基于Python的“地理处理”并行方案
2017-10-17杨霄翼
杨霄翼
(国家测绘地理信息局 第三地理信息制图院,四川 成都 610100)
0 引 言
由美国环境系统研究所(ESRI)研发的ArcGIS系列平台软件中的地理处理(GP)几乎包含了地理处理的全部核心功能和工具模块,是软件的精华所在,也是其被广泛应用的原因之一[1]。为实现高效执行地理数据分析、数据转换、数据管理和地图自动化创建等GP功能,ESRI构建了基于Python编程语言的Arcpy站点包,Python通过Arcpy调用全部的GP工具[2],已在多个领域得到广泛推广与应用[3-6]。
随着一个城市、一个国家乃至全球地理空间数据的综合处理需求日益增加,待处理的时空数据量呈现爆发性增长,为此装配多核CPU以及高速存储设备的高性能计算机(HPC)在GIS领域被广泛采用。而常规方式下,利用Arcpy调用GP处理空间数据时,CPU不能满载,即不能充分利用机能,导致数据处理效率偏低的问题愈发突出。并行处理是充分发挥多核CPU强大运算能力的有效途径,因此实现GP的并行化执行,不仅能延续其既有优势,还能实现一定硬件环境条件下地理数据处理效率的最大化,具有十分广阔的应用价值。
1 GP工具
1.1 GP工具特点分析
GP工具作为ESRI所打造的GIS平台的核心组成部分,因其全面性、专业性和易用性,在诸多与地理空间科学有交集的学术和工程领域得到应用。工具的使用方式包含了常规的ArcToolBox访问[1]、ModelBuilder可视化编程方式[7],以及Arcpy独立模块访问方式[8]。但这3种方式均无法自动利用计算机全部的运算能力,只因待执行的多个GP工具任务将会以“串行”的方式逐个执行,这是导致迭代型地理处理任务的执行过程只利用了单核心运算能力,进而影响执行效率的根本原因。Python是一种模块化设计的,具有简洁和高可读性语法的高级编程语言[9],且支持多种方式的并行编程[10],Arcpy站点包的访问方式在Python语言的框架内实现了GP工具调用的高度灵活性,也为GP工具并行运行提供了可能。
1.2 GP工具运行机制
利用Arcpy调用GP工具可分为函数方式和工具箱别名方式,两者没有本质的区别,通常使用函数式[11]。函数以GP工具命名,参数在函数被调用时直接传递,若GP工具执行完毕,函数将返回Result对象,执行中断则会抛出异常。
GP工具的执行默认为串行机制,用户只能通过改变相关的隐含参数,如默认工作空间、矢量数据XY分辨率和容差、处理范围等环境变量的方式干预执行过程,起决定性作用的是非隐含输入参数和输入数据。其中,前者是指数值或字符串变量,后者指文件类数据,即地理处理任务直接相关的数据文件。因此,根据数据文件在单个GP工具执行前后的存在方式,可以将其分为以下四类,如图1所示。
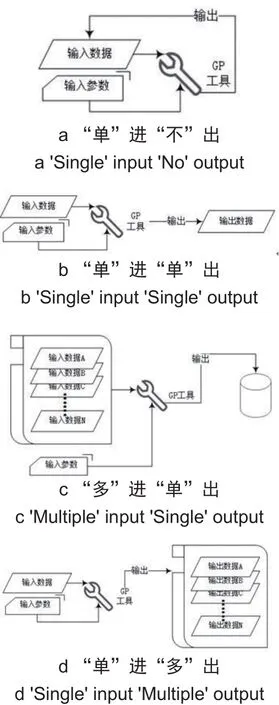
图1 GP工具分类Fig.1 Classification of GP tools
a类工具的特点表现为,输入数据被GP工具直接修改,无新的文件类数据输出,如定义空间参考、字段计算工具等;b、c、d均有异于输入文件的成果数据输出,b中的输入输出端均为单一文件,如构建栅格金字塔、投影变换等;c和d分别在输入端和输出端存在多种数据文件的情况,常见于合并和分割类GP工具。当一个GP工具并行运行时,其所属类型从整体看会有不同。如裁切工具本属于b类,但若多个裁切结果需要放入同一个工作空间,则应归为c类。
2 GP工具的Python并行实现方案
基于Python语言的并行编程技术发展至今,形成了5种模式,分别是:异步编程模式、分布式并行模式、GPU并行模式、基于多线程的并行模式和基于多进程的并行模式[10]。其中,异步编程模式适用于因复杂任务中的子任务争夺运算资源,而需要在程序运行期间协调CPU使用权的情况;分布式并行模式应用于集群运算;GPU并行模式则应用于图形及科学运算[10]。因此,“多线程”和“多进程”是GP工具并行运行的主要实现方式。
线程是程序执行的最小单位,而进程包含至少一个线程,是资源管理的最小单位,多线程之间共享内存资源,通信相对容易,且生成新线程的开销远小于新进程[12]。但是由于Python语言使用了全局解释锁(Global Interpretor Lock,GIL)[12],导致CPU在同一进程的同一时刻只会执行一个线程。当前GP工具默认的串行执行方式不能充分利用CPU运算能力,故希望并行状态下,能让多个工具分别利用CPU的多个核心,实现运算能力的最大化利用,因此“多进程”模式才能满足需求。
目前,被ArcGIS产品所支持的Python语言版本为2.7或3.4,其标准库中,以multiprocessing模块为基础,可将待并行运行的代码以函数形式传递给进程对象,从而实现“多进程”编程。对进程总数的动态控制方式分为进程池控制和逐个控制2种,前者通过multiprocessing模块中的Pool对象实现:在开始并行时,给定进程数量的最大值,整个并行过程,每个进程动态地获取任务,适用于待并行的函数代码,此处即为GP工具,具有唯一性的情形;后者需要利用Process对象:在开始并行前,配置不同GP工具信息列表,并为不同工具分别启动进程,且该进程在执行一次后结束生命周期,适用多种工具的并行。由于地理处理任务中,不同类工具通常位于工作流的不同阶段,多个工具并行的实际需求可以拆分为单个工具各自相继并行,所以进程池控制方式适用范围更广。
3 关键技术问题
并行运行的难点在于解决数据竞争、同步通信等关键技术问题[13]。而在基于Arcpy的地理处理任务中,类似问题需要根据GP工具的特点寻求相应解决方案。
3.1 非数据竞争型
对于a类工具而言,由于处理过程直接修改输入数据作为输出数据,没有数据竞争以及通信问题。因此,利用multiprocessing站点包建立进程池,动态映射任务,即可实现并行。其核心代码如下:
import multiprocessing #导入多进程支持模块
def dispose_parameters_list(): #编写函数配置GP工
具所需的参数列表
……
return parameters_list #返回参数列表
def gp_tool(parameters): #编写GP工具函数,在其中实现具体的地理处理
……
if __name__=='__main__':
parameters_list = dispose_parameters_list #调用函数
p = Pool(multiprocessing.cpu_count) #以当前CPU物理核心数作为最大进程数,建立进程池
p.map(gp_tool, parameters_list) #映射函数与对应的参数,并启动并行
p.close() #关闭进程池
p.join() #阻塞主进程
3.2 数据竞争型
图1中b、c、d三类工具都存在数据竞争的可能,由于进程具有相对独立性,所以,改造后的GP工具执行时,竞争将只会发生在输入或者输出端。
3.2.1 输入端竞争型
为了保证GP工具在运行过程中,输入地理数据的稳定性,ArcGIS会为不支持共享方式访问的数据资源设定文件独占锁[14],排斥处理过程中其他应用程序或进程对数据的访问,这是造成输入端竞争的原因。表1列举了常见的数据文件类型的独占锁特征。
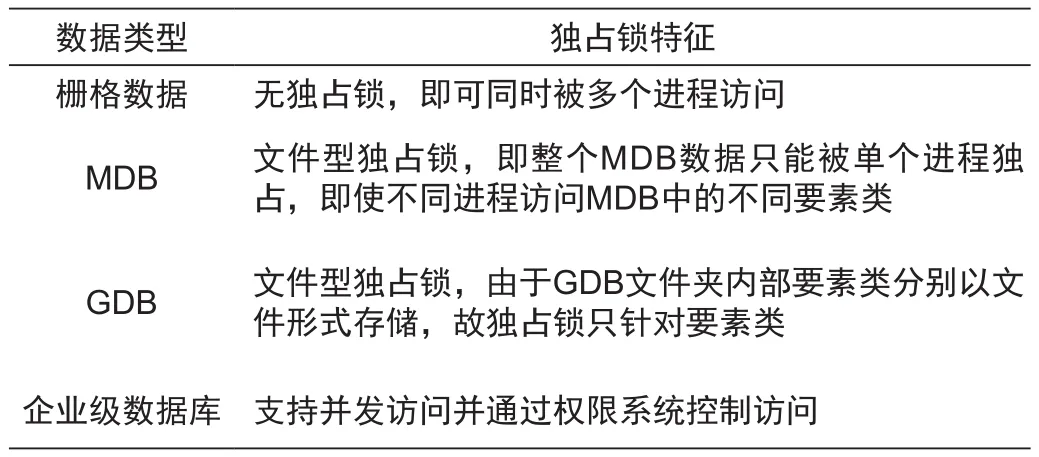
表1 常用数据类型独占锁特征Tab.1 Characteristic of exclusive lock for common data type
为了消除输入端竞争,也为了减少磁盘IO的时间消耗,需要利用multiprocessing模块所包含的进程锁以及ArcGIS所独有的“内存工作空间(in_memory)”特性。其中,进程锁是保证共享资源在某一时期内,被某个进程独占而避免访问冲突的一种特殊对象。在创建进程时,给每个进程传递一个所有子进程可共享的全局对象进程锁,当某个进程需要访问数据前,获取进程锁,确保对数据的独占访问,并在访问完毕后释放进程锁,可保证数据在不同进程的GP工具执行过程中的正常访问和输入。“内存工作空间”是一个可写入工具输出要素类、表和栅格数据集的、基于操作系统内存的工作空间[15]。由于存储于内存中,所以其读写速度显著优于永久性存储设备,常用于存放中间数据。在前述读取数据的过程中,若被读取的数据将被同一进程中反复使用,便可在首次读取时,直接存放于内存工作空间中,既避免了此后的数据竞争,更可提高处理效率。
为了使用进程锁,需要在前述实现方式基础上,编写初始化函数并传递进程锁。
from multiprocessing import Pool,Lock
……
def gp_tool(parameters):
lock.acquire()
#在独占状态处理输入端数据
lock.release()
def init(l): #初始化函数
global lock #表明为全局变量
lock=l #用进程锁给全局变量赋值if __name__=='__main__':
lock_in = Lock() #得到一个进程锁对象……
p = Pool(multiprocessing.cpu_count(),initiali
zer=init,initargs=(lock_in,))#传递给每个新建
立的进程
p.map(gp_tool, parameters_list) #启动并行
3.2.2 输出端竞争型
c类工具常出现输出端竞争,与输入端竞争不同的是,此时需要以成果数据为导向,并根据中间数据的存在形式,设定相适应的解决方案。
对于不受内存工作空间支持的中间数据,只能以进程锁为基础,在每次执行完毕前写入目标工作空间;相反,通过内存工作空间存放中间数据则能优化该过程,将数据的磁盘写入次数减少至并行进程总数,为此需要确定写入时机。通过提前为每个进程确定任务列表,以多进程间共享内存的Value对象记录任务进度,在进程生命周期结束前,将内存工作空间中的数据写入目标工作空间。核心代码如下所示:
from multiprocessing import Pool,Value def init(c,l): #初始化函数
global counter,lock
counter = c; lock = l#用进程锁给全局变量赋值def gp_tool(parax):
counter.value+=1 #更新已分配任务数,可掌握处理进度……#将单个进程每次处理的成果数据存放在’in_memory’空间
#若子任务清单已完成则转移数据至目标工作空间if __name__=='__main__':
counter_in = Value('i',0) #创建为整型变量
lock_in = Lock() #得到一个进程锁对象#分拆任务总清单为与进程数相协调的子清单#如paras 分拆为 para0 para1等
p = Pool(multiprocessing.cpu_count(),initiali zer=init,initargs=(counter_in,lock_in))
#传递给进程池中的进程
i = 0
for i in range(0, multiprocessing.cpu_count()):
p.apply_async(gp_tool, (eval('para'+str(i)),))#以非阻塞方式并行
i+=1
4 实验与分析
选用大比例尺地形图生产中常见的“按照标准分幅图框裁切总数据库”的地理处理任务,构建前述并行运行方案,在一台当前常见的工作站上对比测试传统方式与并行运行方式的硬件资源使用情况及数据处理效率。测试平台的关键参数见表2。

表2 平台配置Tab.2 Configuration of test platform
待处理数据库为某测区1:500地形图MDB总数据库,文件体积约50兆字节,实际面积约25km2,共包含30个要素类,使用测区范围内100个250m×250m标准分幅图框,以不同方式裁切该库,选取图号作为文件名,裁切结果保存为GDB格式数据库,得到以下测试数据。
测试结果表明,传统方式耗时最长,硬件资源使用率最低;1个进程的并行模式实为串行执行,但因为利用了“内存工作空间”特性,减少了磁盘IO次数,效率提高较显著;开启8个进程利用多核处理能力后,耗时缩减至传统方式的1/5,此时CPU负载过半,但加倍进程数至16个,处理效率提升不明显,此时瓶颈为硬盘IO负载。

表3 测试结果Tab.3 Test result
5 结束语
传统运行方式下,地理处理任务中的多个GP工具会以“串行”的方式逐个执行,不能充分利用多核高性能计算机的运算资源,导致任务执行效率低下。通过基于Python的Arcpy站点包方式调用GP工具可以实现并行运行,综合分析后得到“多进程模式”是适用于GP工具并行运行的Python并行编程模式。利用multiprocessing站点包的Pool类实现了基础形式的并行,并利用Lock进程锁、Value进程通信以及非阻塞并行方式,消除了输入端竞争和输出端竞争,结合ArcGIS所独有的“内存工作空间”特性构建的解决方案,达到了工具执行效率的最大化。测试结果表明,并行运行的效率较传统方式提升显著,若能突破硬盘IO瓶颈,则效率可进一步提高。
