以第一性原理计算进行不同高性能计算集群架构性能测评*
2017-11-10张彦彬吴民耀石裕维肖熠琳任豪
张彦彬 吴民耀 石裕维 肖熠琳 任豪
以第一性原理计算进行不同高性能计算集群架构性能测评*
张彦彬1吴民耀1石裕维1肖熠琳2任豪2
(1.广州高能计算机科技有限公司 2.广州市光机电技术研究院)
高性能计算集群平台种类繁多,按处理器种类可分为贝奥武夫架构的个人计算机集群和服务器集群,目前对其性能测评的研究较少。以不同架构、不同网络拓扑结构和不同网络带宽的高性能计算机集群为研究对象,利用第一性原理数值计算软件为性能测评工具,对不同的计算集群进行性能测评,分析架构、拓扑结构、带宽等因素对计算效能的影响。
性能测评;高性能计算集群;CPMD;VASP;第一性原理
0 引言
利用高性能计算集群进行科学模拟已成为现代科学研究主流,特别是利用高性能计算机仿真研究物质内部原子尺度的结构特性,已经成为物理、化学、生命与材料科学研究的有效方法。在诸多应用领域中,科学模拟取得的计算成果不仅可解释实验中观察到的测量数据,还可预测一些材料的性质,甚至是设计和创造新材料。但高性能计算集群建置成本昂贵。因此,利用个人计算机组成的贝奥武夫(Beowulf)架构[1]建立的高性能计算集群得到了快速发展,其计算性能得到了用户的肯定。但其具体计算性能与传统服务器所搭建的集群对比研究较少,造成高性能计算集群选择上的困难。鉴于此,本文针对3种不同硬件计算机集群(2种Beowulf架构,1种服务器架构)和3种不同的集群内部资源网络连接方法做性能测评。
以密度泛函理论(density functional theory,DFT)为基础的第一性原理计算,在解释和预测材料结构特性方面有非常重要的作用[2]。本文选择CPMD(Car-Parrinello Molecular Dynamics)[3]和VASP(Vienna Ab-initio Simulation Package)进行第一原理计算仿真,比较不同架构下高性能计算集群的性能表现。
CPMD是利用第一性原理分子动力学方法,结合密度泛函理论和古典分子动力学的计算机模拟技术[4]。
VASP[5]是维也纳大学Hafner小组开发的进行电子结构计算和量子力学—分子动力学模拟软件包。它是目前材料模拟和计算物质科学研究中最流行的商用软件之一。
1 测试环境
1.1 贝奥武夫架构集群
本文关于贝奥武夫架构集群所使用的测试平台为MCBW-I和MCBW-II高性能计算集群,其硬件和软件配置如表1、2所示。
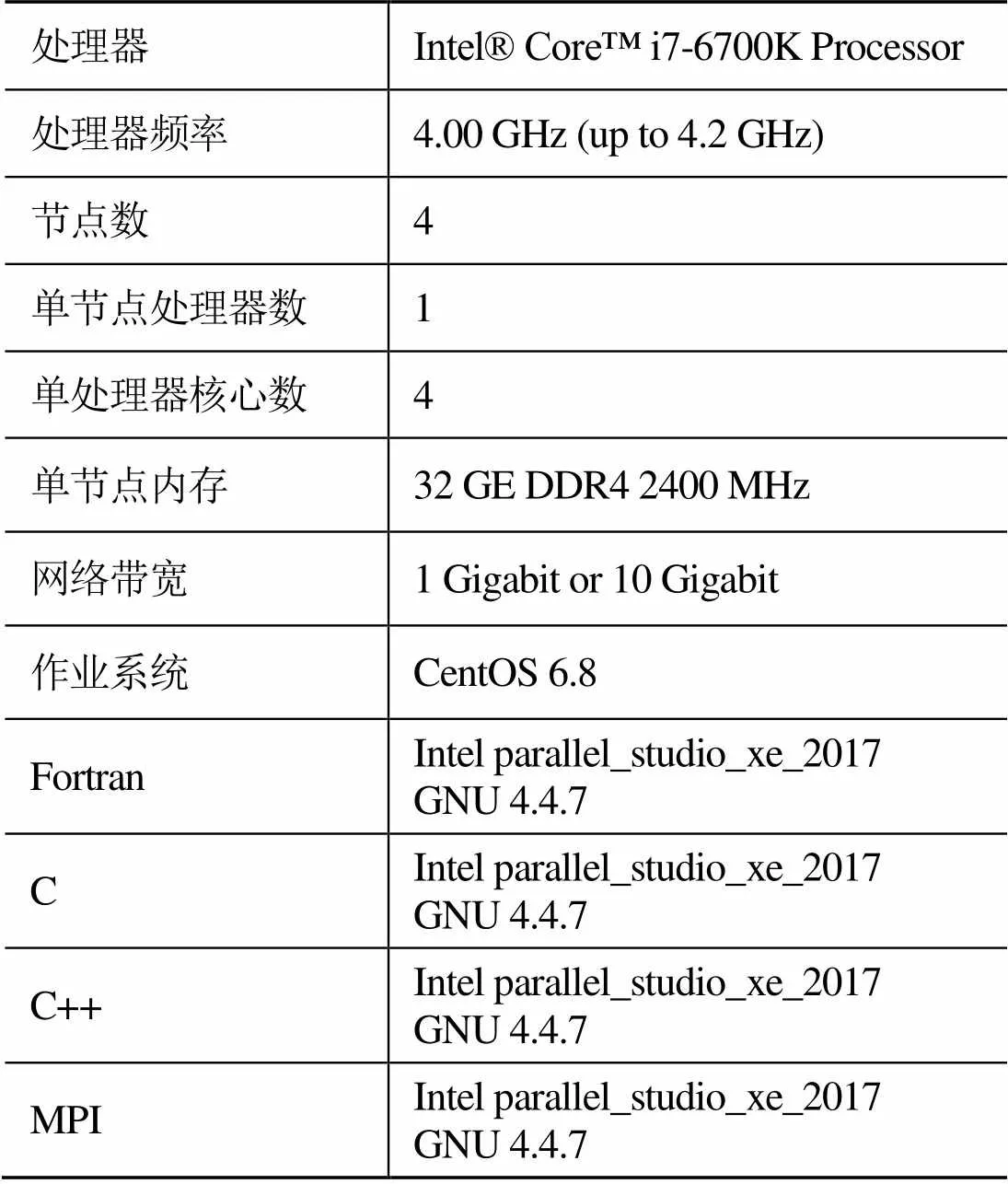
表1 MCBW- I硬件和软件配置
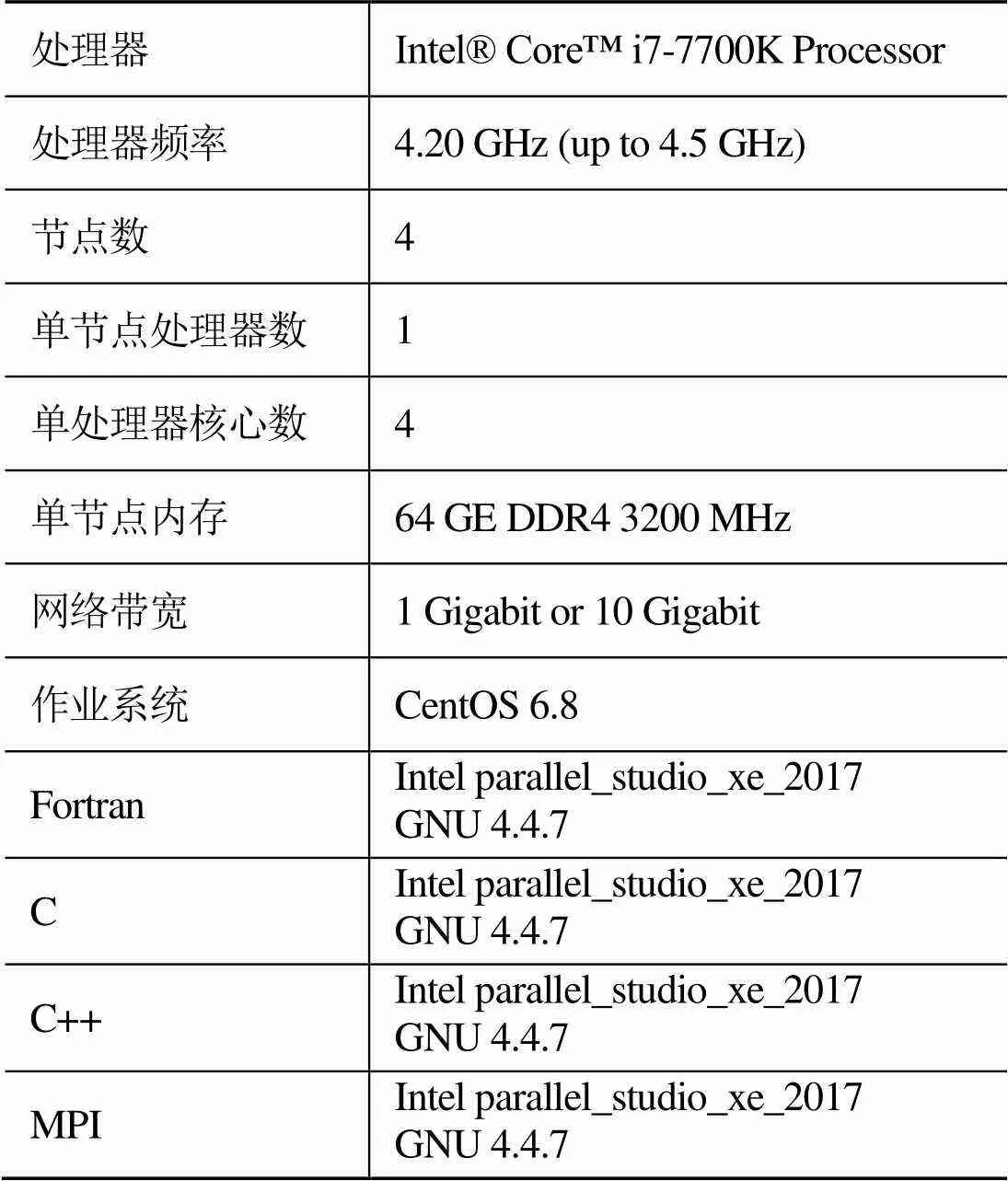
表2 MCBW-II硬件和软件配置
1.2 服务器架构集群
本文关于服务器架构集群所使用的测试平台为SFCS(switch free cluster system)高性能计算集群,其硬件和软件配置如表3所示。
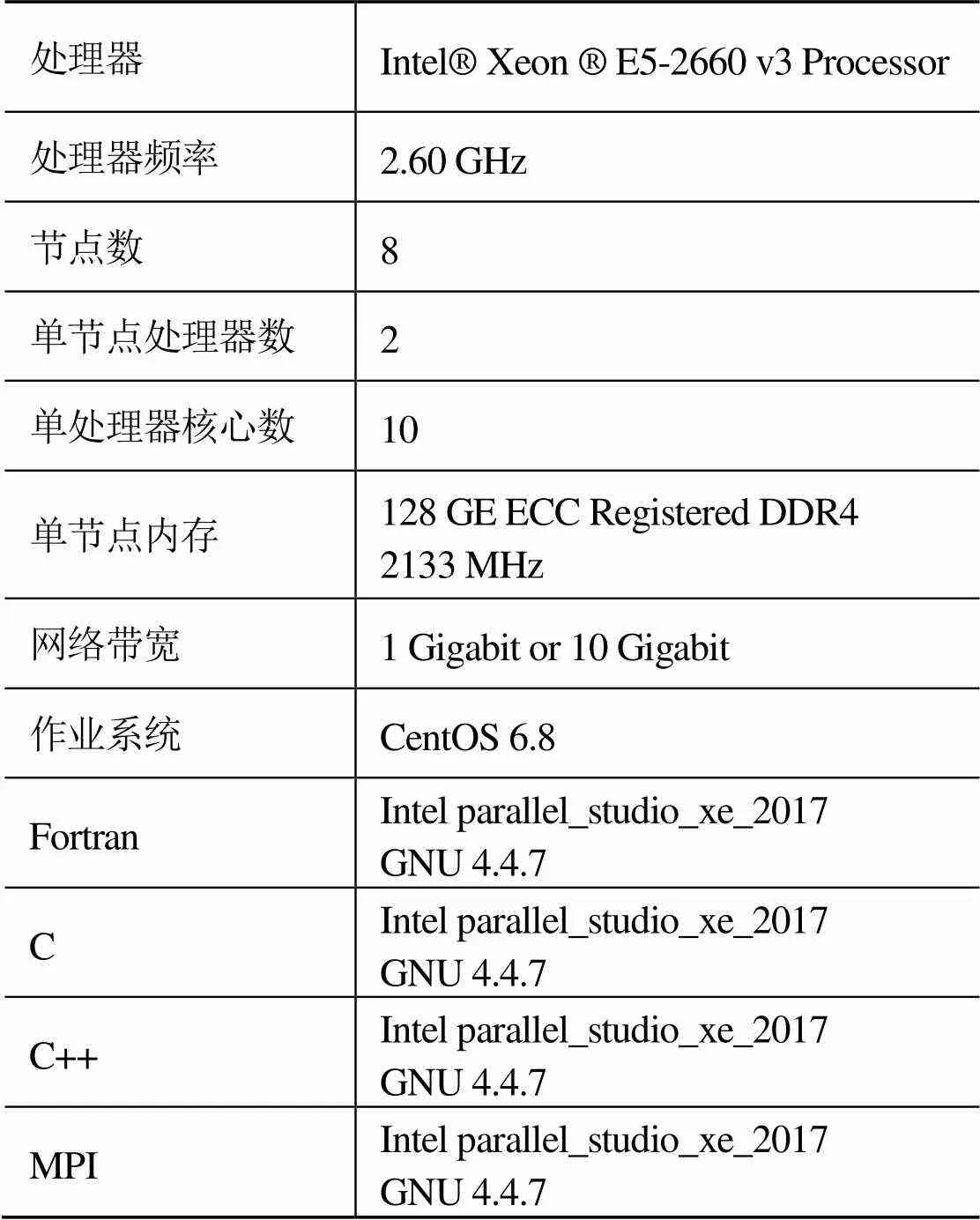
表3 SFCS硬件及软件配置
1.3 网络拓扑架构
本文测试全直连(见图1)、星状连接(见图2)和网络交换机(见图3)3种不同的连接架构。

图1 全直连系统架构
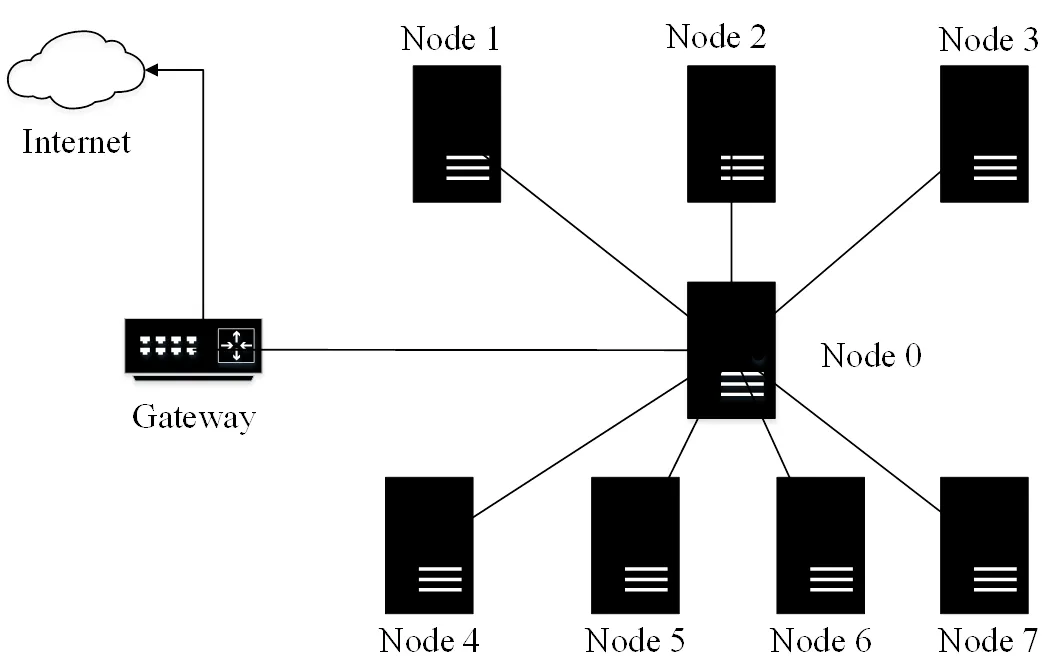
图2 星状连接系统架构
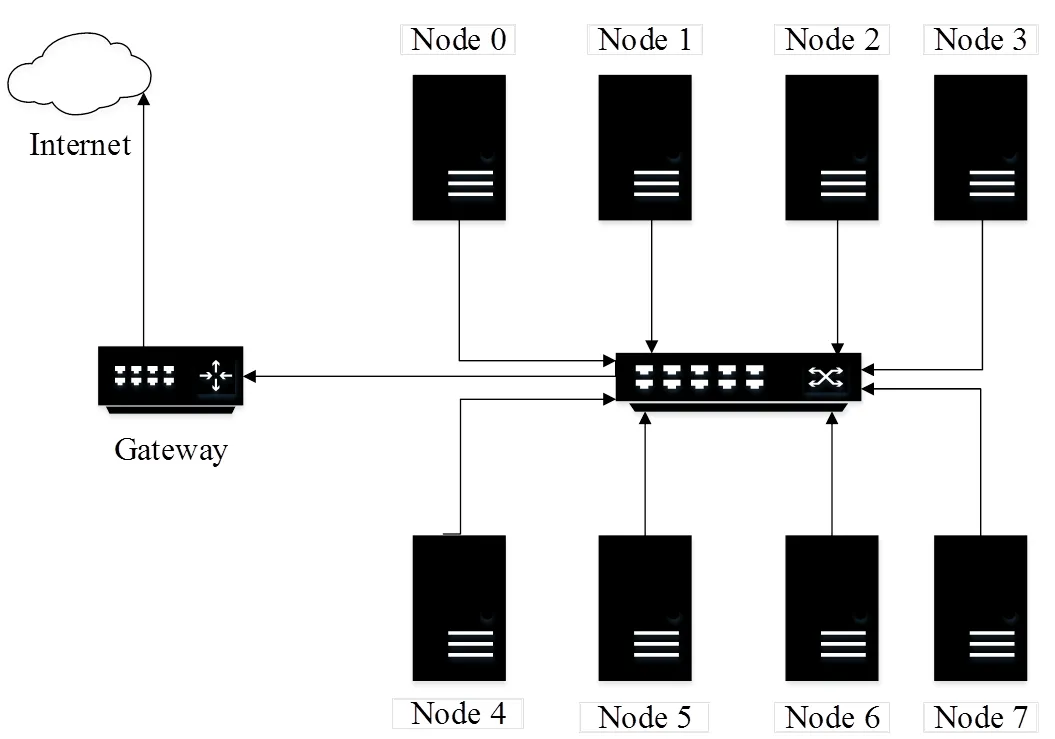
图3 网络交换机系统架构
其中全直连系统架构为每一个计算节点都与其他节点以直接链接的方式进行通讯;星状连接系统架构为以一个计算节点为中心节点,与其他计算节点连结,中心节点的功能类似传统网络交换器;网络交换机系统架构为计算节点之间利用交换器进行数据交换。为测试网络带宽对计算效能的影响,使用1 GE和10 GE 2种网络带宽进行测试。
2 测试结果
2.1 MCBW-I测试结果
在MCBW-I平台上,利用CPMD计算碳60结构的基态能量,不同网络拓扑架构和网络带宽的计算效能差异如图4所示。其中,纵坐标加速比以单节点计算时间为基准。由图4可知,第一影响因素是网络带宽;第二影响因素是网络拓扑架构。
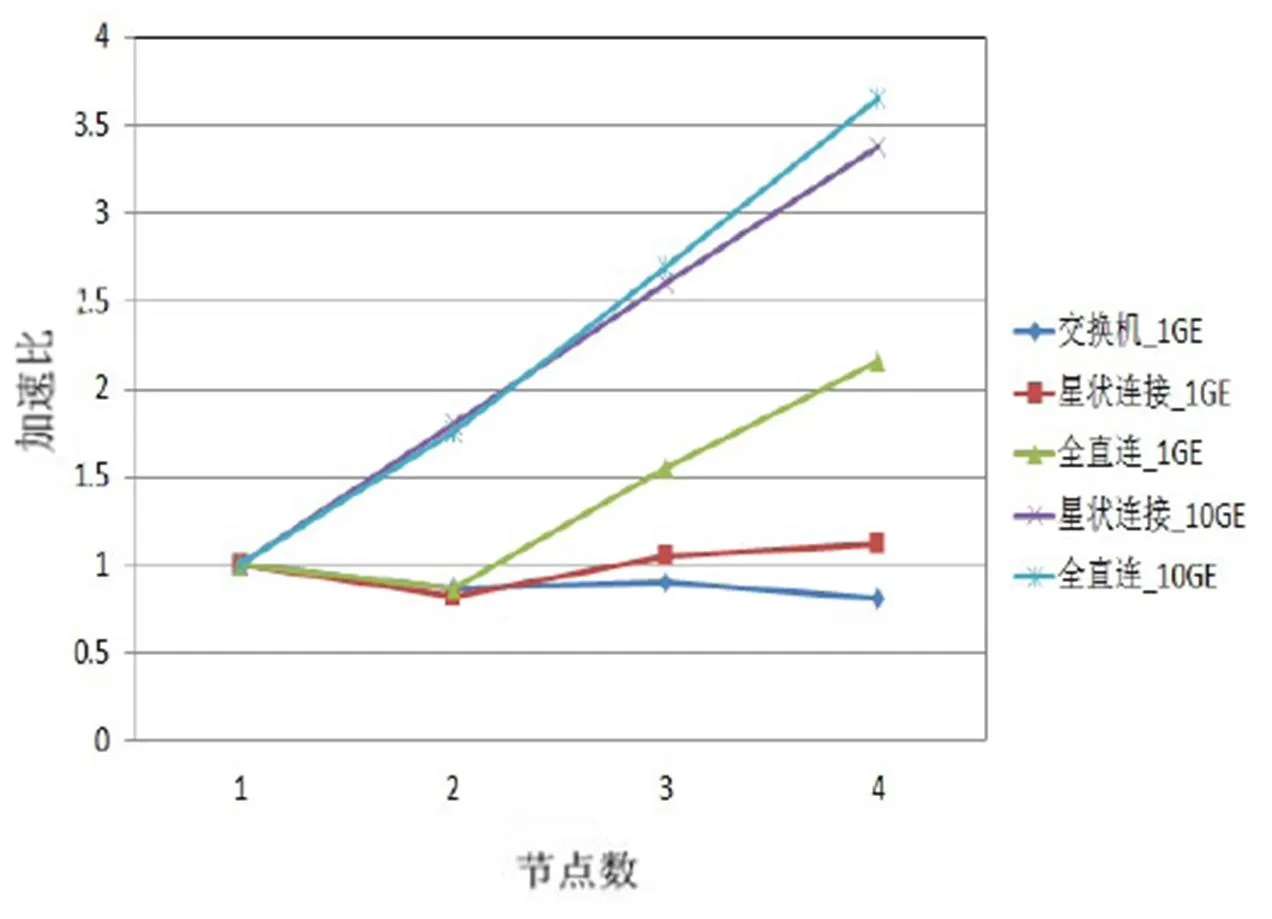
图4 MCBW-I CPMD测试结果
当采用1 GE网络带宽时,CPMD跨节点计算效率不理想。虽然全直连系统可提供较大的网络带宽(每台节点有3条网络线连接),但4节点计算仅提供2倍的加速比。
当采用10 GE带宽进行4节点计算时,星状连接和全直连系统架构都提供超过3倍的加速比,效率超过80%。在节点增加时,全直连系统架构较星状连接系统架构效能增加更明显,这是由于在全直连系统架构下,计算节点以直接连结方式通讯;而星状连接系统架构,除中心节点,其他计算节点至少需要经过1个计算节点才能与其他节点通讯,通信成本随之增加。
在MCBW-I平台上,利用VASP计算HfO2电子结构的跨机效能如图5所示。VASP在1 GE带宽下的跨机平行效率比CPMD高,全直连10 GE的4节点计算加速比最高,星状连接10 GE以微小差距排第二。值得注意的是,VASP的计算会出现效率超过100%的情况,这是因为加速比以单计算节点的计算时间为基准。当单计算节点内存带宽不足时,会出现如图5所示情况。
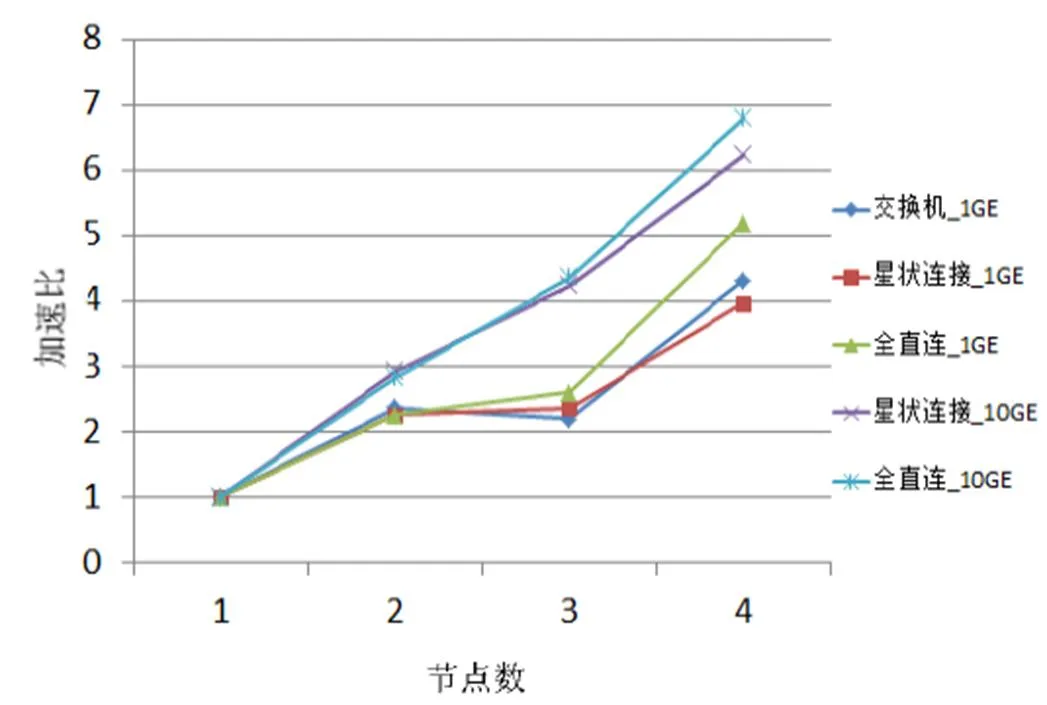
图5 MCBW- I VASP测试结果
2.2 SFCS测试结果
为研究服务器架构平台在不同网络拓扑架构和网络带宽下的跨机运算情况,进行了与图4、图5相同的计算。SFCS CPMD测试结果如图6所示,与图4的跨机效能趋势一致,CPMD的跨机运算效能主要受到网络带宽的影响。SFCS VASP测试结果如图7所示,全直连网络拓扑架构可有效提升1GE网络带宽下的跨机运算效率。与CPMD计算相同,网络带宽主要决定了跨机运算效率,而全直连网络拓扑架构的优势会在计算节点增加时出现。
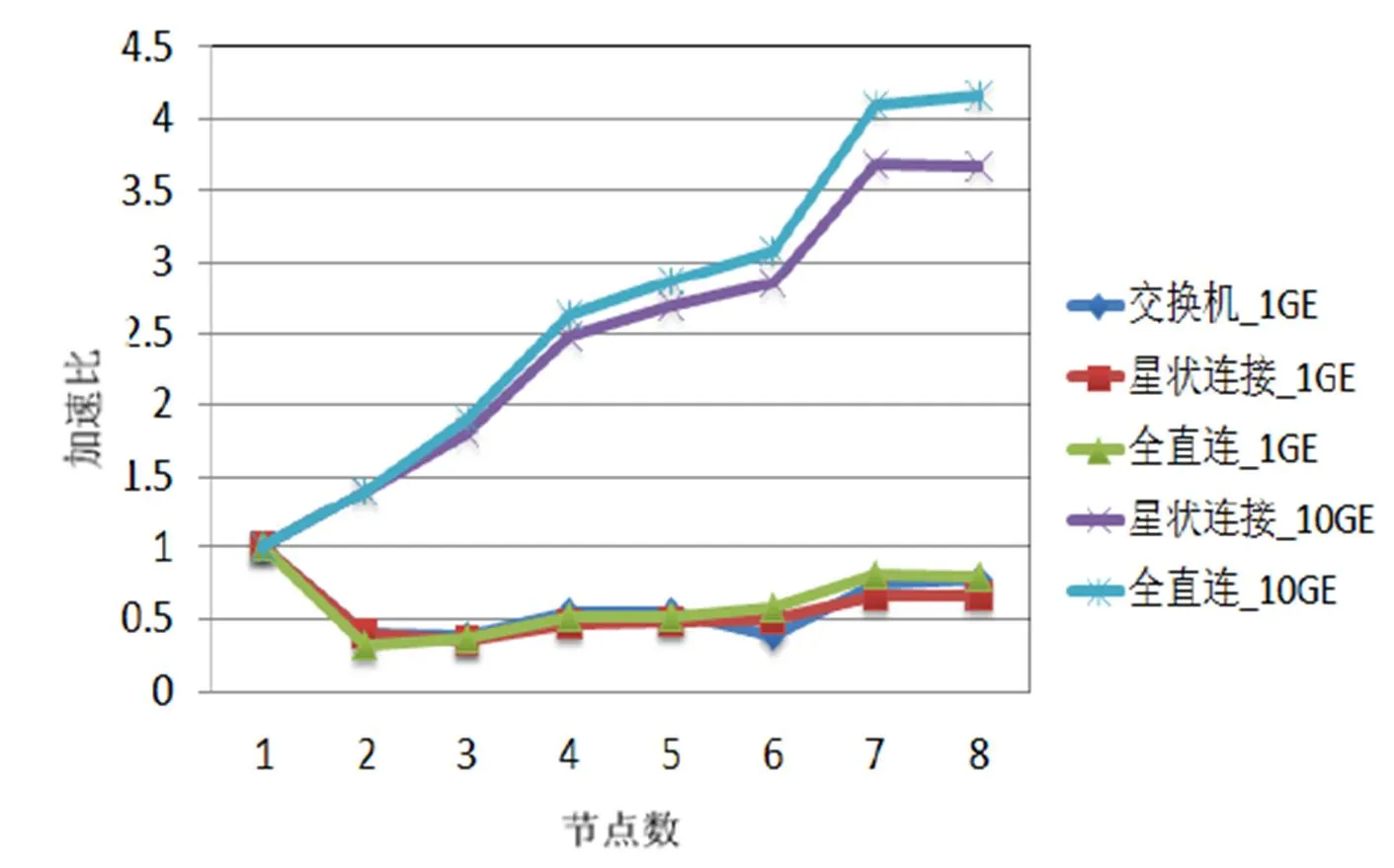
图6 SFCS CPMD测试结果
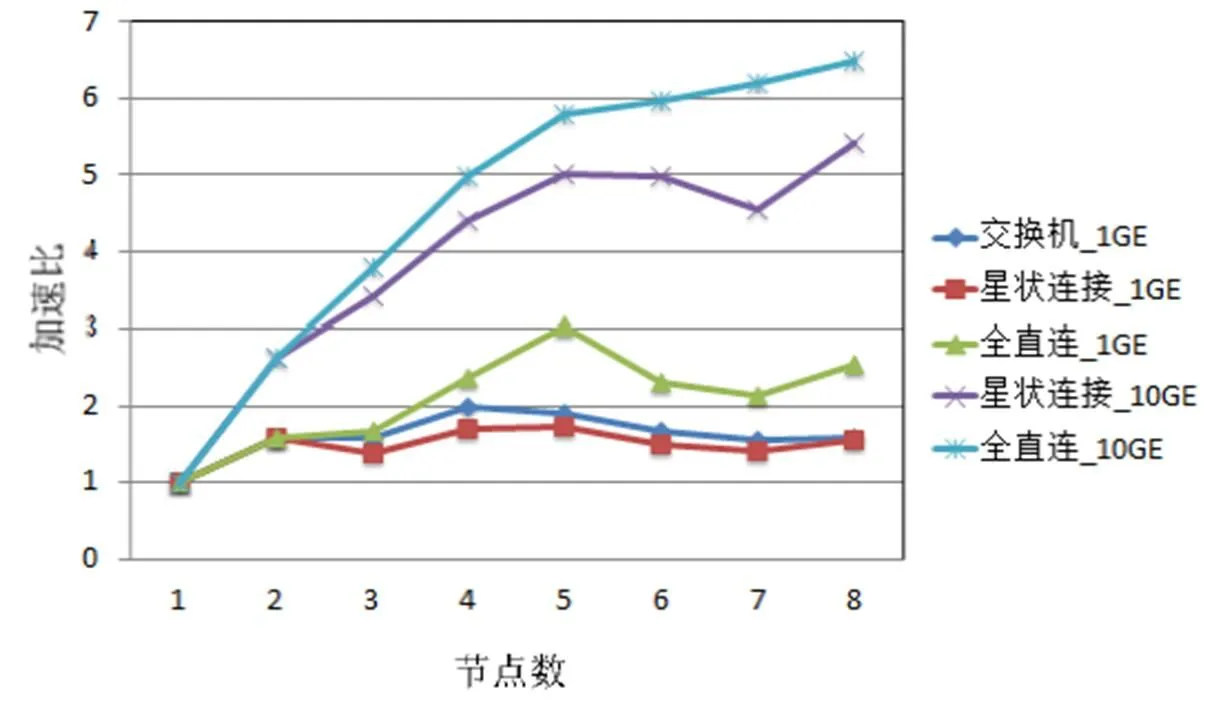
图7 SFCS VASP测试结果
2.3 MCBW-II测试结果
MCBW-II为MCBW-I的二代版,主要差异为CPU频率由4.0 GHz 提升到4.2 GHz,内存带宽由2400 MHz提升到3200 MHz。CPU频率的提升有助于提高单核的计算效能。MCBW-I和MCBW-II的计算效能测试结果如图8、图9所示。根据图4、图5的测试结果,在较少节点情况下,星状连接系统架构和全直连系统架构的计算效能接近,且不同的网络架构在1 GE带宽下效能差别不大,所以接下来的测试将以星状连接系统10 GE和1 GE网络交换机系统架构为主。
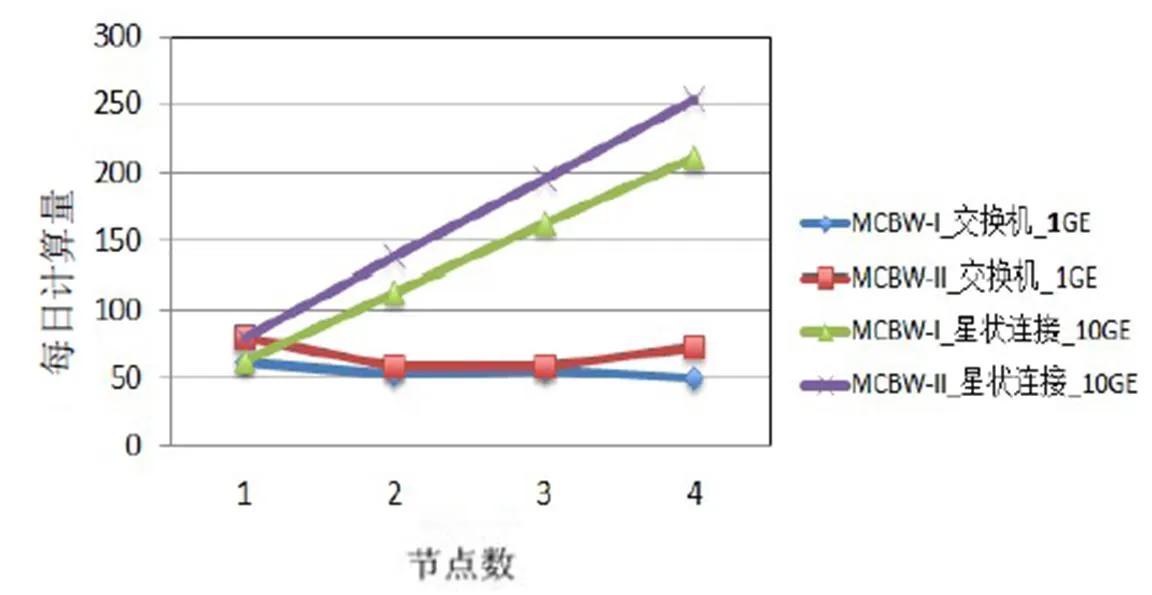
图8 CPMD测试结果
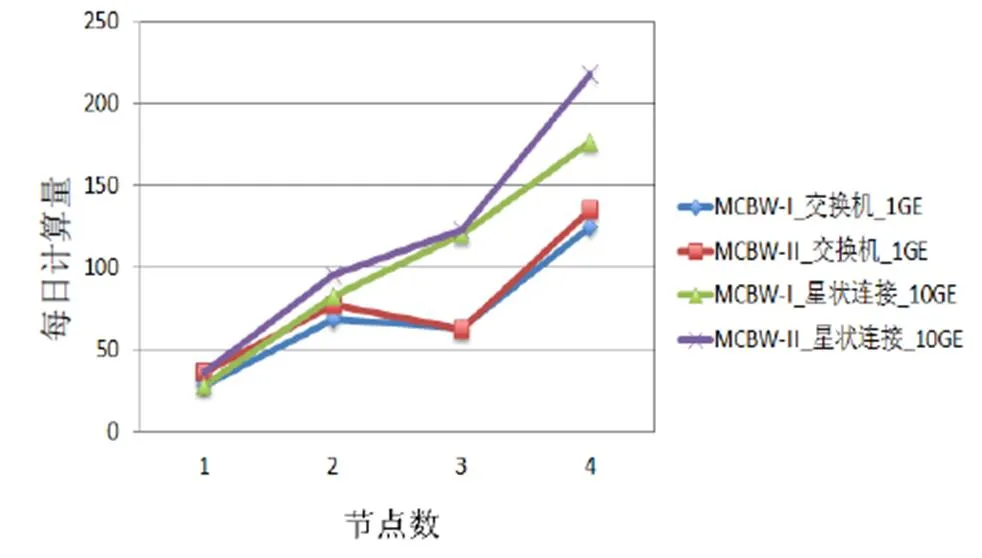
图9 VASP测试结果
2.4 不同架构、网络拓扑结构及网络带宽的计算机集群性能对比
由图5和图7可知,VASP跨机运算效率出现超过100%的情况,上文已经提到这现象与单机的内存带宽有关。为证明这点,在MCBW-II的一个计算节点做测试:让一个VASP仅使用单核进行计算,依次将相同的工作增加到4个。理想状况下,一个计算节点拥有4个运算核心,一个节点执行一个工作和同时执行4个工作运算时间是一样的。MCBW-II单节点进行VASP模拟的运行时间如图10所示,发现由于受到内存带宽和通信道数目的限制,同时执行4个工作所花的计算时间仅是执行1个工作的2.4倍。
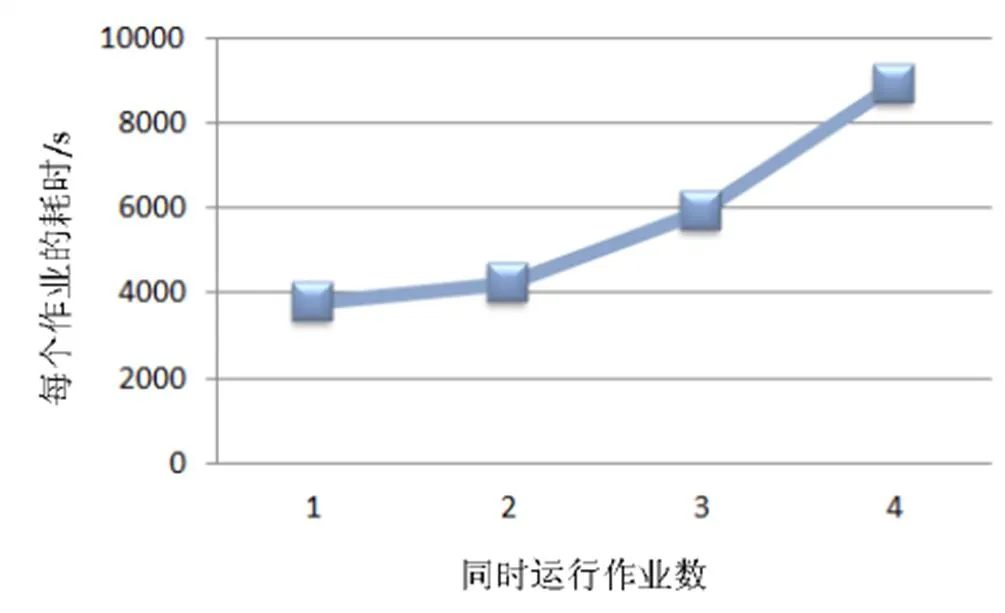
图10 MCBW-II单节点进行VASP模拟的运行时间
测试结果说明了多核计算由于内存带宽和通信道数的限制,使得内存和CPU的通讯时间增长,最终造成运算时间增加。SFCS单节点VASP并行计算测试结果如图11所示。
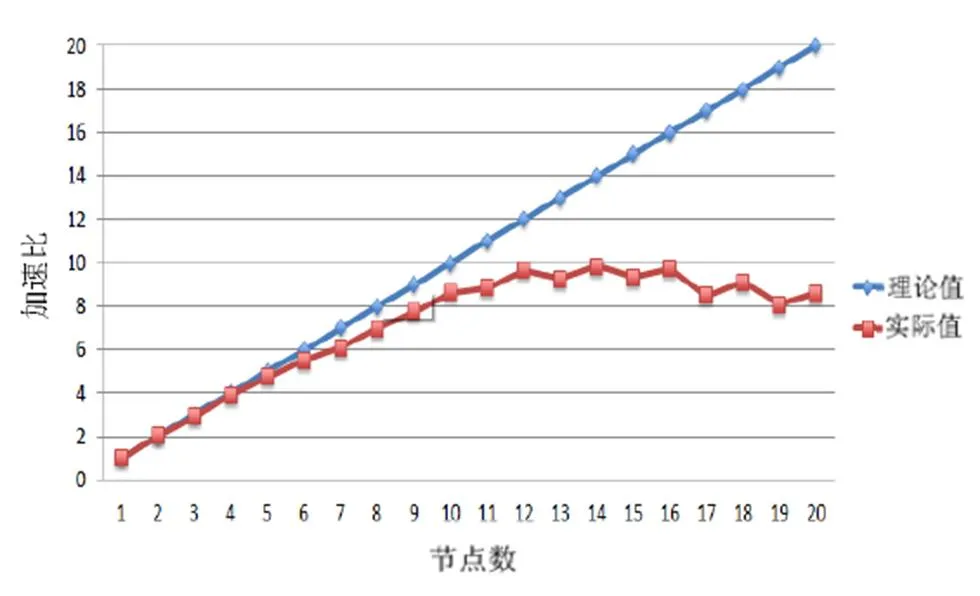
图11 SFCS单节点VASP并行计算测试结果
由图11可以看出,使用5个核心进行运算时,效能基本符合理论值,超过5个核心后,效能开始偏离理论值。由于SFCS每个计算节点具有2颗实体CPU(每颗CPU具有10个核心),除了内存信道数目和带宽限制,2颗CPU之间通讯的带宽也会限制多核心的运算效率。从图5和图7的测试结果显示,跨机运算可以解决单机内存带宽不足的限制。由图10和图11可知,以单计算节点的计算时间作为跨机效率的基准存在问题,利用单核的计算时间作为基准比较适合。
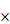
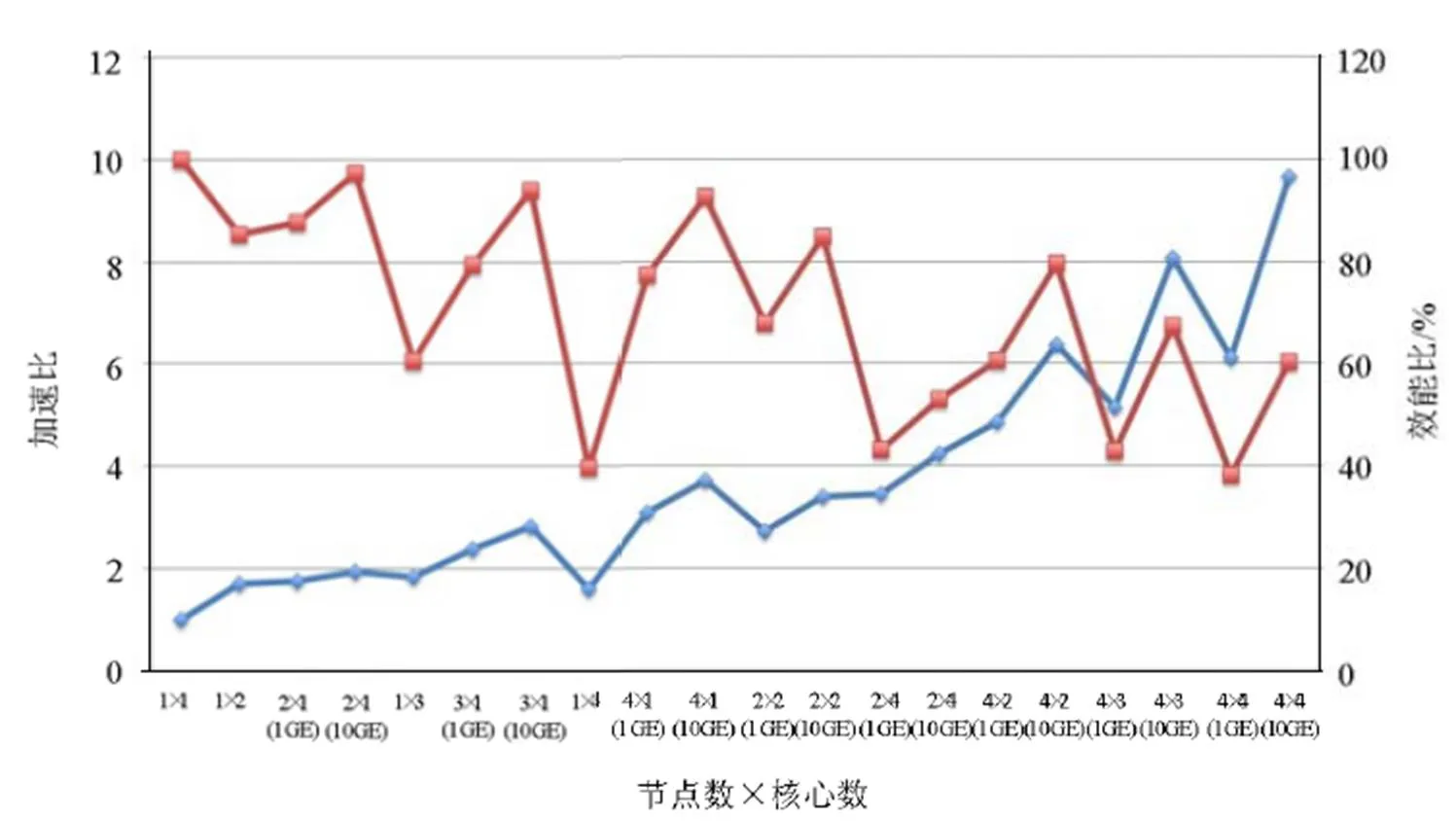
图12 利用跨节点计算的方式有效增加内存带宽提升多核运算效率

图13 MCBW-II和SFCS单节点在相同核心数下运算效能比较图
根据以上的测试结果可知,在网络带宽足够的情况下,采用跨机运算的方式比单机增加CPU核心数目更能有效提升计算效能。
3 结论
本文通过3种不同的网络架构对2大类型计算集群进行第一性原理计算分析,对于集群单节点性能、整体性能与网络结构及带宽影响有了整体了解,并得出以下结论:
1)全直连系统架构可在千兆带宽时提供与交换机网络架构相同的计算性能;
2)计算量较大时,采用直连万兆带宽可有效提升集群整体运算性能;
3)CPMD和VASP在跨机运算时需要非常大的网络带宽,除了采用10 GE网络,搭配利用全直连系统或星状连接系统的网络拓扑架构可以进一步提升网络带宽;在第一性原理计算应用过程中,为有效提升计算效率,可采用跨界点的并行计算方法;
4)贝奥武夫集群可利用增加计算节点数的方式增加内存带宽,计算效能可持续增加;服务器集群因受限内存和CPU之间通讯的带宽,到16核心已出现效能饱和的情况,对计算效能提升并不明显。
[1] Wikipedia. Beowulf Cluster[EB/OL]. [2017-08-28]. https://en. wikipedia.org/wiki/Beowulf_cluster.
[2] Marx D, Hutter J. Ab initio molecular dynamics: basic theory and advanced methods [J]. Cambridge University Press, Aug. 2011, 307:109-153.
[3] CPMD Org. CPMD [EB/OL]. [2017-08-28]. http://www.cpmd. org/Copyright IBM Corp 2000-2017.
[4] CPMD Org. CPMD manual[EB/OL]. [2017-08-28]. http://cpmd.org/downloadable-files/nouthentication/manual_v4_0_1.pdf.
[5] Xsede.org. VASP manual [EB/OL]. [2017-08-28]. https:// www.xsede.org/wwwteragrid/archive/web/user-support/vasp_ benchmark.html.
Performance Evaluation of Different HPC Cluster Architectures by Using First Principles Calculations
Zhang Yanbin1Ng Mingyaw1Shi Yuwei1Xiao Yilin2Ren Hao2
(1. Guangzhou HPC Technology Inc. 2. Guangzhou Research Institute of O-M-E Technology)
Currently, there are many kinds of high performance computing system. According to the division of processor types, it can be simplified into two types - Beowulf PC cluster architecture and server cluster, but there were less performance evaluation studies between these two kinds of system. This paper carried out the study on their properties, with different architectures interconnect topologies and bandwidth, use the 1stprinciple software as the performance evaluation tools. The results can be useful for the HPC users in the future.
Performance Evaluation; High Performance Computing Cluster; CPMD; VASP; First Principles
张彦彬,男,1978年生,硕士,主要研究方向:热流分析、并行计算、网络拓扑设计、分布式计算、高性能计算系统。 E-mail: johnson.z@hpctek.com
吴民耀,男,1979年生,博士,主要研究方向:近场光学,第二型半导体量子点的激子效应和纳米材料的瞬时结构动力学。
石裕维,男,1993年生,本科,主要研究方向:高性能计算系统、并行计算、网络架构。
肖熠琳,女,1982年生,硕士,高级工程师,主要研究方向:项目资源与作业管理、并行计算。
任豪,男,1972年生,博士后,教授级高工,主要研究方向:纳米陶瓷薄膜材料。
广州市科技计划项目(201508030009);广东省科技计划项目(2017A010109077)。
