 471023; 2.河南科技大学 数学与统计学院,河南 洛阳 471023)(*通信作者电子邮箱alisha@163.com)
时空特征局部保持的运动视频关键帧提取
石念峰1,侯小静1*,张 平2
(1.洛阳理工学院 计算机与信息工程学院,河南 洛阳 471023; 2.河南科技大学 数学与统计学院,河南 洛阳 471023)(*通信作者电子邮箱alisha@163.com)
为提高运动视频关键帧的运动表达能力和压缩率,提出柔性姿态估计和时空特征嵌入结合的运动视频关键帧提取技术。首先,利用人体动作的时间连续性保持建立具有时间约束限制的柔性部件铰接人体(ST-FMP)模型,通过非确定性人体部位动作连续性约束,采用N-best算法估计单帧图像中的人体姿态参数;接着,采用人体部位的相对位置和运动方向描述人体运动特征,通过拉普拉斯分值法实施数据降维,获得局部拓扑结构表达能力强的判别性人体运动特征向量;最后,采用迭代自组织数据分析技术(ISODATA)算法动态地确定关键帧。在健美操动作视频关键帧提取实验中,ST-FMP模型将柔性混合铰接人体模型(FMP)的非确定性人体部位的识别准确率提高约15个百分点,取得了81%的关键帧提取准确率,优于KFE和运动块的关键帧算法。所提算法对人体运动特征和人体姿态敏感,适用于运动视频批注审阅。
关键帧提取;运动视频;姿态估计;柔性混合铰接人体模型;特征选择
随着混合式教学和MOOC(Massive Open Online Course)等在线学习技术在体育教学中的应用[1],产生了大量的学生动作长视频,通常采用基于视频关键的视频批阅技术提高学生动作长视频的评价效率[2-3]。在动作视频批阅时,教师依据人体部位的位置、形状等信息预测学生动作的运动轨迹和运动趋势,判断视频中是否存在错误或者不规范动作。因此,它要求关键帧集合帧数要尽可能少,同时人体动作局部拓扑结构表达要更准确。
关键帧技术是模式识别领域的研究热点,广泛地应用在运动捕获、人体行为及动作识别等方面[4-5]。但由于运动视频的高复杂性和非线性特征,至今尚未通用的关键帧算法。文献[6]通过相邻视频间颜色直方图的熵值差异比较,借助特定阈值筛选出高压缩率的关键帧集合;但由于需要事先设定阈值,所以当视频中动作变化剧烈时容易造成关键帧冗余或者遗漏,自适应性差。文献[7]采用基于核与局部信息的多维度模糊C均值聚类权衡图像的噪声和细节,自适应性筛选关键帧;但是由于缺乏时空约束,筛选的关键帧集合的运动时序表达能力较差,不适合本文的视频批阅。文献[8]将视频分割成运动物体和运动背景,通过分析物体运动和形状变化,采用无监督聚类算法确定关键帧;由于从语义层面分析和理解原始视频,所以提取的关键帧集合紧致且运动特征表达准确,能够满足本文的视频批阅需要。
采用文献[8]进行关键提取时通常需要根据应用背景设计物体识别及运动特征描述模型,因此如何建立运动视频中的人体运动模型是关键。文献[4]采用3D卷积神经网络(Convolutional Neural Network, CNN),通过执行3D卷积从多个连续视频帧中提取空间和时间维度上的运动特征,借助多通道信息融合确定关键帧,较好地保持了人体动作的时空特征,可以准确识别人体动作。然而,本文研究的运动视频中通常存在大量错误或者不规范动作,导致动作特征变化较大,所以这种人体运动特征模型不适合运动视频关键帧提取。文献[9]采用梯度方向直方图(Histogram of Gradients, HoG)人体分类器确定图像中的人体包围盒,利用人体模板将人体包围盒划分为16个不同权重的运动区域,通过比较运动区域的运动方向差异确定关键帧。由于受人体分类器的比例和人体模板尺寸限制,在复杂场景或者运动景深变化剧烈时下,容易造成人体动作识别错误,降低关键帧提取准确率。
综上所述,迫切需要一种自适应、能准确反映人体动作特征的运动视频关键帧提取技术。考虑到刚性人体模型的姿态识别方法的良好性能[10-11],本文提出在柔性混合铰接人体模型(articulated human model with Flexible Mixture-of-Parts, FMP)嵌入人体部位运动时空特征,提高人体及动作识别的鲁棒性,利用人体姿态参数及动作特征确定运动视频关键帧。
1 理论模型
1.1 嵌入时空特征的人体姿态估计模型
在FMP模型中,每个人体部位的不同仿射变形(如旋转或弯曲)被称为该部位的混合类型,简称混合类型[10]。由于同一个人体部位对应若干个混合类型,所以一幅图像I中的人体姿态参数由各个部位的位置信息及其混合类型共同确定。一般用一个K关系图G=(V,E)描述I中的某个姿态,其中顶点集合V表示人体部位(如头、上肢和躯干等),边集合E⊆V×V表示不同人体位之间的一致性约束关系。
根据FMP定义,一幅图像I中人体姿态p的参数估计问题可形式化为成本最小化问题,其成本函数C(I,p)为:
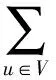
(1)
其中:φu(I,pu)是一个外观模型,表示在图像I的位置pu处识别出人体部位u的成本;ψu,v(pu-pv)是一个变形模型(通常假设为弹簧能量模型),表示两个人体部位u和v之间的变形成本。
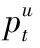

(2)
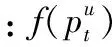
假设一段运动视频的帧图像集合为Ι={I1,I2,…,IT},估计的姿态参数序列为Ρ={p1,p2,…,pT},那么采用ST-FMP模型从Ι中得到Ρ的成本为:
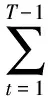
(3)
其中:C(IT,pT)表示根据式(1)得到的从图像IT中估计人体姿态pT的成本,T是运动视频帧数,λ1是一个规范化常量,θ(·)是式(2)表达的时空连续性误差。
1.2 基于非确定性部位优化的ST-FMP求解
FMP是一个刚性人体模型,可用一个马尔可夫随机场(Markov Random Field, MRF)表示,通过机器学习方法来确定人体部位参数[12]。在单帧图像中采用FMP估计人体姿态参数时,MRF被看作树状或星形图结构,通过置信度传播(Belief Propagation, BP)进行求解[10]。引入时间约束后,ST-FMP中会产生大量回路,需采用循环置信度传播(Loopy Belief Propagation, LBP)等近似算法通过最小化式(3)求解。然而LBP算法是图的最大团问题,具有指数级复杂度,在进行长视频姿态估计时效率很低。因此,本文设计了一种基于非确定性人体部位的两段式ST-FMP求解算法。
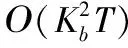
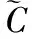
(4)
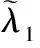
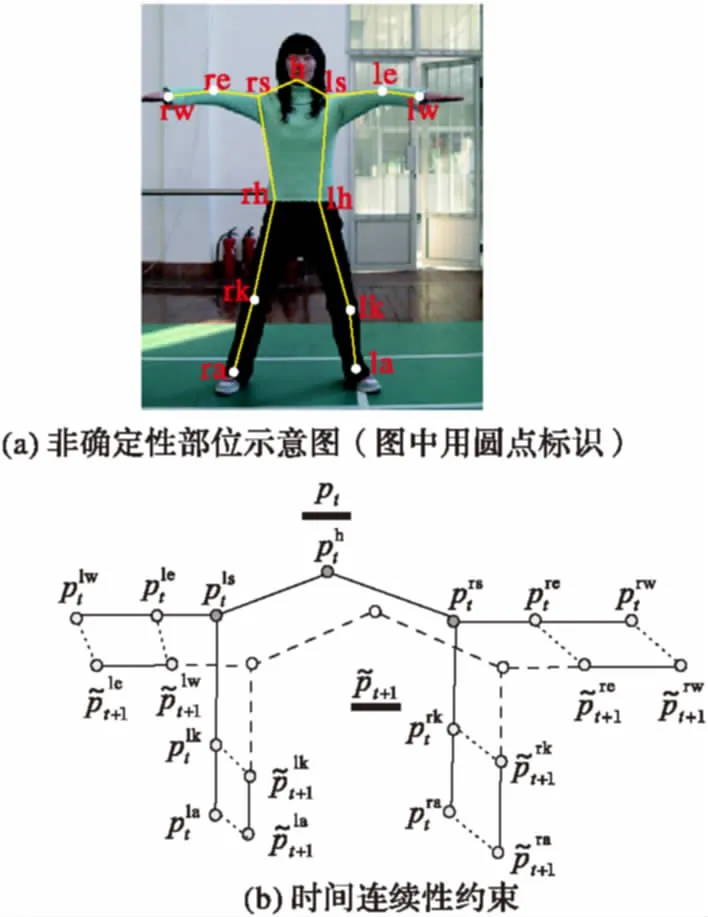
图1 非确定性部位局部动作时间连续性保持
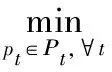
(5)
1.3 人体部位运动特征描述
由于无法获得关节角速度、位移速度等精确的人体部位运动参数导致现有运动捕获和动作识别的人体运动模型无法直接使用,为此,本文设计了一个基于人体部位相对位置特征和运动方向的人体运动特征描述模型。

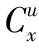
(6)
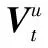
(7)

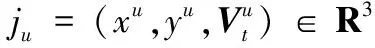
根据上述定义,人体姿态特征Ji是一个78维运动的向量,运动视频的运动特征f是一个78×T的向量矩阵。实验证明,在78×T的高维运动特征空间中进行关键帧提取具有较高时间复杂度,而且大量的数据冗余和噪声信息[14]将直接影响关键帧提取的准确性。为提高运动向量的局部特征表达能力,本文采用拉普拉斯分值法(Laplacian Scoring, LS)[15]对运动向量实施数据降维,确定更具判别性的人体动作特征。首先构建一个k近邻图Gk;然后采用热核函数计算Gk中相连两节点的相似度,获得第r个运动特征的拉普拉斯分值Lr;最后将前n(1≤n≤3d)个Lr较小的运动特征确定为该运动视频的人体姿态特征向量。
2 关键帧提取
本文提出一个基于ST-FMP模型和动态聚类的运动视频关键帧提取流程,简称ST-FMP算法。
首先,采用ST-FMP模型通过式(5)估计第r帧图像的人体姿态参数获得人体部位集合p={pu|u∈V},并利用式(6)和(7)得到人体运动向量,即:
fr=(fr1,fr2,…,frK)
(8)
其中:K等于3d,表示运动特征数;fri表示Ir中第i个人体部位的运动特征。
然后,将运动视频的所有运动向量进行组合得到动作特征的组合向量,即:
fcom=(f1,f2,…,fKT)
(9)
其中:T表示运动视频的帧数。
接着,利用LS算法计算fcom的Lr分值,获得判别性运动特征向量,记作fsub。
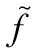
3 实验结果与分析
本文以健美操动作视频的关键帧为例进行仿真实验,实验结果与人工提取以及最新的运动视频关键帧算法[9,17]的提取结果进行了对比分析。
3.1 实验数据样本及特征训练
首先邀请3位学生每人做两遍120 s的大众二级健美操动作,并以20帧/s的采样频率采用普通网络摄像头录制成分辨率为640×480的视频;然后从第10个韵律节拍开始从6套视频中各选300帧图像作为实验数据;最后在1 800帧图像中按照图1(a)所示人工标记出每个健美操动作的13个关节位置。仿真实验时,选择第一、二遍动作的各900帧图像作为训练样本数据集和测试样本数据集。
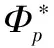
3.2 评价标准
人工提取出测试样本集中的所有关键帧,并以常用的关键帧提取准确率[18]作为算法性能评价标准,即:

(10)
其中:n和m分别代表人工和算法提取的关键帧帧数;fi和ri表示算法和人工提取的关键帧;δ(.)是fi和ri之间的相似函数,当fi和ri相同时δ(·)值为1,否则为0。
3.3 实验结果分析
3.3.1 非确定性部位时空特征嵌入的有效性比较
为了检验非确定性部位时空特征嵌入的人体模型在视频中的人体部位准确率,分别采用3种不同的ST-FMP模型实现,按照不同的误差像素阈值进行了肘部和膝盖两个人体部位的比较实验,实验结果如图2所示。
从图2可以看出,和FMP模型相比,采用ST-FMP算法进行运动视频中人体姿态估计时,在一定像素误差范围内非确定性部位的准确率显著提高。以误差阈值为20像素为例,ST-FMP算法得到的肘部和膝盖两个部位的准确率分别比FMP模型大约提高了15和19个百分点。但是当像素误差阈值较大(例如大于40像素)或者较小(例如大于10像素)时准确率差异不显著。图2还可以看出,当仅保持上肢(下肢)非确定性部位的时间连续性时,肘部和手腕(膝盖和脚踝)的识别准确率比直接采用FMP模型高,但比ST-FMP算法低。实验结果表明,通过人体部位局部时间连续性约束来优化人体部位识别结果,ST-FMP算法显著提高了运动视频中非确定性部位的识别性能。
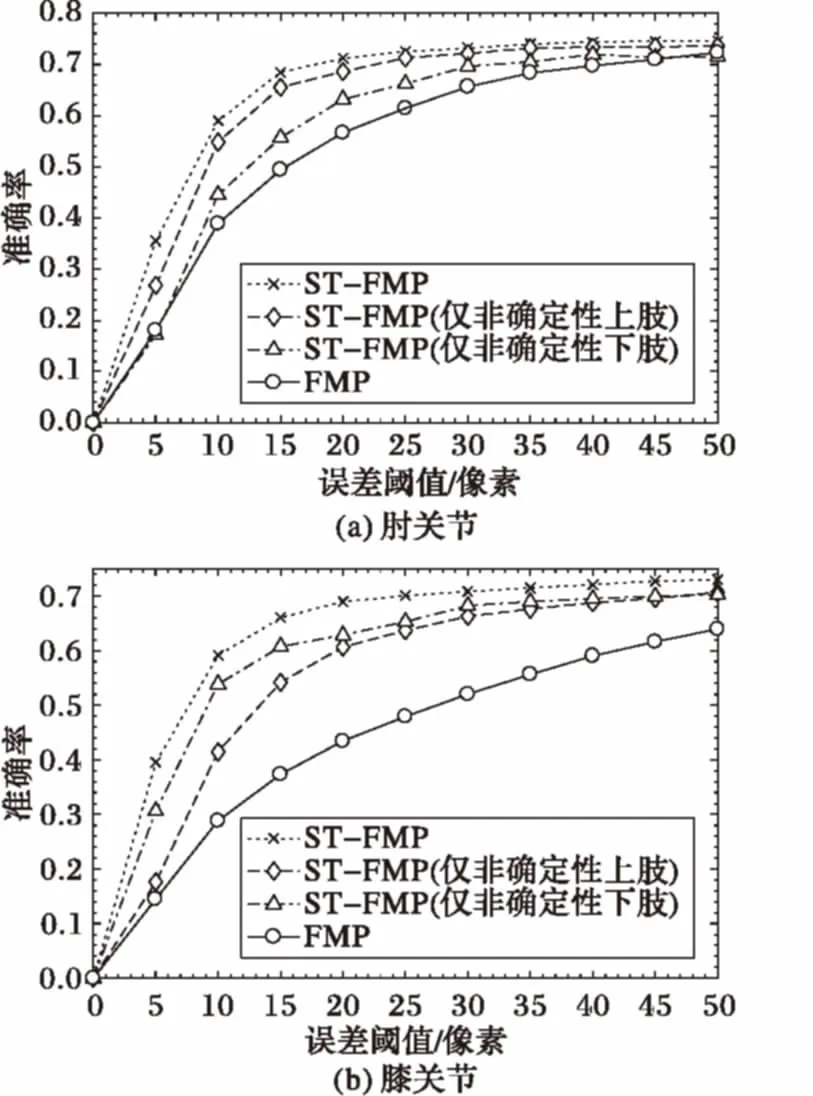
图2 不同ST-FMP实现下人体部位识别准确率比较
本文还对FMP模型和ST-FMP模型及其不同实现在运动视频关键帧提取方面的性能进行了比较。实验结果如图3所示。从图3可以发现:1)当精度误差小于30像素时, ST-FMP算法的准确率较高且比较稳定,比采用FMP的关键帧算法平均提高约11个百分点,而且仅增加上肢(下肢)非确定性部位的时间连续性约束时,FMP模型的关键帧提取准确率仍提高了约3个百分点;2)当误差精度大于35像素时,ST-FMP算法性能仍比采用FMP模型有所提高,但准确率降低大约15个百分点。
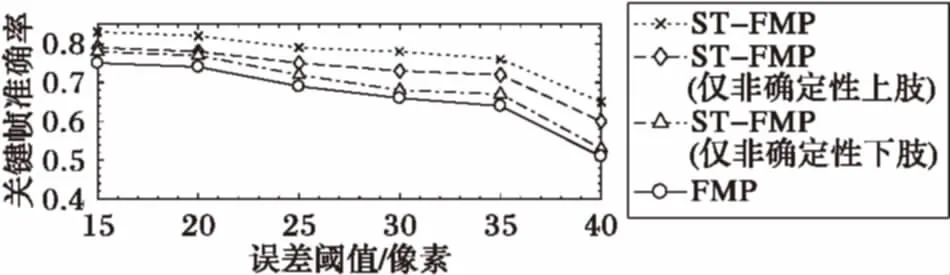
图3 基于FMP和ST-FMP的关键帧提取比较实验结果
同时,当精度误差为30个像素,以不同运动特征数通过ST-FMP算法提取关键帧时,算法准确率曲线在运动特征数为15~60的区间内波动不剧烈、性能稳定,如图4所示。
上述实验结果表明,ST-FMP算法对人体姿态估计结果和人体局部拓扑结构敏感,非确定性部位的时空约束保持对关键帧提取性能作用明显。
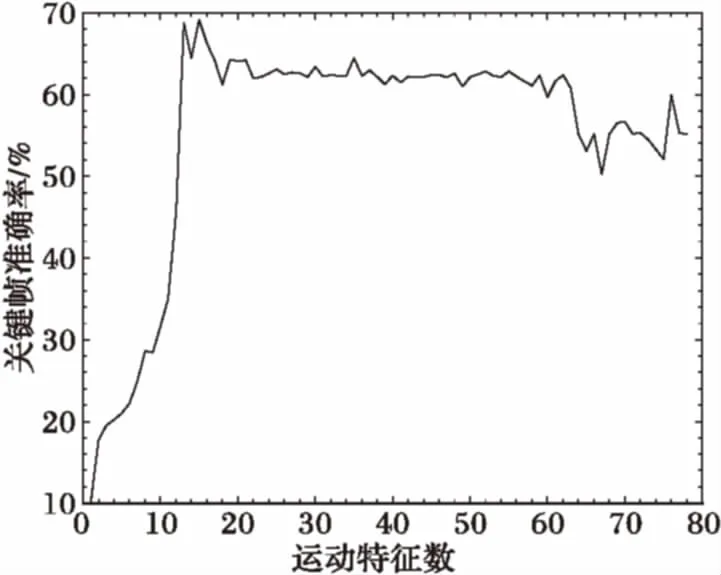
图4 不同运动特征数的关键帧准确率比较
3.3.2 关键帧算法性能比较
为了比较关键帧算法的性能,ST-FMP算法的仿真实验结果和文献[9]的基于先验的动作视频关键帧提取算法(简称KFE算法)及文献[17]的基于运动块关键帧提取算法(简称运动块算法)的运行结果进行了对比实验,如表1所示。
表1的实验结果显示ST-FMP算法的准确率和召回率均优于其他两种算法。首先,从表1中可以看出,ST-FMP算法的准确率比KFE算法和运动块算法分别高约18和26个百分点。KFE算法采用预先定义的16个区块的运动方向表示人体运动特征,而ST-FMP算法采用每套动作视频前15个LS人体运动姿态特征值表示人体运动。因此,ST-FMP算法采用的运动特征向量冗余小、噪声少,人体部位局部运动表达准确,利于提高关键帧和动作识别的准确率[19]。

表1 不同关键帧提取算法性能比较
其次,从表1还可以看出,ST-FMP算法的召回率也明显优于其他两种算法,平均分别高约23和13个百分点。KFE算法和运动块算法均属于基于图像底层特征差异的关键帧技术,它们通过比较图像不同区域内运动变化,采用特定阈值筛选关键帧。而ST-FMP算法描述的是人体部位的局部运动特征,本质上是一个语义模型,可以从人体运动参与部位及其运动变化趋势等更高层面来分析和理解运动视频中的人体动作,利用人体姿态相似等语义规则来筛选关键帧,可以获得符合人们认知过程的、更准确的关键帧结果。
上述实验结果说明,由于不仅具有较强的人体部位动作局部拓扑结构表达能力,而且还具有支持基于语义规则进行关键帧筛选的能力,所以ST-FMP算法更接近于人工提取结果,更适合基于关键帧的动作视频批阅。同时,由于ST-FMP将人体部位拆分成不同的柔性部件,通过柔性部件的局部拓扑结构识别人体姿态,借助时序特征边约束降低人体姿态估计连续误差,所以在复杂场景中具有较强的鲁棒性[10-11]。
4 结语
本文提出在柔性混合人体模型中嵌入人体部位运动时间约束,通过关注非确定性人体部位的时空连续性和优化人体姿态估计参数提高运动视频关键帧提取算法的准确率和召回率。首先,为保持FMP模型在运动视频中人体姿态估计的时空连续性,通过在相邻帧图像的人体部位顶点对间建立时间连续性约束得到具有时空连续特征的ST-FMP模型;然后,在相邻视频帧中的非确定性人体部位之间嵌入时空约束简化ST-FMP模型,采用N-best优化算法估计人体姿态参数,提高运动视频中人体姿态参数求解效率;接着,利用人体部位的相对位置特征和运动方向等特征描述人体部位运动特征,采用拉普拉斯分值算法实施特征选择,形成具有局部判别性的人体运动特征向量;最后,通过ISODATA动态聚类算法确定运动视频关键帧。对比实验表明,非确定性人体部位的时空连续性保持和局部动作时空特征嵌入等显著地提高了ST-FMP模型的人体部位识别准确率和人体姿态估计性能,获得的关键帧集合更符合人们认知过程。
由于本文采用ST-FMP算法从单帧图像中估计人体姿态参数,所以当运动视频中自遮挡或者运动模糊较多时会导致人体部位识别误差显著增加,从而影响关键帧提取的性能。因此,下一步可以考虑采用稠密光流轨迹或CNN技术通过提高人体部位识别的鲁棒性改善算法性能。
References)
[1] ZHOU M. Chinese university students’ acceptance of MOOCs: a self-determination perspective [J]. Computers & Education, 2016, 92/93: 194-203.
[2] LEHMANN R, SEITZ A, BOSSE H M, et al. Student perceptions of a video-based blended learning approach for improving pediatric physical examination skills [J]. Annals of Anatomy—Anatomischer Anzeiger, 2016, 208: 179-182.
[3] PANG Y J. Techniques for enhancing hybrid learning of physical education [C]// International Conference on Hybrid Learning, LNCS 6248. Berlin: Springer, 2010: 94-105.
[4] JI S, XU W, YANG M, et al. 3D convolutional neural networks for human action recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221-231.
[5] 姬晓飞,左鑫孟.基于关键帧特征库统计特征的双人交互行为识别[J].计算机应用,2016,36(8):2287-2291.(JI X F, ZUO X M. Human interaction recognition based on statistical features of key frame feature library [J]. Journal of Computer Applications,2016, 36(8): 2287-2291.)
[6] HANNANE R, ELBOUSHAKI A, AFDEL K, et al. An efficient method for video shot boundary detection and keyframe extraction using SIFT-point distribution histogram [J]. International Journal of Multimedia Information Retrieval, 2016, 5(2): 89-104.
[7] 王少华,狄岚,梁久祯.基于核与局部信息的多维度模糊聚类图像分割算法[J].计算机应用,2015,35(11):3227-3231.(WANG S H, DI L, LIANG J Z. Multi-dimensional fuzzy clustering image segmentation algorithm based on kernel metric and local information [J]. Journal of Computer Applications, 2015, 35(11): 3227-3231.)
[8] JANWE M N J, BHOYAR K K. Video key-frame extraction using unsupervised clustering and mutual comparison [J]. International Journal of Image Processing, 2016, 10(2): 73-84.
[9] 庞亚俊.基于先验的动作视频关键帧提取[J].河南理工大学学报(自然科学版),2016,35(6):862-868.(PANG Y J. Key frames extraction of motion video based on prior knowledge [J]. Journal of Henan Polytechnic University (Natural Science), 2016, 35(6): 862-868.)
[10] YANG Y, RAMANAN D. Articulated human detection with flexible mixtures of parts [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2013, 35(12): 2878-2890.
[11] 胡琼,秦磊,黄庆明.基于视觉的人体动作识别综述[J].计算机学报,2013,36(12):2512-2524.(HU Q, QIN L, HUANG Q M. A survey on visual human action recognition [J]. Chinese Journal of Computers, 2013, 36(12): 2512-2524.)
[12] PARK D, RAMANAN D. N-best maximal decoders for part models [C]// Proceedings of the 2011 International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2011: 2627-2634.
[13] SUN D, ROTH S, BLACK M J. Secrets of optical flow estimation and their principles [C]// Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2010: 2432-2439.
[14] FU Y. Human Activity Recognition and Prediction [M]. Berlin: Springer, 2016: 462-471.
[15] HE X, CAI D, NIYOGI P. Laplacian score for feature selection [C]// Proceedings of the 18th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2005: 507-514.
[16] BALL G H, HALL J. ISODATA, a novel method of data analysis and pattern classification [R]. Springfield: NTIS, 1965.
[17] 应锐,蔡瑾,冯辉,等.基于运动块及关键帧的人体动作识别[J].复旦学报(自然科学版),2014,53(6):815-822.(YING R, CAI J, FENG H, et al. Human action recognition based on motion blocks and key frames [J]. Journal of Fudan University (Natural Science), 2014, 53(6): 815-822.)
[18] XIA G, SUN H, NIU X, et al. Keyframe extraction for human motion capture data based on joint kernel sparse representation [J]. IEEE Transactions on Industrial Electronics, 2017, 64(2): 1589-1599.
[19] LIU Z, ZHU J, BU J, et al. A survey of human pose estimation [J]. Journal of Visual Communication & Image Representation, 2015, 32(C): 10-19.
Keyframeextractionofmotionvideobasedonspatial-temporalfeaturelocallypreserving
SHI Nianfeng1, HOU Xiaojing1*, ZHANG Ping2
(1.SchoolofComputerandInformationEngineering,LuoyangInstituteofScienceandTechnology,LuoyangHenan471023,China;2.SchoolofMathematicsandStatistics,HenanUniversityofScienceandTechnology,LuoyangHenan471023,China)
To improve the motion expression and compression rate of the motion video key frames, a dynamic video frame extraction technique based on flexible pose estimation and spatial-temporal feature embedding was proposed. Firstly, a Spatial-Temporal feature embedded Flexible Mixture-of-Parts articulated human model (ST-FMP) was designed by preserving the spatial-temporal features of body parts, and the N-best algorithm was adopted with spatial-temporal locally preserving of uncertain body parts to estimate the body configuration in a single frame based on ST-FMP. Then, the relative position and motion direction of the human body were used to describe the characteristics of the human body motion. The Laplacian scoring algorithm was used to implement dimensionality reduction to obtain the discriminant human motion feature vector with local topological structure. Finally, the ISODATA (Iterative Self-Organizing Data Analysis Technique) algorithm was used to dynamically determine the key frames. In the key frame extraction experiment on aerobics video, compared to articulated human model with Flexible Mixture-of-Parts (FMP) and motion block, the accuracy of uncertain body parts by using ST-FMP was 15 percentage points higher than that by using FMP, achieved 81%, which was higher than that by using Key Frames Extraction based on prior knowledge (KFE) and key frame extraction based on motion blocks. The experimental results on key frame extraction for calisthenics video show that the proposed approach is sensitive to motion feature selection and human pose configuration, and it can be used for sports video annotation.
key frame extraction; motion video; pose estimation; articulated human model with Flexible Mixture-of-Parts (FMP); feature selection
2017- 04- 25;
2017- 06- 10。
河南省科技攻关项目(152102210329, 172102310635)。
石念峰(1976—),男,河南洛阳人,副教授,博士,CCF高级会员,主要研究方向:计算机协同工作、模式识别; 侯小静(1975—),女,河南洛阳人,讲师,硕士,主要研究方向:模式识别; 张平(1976—),男,黑龙江牡丹江人,副教授,博士,主要研究方向:网络安全、模式识别。
1001- 9081(2017)09- 2605- 05
10.11772/j.issn.1001- 9081.2017.09.2605
TP391.4
A
This work is partially supported by the Key Science and Technology Program of Henan Province (152102210329, 172102310635).
SHINianfeng, born in 1976, Ph. D., associate professor. His research interests include computer supported cooperative work, pattern recognition.
HOUXiaojing, born in 1975, M.S., lecturer. Her research interests include pattern recognition.
ZHANGPing, born in 1976, Ph. D., associate professor. His research interests include network security, pattern recognition.
