基于Hadoop和Paoding的中文词频统计的实现
2017-10-26关辉
关辉

摘要:大数据分析技术近年来发展非常迅速,已经成功应用在多个行业和领域,词频统计是大数据分析中经常要实现的一个功能。目前最为热门的开源大数据框架Hadoop中提供的经典案例WordCount仅能进行英文词频分析。通过对Ha-doop相关技术的研究,对WordCount进行了改写,利用中文分词器Paoding对中文语句进行分词,实现了中文词频统计的功能。
关键词:大数据分析;词频统计;Hadoop;MapReduce;Paoding
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2017)22-0007-03
1背景
近年来伴随着互联网、云计算、移动互联和物联网技术的迅猛发展,带动了电子商务、网络金融等相关产业的发展,这些新一代信息技术正成为各行各业运营和发展的重要推动力。但无处不在的移动设备、RFID、无线传感器等每时每刻都在产生数据,数以亿计用户的互联网服务每分每秒都在产生巨量的交互,要处理的数据量以几何级数的形式增长,而业务需求和竞争压力对数据处理的实时性、有效性又提出了更高的要求,传统的信息处理手段难以应对。从2009年开始,“大数据”成为互联网信息技术行业的热门词汇,各种大数据处理技术纷至沓来,为解决上述问题提供了新的方案。随着大数据时代的来临,大数据分析也应运而生。大数据分析带给我们最直接的视觉感受就是利用图形或者表格来展示大数据背后所隐藏的内容,既真实又直观。比如我们在各种媒体上经常看到的“词云”、“新闻热词”等实际上就是利用大数据分析技术实现的词频统计的一种形式。
当前最为炙手可热的开源大数据框架Hadoop可以帮助我们来实现词频统计的功能。Hadoop是一个能够对大量数据进行分布式处理的软件框架,它以一种可靠、高效、可伸缩的方式进行数据处理。WordCount就是Hadoop中的一个经典案例,它可以对以空格划分的英文进行词频统计,初学Hadoop的人都是从理解WordCount这个案例开始的。相比于英文,中文的词频统计通常要复杂得多,因为中文涉及很多语义及分词的不同。就像大家经常用的Word软件中的检查拼写和语法的功能,检查英文往往很准确,而它检查出的中文错误往往根本就没有错误。不过,现在也出现了很多中文分詞的工具组件,Pa-oding(庖丁)就是一款非常好用高效的开源中文分词组件,填补了国内中文分词方面开源组件的空白。我们可以结合Hadoop和Paoding这两种技术,利用Hadoop来实现分布式的数据处理,利用Paoding进行中文分词,仿照WordCount案例来实现中文词频统计的功能。
2开源大数据框架Hadoop和中文分词组件Paoding
Hadoop是一个开发和运行处理大规模数据的软件平台,是Apache基金会所开发的一个用Java语言实现的开源分布式系统基础框架,实现在大量计算机组成的集群中对海量数据进行分布式计算的功能。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop DistributedFile svstem),简称HDFS,HDFS为海量的数据提供了存储。另外还实现了一个并行计算的编程模型MapReduce,用户只要继承MapReduceBase,提供分别实现Map和Reduce的两个类,并注册Job即可自动分布式运行。MapReduce为海量的数据提供了计算。
Paoding(庖丁)中文分词库是一个使用Java开发的,可结合到Lucene应用中的,为互联网、企业内部网使用的中文搜索引擎分词组件。它采用完全的面向对象设计,具有极高的效率和扩展性。它采用基于不限制个数的词典文件对文章进行有效切分,能够对词汇进行分类定义,并能对未知的词汇进行合理解析。
3中文词频统计的实现
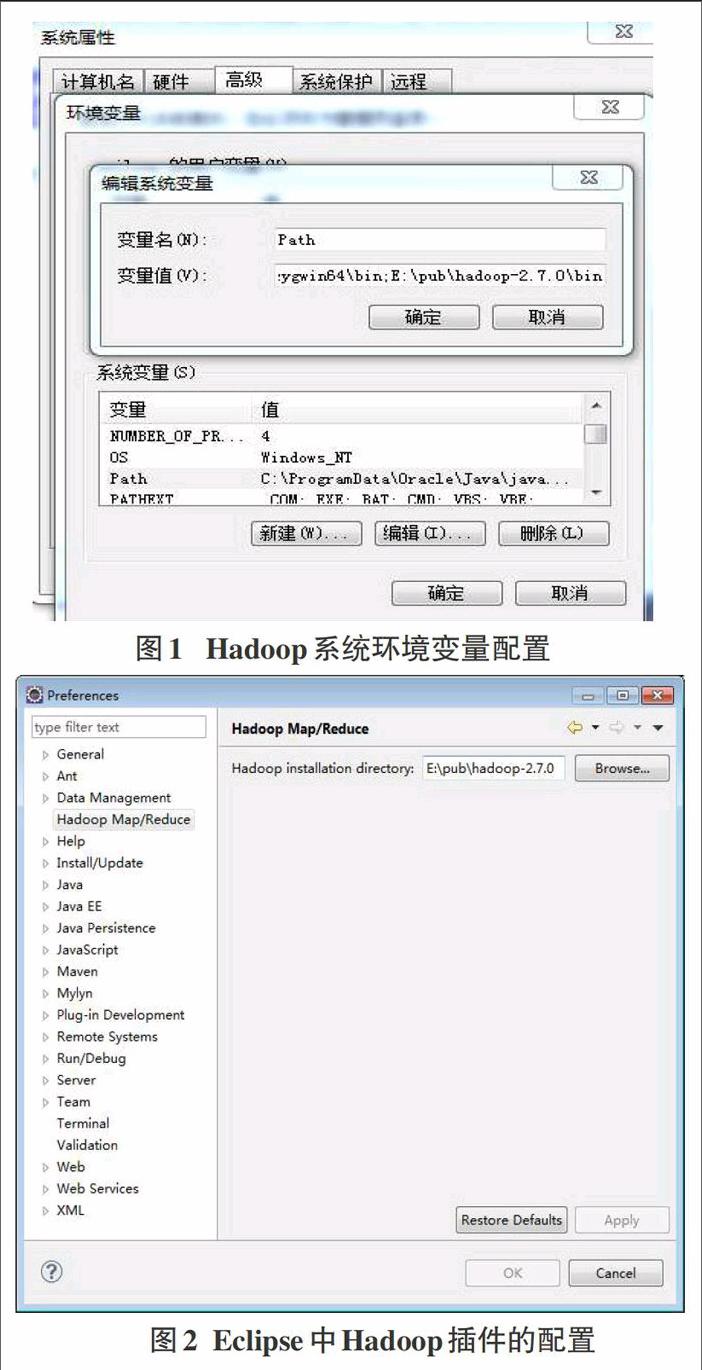
3.1Hadoop开发环境配置
首先在用于开发的PC机上安装hadoop 2.7.0,并将hadoop-2.7.0/bin目录下的hadoop.dll文件拷贝到系统路径C:\Win-dows\System32下,还需在系统环境变量的path中添加hadoop的bin目录路径,如图1所示。接着就需要在Java开发平台Eclipse中配置Hadoop开发环境。在网上下载Hadoop插件hadoop-eclipse-kepler-plugin-2.2.0.iar,将文件拷贝到Eclipse的pl-ugins目录下。然后进人Eclipse,依次打开Window→Preferenc-es,选中左边的Hadoop Map/Reduce标签,在右边的文本框中指定到hadoop-2.7.0目录,点击OK按钮,如图2所示。至此Ha-doop的开发环境准备完毕。
3.2中文分词组件Paoding的配置
从Paoding官网下载paoding-analysis压缩包,解压后找到四个jar包:lucene-analyzers,iar、lucene-core.jar、paoding-analy-sis.iar和commons-logging.jar,拷贝到项目的WEB-INF/lib目录。从paoding-analysis压缩包解压后的文件中找到dic文件夹,拷贝到Hadoop的安装目录E:/pub/hadoop-2.7.0中。然后停止HDFS,再在hadoop-env.sh文件末尾配置Paoding字典的环境变量:添加export PAODING_DIC_HOME=E:/pub/hadoop-2.7.0/dic,添加完后重启HDFS。
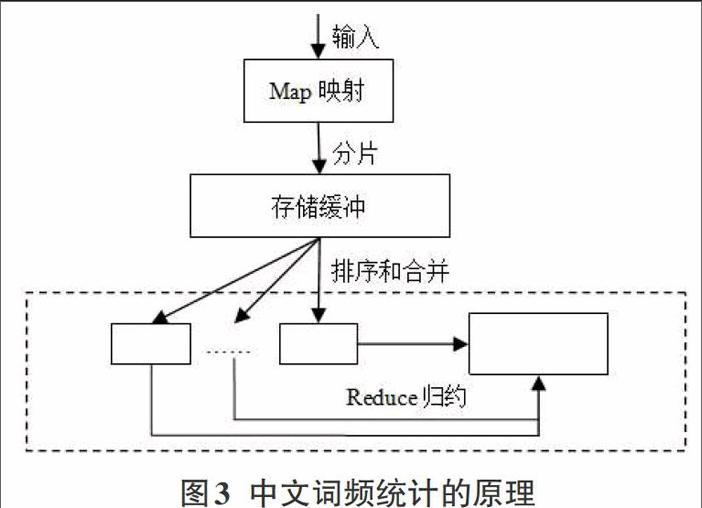
3.3中文词频统计的原理
首先利用中文分词组件Paoding对HDFS中的输入数据进行切片,再通过Map方法将键值映射,最后通过Reduce方法进行归约。为了减少Reduce的压力,有时还会在Map结束后在每个Hadoop节点进行排序以及合并,如图3所示。
3.4中文词频统计的实现
将需要进行分析的文件拷贝到指定的临时目录temp中,并调用文档转换的方法对文件格式进行转换,将各种常见类型的文档(如:pdf、doc等)转换为纯文本txt形式的文档。通过运行MapReduce,对temp目录中需要分析的文件进行映射(M印)和归约(Reduce)。Map和Reduce的输入、输出都采用键值对的形式进行传递。Map对输入的键值(键:偏移量,值:一行文本)调用中文分词器Paoding进行切片分词,将每个单词作为键、单词标记(定值1)作为值进行输出。Map的输出内容(键:单词,值:单词标记1)会作为Reduce的输入内容进行归约处理,对相同键的列表进行累加,Reduce结束后返回整个MapReduce的输出内容,即每个单词的计数。这些可以通过改写Hadoop的经典案例WordCount中的Mapper类和Reducer类来实现。改写后的Mapper类和Reducer类的关键代码如下:
当MapReduce结束后,每个单词以及该单词在文件中出现的次数会以Json的形式传递给前端,前端会调用d3js大数据可视化引擎对传递的Json数据进行各种形式的展示(如:词云、柱形图、饼状图等)。例如:对中国古代四大名著之一的《红楼梦》进行词频统计并把结果以“词云”形式展示出来的效果如图4所示。
4结束语
大数据分析技术近年来得到了飞速发展和快速应用,词频统计功能在大数据分析中经常用到。利用开源大数据框架Ha-doop实现分布式数据处理,利用中文分词组件Paoding进行中文分词,成功实现了中文词频统计的功能,并可以调用d3js大数据可视化引擎对统计结果进行图形化展示。endprint
