低信噪比环境下的语音识别方法研究
2017-10-26王群曾庆宁谢先明郑展恒
王群,曾庆宁,谢先明,郑展恒
低信噪比环境下的语音识别方法研究
王群,曾庆宁,谢先明,郑展恒
(桂林电子科技大学信息与通信学院,广西桂林541004)
单通道语音信号在信噪比较大的环境下经过增强后再识别,能表现出较高的识别率。但是在低信噪比环境下,增强后语音信号的识别率急剧下降。针对此种情况,提出了一种用在识别系统前端的语音增强算法,该增强算法将采集到的带噪语音信号先使用对数最小均方误差(Logarithmic Minimum Mean Square Error,LogMMSE)提高其信噪比,然后再利用改进的维纳滤波去除噪声残留并提升语音可懂度,最后用梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)和隐马尔科夫模型(Hidden Markov Model,HMM)对增强后的语音信号做特征提取并识别。实验分析结果表明,该方法能有效地抑制背景噪声并减少噪声残留,显著提升低信噪比环境下语音识别的准确性。
语音增强;低信噪比;改进维纳滤波;对数最小均方误差算法;语音识别
0 引言
语音识别主要是指能够让机器听懂人所说的话,即在特定或非特定环境下准确识别出语音的内容,并根据识别出的内容去执行相应的操作。语音识别在车载导航、视频监控、网络视讯等人机交互领域有着非常广泛的应用。例如视频监控往往存在较多盲区,利用语音识别技术可有效识别出视频盲区内外的危险语音信号,对某些突发情况及时做出反应。在识别系统中,一般是将理想环境下语音训练出的模型应用于真实的含噪环境中。而在实际环境中,由于背景噪声的影响,含噪语音的识别率急剧下降,甚至还会出现无法工作的现象。近些年来,理想环境下的语音识别技术发展迅速,单通道语音识别技术在理想环境中已经达到了较高的识别率。而在低信噪比环境下,如何提高语音识别率成为人们关注的焦点。近年来在语音识别抗噪方面很多人做了大量研究,例如谱减算法、维纳(Wiener)滤波、最小均方误差(Minimum Mean Square Error,MMSE)估计等[1]。这些算法虽然能有效地去除噪声,但都会不同程度地产生失真或引入音乐噪声,反而使增强后的语音识别率更低。这在低信噪比环境下更为明显。近年来有人提出最小控制递归平均(Improve Minima Controlled Recursive Averaging,IMCRA)改进噪声估计的对数最小均方误差(Logarithmic Minimum Mean Square Error,LogMMSE)算法[2]。该算法具有一定的增强效果,但计算量大,且识别效果并不突出。针对此种现象,本文通过在识别系统前端先采用基于对数最小均方误差算法提高含噪语音信噪比,再使用改进的(Wiener)滤波去除噪声残留并提升语音可懂度,从而提高语音识别率。
1 语音增强
1.1 谱减算法
谱减算法[3]的基本原理为假设信号是不相关的加性噪声,通过快速傅里叶变换(Fast Fourier Transformation,FFT),从含噪语音中减去噪声短时幅度谱,将计算所得纯净语音的短时幅度谱结合含噪语音的相位,再经过快速傅里叶逆变换(Inverse Fast Fourier Transformation,IFFT),得到需要的纯净语音信号,噪声的短时幅度谱可以在语音的静音段或者间隙进行重估和更新。基本框图如图1所示。
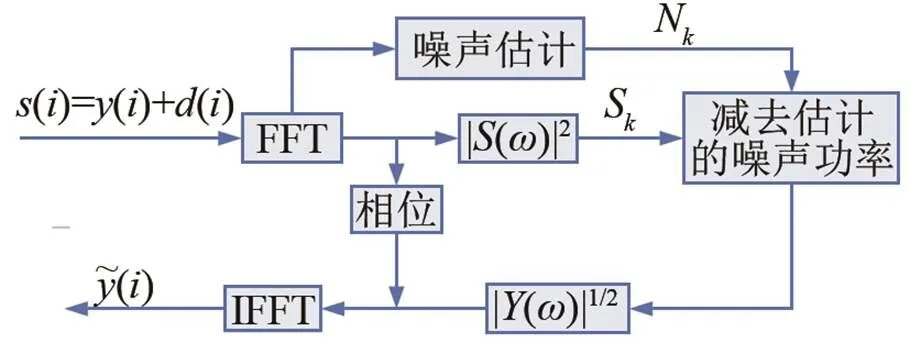
图1 谱减法框图
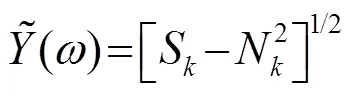
1.2 对数最小均方误差(LogMMSE)
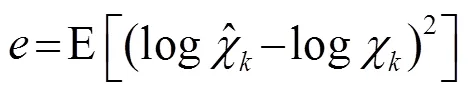
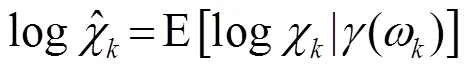
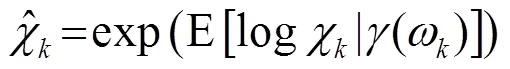
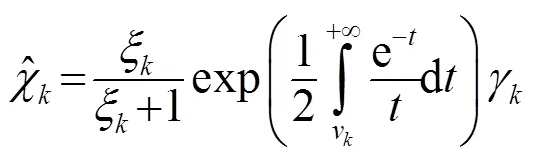
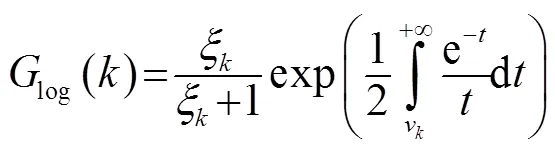
1.3 最小控制递归平均算法(IMCRA)
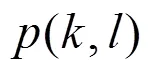
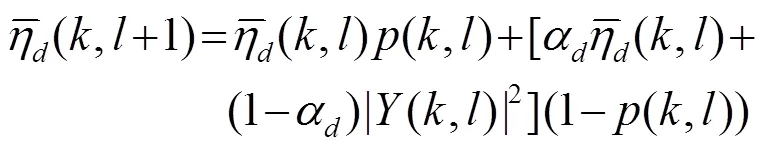
第一次平滑由式(8)得到:
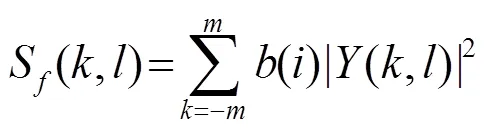
第二次平滑如式(9)所示:
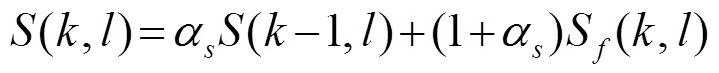
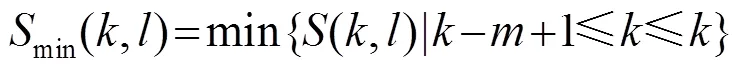
最后得到条件概率估计值:
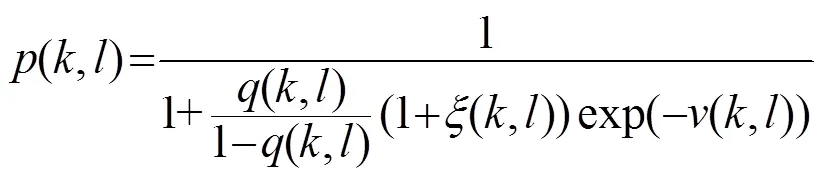
1.4 改进的Wiener滤波
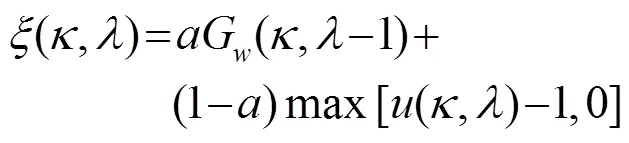
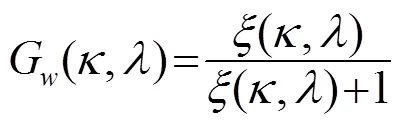
在Wiener滤波中用直接判决法估计先验信噪比会出现高估和低估的情况[8]。研究表明,在-10 dB以下的区域存在较多的高估,在放大畸变大于6.02 dB的区域存在较多的低估。高估和低估会导致语音信号增强效果不明显或失真。所以,可以从两方面对Wiener滤波器进行改进。
首先分两步来估计先验信噪比,第一步估计为式(13),在(13)基础上进行第二部估计:
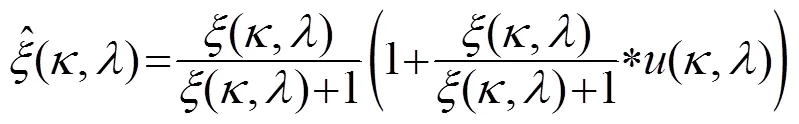
对于在-10 dB以下的区域,人工引入偏差值修改正增益函数,修正后可表示为
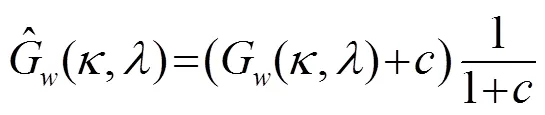
文献[9]中指出放大畸变大于6.02 dB时,有:
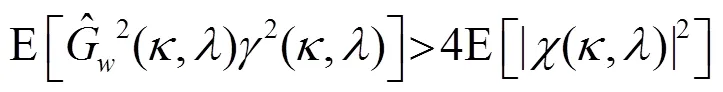
所以有:
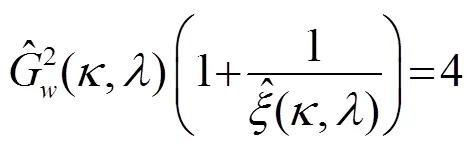
对增强后的语音幅度谱放大畸变大于6.02 dB的语音进行限制:
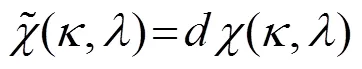
本文采用对数最小均方误差(LogMMSE)和改进Wiener滤波串联形式对带噪语音进行增强处理。先经过LogMMSE提高带噪语音信噪比,再用改进Wiener滤波去除噪声残留,同时还对容易产生畸变失真的区域进行增益补偿,最大限度地减小因去噪所造成的信号失真,以此提升识别率。
图2为LogMMSE和改进Wiener在0 dB、白噪声环境下级联方式的对比分析。其中图2(a)为纯净语音信号;图2(b)为LogMMSE去噪效果;图2(c)为改进Wiener去噪效果;图2(d)为先经过改进Wiener后使用LogMMSE去噪效果;图2(e)为本文所使用方式的去噪效果。从图2中可以看出,采用LogMMSE+改进Wiener的级联方式去噪效果最佳。从图2(b)、2(c)图中可以看出LogMMSE相比于改进Wiener在低信噪比有更好的去噪效果,产生毛刺较少。这样先经过LogMMSE处理后再使用改进Wiener去除噪声残留效果更为明显。若采用前置改进Wiener先对信号做去噪处理,这样得到的信号噪声残留较大,即使最后再使用LogMMSE去噪并不能达到理想去噪效果。所以本文采用LogMMSE后置改进Wiener滤波的级联方式。
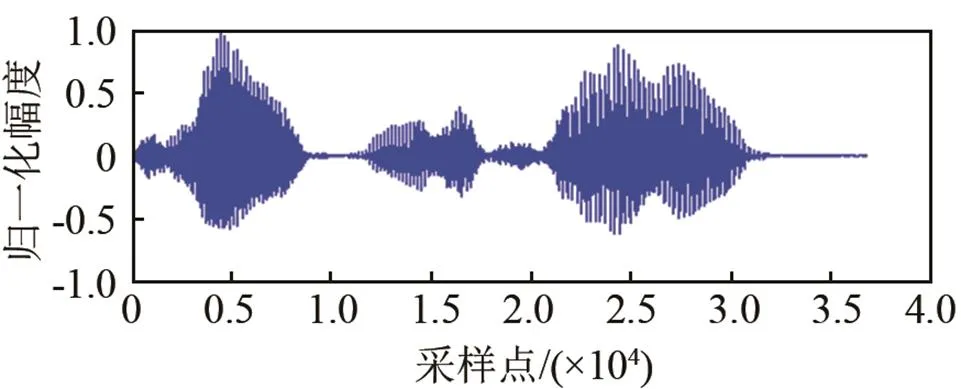
(a) 纯净语音
(b) LogMMSE去噪
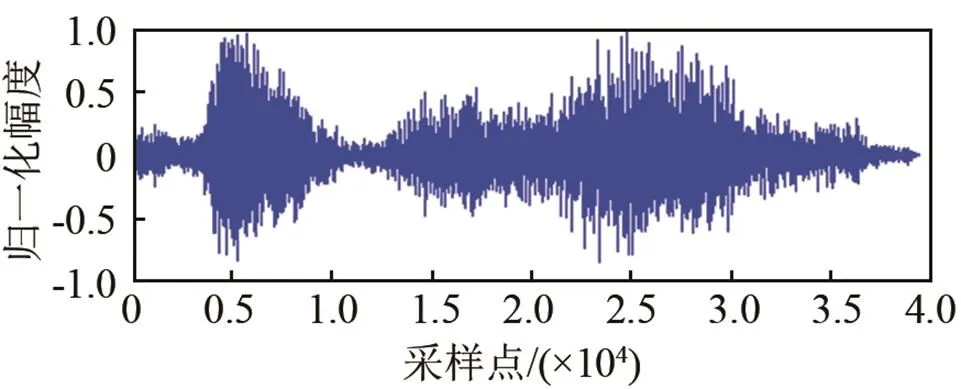
(c) 改进Wiener去噪
(d) 改进Wiener+LogMMSE
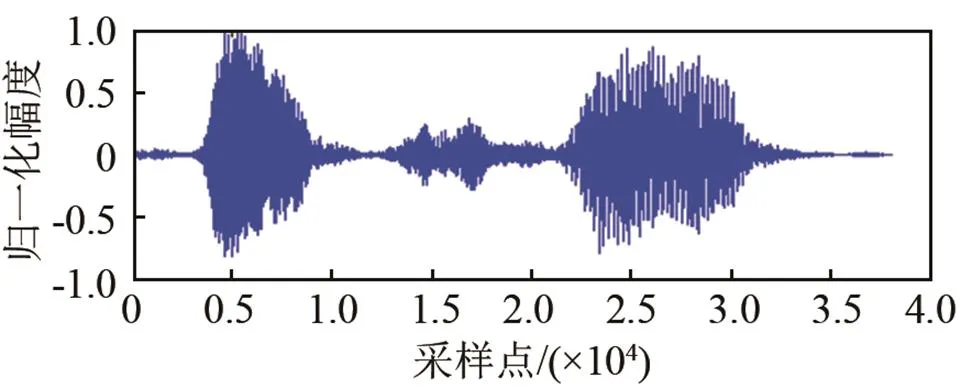
(e) LogMMSE+改进Wiener
2 语音识别
本文使用的识别系统为基于隐马尔科夫模型(Hidden Markov Model,HMM)的非特定人语音识别。识别系统提取增强后语音的声学特征,再通过维特比(Viterbi)算法解码匹配到最佳状态序列得到识别结果。该识别系统采用梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)做特征提取,采用隐马尔科夫(HMM)得到训练模型。
2.1 梅尔倒谱系数(MFCC)
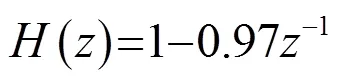
2.2 隐马尔科夫(HMM)
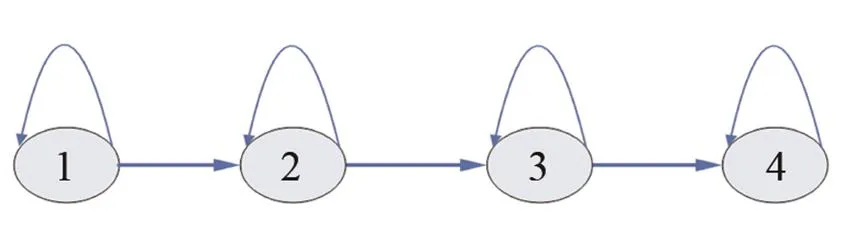
图3 HMM结构
3 仿真实验以及结果分析
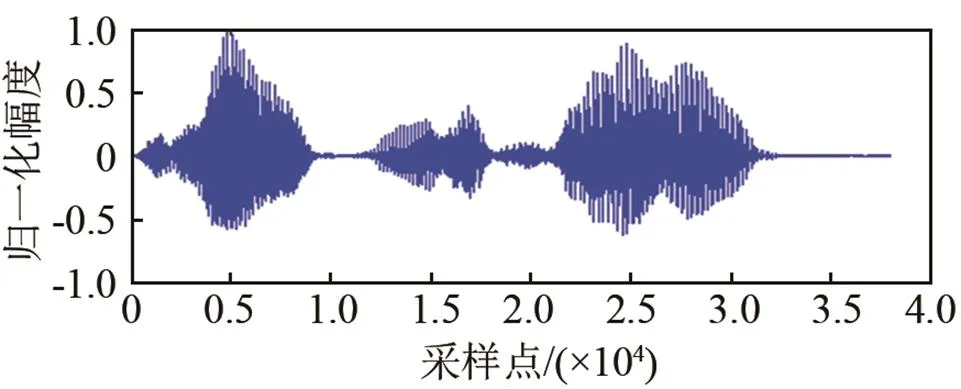
本次实验结合公共安防课题,解决传统视频监控只能看不能听的问题,利用语音识别技术对部分敏感词汇进行识别。数据使用M-AUFIO音频采集器完成,录制环境为相对安静的楼顶天台。噪声和语音分别在同样的环境下采集。本实验由20位同学参与录制,有13位男生和7位女生。其中随机抽取10人的语音(400条)作为训练样本,另外10人的语音(240条)做测试用。每人分别录制12个敏感词汇:火灾、爆炸、抢劫、盗窃、中毒、溺水、晕倒、危险、救命、受伤、救护车、消防车。噪声采集使用三种,分别为白噪声、F16和volvo噪声,本文语音和噪声的实验设备采样频率均为44.1 kHz,采样精度为32 bit。在实际仿真中经过了降采样处理,采样率为16 kHz,帧长为512,帧移是256,窗函数为Hamming窗。特征参数采用12维的梅尔倒谱系数,选用连续混合密度HMM,模型结构如图3所示,它包含4个状态,每状态含有3个高斯概率密度函数。为了验证本文方法的可行性,选取以下三种方法做对比。分别为:谱减法、改进Wiener滤波、LogMMSE-IMCRA。图4为在F16噪声干扰下各算法增强后时域仿真波形,选用的语音内容为“救护车”,信噪比为0 dB。
从图4可以看出,谱减法增强效果并不理想。LogMMSE-IMCRA较改进Wiener有更明显的增强效果,但是两者在时域波形上表现出较多的毛刺和噪声残留。本文所使用的增强方法效果明显,虽然仍会产生部分失真,但在低信噪比的环境下是可以接受的。
(a) 纯净语音
(b) 加噪语音
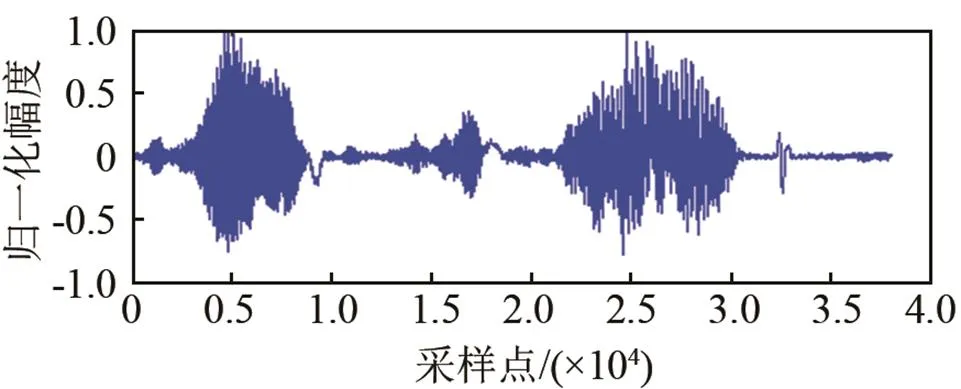
(c) 谱减增强
(d) 改进Wiener增强
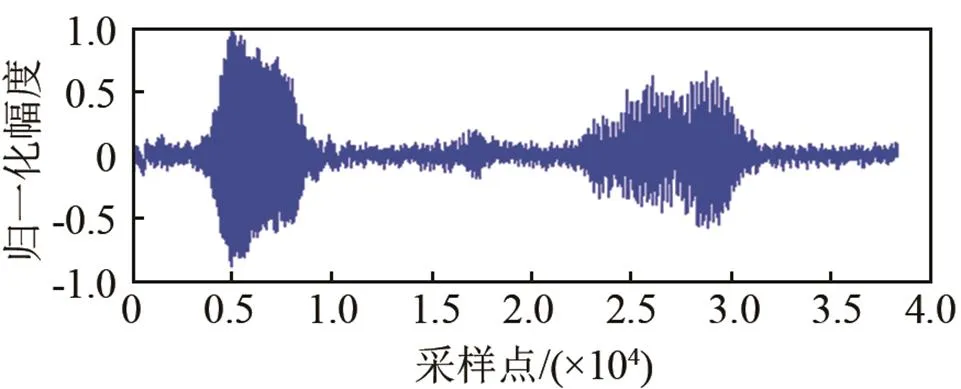
(e) LogMMSE-ICRMA增强
(f) 本文算法增强
图4 F16噪声环境下增强后的语音时域仿真图
Fig.4 The simulation diagrams of the speeches enhanced by different algorithms in F16 noise environment
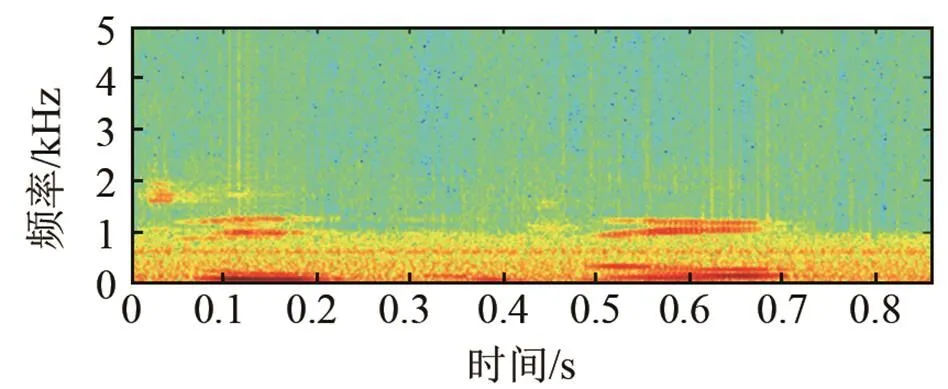
图5为增强后的语谱图,图5中所列的语谱图分别对应图4中的各时域仿真图。从语谱图来看,本文算法能更好地去除噪声,减少语音畸变,信号能量在低频段明显,增强后与原始语音基本保持一致。
图6(a)、6(b)、6(c)分别是在白噪声、F16和volvo噪声环境下通过四种算法增强后的识别率。
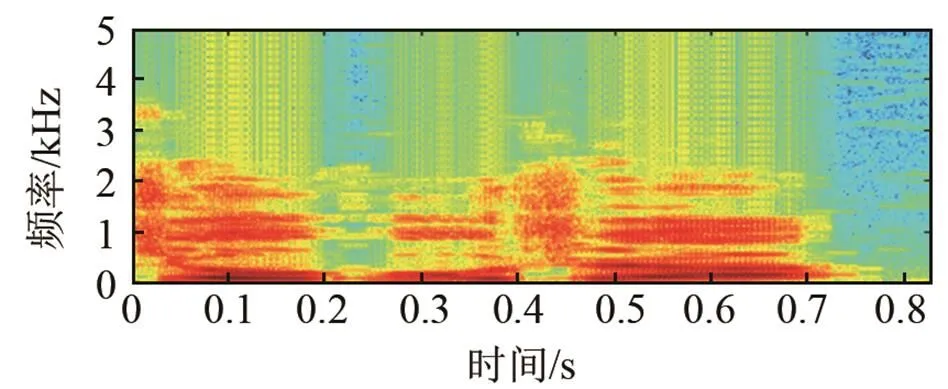
(a) 纯净语音
(b) 加噪语音
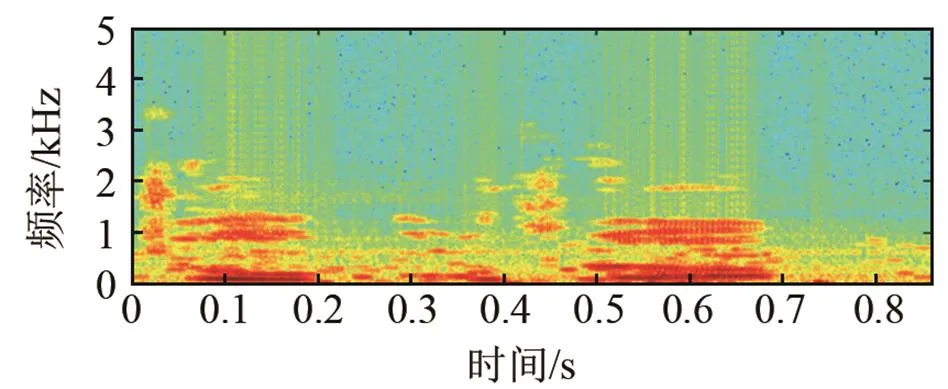
(c) 谱减增强
(d) 改进Wiener增强
(e) LogMMSE-ICRMA增强
(f) 本文算法增强
图5 F16噪声环境下增强后语谱图
Fig.5 The spectrograms of the speeches enhanced by different algorithms in F16 noise environment
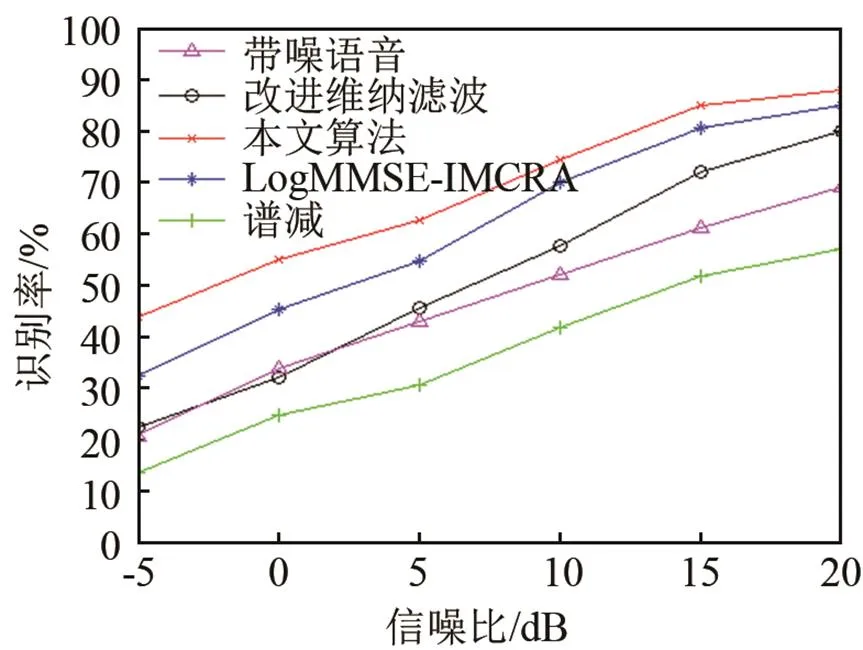
(a) White噪声识别率
(b) F16噪声识别率
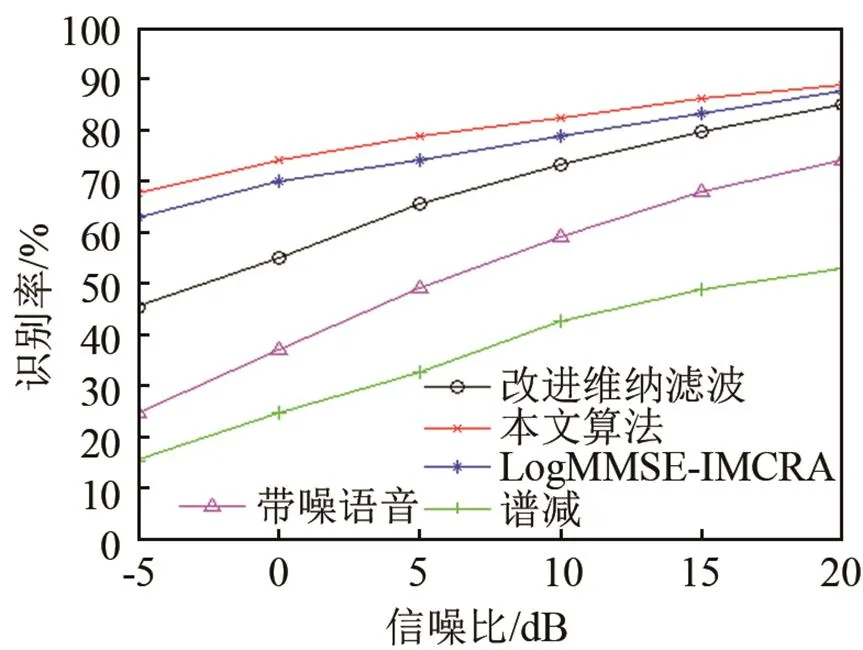
(c) volvo噪声识别率
从图6中对比可以看到,谱减法表现出较低的识别率,这是由于谱减法在增强后引入音乐噪声,使语音产生畸变从而降低识别率。改进Wiener滤波比谱减法的识别率要高,是因为其有更好的噪声抑制效果。LogMMSE-IMCRA算法通过准确的噪声估计来增强语音能有效提高识别率,但由于去噪后仍有较多噪声残留,识别率表现一般。使用本文算法增强后的识别率明显提高,尤其在低信噪比环境下效果更为明显。这是因为本算法不仅对信号的增强去噪效果明显,还针对语音信号消噪后容易产生畸变失真的区域,对其进行增益补偿,最大限度地减少语音失真以提高识别率。
表1列举了三种噪声环境在-5dB环境下通过四种算法增强后的平均运行时间,单位是秒(s)。四种算法的运行环境均为在同一设备下运行,实验仿真平台为matlab2012(a),所使用的计算机CPU主频为2.40×106kHz。从表1中可以看出,谱减法和改进Wiener虽然运行时间较短,但去噪效果并不明显。LogMMSE-IMCRA由于引入了递归平均算法做噪声估计,所以运行时间较长,而本文算法与其他算法相比在减少了运算量的同时也达到了较好的去噪效果。
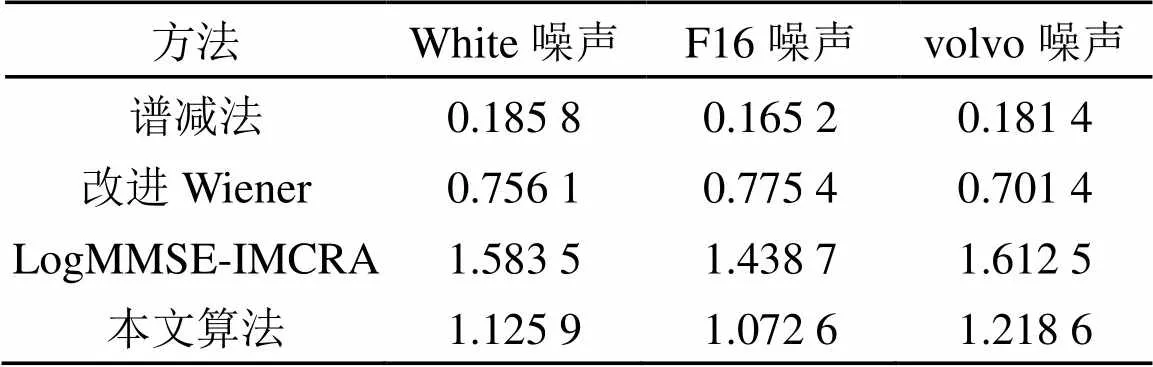
表1 不同方法在-5 dB环境下语音增强的时间对比(s)
表2列举了白噪声、F16和volvo噪声在-5 dB环境下通过四种算法增强后的识别率。可以看出本文算法在volvo噪声下相比较其他两种噪声表现出更高的识别效果,这是由于基于LogMMSE算法在提升语音可懂度方面相对于传统增强算法在非平稳噪声中有更好的表现。而改进的Wiener滤波又能有效降低语音畸变,进一步提升语音可懂度。
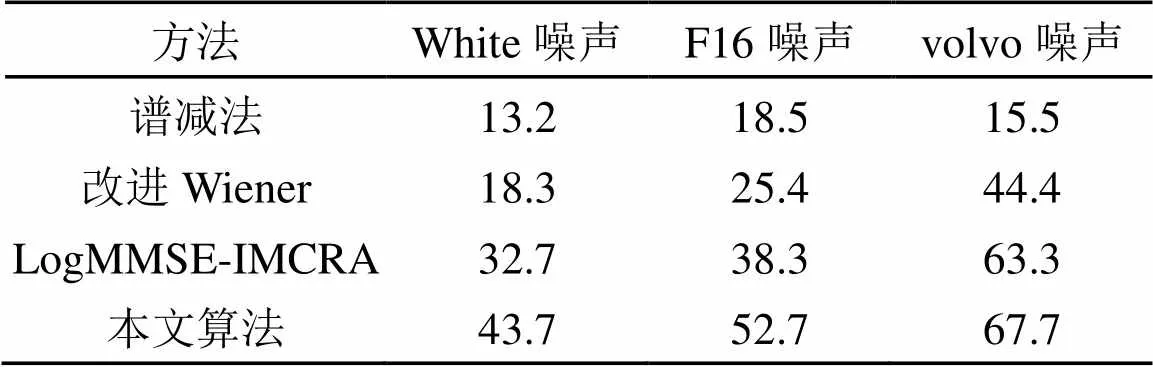
表2 不同方法在信噪比为-5 dB环境下语音增强后识别正确率对比(%)
本文通过随机抽取不同噪声环境在-5 dB到5 dB的识别情况发现,同一信噪比环境下的不同组,所识别不正确的单词是不同的。也就是说低信噪比下识别错误的单词是随机的。通过提取识别错误的单词发现,其时域波形表现为仍有部分噪声残留或失真,所以导致识别错误,这种情况随着信噪比的提高而减小。另一种原因可能是有的参与录制人员说话夹杂方言,在理想环境下可以有效识别,但经过处理后识别效果下降。
4 结 论
针对低信噪比环境下识别率不高的问题。本文先用LogMMSE提高各通道信噪比,再利用改进的Wiener滤波去除噪声残留并降低由于增强处理所导致的语音畸变,最后对增强后的信号进行识别。实验表明本文方法相比较LogMMSE-IMCRA算法不仅取得了更好的识别效果,同时还减少了算法的计算量,而且更适用于低信噪比环境中。
[1] Loizou P C. Speech enhancement: theory and practice[M]. The Chemical Rubber Company Press, 2013: 75-109.
[2] 胡丹, 曾庆宁, 龙超, 等. 连续语音识别前端鲁棒性研究[J]. 电视技术, 2015, 39(24): 43-46. HU Dan, ZENG Qingning, LONG Chao, et al. Front-end robust study for continuous speech recognition[J]. Video Engineering, 2015, 39(24): 43-46.
[3] 曹亮, 张天骐, 高洪兴, 等. 基于听觉掩蔽效应的多频带谱减语音增强方法[J]. 计算机工程与设计, 2013, 34(1): 235-240. CAO Liang, ZHANG Tianqi, GAO Hongxing, et al. Multi-band spectral subtraction method for speech enhancement based on masking property of human auditory system[J]. Computer Engineering and Design, 2013, 34(1): 235-240.
[4] Jose A Gonzalez, Antonio M Peinado, Ma N, et al. MMSE-Based missing-feature reconstruction with temporal modeling for robust speech recognition[J]. Audio Speech & Language Processing IEEE Transactions on, 2013, 21(3): 624-635.
[5] Cohen I, Berdugo B. Speech enhancement for non-stationary noise environments[J]. Signal Processing, 2009, 81(11): 2403-2418.
[6] 张东方, 蒋建中, 张连海. 一种改进型IMCRA非平稳噪声估计算法[J]. 计算机工程, 2012, 38(13): 270-272. ZHANG Dongfang, JIANG Jianzhong, ZHANG Lianhai. Improved IMCRA non-stationary noise estimation algorithm[J]. Computer Engineering, 2012, 38(13): 270-272.
[7] 张亮, 龚卫国. 一种改进的(Wiener)滤波语音增强算法[J]. 计算机工程与应用, 2010, 46(26): 129-131. ZHANG Liang, GONG Weiguo. Improve wiener filtering speech enhancement algorithm[J]. Computer Engineering and Applications, 2010, 46(26): 129-131.
[8] Fei C, Loizou P C. Impact of SNR and gain-function over- and under-estimation on speech intelligibility[J]. Speech Communication, 2012, 54(2): 272-281.
[9] 郭利华, 马建芬. 具有高可懂度的改进的(Wiener)滤波的语音增强算法[J]. 计算机应用与软件, 2014(11): 155-157. GUO Lihua, MA Jianfen. Animproved wiener filtering speech enhancement algorithm with high intelligibility[J]. Computer Applications and Software, 2014(11): 155-157.
[10] 宋知用. MATLAB在语音信号分析与合成中的应用[M]. 北京: 北京航空航天大学出版社, 2013. SONG Zhiyong. The application of MATLAB in speech signal analysis and synthesis[M]. Beijing: Beihang University Press, 2013.
Research on speech recognition in low SNR environment
WANG Qun, ZENG Qing-ning, XIE Xian-ming, ZHENG Zhan-heng
(School of Information and Communication, Guilin University of Electronic Technology, Guilin 541004, Guangxi, China)
The accuracy rate of single channel enhanced speech recognition in high SNR environment is acceptable, but not so in low SNR environment. In this case, speech enhancement based on logarithmic minimum mean square error (LogMMSE) algorithm and modified Wiener filter algorithm is presented. Firstly the gathered speech signals' SNR is improved by the LogMMSE algorithm. Then using the improved Wiener filter algorithm removes residual noise and improves the signal quality. Finally the enhanced speech is used for recognition by MFCC and HMM algorithms. Experimental results show that the proposed method can effectively remove the background noise and reduce the residual noise, significantly increase the accuracy of the automatic speech recognition in noisy environment.
speech enhancement; low SNR; modified Wiener filter; LogMMSE algorithm; speech recognition
TN912.34
A
1000-3630(2017)-01-0050-07
10.16300/j.cnki.1000-3630.2017.01.010
2016-07-20;
2016-09-29
国家自然科学基金(61461011)、教育部重点实验室2016年主任基金(CRKL160107)资助项目。
王群(1990-), 男, 湖北随州人, 硕士研究生, 研究方向为语音信号增强、语音识别。
郑展恒, E-mail: glzzh@guet.edu.cn
