MPD:结点具有多个并行缓存一致性域的CC-NUMA系统
2017-11-07陈继承赵雅倩李一韩王恩东史宏志唐士斌
陈继承 赵雅倩 李一韩 王恩东 史宏志 唐士斌
(高效能服务器和存储技术国家重点实验室(浪潮集团有限公司) 北京 100085)
(chenjch@inspur.com)
缓存一致性维护是影响高速缓存一致性非均匀存储访问(cache coherence non-uniform memory access, CC-NUMA)系统性能的关键因素.早期的CC-NUMA系统中,处理器数量较少,各处理器间直接互连,系统采用单级一致性域设计即可满足系统性能需求.但随着系统规模的扩展,单级一致性域系统的处理器互连结构越来越复杂,消息全局性传播引发的网络阻塞延迟越来越大,缓存一致性维护开销急剧增长,严重影响系统性能与扩展性.因此,8路以上的CC-NUMA系统通常采用两级一致性域设计抑制缓存一致性维护开销,即:多个处理器互连组成结点后形成结点内一致性域,多个结点互连组成系统后形成结点间一致性域,两级一致性域间的协议转换通过一致性协同芯片(coherence chip, CC)实现[1-3].该方法可将一致性维护操作尽量限制在局部区域以避免一致性消息的全局传播,避免了单级一致性域造成的系统互连结构复杂、跨处理器访问跳步数多、高负载下阻塞延迟急剧增长等难题[4],从而使系统性能得到有效扩展.
受限于处理器的直连能力和处理器可识别的ID数,CC-NUMA系统所能构建的单结点规模有限,系统扩展只能通过增加结点数目来实现.但是,结点数目的增加会导致一致性目录存储开销上升、跨结点访问跳步数和延迟增大、系统规模无法进一步有效扩展.针对上述问题,当前CC-NUMA系统采用目录优化[5]、片外缓存扩展[6-8]、缓存数据预取[9-11]、一致性协议优化[12-14]等方法来降低跨结点访问频度,减少一致性开销.
然而,上述优化方法都是通过减少跨结点访问频度间接减少平均访问延迟,对系统拓扑结构没有改变,没有缩短跨结点访问路径和跳步数.针对该问题,本文提出了一种可任意配置结点内处理器规模的CC-NUMA系统——多并行缓存一致性域(multiple parallel cache coherency domain, MPD).该系统通过在结点内构建多个并行缓存一致性域来扩大单结点规模,使其不再受限于处理器直连能力和处理器可识别ID数,从而减少系统结点数量,简化系统拓扑结构,缩短访问路径和跳步数,直接减少系统平均访问延迟.同时,由于结点内的多个缓存一致性域之间是并行关系,连接至1个一致性协同芯片,共同构成结点内一致性域,所以,与传统CC-NUMA系统相比,MPD系统并未增加缓存一致性域的层级.
1 两级一致性域CC-NUMA系统
为减少缓存远端访问频率,降低缓存一致性维护开销,CC-NUMA系统通常将缓存资源划分为2个一致性同步域,使用两级缓存一致性协议对各一致性域进行一致性管理.图1是一个典型的多结点CC-NUMA系统,包含结点内一致性域和结点间一致性域的两级缓存一致性域.
1) 结点内一致性域.n个处理器与1个一致性协同芯片互连,构成结点内一致性域,维护的是本结点内n个处理器间的缓存一致性.
2) 结点间一致性域.M个结点通过一致性协同芯片互连,构成结点间一致性域,维护的是系统内各结点间的缓存一致性.
两级一致性域系统中,一致性协同芯片用于维护两级一致性协议的转换和维护,该芯片通常包含远端代理(remote proxy, RP)和本地代理(local proxy, LP)两个处理单元.
1) RP.结点一致性协同芯片的远端内存代理,存储远端地址数据在本地结点内处理器的一致性状态,监控本地处理器对远端地址的请求,可与本地处理器及远端结点一致性协同芯片的LP单元进行通信.
2) LP.结点一致性协同芯片的本地内存代理,存储本结点地址的数据在其他远端结点的一致性状态,监控远端结点对本地地址的请求,可与本地根目录及远端结点一致性协同芯片的RP单元进行通信.
侦听与目录是对缓存一致性信息的2种处理方式[15].由于侦听协议可扩展性差,所以,CC-NUMA系统多采用基于目录的缓存一致性协议.结点一致性协同芯片的缓存一致性目录记录了各缓存行的一致性状态(State)、共享列表(Share List)和写权限拥有者(Owner),按缓存数据地址的不同,分别由RP与LP单元维护与更新.
RP目录存储了远端数据在本结点的一致性状态信息,目录项如图2所示:
1) State——状态位,记录远端数据在本结点的一致性状态,其长度与协议有关,如MI协议占用1 b,MESI协议占用2 b;
2) Share List——共享列表,记录远端数据在本地结点内处理器的一致性状态,其长度与目录实现技术有关,如全映射目录[3]的共享列表长度为n;
3) Owner——写权限拥有者,记录远端数据在本结点内处于ME态的处理器ID,其长度为n.
LP目录存储了本地数据在远端结点的一致性状态信息,目录项如图3所示:
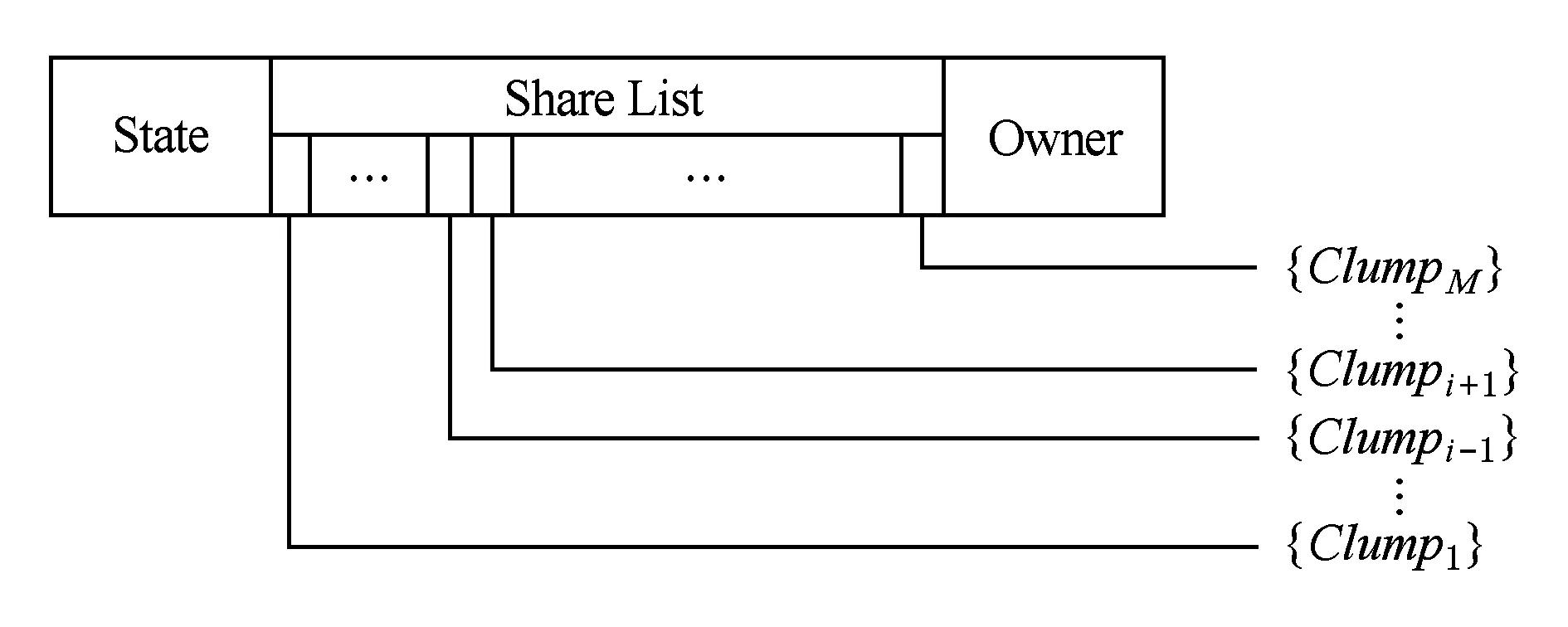
Fig. 3 LP directory entry in CC-NUMA system图3 CC-NUMA系统结点一致性协同芯片LP目录项
1) State——状态位,记录本地数据在本结点的一致性状态;
2) Share List——共享列表,记录本地数据在本结点i之外的所有远端结点的一致性状态,全映射目录的共享列表长度为M-1;
3) Owner——写权限拥有者,记录本地数据在远端结点处于ME态的远端结点ID,其长度为M-1.
2 MPD系统
2.1 MPD系统结构
MPD系统是一个结点内包含多个并行缓存一致性域的CC-NUMA系统.如图4所示,n个处理器与结点一致性协同芯片紧耦合互连,构成1个缓存一致性域(cache coherence domain, CCD);k个缓存一致性域并行连接至1个结点一致性协同芯片,共同构成结点内一致性域;m个结点通过结点一致性协同芯片互连,构成结点间一致性域,m=Mk.与图1的CC-NUMA系统相比,图4的MPD系统结点数量缩减为原系统的1k.
MPD系统中,结点内的多个缓存一致性域并行连接至1个一致性协同芯片,并由该协同芯片统一维护其结点内的缓存一致性,也就是说,这些并行的缓存一致性域并不单独维护一致性域.所以,MPD系统的一致性域设计与CC-NUMA系统相同,都是结点内结点间两级一致性域架构,使用两级缓存一致性协议,两级一致性域间的协议转换通过一致性协同芯片实现.
1) 结点内一致性域.k个缓存一致性域与1个一致性协同芯片互连,构成结点内一致性域,由本结点的一致性协同芯片统一维护结点内nk个处理器间的缓存一致性.
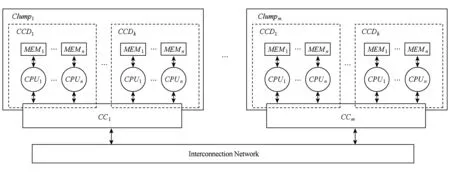
Fig. 4 MPD system with multiple clumps图4 多结点MPD系统
2) 结点间一致性域.m个结点通过一致性协同芯片互连,构成结点间一致性域,由各结点的一致性协同芯片共同维护系统各结点间的缓存一致性.
与CC-NUMA系统类似,MPD系统的结点一致性协同芯片也包括远端代理RP和本地代理LP这2个处理单元,但逻辑功能和通信单元略有差异,主要是对LP进行了功能扩展,以同时维护结点内所有处理器的缓存一致性.
1) RP.结点一致性协同芯片的远端内存代理,存储远端地址数据在本地结点内(含本结点内所有缓存一致性域)处理器的一致性状态,监控本结点内所有处理器对远端地址的请求,可与本结点内处理器或远端结点一致性协同芯片的LP单元进行通信.
2) LP.结点一致性协同芯片的本地内存代理,存储结点内各缓存一致性域的本地数据在本结点内其他缓存一致性域各处理器以及系统内所有远端结点的一致性状态,监控各缓存一致性域对结点内其他缓存一致性域的请求以及远端结点对本地地址的请求,可与本结点内处理器、根目录以及远端结点一致性协同芯片的RP单元进行通信.
从CC-NUMA与MPD系统中RP与LP的逻辑功能对比来看,MPD系统中的RP与LP单元需要存储更多处理器的一致性状态信息,所以需要对CC-NUMA系统的一致性协同芯片目录的共享列表进行扩展.
RP目录存储了远端数据在本结点内所有并行缓存一致性域的一致性状态信息,目录项如图5所示.
1) State——状态位,记录远端数据在本结点的一致性状态;
2) Share List——共享列表,记录远端数据在本地结点所有缓存一致性域内处理器的一致性状态,全映射目录的共享列表长度为nk;
3) Owner——写权限拥有者,记录远端数据在本结点内处于ME态的处理器ID,其长度为lb(nk).
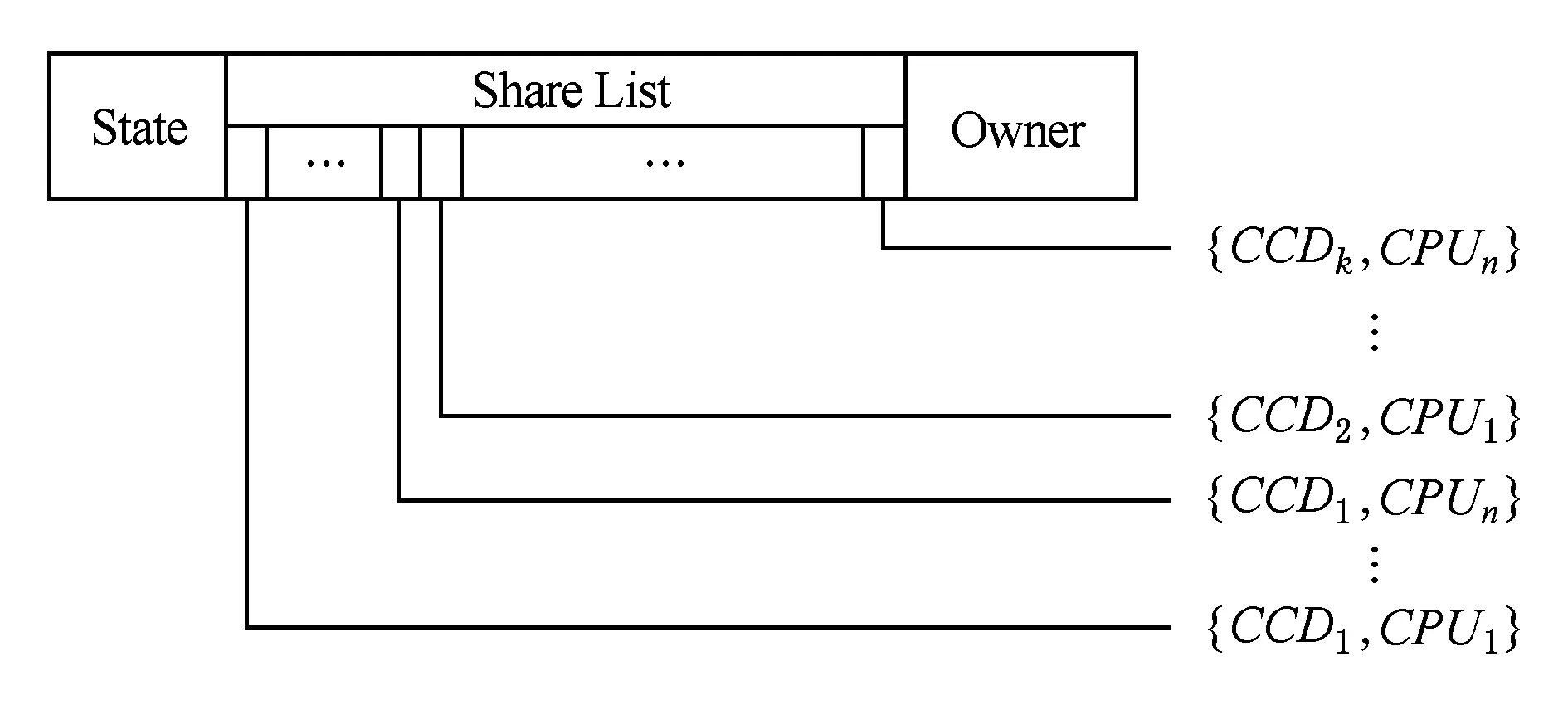
Fig. 5 RP directory entry in MPD system图5 MPD系统RP目录项
LP目录存储了本结点各缓存一致性域的本地数据在结点内其他并行缓存一致性域以及系统远端结点的一致性状态信息,目录项如图6所示.
1) State——状态位,记录本地数据在本结点的一致性状态;
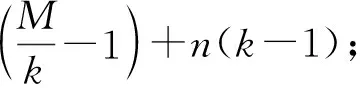
3) Owner——写权限拥有者,记录本地数据在远端结点处于ME态的远端结点ID,或缓存一致性域本地数据在结点内其他缓存一致性域处于ME态的处理器ID,长度为
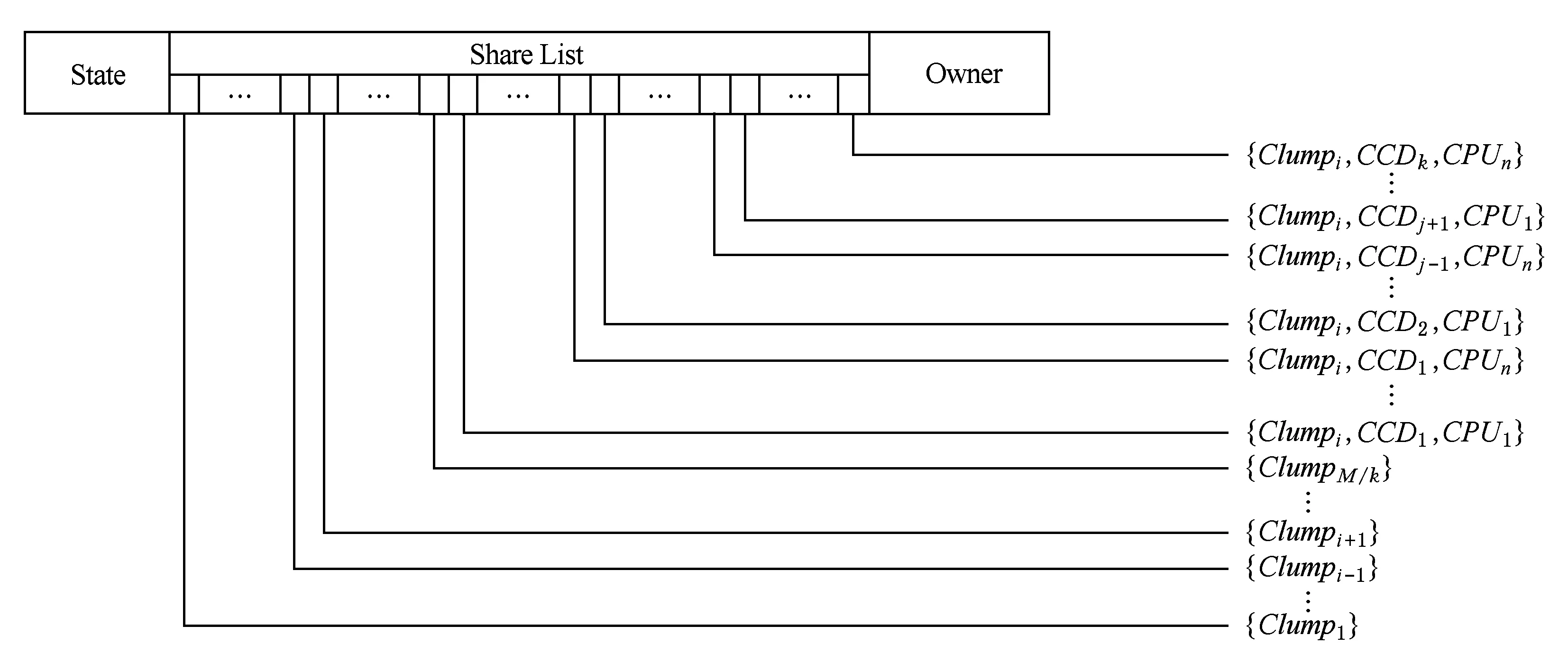
Fig. 6 LP directory entry in MPD system图6 MPD系统LP目录项
2.2 MPD系统的缓存一致性访问
虽然MPD系统与CC-NUMA系统的缓存一致性域层次相同,但两者的系统架构不同,因此,2种系统的缓存一致性交互流程略有不同.
1) 缓存一致性域内访问
MPD系统与CC-NUMA系统的缓存一致性域结构相同,都是由多个处理器与一致性协同芯片互连而成,因此,两者的缓存一致性域内访问流程相同,均为CPU与根目录直接交互,如图7所示:
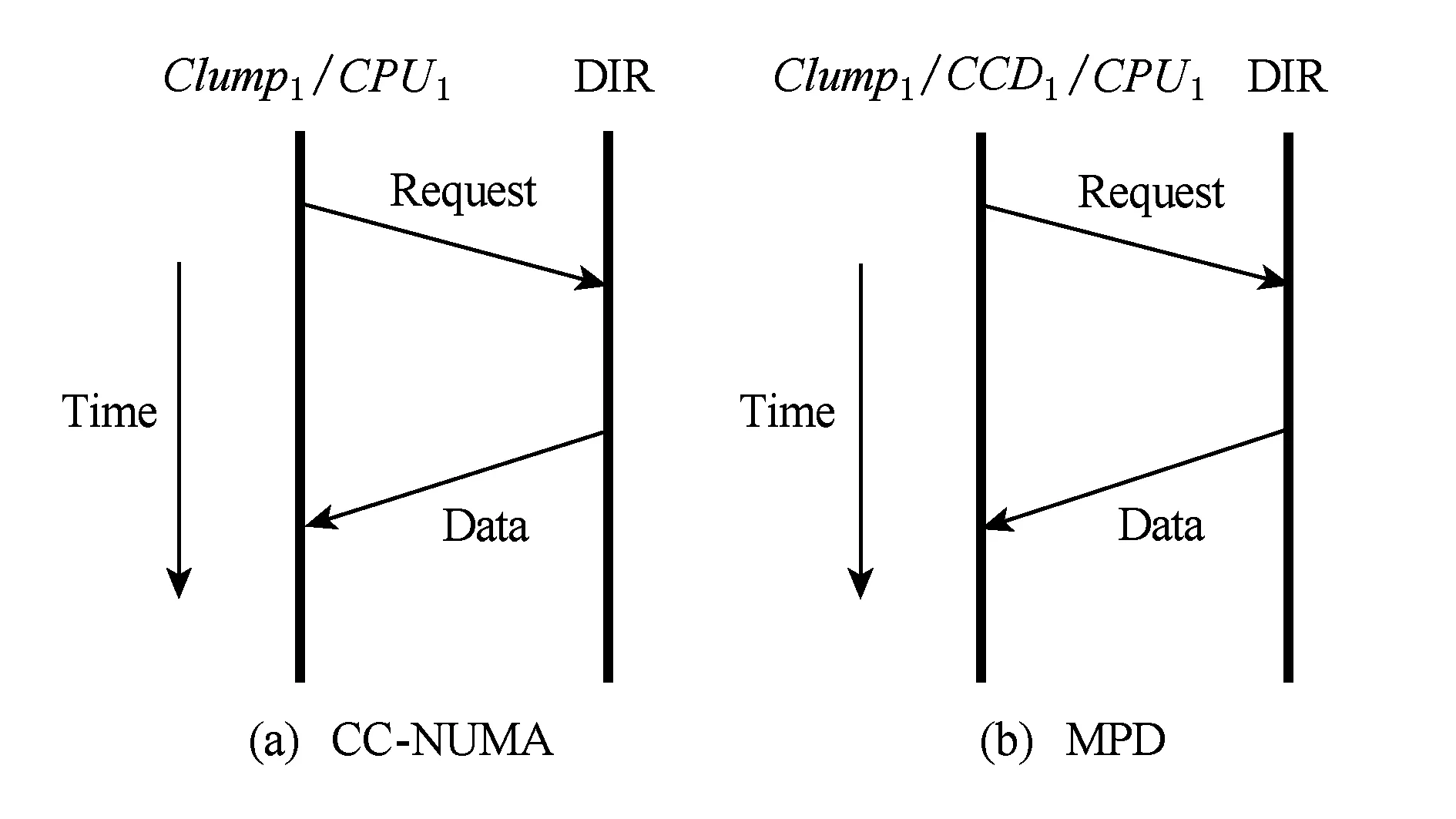
Fig. 7 Access within the same CCD in CC-NUMA or MPD system图7 CC-NUMA系统与MPD系统的缓存一致性域内访问
2) 缓存一致性域间访问
CC-NUMA系统内,结点内一致性域由单个缓存一致性域构成,所以,缓存一致性域间访问即为结点间一致性访问,如图8所示:
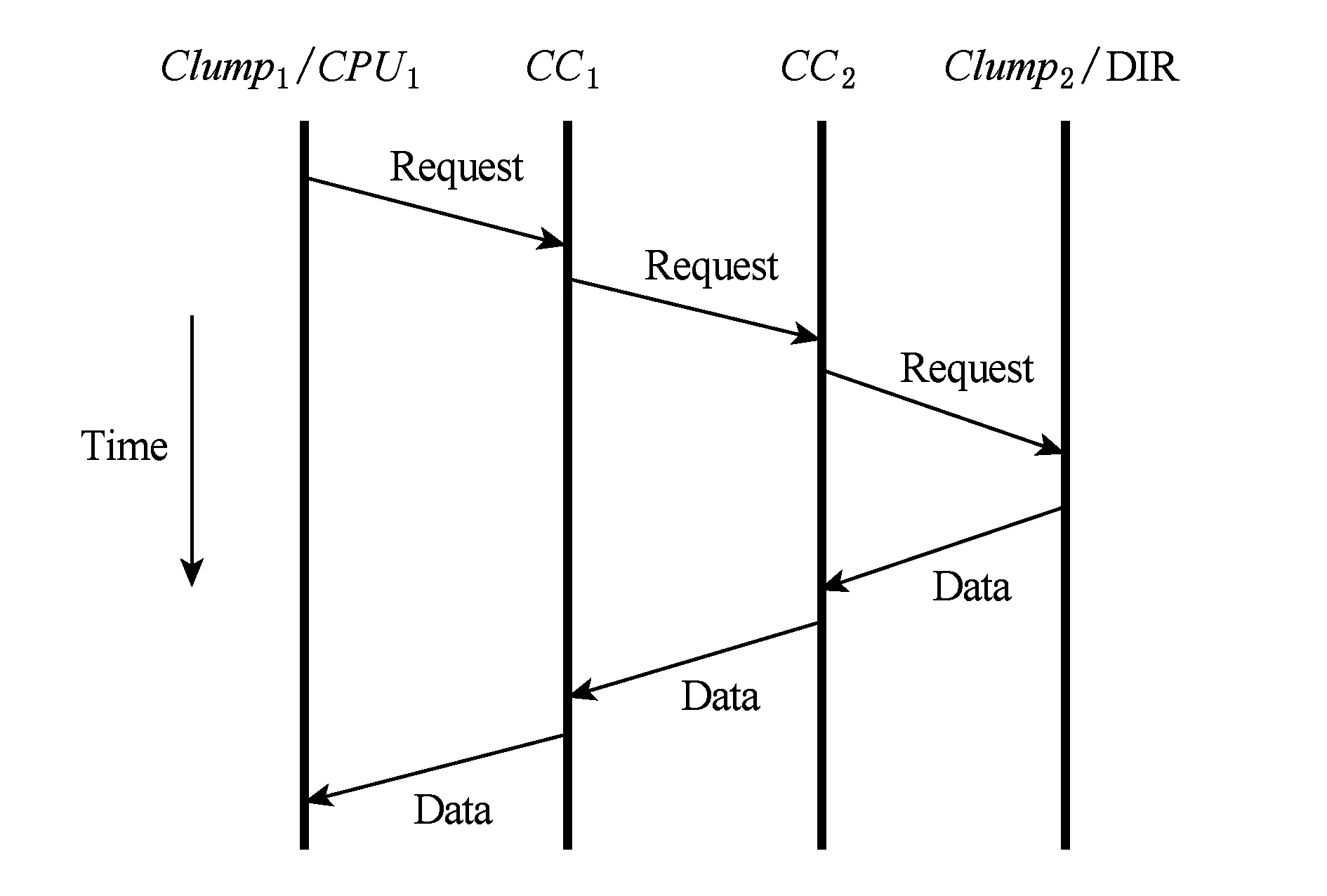
Fig. 8 Access between different CCDs in CC-NUMA system图8 CC-NUMA系统的缓存一致性域间(结点间)访问
MPD系统内,单个结点一致性域内包含多个缓存一致性域,因此,MPD系统的缓存一致性域间访问包含了结点内的缓存一致性域间访问和结点间的缓存一致性域间访问2种类型,如图9所示:

Fig. 9 Access between CCDs in MPD system图9 MPD系统的缓存一致性域间访问
图9(a)描述了MPD系统独有的结点内跨缓存一致性域访问,它将CC-NUMA系统中的远端跨结点访问转换为近端结点内跨域访问,仅与本地一致性协同芯片进行交互;图9(b)描述了与CC-NUMA系统相同的结点间的缓存一致性域间访问,需与本地一致性协同芯片及远端一致性协同芯片进行交互.
从2种系统的缓存一致性交互流程描述来看,MPD系统中的缓存一致性访问分为3类:
1) 结点内的缓存一致性域内访问.该类访问对应CC-NUMA系统的结点一致性内访问(即缓存一致性域内访问),两者开销相同.
2) 结点内的缓存一致性域间访问.该类访问对应CC-NUMA系统中的结点间访问,前者仅通过本地CC即可进行交互,而后者需要通过本地CC与远端CC才可进行交互,前者开销小于后者.
3) 结点间的缓存一致性域间访问.该类访问对应CC-NUMA系统中的结点间访问,两者开销相同.
因此,与CC-NUMA系统相比,MPD系统并未产生额外的一致性开销,并将部分结点间访问转换为结点内访问,直接缩短了访问路径与跳步数,从而降低系统平均访问延迟,减少一致性维护开销,提升系统性能.
3 MPD系统性能分析
3.1 结点规模分析
MPD系统通过在结点内构建多个并行缓存一致性域突破了单结点规模限制,减少了结点数量,从而降低了结点规模和结点间网络复杂度.
假设某系统规模(即处理器总数)为N,单个缓存一致性域内最多容纳处理器数量为n,那么,传统CC-NUMA系统和MPD系统的结点数Num_C以及结点间全互连的连接数T分别为
Num_CCC-NUMA=Nn,
(1)
TCC-NUMA=N(N-n)2n2,
(2)
Num_CMPD=Nnk,
(3)
TMPD=N(N-nk)2(nk)2,
(4)
其中,k为MPD系统中单个结点内包含的并行缓存一致性域个数.
由式(1)~(4)可以得出,同等系统规模下,传统CC-NUMA系统和MPD系统的结点数量的比值ηNum_C为
(5)
结点间全互连的连接数比值ηT为
(6)
因此,与传统CC-NUMA系统相比,MPD系统的结点规模可缩减至1k,结点间全互连的连接数可降低到1k2以下.例如,当N=64,n=4,k=2时,MPD系统的结点规模降低50%,结点间全互连的连接数降低77%;而当N=64,n=4,k=4时,MPD系统的结点规模降低75%,结点间全互连的连接数降低95%.
3.2 平均访问延迟分析
由于同一结点内不同缓存一致性域间的近端跨域访问延迟远小于不同结点间的远端跨结点访问延迟,所以MPD系统的平均访问延迟低于CC-NUMA系统,如图10所示:
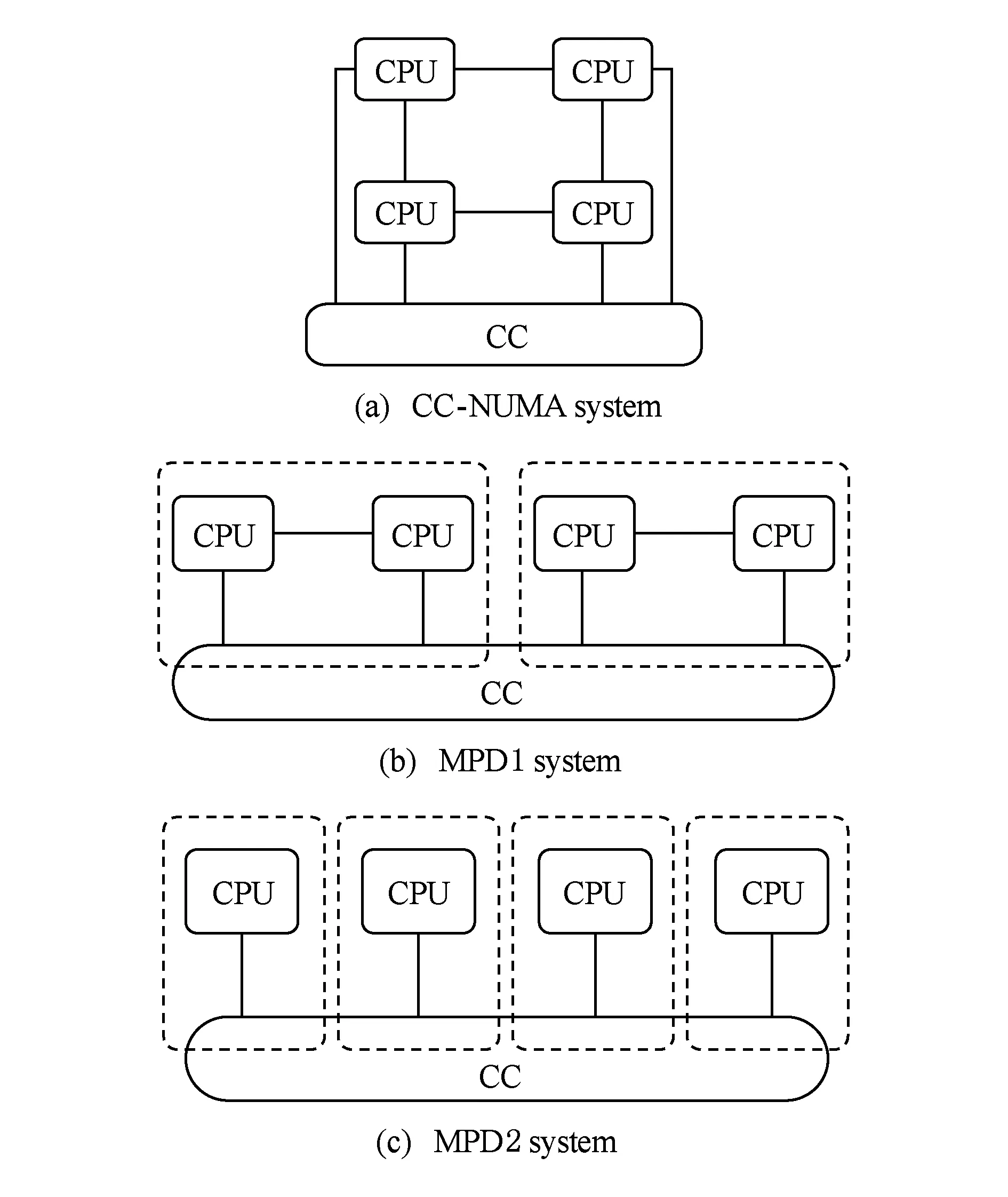
Fig. 10 Clump architecture in different systems built with different CPU图10 不同规格处理器搭建的系统单结点架构
假设MPD系统中同一缓存一致性域内的平均访问延迟为l,同一结点内不同缓存一致性域间的平均访问延迟为3l,不同结点间的平均访问延迟为7l,缓存一致性域内的缓存次数占比为α,近端结点内跨域的访问次数占比为β,那么,MPD系统的远端跨结点的访问次数占比为1-α-β,而相同规模的CC-NUMA系统的远端跨结点的访问次数占比为1-α.因此,同规模的MPD系统与CC-NUMA系统的平均访问延迟L分别为
LMPD=l×α+3l×β+7l×(1-α-β)=
l×(7-6α-4β),
(7)
LCC-NUMA=l×α+7l×(1-α)=l×(7-6α).
(8)
① 该结论仅针对大规模CC-NUMA系统,单结点等小规模系统不保证不等式结论成立.
由式(7)(8)可得2种系统平均访问延迟的比值为
(9)
假设α=10%,β=30%,则2种系统的平均访问延迟之比为1316=0.812 5,即MPD系统的平均访问延迟降低了近2成,有效提高了系统性能.
3.3 结点一致性目录存储开销分析
CC-NUMA系统中,每个缓存一致性域单独维护1个结点一致性目录,结点数量较多,系统的结点一致性目录开销较大;而MPD系统中,多个并行缓存一致性域共同维护1个结点一致性目录,结点数量较少,系统的结点一致性目录开销较小.
以MESI(modified,exclusive, shared or invalid)协议的全映射目录结构为例,假设MPD系统规模为N,单个缓存一致性域内最多容纳处理器数量为n,每个结点内共有k个缓存一致性域,内存容量为B,缓存项大小为b,则该系统内单个结点一致性目录开销为
(10)
该MPD系统内所有结点的一致性目录总开销为

(11)
同等规模的传统CC-NUMA系统内单个结点目录开销为
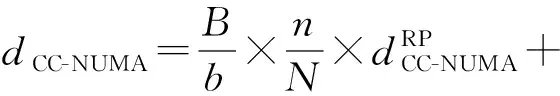
(12)
该CC-NUMA系统内所有结点的一致性目录总开销为
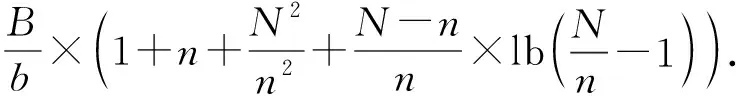
(13)
由式(11)(13)可得,传统CC-NUMA系统与MPD系统的结点一致性目录总开销的差值ΔD为
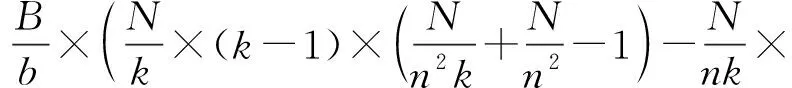
因为在大规模CC-NUMA系统中,
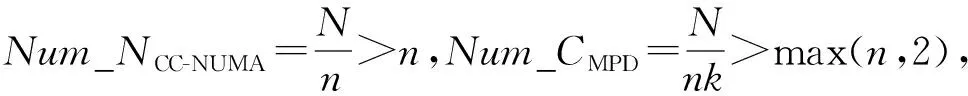
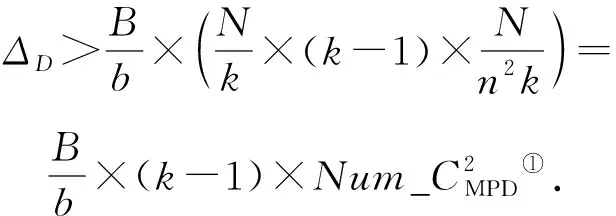
因此,对于大规模CC-NUMA系统,同等规模的MPD系统的结点目录开销更小,而且,内存容量越大,目录开销降低的幅度越大.
以64颗处理器组成的CC-NUMA系统为例,假设每个缓存一致性域内最多可容纳2颗处理器,系统内存容量为16 GB,单个缓存项大小为128 KB.那么传统CC-NUMA系统共需32个结点一致性协同芯片,目录开销为[8×(1 027+31×lb 31)]Mb,约为9.223 Gb;而单结点内含2个并行缓存一致性域的MPD系统仅需16个结点一致性协同芯片,目录开销为[8×(293+15×lb 17)]Mb,约为2.768 Gb,不到CC-NUMA系统目录开销的13;单结点内含4个并行缓存一致性域的MPD系统仅需8个结点一致性协同芯片,目录开销为[8×(118+7×lb 13)]Mb,约为1.124 Gb,不到CC-NUMA系统结点目录开销的18.
3.4 系统构建成本与功耗分析
MPD系统中,单结点规模不再受处理器直连能力的限制,因此,可以选用直连能力较弱的处理器代替直连能力较强的处理器搭建同等结点规模的系统,以降低系统成本与功耗.不同直连能力的处理器价格和功耗差异较大.支持8路直连的处理器有3个一致性互连端口,功耗约为130 W,单价约为2 500美元;支持4路直连的处理器有2个一致性互连端口,功耗为115 W,单价为2 000美元;而支持2路直连的处理器仅有1个一致性互连端口,功耗为100 W,单价为1 500美元.
假设要搭建8结点的32路系统,传统CC-NUMA系统需要32颗具有8路直连能力的处理器,结点内结构如图10(a)所示;而结点内含2个并行缓存一致性域的MPD1系统则只需要32颗具有4路直连能力的处理器,结点内结构如图10(b)所示;结点内含4个并行缓存一致性域的MPD2系统仅需要32颗具有2路直连能力的处理器,结点内结构如图10(c)所示.
假定一致性协同芯片的单价为1 000美元,那么,CC-NUMA,MPD1,MPD2这3种8结点32路系统的硬件成本和处理器功耗如表1所示.相比于传统CC-NUMA系统,单结点内含2个并行缓存一致性域的MPD1系统可降低功耗11.5%,降低成本20%;单结点内含4个并行缓存一致性域的MPD2系统可降低功耗23.1%,降低成本40%.
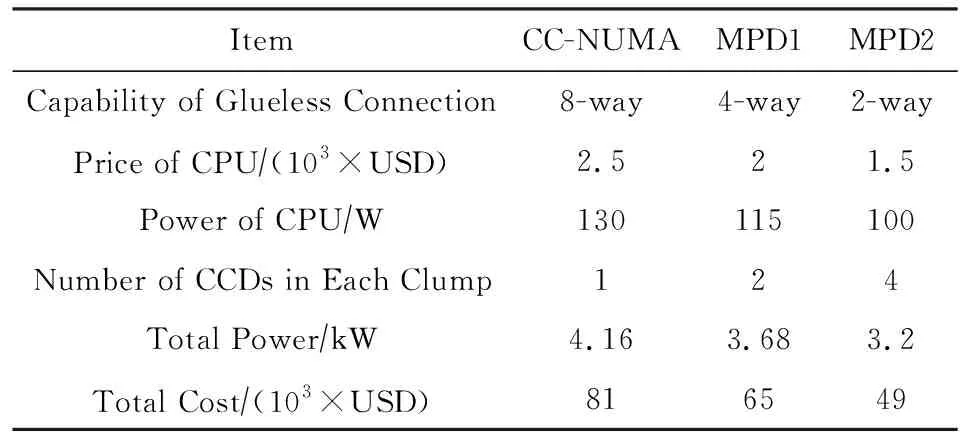
Table 1 Comparison of Power and Cost AmongDifferent Systems
① 本文实验设置较小的内存容量是为了避免部分缓存密集访问,以便更好地模拟大规模系统的多结点间的缓存一致性维护.
4 系统性能模拟
4.1 实验平台
本文选用gem5[16]对两级缓存一致性域的MPD系统和CC-NUMA系统进行模拟,模拟系统中,系统结点无结点缓存功能,对接收的消息均做转发处理.各级访问延迟比为∶缓存域内访问延迟∶结点内访问延迟∶结点间访问延迟=1∶3∶7.实验的主要系统参数如表2所示.实验测试程序选用了SPLASH2[17]的1个内核程序和3个应用程序,以及PARSEC[18]中的3个应用程序,各配置如表3所示.

Table 2 Parameters of System Configuration表2 系统参数配置
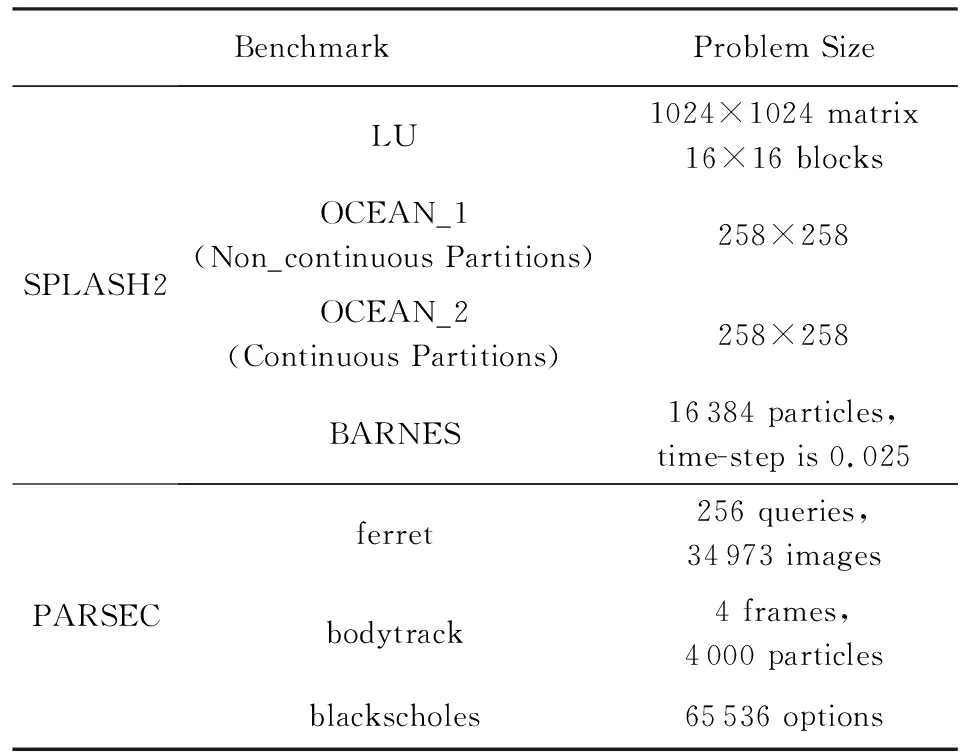
Table 3 Benchmark SPLASH2 and PARSEC表3 测试集SPLASH2与PARSEC
为验证MPD系统对系统性能有效扩展能力的提升,以及低功耗低成本MPD系统构建的可行性,本节分别对16路、32路和64路的传统CC-NUMA系统与不同配置的MPD系统进行了对比测试.测试实验数据显示,不同处理器规模的系统对比结果类似.因此,为了避免重复,本节仅选用32路系统的对比测试数据进行说明.另外,为便于数据比较的直观性,各组数据均以传统CC-NUMA的系统性能为标准进行了归一化处理.
4.2 同规格处理器下的系统性能对比
4.2.1 平均访问延迟对比
图11显示了CC-NUMA系统与各MPD系统中不同类型访问的数量占比.图11中的横坐标m×k代表了系统的缓存一致性域规模:m代表结点数,k代表单结点内缓存一致性域数量.因此,m×1就代表了结点数为m的CC-NUMA系统.从图11中各类访问占比来看,由于MPD系统扩大了单结点处理器规模,有效减少了结点数量,部分结点间远端访问转换为结点内跨域近端访问,而且,单结点处理器规模越大,转换为结点内跨域访问的结点间访问量越多.图11中结点间访问量减少最多的是OCEAN_NS.当单结点内有8个并行缓存一致性域时,OCEAN_NS有58%的结点间访问转换为结点内跨域访问.

Fig. 11 Comparison of the access ratio among different 32-way systems图11 32路CC-NUMA系统与MPD系统的各类型访问量对比
因为结点内跨域访问延迟远小于结点间访问延迟,所以结点间访问数量的减少直接降低了系统平均访问延迟.例如,单结点内有8个并行缓存一致性域时,OCEAN_NS的系统平均访存延迟降低32%.从图12的对比结果来看,系统平均访问延迟的变化趋势与结点间访问占比类似,均随结点内缓存一致性域数量k的增加而减少.当k=2时,与CC-NUMA系统相比,MPD系统的平均访问延迟降低3.9%;当k=4时,与CC-NUMA系统相比,MPD系统的平均访问延迟降低11.7%;当k=8时,与CC-NUMA系统相比,MPD系统的平均访问延迟降低27.9%.
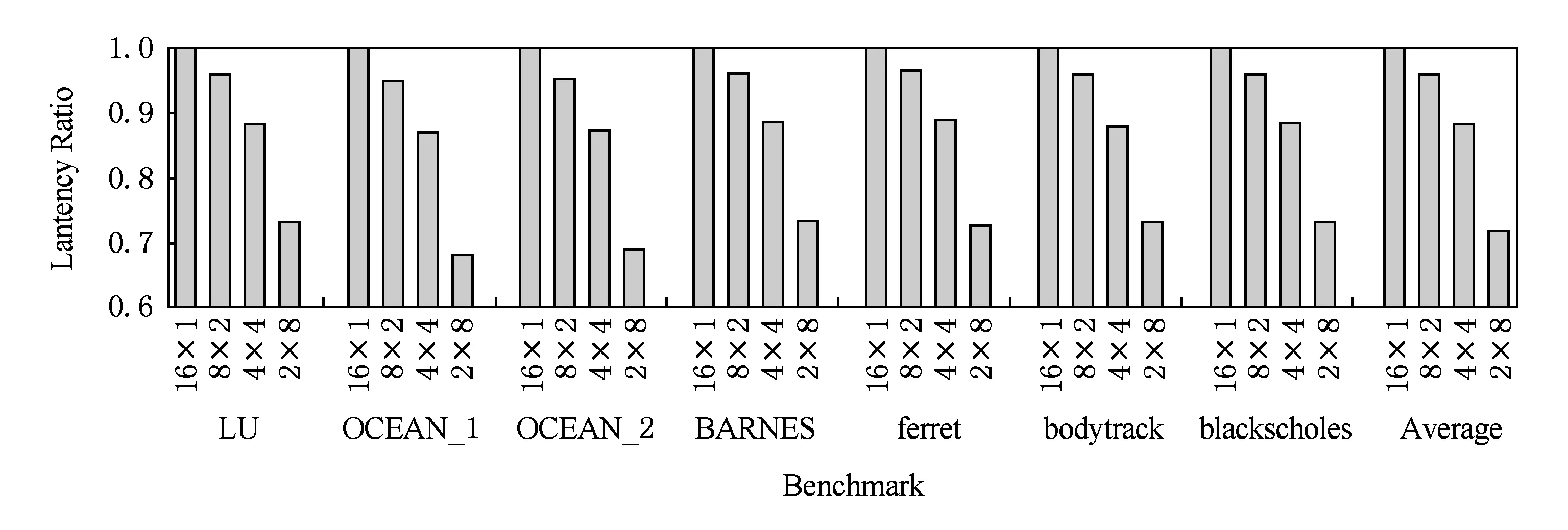
Fig. 12 Comparison of the average access latency among different 32-way systems图12 32路CC-NUMA系统与MPD系统的平均访问延迟对比
4.2.2 指令平均执行周期对比
相较于系统平均访问延迟,CC-NUMA系统和MPD系统的指令平均执行周期(cycles per instruction,CPI)差异较小,但仍是MPD系统性能较优,且系统CPI随结点内缓存一致性域数量k的增加而减少.这主要是因为,系统平均访问延迟仅与访问类型占比有关,而CPI还与程序指令数、指令类型等有关.图13中各程序的CPI变化幅度不同也是因为这个原因.尽管各测试程序的CPI降幅不同,但MPD系统整体平均性能仍呈现较明显的线性下降趋势:当k取值为2,4,8时,MPD系统比传统CC-NUMA系统的CPI分别降低3.6%,7.6%,12.6%,即MPD系统性能提升3.5%,8.2%,14.4%.
4.3 不同规格处理器的系统性能对比
本文3.4节所述,MPD系统中可采用直连能力较弱的处理器代替直连能力较强的处理器搭建同等规模的系统,以降低功耗、节约成本.但是,MPD系统采用的是单结点内多缓存一致性域架构;原CC-NUMA系统中的部分缓存一致性域内访问将转换为结点内跨一致性域访问,从而导致系统平均访问延迟增加,性能下降.
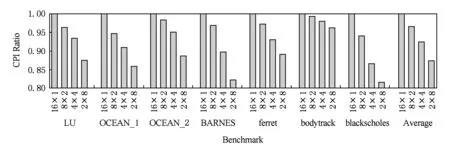
Fig. 13 Comparison of CPI among different 32-way systems图13 32路CC-NUMA系统与MPD系统的CPI对比
为测试这种低功耗低成本的MPD系统与传统CC-NUMA系统的性能差异度,本节对不同规格处理器搭建的4结点16路系统、8结点32路系统和16结点64路系统进行了性能测试.各组测试数据均表明,与传统CC-NUMA系统相比,采用较低规格处理器搭建的MPD系统性能下降有限.以图14中的32路系统为例,当处理器为4路直连时,每个结点内有2个缓存一致性域,系统CPI上升1.7%;当处理器为2路直连时,每个结点内有4个缓存一致性域,系统CPI上升2.6%,上升幅度变小.
与表1中处理器硬件成本的下降程度相比,这种MPD系统的性能下降幅度较小,因此,使用低规格处理器搭建的MPD系统具有更高的性价比.如图15所示,与8路直连处理器搭建的CC-NUMA系统相比,4路直连处理器搭建的32路MPD系统性价比提升1.20倍,2路直连处理器搭建的32路MPD系统性价比提升1.53倍.

Fig. 14 Comparison of CPI among 8 clumps 32-way systems built by different processors图14 不同处理器搭建的8结点32路系统的CPI对比

Fig. 15 Cost-effective of different systems图15 不同处理器系统的性价比
5 结 论
处理器直连能力和处理器可识别ID数的有限性限制了CC-NUMA系统的单个结点规模,导致系统规模的扩张只能通过结点数量的增加来实现.而结点数量的增加致使缓存一致性维护开销增大,结点间互连结构复杂,降低了系统性能的有效扩展.本文提出的MPD系统突破了单结点的处理器规模限制,能够任意设置单结点规模,大幅减少结点数量.与其他系统性能优化方法相比,这种扩大单结点规模的方法直接缩短了系统平均访问路径和跳步数,从而降低了平均访问延迟,实现了系统性能的有效扩展.另一方面,由于MPD系统的单结点规模与处理器直连能力无关,MPD系统还可用于构建低功耗低成本系统,提升系统性价比.实验数据表明,32路系统中,采用同规格处理器时,结点内4个并行缓存一致性域的MPD系统平均访问延迟降低27.9%,系统性能提升14.4%;采用不同规格处理器时,与8路直连处理器搭建的CC-NUMA系统相比,2路直连处理器搭建的MPD系统性价比提升1.53倍.
未来的工作中,我们将增加结点缓存功能,进一步优化MPD系统的一致性协议实现,提升大规模系统性能.
