基于FPGA的脉冲神经网络加速器设计
2017-10-17沈阳靖沈君成
沈阳靖,沈君成,叶 俊,马 琪
(1.杭州电子科技大学 微电子CAD研究所,浙江 杭州 310018;2.浙江大学 超大规模集成电路研究所,浙江 杭州 310007;3.杭州士兰微电子股份有限公司,浙江 杭州 310007)
基于FPGA的脉冲神经网络加速器设计
沈阳靖1,沈君成2,叶 俊3,马 琪1
(1.杭州电子科技大学 微电子CAD研究所,浙江 杭州 310018;2.浙江大学 超大规模集成电路研究所,浙江 杭州 310007;3.杭州士兰微电子股份有限公司,浙江 杭州 310007)
脉冲神经网络是一种基于离散神经脉冲原理进行信息处理的人工神经网络,文中提出了一种基于FPGA的灵活可配的脉冲神经网络加速器架构,能够支持神经网络拓扑结构、连接权值的灵活配置。该设计首先在算法层对LIF神经元模型进行公式分解和浮点转定点两个层次的优化,并在硬件实现中采用时分复用技术将硬件中实现的8个物理神经元复用为256个逻辑神经元。神经元模电压计算采用三级流水线架构,以提高神经元数据处理效率。通过采用Xilinx XC6SLX45 FPGA实现整个神经网络加速器,工作频率可达50 MHz,并基于该加速器构建手写数字识别网络架构,实验结果表明,采用MNIST数据集作为测试样例,该网络架构准确率可达93%。
脉冲神经网络;LIF模型;时分复用;分类
AbstractSpiking neural network is a kind of biologically-inspired neural networks that perform information processing based on discrete-time spikes. This paper proposes a FPGA based hardware accelerator, which supports the flexible configuration of topology and synapse weights. First, LIF(Leaky Integrate-and- Fire, LIF) model is optimized for hardware implementation, and then 8 physical LIF neurons are implemented, which could be extended to 256 neurons by using time-multiplexing technology. To improve the data processing efficiency of the spiking neuron, the design adopts three-stage pipeline architecture to calculate the neuron voltage. At last, the design is implemented on XC6SLX45 FPGA running over 50 MHz operation frequency. MINST database is used as an application example to demonstrate the configurability and efficiency of the proposed implementation. The experimental results show the accuracy of handwritten number classification could be achieved as high as 93%.
Keywordsspiking neuron network; LIF model; time-multiplexing technology; classification.
脉冲神经网络[1](Spiking Neuron Network,SNN)是一种基于离散神经脉冲进行信息处理的人工神经网络,采用可塑的突触和基于脉冲模式的编码,能够同时模拟神经网络的时空特性,具有更高的生物真实性, 可达到更好的性能功耗比,被称为第三代人工神经网络[3]。
目前脉冲神经网络以软件的实现方式为主,具有灵活性强、精度高的特点,但无法充分利用神经网络高并行性的特点,处理速度慢、功耗高[4]。为了充分挖掘脉冲神经网络并行性高、功耗低的特点,学术界逐渐开始采用专用集成电路实现脉冲神经网络, 目前根据实现方式的不同,神经网络芯片分为模拟和数字两大类。模拟电路由于其设计的复杂性,神经网络规模一般较小且受制造工艺、温度和电压的影响[5],芯片间神经网络的行为一致性无法保证,而数字集成电路适用于大规模神经网络架构的实现[6],且具有更高的稳定性和扩展性。FPGA(Field-Programmable Gate Array)作为一种特殊的数字集成电路实现方式,具有灵活可编程、计算资源丰富、开发周期短[7]等优点。FPGA广泛用于开发基于SNN的应用,文献[8]提到在单片FPGA上实现了达百万神经元规模的神经网络。因此,文中提出了一种基于FPGA的脉冲神经网络架构。
介绍了LIF(Leaky Integrate and Fire)神经元模型,并对模型的数学公式进行优化以适合硬件实现。SNN加速器利用时分复用技术将8个物理神经元复用为256个神经元,提高硬件资源的利用率,并采用三级流水线架构对神经元计算单元进行优化,显著提高数据处理效率。实验采用MINST手写数字字符库[9]对实现的SNN加速器进行功能验证。
1 神经元模型优化
神经元是类脑计算的基础,近年来研究者提出了从简单到复杂的多种不同抽象层次的神经元模型,如Izhikevich[10],Hodgkin-Huxley[11],LIF和DLIF模型[12]等。LIF模型计算复杂性适中且具有较高的生物精度,在硬件领域广泛使用。设计在保证精度的同时从两个方面对LIF模型进行优化:(1)分解计算公式,离散化膜电压变化函数;(2)浮点转定点,降低神经元模型的复杂性,提高运算的效率。
1.1 公式分解
神经元由指数式衰减的突触电流驱动,神经元的膜电位由与之相连并能够产生激励的突触权重值叠加而成,文献[13]提出LIF模型的计算公式如下
(1)
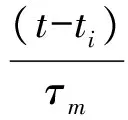
(2)
其中,ωi表示突触的权重值;ti表示第i个突触产生激励的时间;Vrest代表神经元的复位电压值;K代表突触后神经元膜电位;τm和τs是为突触电流的常数。在不影响神经元模型情况,将复位电压Vrest设置为0,因此式(1)可以简化为
(3)
式(3)中,V(t)在单位Δt时间内,电压变化没有规律性不适合FPGA硬件实现中数值的规律性离散变化,为了解决这个问题,将V(t)分解为Vfall(t)和Vrise(t)两部分
(4)
(5)
因此,未输入脉冲激励的情况下,Vfall(t)和Vrise(t)在单位Δt时间内的变化如式(6)和式(7)所示,为前一时刻的值乘以一个时间常数
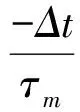
(6)
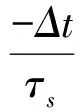
(7)
当突触 在时间 收到输入激励,膜电位通过Vfall(t)和Vrist(t)计算公式如下
Vfall(t)=Vfall(t)+V0ωi
(8)
Vrise(t)=Vrise(t)+V0ωi
(9)
当神经元在时间t产生激励V(t)≥Vth,Vth代表阈值电压,Vfall(t)和Vrise(t)复位到0。
1.2 浮点转定点优化
将LIF计算模型分解为式(6)~式(9)后,虽然能够满足硬件实现的需求,但所有的运算均为浮点运算,需要占用较多的硬件资源,不适合用于大规模神经网络的实现。因此,为使神经网络适合于FPGA的硬件实现,在保证精度的前提下需将浮点运算转化为定点运算。
将所有的权重值和阈值电压扩大β倍,并将因此相应产生激励的条件为V′(t)≥βVth,并不影响神经元的行为,而膜电位的表述如下
(10)
(11)
(12)
(13)
(14)
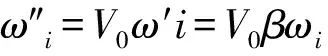
V[n+1]=Vfall[n+1]-Vrise[n+1]
(15)
Vfall[n+1]=A(Vfall[n]+wgt_sum[n])
(16)
Vrise[n+1]=B(Vrise[n]+wgt_sum[n])
(17)
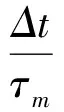
2 脉冲神经网络的硬件设计
2.1 脉冲神经网络整体架构
SNN加速器架构主要由路由控制单元、时延查找表、时延FIFO、脉冲神经元阵列、输入信息编码和输出信息判决等几部分组成,如图1所示。
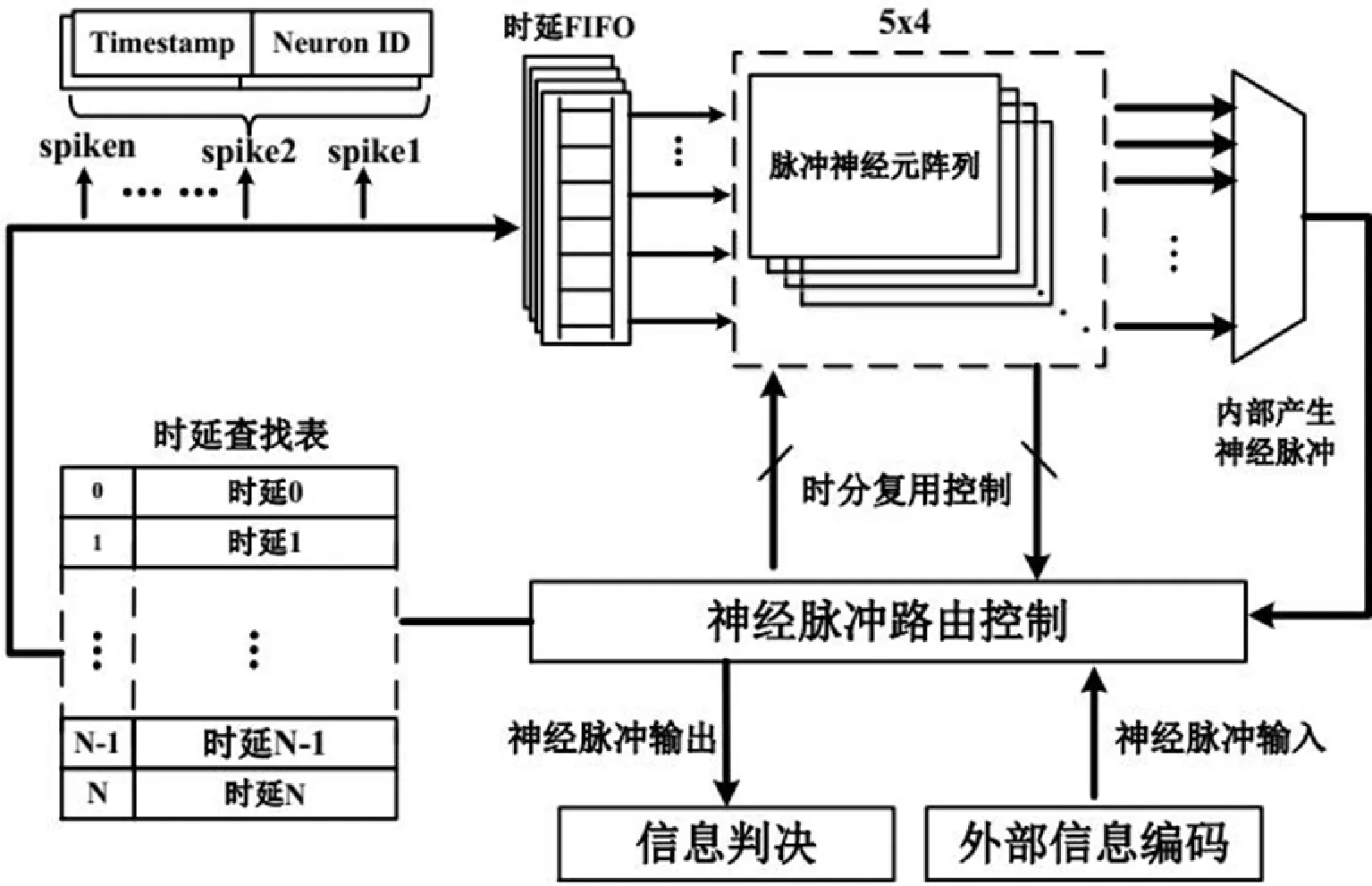
图1 脉冲神经网络整体架构
外部信息编码单元将外部的图像、声音等信息编码成脉冲信息。时延查找表包含脉冲到达神经元阵列的延时信息,用于模拟真实生物神经元的突触延迟。经过时延查找表后,每一个脉冲会被添加一个时间戳,SNN加速器支持16种不同的时间延迟。时延FIFO将当前时刻的神经脉冲输入到神经元阵列中,并对其它的神经脉冲作缓存。脉冲神经元阵列中实现了8个物理神经元,通过时分复用每个神经元可以模拟32个神经元膜电压的变化。当神经元膜电压超过阈值电压时,产生新的神经脉冲,并由路由控制器决定传回神经元阵列还是直接输出给信息判决单元。信息判决单元根据预先设置的判决条件,对目标信息进行分类。
2.2 单个LIF神经元的设计
数字集成电路的计算速度远高于生物神经元的真实计算速度,因此设计采用分时复用的技术来实现神经元阵列,以8个物理神经计算单元实现256个神经元。通过时分复用技术,在有限的FPGA资源内,显著地增加神经元的实现数目。单个LIF物理脉冲神经元复用的结构如图2所示。
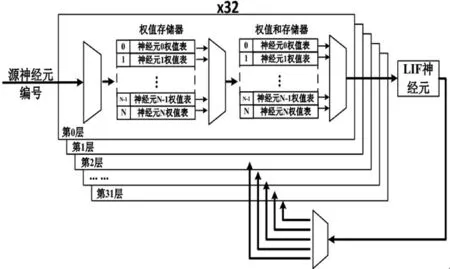
图2 单个LIF脉冲神经元复用结构
神经元间不同的连接方式具有不同的突触权重和延迟。权值存储器可根据神经网络结构灵活配置,由产生脉冲的神经元(源神经元)索引与其相连的所有目标神经元间的权重,并累加到对应的权值存储器中。当权重为0时,神经元之间没有连接,这样权值存储器就保存了每个神经元当前时刻接收到的脉冲之和。SNN加速器支持256个神经元之间的全连接且权重的精度为16位。因此,权值存储器的大小为256×256×2 Byte,权值和存储器的大小为256×3 Byte(权值和以24位精度保存)。
2.3 LIF神经元的流水线设计
LIF神经元采用流水线的结构提高系统的吞吐率。在实现的流水线技术中,包含3个阶段,每个阶段维持1个时钟周期。图3显示了输入权重和从存储器中提取的过程。流水线的第2阶段为第3阶段提供Vfall(t)和Vrise(t)的值。当膜电位超过阈值电压时,产生一个激励。LIF神经元的行为参见式 (15)~式(17),单个LIF神经元流水线计算如图3所示。

图3 LIF神经元流水线结构
2.4 LIF神经元的分类策略
信息判决模块根据配置的分类策略和输出神经元产生的脉冲刺激,对输入的信息进行分类。SNN加速器的分类策略如图4所示。
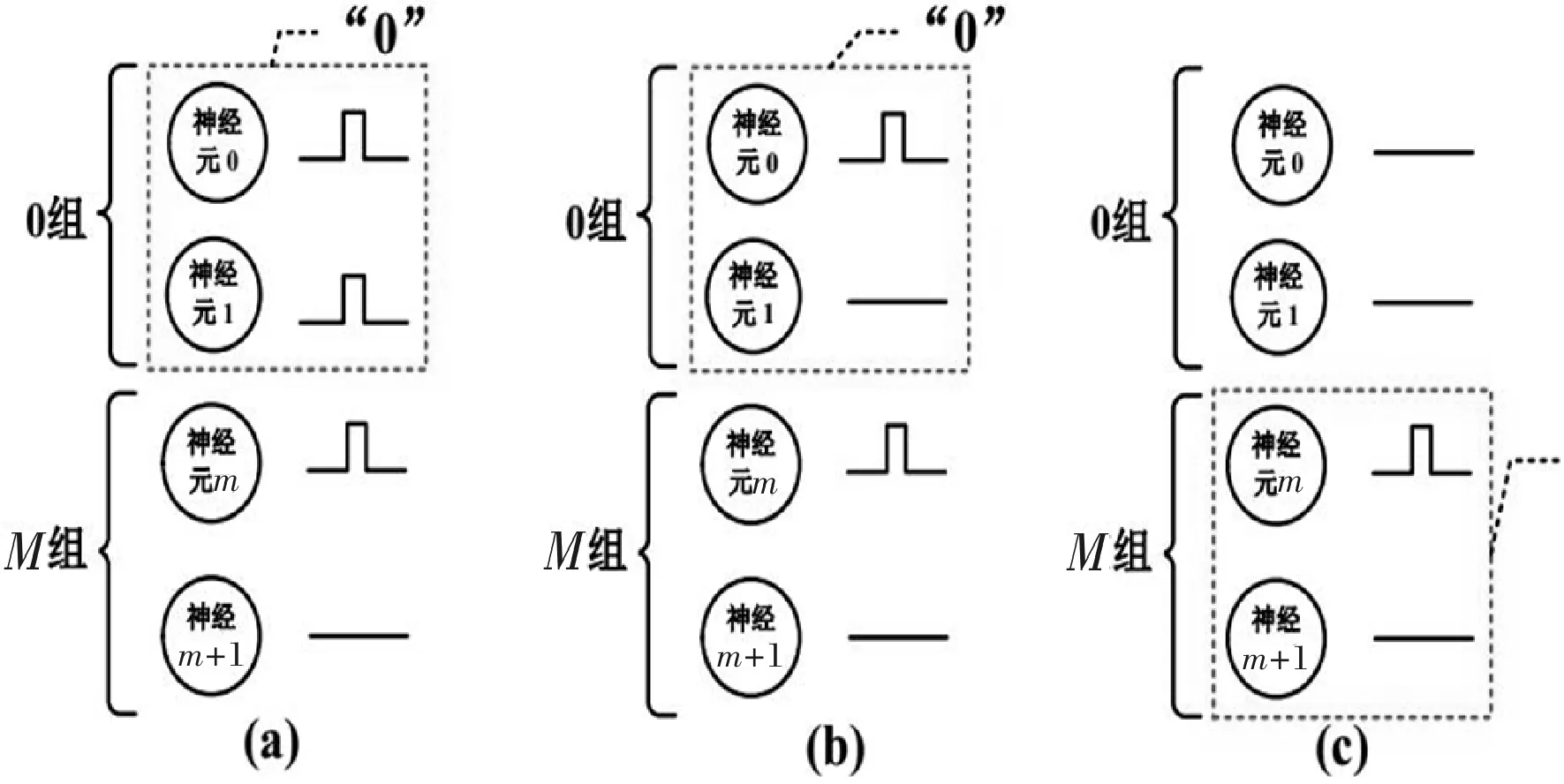
图4 SNN的分类策略
图4为手写数字识别应用的分类策略,20个输出神经元被分成10组,每组分别对应一个手写数字,2个神经元1组对应1个阿拉伯数字,哪一组产生的神经脉冲数量最多,该组对应的数字即为分类结果。当两组产生的脉冲数目相同时,数字越小的组优先级越高。如图4所示,图4(a)和图4(c)中系统优先分类那些包含更多输出神经脉冲的组,组所对应的数字即为分类的结果。图3(b)中,当两组包含的输出脉冲数目相同时序号低的组优先级更高。
3 实验结果及分析
采用Xilinx的Spartan6 XC6SLX45 CSG324 FPGA实现整个脉冲神经网络,FPGA的资源利用率如表1所示。

表1 Spartan6 XC6SLX45资源利用率
由表可知,Block RAM资源的使用率最高,这是限制脉冲神经网络规模的一个重要因素,脉冲神经网络利用存储器来存储激励时延、突触的权重值、神经元拓扑结构等参数。设计中每个神经元都采用了时分复用和流水线的技术设计,工作频率可到50 MHz。因此,完成一个神经元行为的模拟需耗时20 ns,一个物理神经元时分复用成32个,因此SNN加速器完成所有神经元的更新需要20 ns×32=640 ns。真实生物神经元处理脉冲激励的时长约为1 ms,SNN加速器的神经元的处理速度比实际的生物神经元约快近1 600倍。
与文献[14]提出的BP神经网络的输入、隐含、输出3层拓扑结构不同,SNN加速器配置成两层网络结构,分别对应输入层和输出层,两层之间采用全连接的方式,输出层神经元被分成10组分别对应分类结果数字0~9。设计对于输出层构建了5种不同的情况,每一组包含不同的神经元数目,分别为1~5个神经元,并通过离线方式训练这5种网络架构的连接权重,神经网络架构如图5所示。
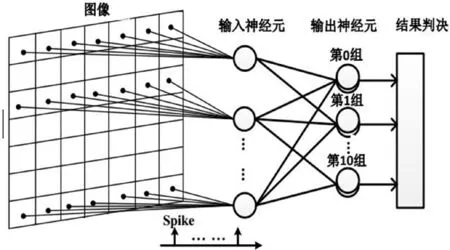
图5 神经网络架构图
手写数字识别库来自于MNIST数据集,其中训练集有60 000幅图像,测试集有10 000幅图像,每幅均为28×28像素的灰度图像,灰度值用0~255的整数表示。对每一个像素点进行编码,若像素图中的灰度值>128,则该数字的对应像素点产生一个脉冲,将一行像素点对应的脉冲按一定顺序输入到一个神经元中如图5所示。改变每组中神经元的数量来进行手写数字识别验证,实验结果如表2所示。
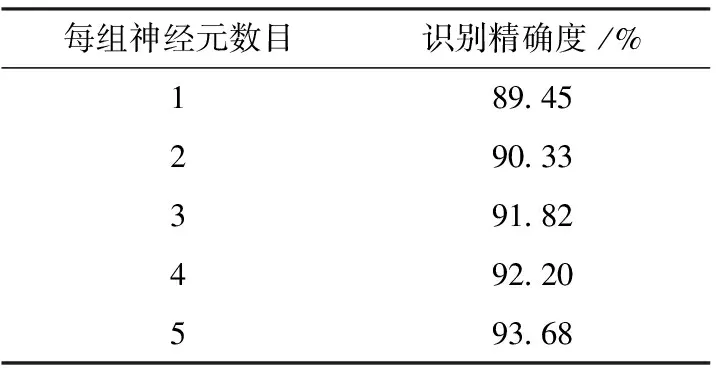
表2 每组不同神经元数目的识别精确度
将SNN加速器的神经网络架构与另一款基于Xilinx Spartan-6 FPGA实现的硬件加速Minitaur[15]做性能对比,结果如表3所示。由表可知,SNN加速器能够在较低的时钟频率下获得类似于Minitaur的计算性能和较好的识别精确度。
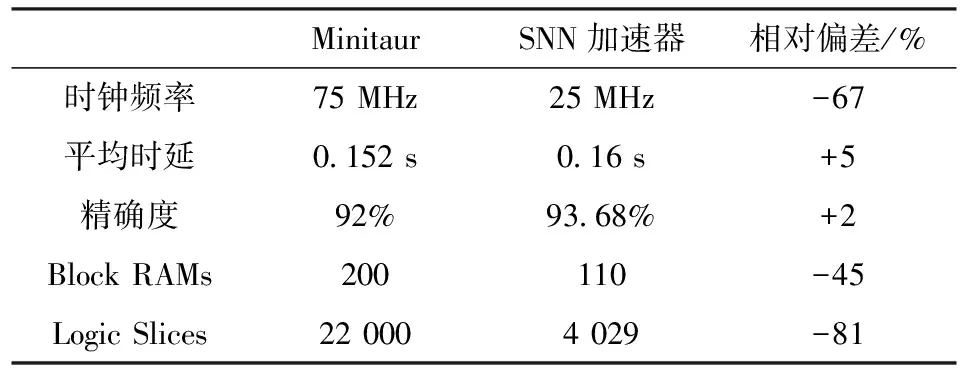
表3 SNN加速器和Minitaur性能的对比
4 结束语
介绍了一种基于FPGA的脉冲神经网络的加速器架构。设计以LIF神经元数学模型为基础,通过将LIF神经计算中的浮点数运算转化为定点数运算,用下降电压和上什电压计算后突触膜电位等优化,使LIF神经元模型更适合硬件实现。设计采用三级流水线架构实现LIF神经元模型,显著提高数据处理效率。该架构支持神经网络拓扑结构,神经元和突触各种参数的灵活配置,通过时分复用技术,使8个物理神经元最多支持256个神经元,满足嵌入式应用的需求。采用FPGA实现该神经网络架构,工作频率达50 MHz,采用MNIST数据集作为应用实例,准确率高达93%,性能相较于同类加速器有较大提什。然而,设计中神经网络的训练是线下完成的,神经网络一经配置神经元的权重值将保持不变,缺乏在线学习能力。下一步研究方向是如何提高神经网络的动态自适应能力[16]方面。
[1] 李利歌,阎保定,侯忠.基于FPGA的神经网络硬件可重构实现[J]. 河南科技大学学报:自然科学版,2009,30(1):37-40.
[2] Yu Qiang, Tang Huajin,Chen Kay,et al.Rapid feed forward computation by temporal encoding and learning with spiking neurons[J].IEEE Transactions on Neural Networks and Learning Systems, 2013, 24(10):1539.
[3] Maass W. Networks of spiking neurons,the third generation of neural network models[J].Neural Networks,1997,10(9):1659.
[4] 韩力群.人工神经网络理论、设计及应用[M]. 北京: 化学工业出版社,2002.
[5] 潘峥嵘,张赵良,朱菊香.基于SoPC的人工神经网络的硬件实现方法[J]. 电子测量技术, 2009,32(6):116-118.
[6] Cassidy A S, Georgiou J, Andreou A G. Design of silicon brains in the nano-CMOS era: Spiking neurons, learning synapses and neural architecture optimization[J]. Neural Networks, 2013, 45(3):4-26.
[7] 杨银涛,汪海波,张志,等. 基于FPGA的人工神经网络实现方法的研究[J]. 现代电子技术, 2009, 32(18):170-174.
[8]CassidyA,AndreouA,GeorgiouJ.DesignofaonemillionneuronsingleFPGAneuromorphicsystemforreal-timemultimodalsceneanalysis[C].Rio:Proceedingof45thAnnu,CISS, 2011.
[9]CiresanDC,MeierU,GambardellaLM,etal.Deep,big,simpleneuralnetsforhandwrittendigitrecognition[J].NeuralComput,2010,22(12):3207-3220.
[10]IzhikevichEM.Whichmodeltouseforcorticalspikingneurons?[J].IEEETransactionsonNeuralNetworks, 2004, 15(5):1063-1070.
[11]HodgkinAL,HuxleyAF.Aquantitativedescriptionofmembranepotentialanditsapplicationtoconductionandexcitationin[J].BulletinofMathematicalBiology, 1990, 117(1):500-544.
[12]CassidyA,AndreouAG,GeorgiouJ.DesignofaonemillionneuronsingleFPGAneuromorphicsystemforreal-timemultimodalsceneanalysis[J].InformationSciencesandSystems, 2011, 35(6):6-13.
[13]SteinRB.Atheoreticalanalysisofneuronalvariability[J].BiophysicalJournal, 1965, 5(2):173-194.
[14] 魏爽.基于BP神经网络的嘴型分类算法[J].电子科技, 2016 ,29 (8): 89-92.
[15]NeilD,LiuSC.Minitaur,anevent-drivenFPGA-basedspikingnetworkaccelerator[C].IEEETransactionsonVeryLargeScaleIntegrSystem,2014.
[16]SeoJS,BrezzoB,LiuY,etal.A45nmCMOSneuromorphicchipwithascalablearchitectureforlearninginnetworksofspikingneurons[C].California:CustomIntegratedCircuitsConference, 2011.
A FPGA Based Spiking Neuron Network Accelerator
SHEN Yangjing1, SHEN Juncheng2, YE Jun3, MA Qi1
(1.Microelectronics CAD Center, Hangzhou Dianzi University,Hangzhou 310018,China; 2.School of Computer Science, Zhejiang University,Hangzhou 310027,China; 3.Hangzhou Silan Microelectronics Co.,LTD, Hangzhou 310027,China)
TN912.11;TP183
A
1007-7820(2017)10-089-05
2016- 12- 05
国家自然科学青年基金(61404041)
沈阳靖(1991-),男,硕士研究生。研究方向:数字集成电路设计。沈君成(1991-),男,博士研究生。研究方向:数字集成电路设计。
10.16180/j.cnki.issn1007-7820.2017.10.024
