基于隐私保护的数据挖掘综述
2017-11-02姜美
姜美
(广州市轻工技师学院广州市轻工高级技工学校,广东 广州 510642)
基于隐私保护的数据挖掘综述
姜美
(广州市轻工技师学院广州市轻工高级技工学校,广东 广州 510642)
无线网络及云计算的普及对网络中用户的隐私构成巨大的威胁,这凸显了基于隐私保护的数据挖掘方法的重要性和迫切性。本文比较了几种颇为典型的用于隐私保护的数据挖掘方法,并概述了国内关于这些方法的研究动向,总结出关于隐私保护的数据挖掘方法所面临的挑战。
数据挖掘;隐私保护;安全
1 引言
随着数据的爆炸式增长以及数据来源的共享性和分布式特点,组织之间对合作式和互为有利的分析资料的需求正日益迫切,随之而来的是对共享型数据的隐私破坏的忧虑,可能会对组织之间造成严重的法律和战略后果[1]。隐私保护是数据挖掘和数据集成面对的一个重要问题[2]。本文探讨几类主要的隐私保护数据挖掘方法与技术,在文章第二部分阐述与隐私保护数据挖掘的相关概念,详细介绍各类隐私保护数据挖掘方法并予以比较,第三部分概述了当前国内关于隐私保护数据挖掘的现状,第四部分说明隐私保护数据挖掘方法与技术的发展所遭遇的困境,最后对全文进行总结并对隐私保护数据挖掘的研究趋势作出展望。
2 隐私保护的数据挖掘方法
在具体应用中,隐私即为数据所有者不愿意被披露的敏感信息,包括敏感数据以及数据所表征的特性。通常我们所说的隐私都指敏感数据,如个人的薪资、病人的患病记录、公司的财务信息等[3]。数据挖掘是通过仔细分析大量数据来揭示有意义的新关系、趋势和模式的过程,是数据库研究中是一门交叉性学科,融合了数据库技术、模式识别、机器学习和统计学等多个领域的理论和技术[5]。
隐私保护的数据挖掘方法按照基本策略主要可分为数据干扰[6-9]和查询限制[10-13]两大类。数据干扰策略就是首先通过数据变换、数据离散化和在数据中增加噪声等方法对原始数据进行干扰,然后再针对经过干扰的数据进行挖掘,得到所需的模式和规则;查询限制则是通过数据隐藏、数据抽样和数据划分等方式,避免数据挖掘者拥有完整的原始数据,而后再利用概率统计等方法得到所需的挖掘结果。
2.1 数据预处理方法
数据预处理法的主要思想是在数据预处理阶段删除数据中最敏感的某些字段,如姓名和证件号码等,或在数据集中随机添加、修改和转换某些字段的数据,这些数据能起到干扰作用,从而避免隐私泄露。
2.2 关联规则
关联规则是寻找在同一事件中出现的不同项目的相关性,关联分析是挖掘关联规则的过程。一个关联规则是形如X⇒Y的蕴涵式,这里X⊂I,Y⊂I,并且X⋂Y=ϕ[14]。
2.3 决策树
决策树是利用树的结构分类数据记录,树的叶结点就代表某个条件下的记录集,根据记录文段的不同取值建立树的分支;在每个分支子集中重复建立下层结点和分支,便可生成一棵决策树[15]。隐私保护的决策树挖掘研究主要还是针对传统决策树进行的,大都选用ID3类算法作为原型算法。
2.4 K-匿名
Samarati P和Sweeney在1998年提出K-匿名技术,要求公布后的数据中存在一定数量不可区分的个体,使得攻击者不能判别出隐私信息所属的具体个体,从而防止泄露个人隐私[16]。使用K-匿名技术需要处理数据中的显示标识符和非显示标识符。
2.5 朴素贝叶斯分类器
贝叶斯定理是由英国数学家Tomas Bayes提出的,它是一种把先验知识与样本中得到的新信息相结合的统计方法,在分类中得到了比较广泛的应用。朴素贝叶斯分类器表示为:
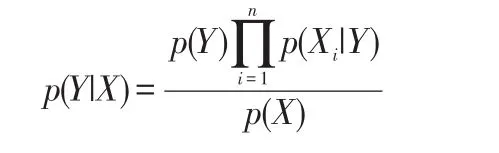
其中,p(X)是常数,先验概率p(Y)可以通过训练集中每类样本所占的比例进行估计。给定Y=y,如果要估计测试样本X的分类,由朴素贝叶斯分类器得到y类的后验概率。
2.6 聚类算法
聚类是把对象或样本的集合分组成为多个簇的过程,使同一个组中具有较高的相似度的对象,而不同类的对象差别较大。聚类算法能有效处理噪声数据、异常数据和高维数据,产生满足指定约束的聚类结果,通过增加噪声可对原始数据进行数据干扰来保护隐私数据。隐私保护的数据挖掘方法比较如表1所示。

表1 隐私保护的数据挖掘方法比较
3 国内外研究现状
周水庚等归纳总结出当前国内的隐私保护研究方向为:通用的隐私保护技术,如Perturbation[18],Swapping[19],Encryption[20];面向数据挖掘的隐私保护技术:如Association Rule Mining[21-23],Classification[24,25],Clustering[26];基于隐私保护的数据发布原则:如k-anonymity[27,28],l-diversity、t-Closeness[29];隐私保护算法:如Anonymized Publication[30-33],Anonymization with High Utility[34]。
3.1 数据预处理研究现状
关于数据预处理的研究,国内的学者主要从数据预处理的应用及算法研究两个方向。刘亮等在Apriori算法的基础上提出基于数据项闲包的、为保密数据挖掘进行数据预处理的全新方法,有效地解决数据提供方不完全信任挖掘请求方,通过提供经变换过的数据库给对方挖掘来获得利益,以及明确对方在挖掘过程中使用的是类Apriori算法的问题[35]。刘明吉等综合分析了数据挖掘中的数据预处理的基本功能包括数据集成、数据清理、数据变换和数据简化;预处理的主要方法包括了基于粗糙集(RS)理论的约简方法、基于概念树的数据浓缩方法、信息论思想和普化知识发现、基于统计分析的属性选取方法和遗传算法。周傲英等详细说明了数据预处理的原理,比如在传统数据管理领域,数据预处理是针对不精确的数据进行数据清理、数据转换,从而提升数据质量,最终能够被确定性管理技术所处理;而在隐私保护领域,数据预处理是将准确数据(或者高精度数据)转化为不精确的数据[37]。
3.2 关联规则研究现状
关联规则方面,李专等则基于分析经典关联规则挖掘及相关的隐私保护等问题,开展多关联规则的刻画和挖掘问题的研究工作,并通过改进查询模式的定义移植Apriori特性到多关系关联规则中,实现规则的挖掘的加速处理。为了平衡数据可用性和安全性之间的矛盾,文中阐述了如何隐藏敏感规则中公共关系的元组,以降低对数据可用性的影响[38]。张鹏等结合数据干扰和查询限制这两种隐私保护的基本策略,提出一种崭新的数据随机处理方法,从隐私性、准确性、高效性和适用性这四方面对RRPH方法进行验证评价,并最终获得了良好的实验效果[39]。决策树方面,决策树方法在数据的隐私保护方面主要将需要加密或需模糊化的数据进行分类,对非同类别的数据进行干扰或限制的处理,从而达到隐私保护的目的。因此,关于决策树的研究主要从算法及应用两个研究方向展开。唐华松等深入探讨数据挖掘中的决策树算法,通过利用熵和加权和的思想解决决策树分支取值难的问题,并通过实验表明利用该算法可提高决策树的生长速度,优化决策树的结构,发掘较好的规则信息[40]。刘小虎等以ID3为基础提出改进的决策树的优化算法,考虑了一个属性和该属性后续选择的属性所带来的信息增益[42]。
3.3 K-匿名方法研究现状
杨晓春等针对单一约束K-匿名化方法在处理多约束情况时容易导致大量信息损失的问题提出多约束K-匿名化方法Classfly+及相应的3种算法,包括朴素算法、完全IndepCSet算法和IndepCSet的Classfly+算法,最终实验结果显示Classfly+能很好地降低多约束K-匿名化的信息损失,改善匿名化处理的效率[44]。黄毅等针对基于中心服务器的位置K-匿名方法使得中心服务器成为性能瓶颈,亦容易造成查询处理过程的复杂化和牺牲用户的服务质量等问题,提出一种用户协作无匿名区域的隐私保护方法,能够在不使用匿名区域的情况下达到K-匿名的效果,还提高匿名系统的整体性能和简化服务提供商的查询处理过程[45]。韩建民等从显示标识符、敏感属性和非敏感属性方面对K-匿名化方法中的微聚集算法进行分类分析,并介绍不同类型的数据的度量方法以及微聚集算法的基本步骤[46]。
3.4 朴素贝叶斯分类器研究现状
朴素贝叶斯分类器方面,李静梅等基于特征独立性假设,利用EM(期望值最大)算法,加强朴素贝叶斯分类器的应用,并提高其分类精度[47]。徐光美等构建了一种新的朴素贝叶斯分类公式,并实现了一种基于关系数据库技术的新的多关系朴素贝叶斯分类器(nMRNBC)。利用新的频率计数方法和新的多关系朴素贝叶斯分类公式很大程度上消除了统计偏斜问题,使得分类器在不增加时间复杂度前提下,找到与分类属性最相关的属性,从而获得较高的分类准确率[48,49]。李旭升等提出了扩展树增强朴素贝叶斯分类器,打破对连续变量进行预离散化的限制,在增强朴素贝叶斯分类器处理混合变量的情况,提高分类精度[50]。范敏等使用贝叶斯网络方法构造贝叶斯网络分类器,并将层次朴素贝叶斯分类器的学习算法应用到水质评价和预警的模型中,获得了较好的适用效果[51]。张阳等采用多元伯里利朴素贝叶斯模型,从关联特征入手来提高分类器的性能[52]。眭俊明等为了放松属性独立性的约束,提高朴素贝叶斯分类器的泛化能力,提出了基于频繁项集挖掘技术的贝叶斯分类学习算法FISC并印证了其有效性[53]。
3.5 聚类算法研究现状
聚类算法方面,孙吉贵等从算法思想、关键技术和优缺点等方面对近年来较有代表性的聚类算法进行分析和概括,并从正确率和运行效率两方面对一些典型的聚类算法进行模拟实验,在通过对同一种聚类算法、不同的数据集和同一个数据集、不同的聚类算法的聚类情况进行对比后归纳出聚类分析的研究热点[54]。张敏等从改变度量方式、改变约束条件、在目标函数中引入熵以及考虑对聚类中心进行约束等几方面对在C-均值算法的基础上得到的基于划分的模糊聚类算法做了综述和评价,并指出模糊聚类算法被广泛应用的原因主要是它对数据的比例变化具有鲁棒性[56]。马帅等提出一种基于参考点和密度的快速聚类算法(CURD),基于参考点对数据进行分析处理,适用于对大规模数据进行挖掘[57]。卜东波等从信息粒度的角度对聚类和分类技术进行分析,并提出一种基于信息粒度原理的分类算法,利于消除分类先验知识和特征选取之间的不协调性[58]。杨博等对网络簇结构的复杂网络聚类方法进行了综述,详细分析了其拓扑结构、功能、隐含模式等,并介绍其在社会网、生物网和万维网中的广泛应用[59]。朱蔚恒等针对数据流聚类算法CluStream的不足提出了一种采用空间分割和按密度聚类的算法ACluS-tream,并验证了该方法无论在准确度还是速度上都优于CluStream[60]。
4 面临的挑战
4.1WLAN带来的安全威胁
(1) 无线系统中的隐私泄漏。使用无线设备进行网上交易可能会泄漏用户的隐私,包括位置信息、账号、密码等。更有甚者无须采集用户的交易信息亦能够获取他人的IP地址,进而从事一些窃取他人隐私的非法活动。
(2) 移动设备与应用安全。目前大多数用户接触无线网络使用的都是移动设备,主要应用平台分别是Android和IOS。以Android市场为例,《Unsafe exposure analysis of mobile in app advertisements》对Android市场的应用程序中的广告插件进行了采集和分析,通过对10万个不同应用程序的分析,文章总结出了51个有代表性的广告插件软件,并且设计AdsRisk程序对不同的广告软件进行风险分析。结果表明,大部分软件库都有搜索用户隐私数据的行为,少量只搜集用户的定位信息等相对不敏感的数据,而较多广告插件会搜集用户的电话记录、通信录、安装软件类表等敏感的信息。
4.2 位置隐私保护技术欠缺点
虽然身份保护方法[61]和位置信息保护方法都能够提供位置信息的隐私保护功能,但在移动环境中,移动用户之间的交互所产生的隐私泄漏问题目前尚未能得以有效解决。
4.3 动态数据隐私保护技术欠缺点
目前,隐私保护技术主要是基于静态数据而发展的,然而现实生活中,数据库中的数据随时都有可能发生变化,包括新数据的添加、旧数据的删除等。而且数据库中的数据记录一般都不可能是完全随机、独立的,数据与数据之间、数据与数据变化之间都是相互关联和影响的[3]。采取何种方法能够保证数据库可以进行有效的更新,最好不需要在每次更新数据时都重新加密数据库或更新整个认证结构是迫切需要解决的难题[63]。
4.4 云计算带来的安全威胁
在云平台中运行的各类云应用无固定不变的基础设施和固定不变的安全边界,难以实现用户数据安全以及隐私保护;云服务所涉及的资源由多个管理者所有,无法统一规划部署安全防护措施;云平台中数据与计算高度集中,安全措施必须满足海量信息处理需求这一大前提[64]。
5 结论与展望
本文首先简要介绍了基于隐私保护的数据挖掘技术的相关概念,其次着重介绍了几种典型的数据挖掘技术,并对其进行了对比,再通过对国内的相关技术进行综述,最后讨论了基于隐私保护的数据挖掘技术所面临的挑战。随着IT的发展尤其是WLAN与云计算的发展,数据、信息、软件等资源能够更快速和便捷地实现共享,但与此同时隐私保护面临的威胁也日益加大,因此对于隐私保护技术的研究将愈发迫切和重要。
[1]Shibnath Mukherjee,Madhushri Banerjee,Zhiyuan Chen,Aryya Gangopadhyay.A privacy preserving technique for distance-based classification with worst case privacy guarantees[J].Data&Knowledge Engineering,2008(66):264-288.
[2]Goldman K,Valdez E.Matchbox:secure data sharing[J].IEEE Internet Computing,2004,8(6):18-24.
[3]周水庚,李丰,陶宇飞,等.面向数据库应用的隐私保护研究综述[J].计算机学报,2009,32(5):847-861.
[4]王光,蒋平.数据挖掘综述[J].同济大学学报.2004,32(2):246-252.
[5]Rizvi SJ,Haritsa JR.Maintaining data privacy in association rule mining.In:Bernstein PA,Ioannidis YE,Ramakrishnan R,Papadias D,eds.Proc.of the 28th Int’1 Conf.on Very Large Data Bases.Hong Kong:Morgan Kaufmann Publishers,2002:682-693.
[6]Agrawal S,Krishnan V,Harista JR.On addressing efficiency concerns in privacy-preserving mining.In:Lee YJ,Li JZ,Whang KY,Lee D,eds.Proc.Of the 9th Int’l Conf.on Database Systems for Advanced Applications.LNCS 2973,Jeju Island:Springer-Verlag,2004:113-124.
[7]Evfimievski.A Randomization in privacy preserving data mining.SIGKDD Explorations,2002,4(2):43-48.
[8]Evfimievski A,Srikant R,Agrawal R,Gehrke J.Privacy preserving mining of association rules.In:Hand D,Keim D,Ng R,eds.Proc.of the 8th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining.Edmonton:ACM Press,2002:217-228.
[9]Saygin Y,Verykios VS,Clifton C.Using unknowns to prevent discovery of association rules.ACM SIGMOD Record,2001,30(4):45-54.
[10]Olivera SRM,Zaiane OR.Privacy preserving frequent itemset mining.In:Clifton C,EstivillCastro V,eds.Proc.of the IEEE Int’l Conf.on Data Mining Workshop on Privacy,Security and Data Mining.Macbashi:IEEE Computer Society,2002:43-54.
[11]Kantarcioglu M,Clifton C.Privacy-Preserving distributed mining of association rules on horizontally partitioned data. IEEE Trans. on Knowledge and Data Engineering,2004,16(9):1026-1037.
[12]Vaidya J,Clifton C.Privacy preserving association rule mining in vertically partitioned data.In:Hand D,Keim D,Ng R,eds.Proc.of the 8th ACM SIGKDD Int’l Conf.on Knowledge Discovery and Data Mining.Edmonton:ACM Press,2002.639-644.
[13]Clifton C,Kantarcioglu M,Vaidya J,Lin X,Zhu MY.Tools for privacy preserving distributed data mining.SIGKDD Explorations,2002,4(2):28-34.
[14]蔡伟杰,张晓辉,朱建秋,等.关联规则挖掘综述[J].计算机工程,2001,27(5):31-49.
[15]唐华松,姚耀文.数据挖掘中决策树算法的探讨[J].计算机应用研究,2001(8):18-22.
[16]Samarati P.Protecting respondents’identities in microdata release.[C]//Proc of the TKDE’01,2001:1010-1027;Samarati P,Sweeney L.Generalizing data to provide anonymity when disclosing information(Abstract)[C]//Proc of the 17th ACMSIGMODSIGACT-SIGART Symposium on the Principles of Database Systems,Seattle,WA,USA,1998:188.
[17]贺玲,吴玲达,蔡益朝.数据挖掘中的聚类算法综述[J].计算机应用研究,2007(1):10-13.
[18]Adam N,Wortmann J C.Security-control methods for statistical databases:A comparison study.ACM Computing Surveys,1989,21(4):515-556.
[19]Fienberg S E,McIntyre J.Data swapping:Variations on a theme by Dalenius and Reiss//Proceedings of the Privacy in Statistical Databases(PSD).Barcelona,Spain,2004:14-29.
[20]Pinkas B.Cryptographic techniques for privacy preserving data mining.ACM SIGKDD Explorations,2002,4(2):12-19.
[21]Evfimievski A,Srikant R,Agrawal A,Gehrke J.Privacy preserving mining of association rules//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(SIGKDD).Madison,Wisconsin,2002:217-228.
[22]Vaidya J S,Clifton C.Privacy preserving association rule mining in vertically partitioned data//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(SIGKDD).Edmonton,Alberta,Canada,2002:639-644.
[23]Kantarcioglu M,Clifton C.Privacy-preserving distributed mining of association rules on horizontally partitioned data.IEEE Transactions on Knowledge and Data Engineering,2004,16(9):1026-1037.
[24]Wang K,Yu P S,Chakraborty S.Bottom-up generalization:A data mining solution to privacy protection//Proceedings of the IEEE International Conference on Data Mining(ICDM).Brighton,UK,2004:249-256.
[25]Fung B C M,Wang K,Yu P S.Top-down specialization for information and privacy preservation//Proceedings of the 21st International Conference on Data Engineering(ICDE).Tokyo,Japan,2005:205-216.
[26]Vaidya J,Clifton C.Privacy preserving K-means clustering over vertically partitioned data//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(SIGKDD).Washington,DC,USA,2003:206-215.
[27]Sweeney L.k-anonymity:A model for protecting privacy.International Journal on Uncertainty,Fuzziness and Knowledge Based Systems,2002,10(5):557-570.
[28]Sweeney L.Achieving k-anonymity privacy protection using generalization and suppression.International Journal on Uncertainty,Fuzziness and Knowledge-Based Systems,2002,10(5):571-588.
[29]Li N,Li T.t-closeness:Privacy beyond k-anonymity and l-diversity//Proceedings of the 23rd International Conference on Data Engineering(ICDE).Istanbul,Turkey,2007:106-115.
[30]Aggarwal C C.On k-anonymity and the curse of dimensionality//Proceedings of the 31st Very Large Data Bases(VLDB)Conference,Trondheim,Norway,2005:901-909.
[31]Meyerson A,Williams R.On the complexity of optimal k-anonymity//Proceedings of the Symposium on Principles of Database Systems(PODS).Paris,France,2004:223-228.
[32]LeFevre K,DeWitt D J,Ramakrishnan R.Mondrian multidimensional k-anonymity//Proceedings of the 22nd International Conference on Data Engineering(ICDE).Atlanta,Georgia,USA,2006:25-35.
[33]LeFevre K,DeWitt D J,Ramakrishnan R.Incognito:Efficient full domain k-anonymity//Proceedings of the ACM SIGMOD Conference on Management of Data(SIGMOD).Baltimore,Maryland,2005:49-60.
[34]Kifer D,Gehrke J.Injecting utility into anonymized datasets//Proceedings of the ACM SIGMOD Conference on Management of Data(SIGMOD).Atlanta,Georgia,USA,2006:217-228.
[35]刘亮,谢舒婷,李顺东.一种为保密挖掘预处理数据的新方法[J].计算机科学.2011,38(7):165-169.
[36]刘明吉,王秀峰,黄亚楼.数据挖掘中的数据预处理[J].计算机科学.2000,27(4):54-57.
[37]周傲英,金澈清,王国任,等.不确定性数据管理技术研究综述[J].计算机学报,2009,32(1):1-16.
[38]李专,王元珍.多关系关联规则挖掘中的隐私保护[J].华中科技大学学报.2005,35(11):41-43.
[39]张鹏,童云海,唐世渭,等.一种有效的隐私保护关联规则挖掘方法[J].软件学报,2006,17(8):1764-1774.
[40]唐华松,姚耀文.数据挖掘中决策树算法的探讨[J].计算机应用研究,2001(8):18-22.
[41]韩慧,毛锋,王文渊.数据挖掘中决策树算法的最新进展[J].2004(12):5-8.
[42]刘小虎,李生.决策树的优化算法[J]软件学报,1998,9(10):797-800.
[43]肖勇,陈意云.用遗传算法构造决策树[J].计算机研究与发展,1998,35(1):49-52.
[44]杨晓春,刘向宇,王斌,等.支持多约束的K-匿名化方法[J].软件学报,2006,17(5):1222-1231.
[45]黄毅,霍峥,孟小峰.CoPrivacy:一种用户协作无匿名区域的位置隐私保护方法[J].计算机学报.2011,34(10):1976-1985.
[46]韩建民,岑婷婷,虞慧群.数据表K-匿名化的微聚集算法研究[J].电子学报,2008,36(10):2021-2029.
[47]李静梅,孙丽华,张巧荣,等.一种文本处理中的朴素贝叶斯分类器[J].哈尔滨工程大学学报.2003,24(1):71-74.
[48]徐光美,杨炳儒,秦奕青.一种新的多关系朴素贝叶斯分类器[J].系统工程与电子技术,2008,30(4):655-657.
[49]徐光美,杨炳儒,秦奕青,等.基于互信息的多关系朴素贝叶斯分类器.[J]北京科技大学学报,2008,30(8):964-966.
[50]李旭升,郭耀煌.扩展的树增强朴素贝叶斯分类器[J].模式识别与人工智能,2006,19(4):469-474.
[51]范敏,石为人.层次朴素贝叶斯分类器构造算法及应用研究[J].仪器仪表学报,2010,31(4):776-781.
[52]张阳,张利军,闫剑锋,等.基于关联特征的朴素贝叶斯文本分类器[J].西北工业大学学报,2004,22(4):413-416.
[53]眭俊明,姜远,周志华.基于频繁项集挖掘的贝叶斯分类算法[J].计算机研究与发展,2007,44(8):1293-1300.
[54]孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
[55]张莉,周伟达,焦李成.核聚类算法[J].计算机学报,2002,25(6):587-590.
[56]张敏,于剑.基于划分的模糊聚类算法[J].软件学报,2004,15(6):858-868.
[57]马帅,王腾蛟,唐世渭,等.一种基于参考点和密度的快速聚类算法[J].软件学报,2003,14(6):1089-1095.
[58]卜东波,白硕,李国杰.聚类/分类中的粒度原理[J].计算机学报,2002,25(8):810-816. [59]杨博,刘大有,LIU Jiming,等.复杂网络聚类方法[J].软件学报,2009,20(1):54-66.
[60]朱蔚恒,印鉴,谢益煌.基于数据流的任意形状聚类算法[J].软件学报,2006,17(3):379-387.
[61]Baugh J P,JinHua G. Location Privacy in Mobile Computing Environments. In UIC. 2006:936-945.
[62]魏琼,卢炎生.位置隐私保护技术研究进展[J].计算机科学,2008,35(9):21-25.
[63]田秀霞,王晓玲,高明,等.数据库服务——安全与隐私保护[J].软件学报.2010,21(5):991-1006.
[64]冯登国,张敏,张妍,等.云计算安全研究[J].软件学报.2011,22(1):71-83.
Survey of Data Mining Based on Privacy Preserving
Jiang Mei
(Guangzhou Light Industry Technician School,Guangzhou 510642,Guangdong)
Users’privacy is under threat with the popularity of WLAN and Cloud computing,which highlights the importance and urgency of the DM techniques used in privacy protection.In this paper,several typical DM technique used in privacy protection are compared,while new trends of these methods in domestic area are summarized.In the end,the challenges faced by DM techniques used in privacy protection are concluded.
data mining;privacy protection;security
TP311.13
A
1008-6609(2017)08-0031-05
姜美(1990-),女,广东人,硕士,研究方向为数据挖掘。
