“大数据”时代的中国现当代文学研究
2017-11-07张全之韩莉
张 全 之 韩 莉
(重庆师范大学 文学院,重庆 401331;齐鲁工业大学 图书馆,山东 济南 250353 )
2017-6-25
张全之(1966--),男,山东沂南人,文学博士,重庆师范大学文学院教授。
韩莉(1970--),女,山东滕州人,齐鲁工业大学图书馆馆员。
“大数据”时代的中国现当代文学研究
张 全 之 韩 莉
(重庆师范大学 文学院,重庆 401331;齐鲁工业大学 图书馆,山东 济南 250353 )
我们已经进入“大数据”时代。“大数据”改变着我们的生活,也改变着我们的思维方式,文学研究也必然会受其影响,进入一个新的时代。就目前来看,中国古代文学研究在数据库的开发利用方面已经取得很高成就,在对“大数据”使用方面也有较为充分的准备。相对而言,中国现当代文学研究对“大数据”时代的反应较为迟钝,尚无理论上的思考和准备。但无论怎样,“大数据”给中国现当代文学带来的新思维和新方法是无法抗拒的,必将给这一学科的研究带来巨大变化。
大数据;数据库;数字化;数据化
一、“大数据”与文学研究的现状
当下我们已经进入大数据时代。所谓“大数据”(Big data),麦肯锡全球研究所给出的定义是:“一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。”(见百度百科)舍恩伯格和库克耶在《大数据时代》中指出:“大数据标志着‘信息社会’终于名副其实。我们收集的所有数字信息都可以用新的方式加以利用。我们可以尝试新的事物并开启新的价值形式。但是,这需要一种新的思维方式,并将挑战我们的社会机构,甚至挑战我们的认同感。……但是,现在大多数人都认为数据是一个技术问题,应侧重于硬件或软件,而我们认为应当更多地考虑当数据说话时会发生什么。”[1]239-240海量的数据,通过“云计算”按照操作者的需要进行处理,已经得到广泛的运用,并产生了惊人的效果。在我国,有关“大数据”的研究和讨论也渐成热点。从中国知网看,标题含有“大数据”的论文,近一两年呈井喷之势,具体数据如下:

年份20102011201220132014201520162017论文数量194335819634448706097802570
很明显,前三年的数据起伏不大,但从2013年开始到2016年,数据迅速扩大,成为众多研究领域中的热点。与之相适应,我们国家对“大数据”也十分重视。2015年,经李克强总理签批,国务院发布《促进大数据发展行动纲要》,对“大数据”在未来经济社会发展中的作用给予了高度重视,认为:“坚持创新驱动发展,加快大数据部署,深化大数据应用,已成为稳增长、促改革、调结构、惠民生和推动政府治理能力现代化的内在需要和必然选择。”“大数据”不仅带来经济和科技发展的新跨越,对人文社会科学研究也会产生重要影响。事实上,在国外,利用“大数据”开展文学研究早已起步。美国斯坦福大学教授弗朗哥·莫莱蒂(Franco Moretti)在他提出的“远距离阅读”(distant reading)的基础上,与马修·乔克思建立了“文学实验室”[2]。他通常的做法是雇佣几个研究生,“专门借助计算机检索、收集相关数据,以供他来分析。他的主要职责是利用统计的数据绘制文学的图表,通过对图表的分析来揭示文学的秘密”[3]。如他在《文体:对7000个小说标题的反思》一文中,通过对数据的整合分析,寻找到小说标题字数的变化与时代之关系,还指出了小说标题的四种类型,他的这类研究如果不靠“大数据”是无法完成的。所以说,以“大数据”为依托,采用数据分析法对文学进行研究,已经成为一种不可阻挡的新趋势,也是“大数据”时代文学研究的题中应有之义。在中国,也有很多学者在思考“大数据”时代文学研究的新方法和新问题,相关研究主要集中在二个方面:一是综合论述“大数据”时代文学研究方法或综合介绍西方相关研究的,这样的论文主要有上面曾经引述过的2篇:《大数据时代的文学研究方法:基于弗兰克·莫莱蒂文学定量分析发的考察》和《“大数据”分析与文学研究》。前者详细介绍了莫莱蒂用定量分析法研究文学取得的成就,认为:“莫莱蒂和他的团队用定量分析的具体研究成果向世人证明,借助大数据的文学研究不是乌托邦的空想,而是具有切实的实践性,它能够为文学研究提供新的研究思路。”后者也是以介绍莫莱蒂“文学实验室”的相关研究为主,但也提出了“大数据”与“小阅读”的问题。作者认为,研究者个人的“小阅读”是不可替代的,但通过“大数据”分析对文学进行研究,也有积极意义:“人脑和电脑在阅读文本的时候所用的方法和关注的重点不一样,读出来的东西也可能截然不同。不过人脑和电脑在阅读阐释文学的时候也往往可以互为体用,互补短长,文学‘大数据’分析和学者个人的‘小阅读’之间存在着许多交融与合作的可能。”[2]二是各学科纷纷着手研讨“大数据”与相关学科研究之间的关系。比较而言,中国文学下面的二级学科中中国古代文学研究领域显得较为活跃,早在2005年《文学遗产》就推出了李铎和王毅的《关于古代文献信息化工程与古典文学研究之间互动关系的对话》,他们特别提醒:“人与计算机将来的关系不是谁代替谁的问题,而是互相交流和启发,对话和融通,当然这之中并不是绝对平等的,人的主体性是第一位的,但我们也要向计算机学习,包括进入它的思维方式:要融合各种知识,也要补课,古典文学研究领域以后培养某些研究生时,应该开电子信息、统计学等课程,应该借鉴社会学数据统计方法等等,在知识结构、特别是在研究方法和研究路径的设计上,弥补我们学科以往明显的欠缺。”[4]这是很有前瞻性的建议,可惜到今天也没有得到充分重视。之后《文学遗产》于2014年推出《加快“数字化”向“数据化”转变——“大数据”“云计算”理论与古典文学研究》,2015年又推出《大数据时代的古典文学研究——以数据分析、数据挖掘与图像检索为中心》,详细讨论“大数据”“云计算”对古代文学研究的助推意义。之后又有人发表《大数据背景下古代文学研究的新策略——以“小李杜”诗词研究为例》,认为“大数据会给古代文学的研究提供新的方法和视角”。
事实上,早在计算机普及之前,已经有多人通过数据分析的方式研究《红楼梦》前八十回和后四十回是否为一人所撰的问题,也提出了多种有价值的说法,这充分说明在古代文学研究领域,数据分析法早就得到应用。[5]在文艺学、网络文学和语言学研究领域,采用大数据推进学术研究,也渐渐成为热门话题,相关论文有《统计文艺学:大数据时代文学研究的新范式》(周才庶)、《大数据时代网络文学多维度评价方法及应用》(介晶)、《大数据时代的汉语语言学研究》(詹卫东)等,立足于当今的大数据时代,提出学科研究的新思维和新方法。但令人奇怪的是,检索中国知网,讨论大数据与中国现当代文学研究的论文,至今没有一篇。经过深度检索,《文学研究的大数据与小时代》(傅修海)一文涉及到大数据与当代文学研究的关系,但就文章的整体而言,依然谈的是大数据与文学研究的一般性问题,并不是专门针对当代文学研究而言的。熟悉学术史的人都很清楚,中国现当代文学研究自新时期以来,就一直处于新思维和新方法的潮头上,总能率先将西方的各种新潮理论应用到具体的文学史研究和文本分析之中,虽然因此也遭受一些诟病,但总体而言,现当代文学研究的先锋性是有目共睹的。但当我们进入大数据时代以后,就大数据给本学科研究可能带来的机遇与挑战,似乎始终处于不自觉状态,与相邻学科相比,明显落后了。所以今天我们来讨论这一问题就显得十分必要。
二、中国现当代文学研究的“数字化”与“数据化”
“大数据”时代,数据库建设是基础,没有数据库,就无从谈起“大数据”。与中国古代文学相比,现当代文学研究中的数据库建设明显滞后。就目前状况而言,中国现当代文学研究者常用的数据库主要是综合库:google books、中国知网、晚清民国期刊全文数据库(上海图书馆)、瀚文民国书库、爱如生民国大报库、大成老旧报刊数据库、台湾学术文献数据库等等,这些综合性数据库覆盖很多学科和专业,属于现当代文学学科的专业数据库则很少,北京大学出版社开发过可以检索的《新青年》数据库,但只能在光盘上使用,没有上线;重庆师范大学正在建设“大后方文学史料数据库”,目前尚不能使用。与之相比,古代文学的专题性数据库则有很多,如《四库全书》《四部丛刊》《历代石刻史料汇编》《十通》《国学宝典》《中国基本古籍库》《古今图书集成》《龙语瀚堂典籍数据库》《全唐诗》《全宋诗》等。而在现代文学研究领域,鲁迅研究虽为显学,但至今没有建成一个像样的数据库。所以现当代文学研究者及相关部门,开发建设专题性数据库,已迫在眉睫。但就目前已有的数据库而言,特别是现代文学研究者经常使用的“晚清民国期刊全文数据库”和“瀚文民国书库”,只是完成了将纸质图书变成图像的过程,只能根据作者、题名、来源等要素进行检索,基本上无法对全文进行统计和检索,这只是一个数字化的过程,还不能称为数据化。在这一点上,谷歌图书的做法很有代表性。“刚开始,谷歌所做的就是数字化文本,每一页都被扫描然后存入谷歌服务器的一个高分辨率数字图像文件中。书本上的内容变成了网络上的数字文本,所以任何地方的任何人都可以方便地进行查阅了。然而,这还是需要用户要么知道自己要找的内容在哪本书上,要么必须在浩瀚的内容中寻觅自己需要的片段。因为这些数字文本没有被数据化,所以他们不能通过搜索词被查找到,也不能被分析。谷歌所拥有的只是一些图像,这些图像只有依靠人的阅读才能转化为有用的信息。”[1]109-110随后谷歌使用了能识别数字图像的光学字符识别软件来识别文本的字、词、句和段落,如此一来,书页的数字化图像就完全数据化了,其功能和意义得到成倍增长。比如说通过检索鲁迅、郁达夫、郭沫若三个词在数据库中出现的频率在时间上的分布,就可以得到这样一个对比曲线图:
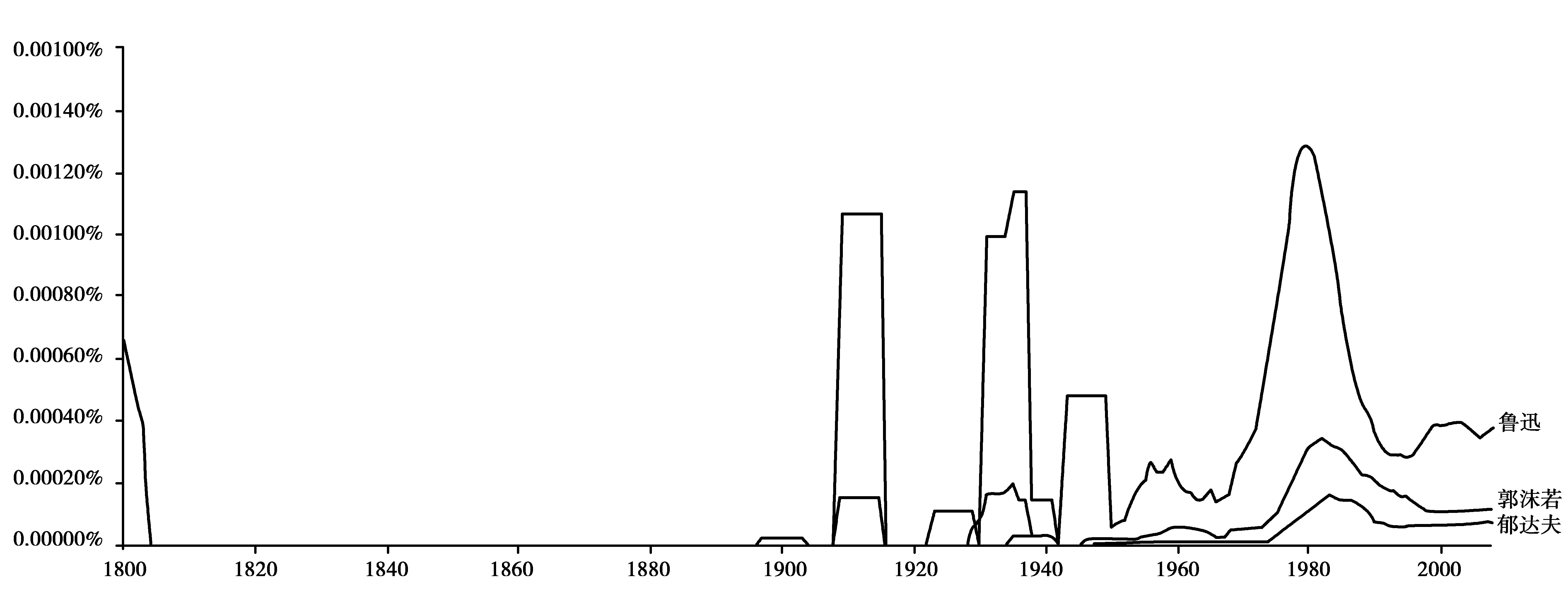
这就是“大数据”检索的结果,如果没有谷歌的“大数据”,我们很难清晰地看到这三个词在文献中出现的频率变化情况。根据这个图表,我们可以分析出很多有价值的问题。如鲁迅出现的两个高峰,一个显然是在1936年前后,因为他的逝世,他的名字频繁出现在各类文献中;一次是1980年代思想解放时期。同时通过对比,可以清楚地看出三个人中鲁迅出现的频率是最高的,而三个人出现的高峰似乎有着一致性,其中原因值得深思。
与谷歌将数字化图书数据化相比,中国大量的数据库都停留在数字化阶段,还没有完成数据化,这无疑影响了研究的深入和拓展。
三、“大数据”给现当代文学研究带来的新路径
依靠专业数据库或者大数据,现当代文学研究可以拓展出新的路径,会极大地改观研究的现状。“大数据”的特点就是“大而全”,不像过去那样只能靠抽样,正如有人指出的那样:“在大数据和云计算出现之前,自然科学抑或人文社会科学,都主要依赖抽样数据和局部数据,甚至在无法获取实证数据时只能依赖假设、经验理论等去推测。这些基于经验、理论或抽样数据的学术研究和理论探讨在未来相当长的时间内还将继续发挥其应有的作用。但是,这种方法所得到的结论,有可能是扭曲的认识或假象,具有一定的局限性。而基于大数据思维和方法分析所得到的结论,在把握问题的实质和分析其发展趋势方面显然具有极大的优越性。”[6]“大数据”带来的最为有效的研究就是通过对词频或字频的统计数据,进行关键词研究。金观涛和刘青峰撰写的《观念史研究:中国现代重要政治术语的形成》一书就是一次成功的尝试。两位作者通过“中国近现代思想史专业数据库(1830—1930)”“《新青年》数据库”等,统计出了“公理”“国民”“个人”“权利”等关键词的使用频率,借此理出了一条观念史的演变轨迹,令人耳目一新。在现当代文学研究领域,我们也可以采用数据统计的方法,查找“启蒙”“个人”“反帝”“反封建”等重要概念的使用频率,也可以从中看到中国文学观念的演变历程。除了对这些思想性关键词进行统计外,还可以对文学意象,尤其是诗歌意象进行统计,也能看出诗歌审美的变化。莫莱蒂还通过关键词统计的方法,研究过更为复杂的文学史问题。2013年,他出版《资产阶级:文学和历史之间》一书,通过对“有用”“有效”“舒适”“严重”“影响”等特定关键词出现频率的统计分析,来说明资产阶级文学的兴衰变迁,这已经不是简单的关键词分析了,而是指向了更为复杂的文学史现象。
莫莱蒂在斯坦福大学的“文学实验室”还通过对词语的统计,分析研究黑格尔的悲剧理论,也产生很大影响,其研究方法也值得借鉴。[7]另外,利用“大数据”可以解决的文学问题还有很多。像作家的地域分布、家庭背景、受教育经历等数据,对我们了解作家的成长与分布很有帮助。就以“文学与生活”的研究而言,如果能拿到书店的销售记录、图书馆的借阅记录以及手机阅读的相关数据,我们一定能从中分析出当前中国人阅读的整体状况,以及文学介入人们日常生活的深度。
就单个作家而言,可以通过词汇的分类统计分析,了解一个作家在不同时期或不同阶段对词汇的偏爱以及用语习惯等。有时可以借助语言统计,对一些可疑文本进行数据分析,以找到真正的作者。这方面国外有一个成功的案例。《哈利·波特》的作者J.K.罗琳匿名发表了一本小说《布谷鸟的呼唤》。随后牛津大学的Peter Millican和Duquesne大学的Patrick Juola通过一系列法律语言学的分析方法对比分析了这部小说和罗琳以往的写作风格,最后推测这部小说非常可能是罗琳的新作。最后罗琳承认此书是她亲笔创作。所以每个作家的作品,都带有自己的印记,就像人的DNA一样,可以通过细致的检测,找到这些个人特征,这为一些佚文或有争议文本的鉴定提供了条件。
“大数据”与“云计算”当前正处于高速发展和迅速普及的状态,它给人们带来的震撼及其潜在的价值和作用,目前还没有被我们充分意识到,所以率先采用“大数据”开展文学研究是适应时代发展的重要步骤。自然,“大数据”也是数据,文学研究需要感情的介入和富有个性的理解、阐释,通过冷冷的数据对文学进行“科学”的分析,自有其局限。但毫无疑问,“大数据”带来的新思维与新方法,必将给文学研究带来一场变革,也可能是一场革命。
[1] [英]维克托·迈尔—舍恩伯格,肯尼斯·库克耶.大数据时代——生活、工作与思维的大变革[M].盛杨燕、周涛译.杭州:浙江人民出版社,2013.
[2] 金雯,李绳.“大数据”分析与文学研究[J].中国图书评论,2014,(4).
[3] 陈晓辉.大数据时代的文学研究方法——基于弗兰克·莫莱蒂定量分析法的考察[J].文艺理论研究,2016,(2).
[4] 李铎,王毅.关于古代文献信息化工程与古典文学研究之间互动关系的对话[J].文学遗产,2005,(1).
[5] 陈大康.文学、数学与电子计算机[J].自然杂志. 1988,(12).
[6] 郑永晓.加快“数字化”向“数据化”转变——“大数据”“云计算”理论与古典文学研究[J].文学遗产,2014,(6).
[7] 周才庶.统计文艺学:大数据时代文学研究的新范式[J].文艺理论研究,2016,(5).
StudyforModernandContemporaryChineseLiteraturein“TheBigData”Era
Zhang Quanzhi Han Li
(School of Literature, Chongqing Normal University, Chongqing 401331;Qilu University of Technology, Library, Jinan Shandong 250353, China)
We’re in the era of “Big Data”. “Big Data” is changing our life, and our way of thinking, and the study of literature is entering a new era. According to the present situation, study for classic Chinese literature has achieved great accomplishment in the development and utilization of database, and that is convenient to own these adequate preparations. Comparatively speaking, study for modern and contemporary Chinese literature, to some degree, slow to respond the era of “Big Data”. And there’s no theoretic thinking or preparation on it. However, the change of new thinking way and the new method that were brought about by “Big Data” is irresistible for modern and contemporary Chinese literature, and it will certainly give rise to great change to study this subject.
big data;database;digitization;datamation
I2
A
1673—0429(2017)05—0005—05
[责任编辑:左福生]
