基于改进CFSFDP算法的电信投诉文本聚类方法
2017-10-17张天宇谌志群黄孝喜王荣波
张天宇,谌志群,黄孝喜, 王荣波
(杭州电子科技大学 计算机学院,浙江 杭州 310018)
基于改进CFSFDP算法的电信投诉文本聚类方法
张天宇,谌志群,黄孝喜, 王荣波
(杭州电子科技大学 计算机学院,浙江 杭州 310018)
为了提高电信服务质量,增强企业竞争力,对电信投诉文本进行聚类,方便电信运营商分析投诉原因,文中提出了基于改进CFSFDP算法对电信投诉文本进行聚类的方法。通过差分进化算法寻找CFSFDP算法中最优密度阈值和距离阈值,降低密度及距离阈值的随机性选取对聚类准确率造成的影响。该算法使用Gaussian Kernel计算数据点密度,降低参数对密度计算的影响。在电信投诉文本数据集上的实验结果显示,改进CFSFDP算法聚类结果达到了与K-Means算法、CFSFDP算法、Agglomerative Clustering算法更好或者相当的效果,证明了算法的有效性。
CFSFDP算法;文本聚类;电信投诉;密度;距离;差分进化
AbstractTo improve the accuracy of the service quality, and enhance enterprise competitiveness,clustering of telecom complaints text is helpful for telecom operators to analyze the reasons of complaints, This paper proposed a clustering method for telecom complaints text based on the improved CFSFDP algorithm. To reduce the effects on the method by random select of optimal density and distance threshold for CFSFDP, the method searches density threshold and distance threshold using differential evolution algorithm. The algorithm calculates the density of data points using the Gaussian Kernel, to reduce the effects of parameters on density calculation. Experiments on datasets of telecom complaints text show that clustering result of improved CFSFDP algorithm is better than k-means algorithm,CFSFDP algorithm and agglomerative clustering, the algorithm is effective.
KeywordsCFSFDP algorithm;text clustering; telecom complaints; density; distance; differential evolution
在电信运营商同质化的业务和服务下,客户对服务质量有更高的要求。客户投诉是客户对电信业服务不认可而提出的疑义。它不仅数量庞大,而且种类繁多。采用文本聚类[1]技术,深入分析客户投诉内容,及时发现客户投诉热点,对电信运营商提高服务质量具有重要意义。
目前,通用的聚类算法主要有基于划分的方法、基于层次的方法、基于密度的方法、基于网格的方法以及基于模型的方法[2-3]。而对文本数据集进行聚类的常用方法有基于划分的聚类方法和基于层次的聚类方法。但是在数据集形状较复杂的情况下,传统聚类算法的准确率一般较低。CFSFDP(Clustering by Fast Search and Find of Density Peaks)是一种新的密度聚类算法[4],该算法具有能有效处理复杂形状数据集、算法效率高、不需要指定类别个数等优点。通过分析现有文本聚类算法的局限性,本文提出一种改进的CFSFDP电信投诉文本聚类方法。
1 CFSFDP算法
1.1 CFSFDP算法原理
CFSFDP作为一种基于密度的聚类方法,算法的大致步骤是:寻找数据集的聚类中心,对剩余数据点归属完成聚类。聚类中心通常具有以下特点:密度较周围数据点的密度大;与其他密度更大的数据点之间的“距离”相对更大。
1.2 局部密度与距离
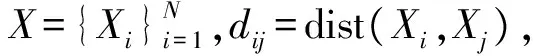
(1)

距离是指数据点i与密度较它高的最近点的距离。定义为
(2)
通过计算密度及距离得到密度大且与其它更高密度点距离大的点作为聚类中心。计算剩余数据点到各个聚类中心的距离,将数据点归属到距离其最近的聚类中心,完成聚类。
2 差分进化算法
差分进化算法[5-7]是一种基于变异、交叉、选择的全局优化算法。该算法通过模拟生物进化的过程,在反复迭代的基础上淘汰了不适应环境的个体,而保存了适应环境的个体。算法的基本思想:首先从随机产生的初始群体中随机选取两个个体,对选取的两个个体作差运算生成一个差向量。然后对差向量进行加权操作,将得到的加权结果与第3个个体按照一定的规则进行求和产生一个变异个体,此过程即为变异操作。将变异操作中得到的变异个体与某个预先决定的目标个体进行参数混合生成一个试验个体,此过程即为交叉操作。比较试验个体与目标个体的适应度值。若目标个体其适应度值优于试验个体的适应度值,则保存目标个体;否则,保留试验个体。此过程即为选择操作。通过差分进化算法对多个个体进行操作,使个体在每次迭代过程中朝最优目标进化,从而得到最优解。
3 CFSFDP聚类方法
在对电信投诉文本聚类时,将N条投诉文本划分成k类,其目的是使各个类中投诉文本内容的相似度较高而类间投诉文本内容的相似度较低。
3.1 算法流程图
算法流程图如图1所示。关键步骤包括:文本预处理,数据点密度及距离的计算,寻找最优参数组,数据点归属完成聚类。

图1 算法流程图
3.2 算法步骤
步骤1所需数据准备以及初始化参数。设原始投诉文本集为X;已知划分数据集为P;最大进化代数为g;种群数量为m;缩放系数为F;交叉概率为CR;
步骤2文本预处理。对电信投诉文本进行特征词提取并构建领域词库。使用Pythonjieba分词程序对电信投诉文本进行分词,并通过与构建的词库对照,提取特征词。计算特征词的权重tfidf(d,t);
步骤3计算密度及距离。将步骤2中得到的每个向量作为一个数据点,对数据点计算各自的密度以及比当前数据密度大的所有数据点中的最小距离;
步骤4寻找最优参数组。通过差分进化算法初始化参数群体。初始化群体时首先对密度及距离参数给定阈值范围,然后随机产生k组阈值范围内的参数并进行实数编码,将其作为初始种群;利用生成的阈值参数选择聚类中心;对数据点归属完成聚类,并通过适应度函数计算出参数个体的适应度值;判断算法是否达到最大进化代数或适应度值是否达到最小值,满足上述条件之一,输出相应的参数组,此阈值参数组为最优参数组;否则重复该步骤直到满足算法终止条件;
步骤5完成聚类。对步骤4得到的参数组选择聚类中心,通过数据点归属完成聚类。
3.3 适应度函数
差分进化算法需要定义一个适应度函数来反应聚类结果的好坏。本文采用Rand系数的倒数作为适应度函数。适应度函数f(x)计算方式如下[8]
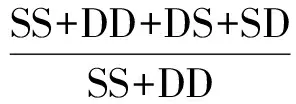
(3)
设经算法产生的聚类结果为:C={C1,C2,…,Ck2},设此聚类集为A;已知聚类为P={P1,P2,…Pk1},设此聚类集为B。适应度函数中有变量SS,SD,DS,DD,其计算方式分别如下
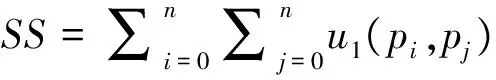
当某两个数据点满足在A中属于同一类且在B中也属于同一类时,有u1(pi,pj)=1,否则u1(pi,pj)=0;当某两个数据点满足在A中属于同一类但在B中不属于同一类时,有u2(pi,pj)=1,否则u2(pi,pj)=0;当某两个数据点满足在A中不属于同一类但在B中属于同一类时,有u3(pi,pj)=1,否则u3(pi,pj)=0;当某两个数据点满足在A中不属于同一类且在B中也不属于同一类时,有u4(pi,pj)=1,否则u4(pi,pj)=0;
3.4GaussianKernel密度计算
由于CutoffKernel计算密度的方式过高地依赖于数据集的特征,其密度值会因统计错误而受到影响[4]。本文采用GaussianKernel[4]来计算局部密度,计算公式如下
(4)
此外,本文采用向量空间模型[9]对文本进行向量化表示,使用tfidf[10]计算特征词权重。文本相似度计算[11]通过欧式距离实现。
4 实验与结果分析
为了验证本文所提算法的可行性和有效性,提取部分电信用户投诉文本,应用本文所提算法进行聚类。此外,对基本的CFSFDP[4]算法,K-Means[12]算法以及AgglomerativeClustering[13]算法在相同数据集上进行实验并对比。所有实验都在i5处理器,8GB内存,Windows7操作系统上进行,使用Python实现具体算法。
实验中从电信投诉文本中抽取了5 000条由电信运营商提供的用户投诉记录。抽取的投诉文本类别与数目分别如下:宽带类1 599条,固定电话类277条,itv类241条,流量类375条,套餐类741条,短信类181条,赔退类471条,费用类857条,其它类258条。其中,其它类表示投诉文本数量比较少但是存在的类别。
4.1 评价指标
本文通过引入聚类精度(Accuracy,AC)、纯度(Rrecision,PR)、召回率(Recall,RE)和F值(F1)[14-15]4个评价指标来评价聚类算法的性能。设P={P1,P2,…,Pk1}为数据集X的人工聚类,C={C1,C2,…,Ck2}为聚类算法对数据集X的聚类结果,nij=|Ci∩Pj|为Ci和Pj的共同部分的基数,bi是Ci中的对象个数,dj是Pj中的对象个数。则上述4个评价指标公式如下
(5)
(6)
(7)
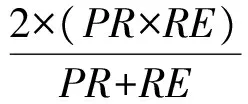
(8)
4.2 实验结果分析
分别用本文算法、基本的CFSFDP算法、K-Means算法、AgglomerativeClustering算法对抽取的5 000条记录进行聚类。对K-Means算法、AgglomerativeClustering算法给定具体类别数目9。设置差分进化算法种群数量为20,缩放因子为0.5,交叉概率为0.9。
通过表1的实验结果可以看出,本文算法在电信投诉文本中的聚类结果相比其他3种聚类算法都有所提高。由于电信投诉文本较复杂、存在噪声点等特点,使得基本的CFSFDP算法在确定聚类中心时,会出现错选、漏选、多选聚类中心的情况,因此导致CFSFDP算法的聚类效果不佳。K-Means算法随机选取初始中心点的策略导致其聚类准确率下降。另外,K-Means对噪声点敏感的特点进一步影响了K-Means聚类的准确率。AgglomerativeClustering算法在聚类过程中由于存在不能更正错误的缺陷,在复杂的数据集中会导致聚类效果的降低。此外,该算法的时间复杂度过高,不适用于大型数据集。本文提出的改进后算法针对传统的CFSFDP算法的缺陷,作了相应的改进。通过实验对比,证明了改进后算法的有效性。
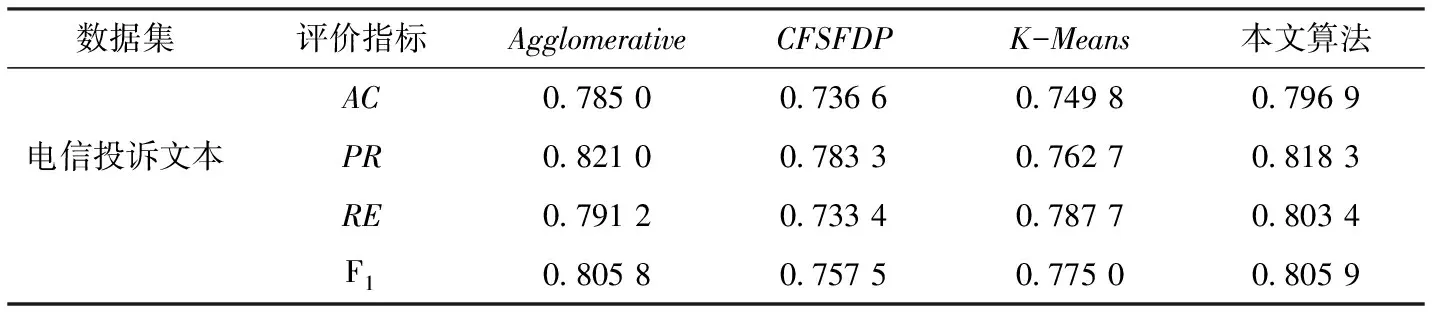
表1 4种算法的AC、PR、RE、F1值比较
5 结束语
本文针对CFSFDP算法过于依赖密度与距离值而导致聚类效果不佳的问题,对CFSFDP算法进行改进。通过引入差分进化算法寻找最优密度、距离值,降低CFSFDP算法对阈值参数的依赖性,提高了算法准确率。作者用GaussianKernel公式代替CutoffKernel公式来计算数据点密度,在一定程度上降低了截断距离对数据点密度计算的影响。实验结果表明,在投诉文本聚类中本文提出的改进CFSFDP算法比常见的文本聚类算法有着更好或者相当的效果。本文研究对电信投诉文本的智能分析与挖掘提供了新方法,对电信运营商把握客户投诉热点,提升客户满意度具有重要的实践价值。
[1]VermaVK,RanjanM,MishraP.Textminingandinformationprofessionals:Role,issuesandchallenges[C].Noida:InternationalSymposiumonEmergingTrendsandTechnologiesinLibrariesandInformationServices,IEEE, 2015.
[2]SunJG,LiuJ,ZhaoLY.Clusteringalgorithmsresearch[J].JournalofSoftware,2008,19(19):48-61.
[3] 王虹,孙红.基于混合聚类算法的客户细分策略研究[J].电子科技,2016,29(1):29-32.
[4]RodriguezA,LaioA.Machinelearning.Clusteringbyfastsearchandfindofdensitypeaks[J].Science, 2014, 344(6191):1492-1496.
[5]KarwaS,ChatterjeeN.Discretedifferentialevolutionfortextsummarization[C].Bhubaneswar:InternationalConferenceonInformationTechnology,IEEE,2014.
[6] 刘亚丹,古发辉.差分进化算法研究进展[J].科技广场,2013(3):20-23.
[7]LiGY,LiuMG.Thesummaryofdifferentialevolutionalgorithmanditsimprovements[C].Chengdu:InternationalConferenceonAdvancedComputerTheory&Engineering,IEEE, 2010.
[8]HalkidiM,BatistakisY,VazirgiannisM.Onclusteringvalidationtechniques[J].JournalofIntelligentInformationSystems, 2015,17(2-3):107-145.
[9]SaltonG,WongA,YangCS.Avectorspacemodelforautomaticindexing[M].NewYork:MorganKaufmannPublishersInc.,1997.
[10]CaoNieqing,CaoJingjing,LuHaili,etal.SentimentclassificationusingTF-1DFfeaturesandextendedspaceforestensemble[C].Guangzhou:InternationalConferenceonMachineLearningandCybernetics,IEEE,2015.
[11] 谭静.基于向量空间模型的文本相似度算法研究[D].成都:西南石油大学,2015.
[12] 吴夙慧,成颖,郑彦宁,等.K-means算法研究综述[J].现代图书情报技术,2011(5):28-35.
[13] 段明秀.层次聚类算法的研究及应用[D].长沙:中南大学,2009.
[14]LiangJ,BaiL,DangC,etal.TheMeans-typealgorithmsversusimbalanceddatadistributions[J].IEEETransactionsonFuzzySystems, 2012,20(4):728-745.
[15] 张鸣.符号数据聚类评价指标研究[D].太原:山西大学,2013.
Clustering Method for Telecom Complaints Text Based on Improved CFSFDP Algorithm
ZHANG Tianyu, CHEN Zhiqun, HUANG Xiaoxi, WANG Rongbo
(School of Computer Science, Hangzhou Dianzi University, Hangzhou 310018,China)
TP391
A
1007-7820(2017)10-093-04
2016- 12- 06
国家自然科学基金青年基金(61202281);杭州电子科技大学“管理科学与工程”省高校人文社科重点研究基金(ZD04-201402)
张天宇(1992-),男,硕士研究生。研究方向:中文信息处理。谌志群(1973-),男,副教授。研究方向:中文信息处理。黄孝喜(1979-),男,博士,副教授。研究方向:语言认知计算。王荣波(1978-),男,博士,副教授。研究方向:自然语言处理。
10.16180/j.cnki.issn1007-7820.2017.10.025
