基于高性能云数据挖掘的算法研究∗
2017-10-16昂朝群
昂朝群 胡 炜 胡 冉
基于高性能云数据挖掘的算法研究∗
昂朝群1胡 炜2胡 冉1
(1.海军工程大学计算机工程系 武汉 430033)(2.中国人民解放军91919部队 黄冈 438000)
论文设计并实现了一种可以用于存档、分析、和挖掘大型分布式数据集的高性能云。文中定义云为一种可以提供互联网资源与(或)服务的基础设施。存储云提供存储服务,计算云则提供计算服务。高性能且能保持这些服务自身的有效性和效率不变,自然很合理地被预期作为实现大规模数据挖掘的中间步骤。论文提出了一种使用Sector/Sphere框架和关联规则的云数据挖掘方法,同时给出了由Sphere计算云和关联规则支持的编程范例。
Sphere;Sector;数据挖掘;云计算;高性能云
AbstractThis paper describes the design and implementation of a high-performance cloud to archive,analyze and mine large distributed data sets.By a cloud,an infrastructure that provides resources and/or services over the Internet.A storage cloud provides storage services,while a compute cloud provides compute services.High-performance can be reasonably intended as a in⁃termediate step of high-performance data mining activities over large-scale amounts of data,while still keeping unaltered the prima⁃ry and self-contained focus of achieving effectiveness and efficiency in these task themselves.In this paper an algorithm is proposed to mine the data from the cloud using Sector/Sphere framework and association rules,and also describe the programming paradigm supported by the Sphere compute cloud and association rules.
Key WordsSphere,Sector,data mining,cloud computing,high-performance cloud
Class NumberTP301.6
1 引言
高性能数据挖掘系统的设计需要利用处理器的强大和共享的优势,因为数据是通过消息传递实例计算并分布在各个处理器上的,然后所有的结果会被汇总而这个过程会在处理器出现新数据时重复[1]。数据挖掘是从不同角度分析数据并将它们归纳成有用的信息的过程,它可以帮助人们增加收益、减少开支。数据挖掘允许用户从不同的维度或者角度去分析数据,对数据进行分类,总结出确定的关系,而关联准则是寻找大型数据集数据项之间有趣关系的一种方法[2]。通过关联规则挖掘,本文已经确定了基于预定义支持的频繁项集。本文中,本文提出了一种基于完全不同范型的分布式高性能数据挖掘系统-Sector/Sphere。Sector用来为以分布式索引进行管理的大型数据集提供长期的持久存储。不同的分割碎片遍布在由Sector管理的分布式存储中。Sector通过复制数据以确保数据的寿命,减少检索它时的时延,提供并行处理的机会。Sector的设计利用了大面积高性能网络的优势。Sphere通过流处理模式并行执行用户定义函数来处理由Sector管理的数据。本文希望通过这样让相同的用户定义函数适用于每一个由Sector管理的数据集的数据记录。这将被用于独立处理每一个数据集碎片(如果有足够的处理器),实现一种自然的并行化。Sector/Sphere的设计将使数据频繁地被处理却不需要移动。总体来说,Sector分布式的,索引式的管理数据;Sphere使用用户定义函数在由Sector管理的数据流的统一方式下处理数据;本文将Sector/Sphere用于使用了专门设计的特定的网络原型的大面积高性能网络。数据挖掘是从大量的数据中提取有用和有趣的知识的处理过程。数据挖掘的知识模式有多种不同的类型,常用的模式有:关联模式、分类模型、类模型、序列模式等[3]。关联规则是一种依赖规则,它在其他项发生的基础上预测一个项是否发生。关联规则在帮助做出关于存储布局,追加销售等等商业决策时简单而有效。当大量的数据需要被收集和储存时,本文通常使用分布式系统实现关联规则挖掘。随着网络技术和分布式技术的发展,本文开始在分布式系统中存储数据库。因此在分布式系统中,关联规则挖掘的算法研究变得越来越重要,具有广阔的应用前景。分布式算法具有适应性强、灵活性高、磨损性低、易于连接等特点。通常情况下,一种规则的使用说明参加关于某个话题的课程的人们将获得关于这个话题的知识并可能改进规则。语义网的构建过程是目前一个非常活跃的领域。首先需要定义它的结构,然后在为它填满内容。为了让这个任务可行,本文应该先从简单的任务开始。
下面的步骤显示了语义网发展的方向:
1)为每一个机器可理解的描述提出一个通用的文法。
2)建立通用的词汇。
3)在逻辑语言上达成共识。
4)使用这种语言作为交换凭证。
Berners-Lee为语义网提出了一种层次结构。这种结构反映了上述的步骤。它遵循的理念是,每一步都会提供附加的价值,从而使语义网能够以一种渐进的方式来实现。云计算在当今计算机行业中是一种最具爆炸性增长的技术。云计算的实现通常使得用户可以将他们的数据迁移到一个遥远的位置同时也给系统性能带来了一些影响。但这也带来了一些无可替代的好处[4]。这样的好处包括:
1)可扩展性—云可以为满足任何用户的需求提供足够的计算能力。虽然在现实中基础设施是不可能无限的,但是云资源预计仍将缓解开发商对于任何具体硬件的依赖。
2)服务质量(QoS)—不像标准的数据中心和先进的计算资源,一个精心设计的云可以比传统的方式提供更高的服务质量。这是由于云不需要依赖具体的硬件,所以任何物理机械故障都可以减轻甚至不需要用户的预先注意[5]。
3)定制化—在云中,用户可以利用定制的工具和服务来满足他们的需求。这包括最新的库,工具包,或在新的基础设施内支持传统的代码。
4)计算代价—用户会发现每个项目都只需要硬件。这降低了机构想要建立一个可扩展的系统的风险,从而提供更大的灵活性,因为用户只需购买所需的基础设施就可以增加在未来所需要的服务。
5)简化的访问接口—无论是使用特定的应用程序,一组工具或网络服务,云都将以方便和以用户为中心的方式为用户提供大量的计算资源。
2 背景与相关工作
本文解决的问题属于数据挖掘和高性能计算的交叉领域。因此本文对这两个方面的相关工作都进行了调研。数据集的大小超过计算机的存储器容量是对于数据挖掘的一大挑战。这一问题可通过优化算法设计和抽样集成方法来缓解,而随着多处理器计算机以及最近的多核技术的发展,有效的并行执行算法可以实现更强的扩展性。但由于通信开销,对于超过8~16核的性能的提升无法有效实现以及数据集大小受系统中总可用内存的限制(一般为几千兆字节)的制约,这些方法仍存在着部分局限[6]。
2.1 关键特点
1)敏捷性:敏捷性随着用户快速而廉价地重新提供技术性基础设施资源能力的提高而提高。
2)成本:成本大幅减少,资本支出转化为运营支出。
3)多租户:实现多用户之间的资源和成本共享。供应商/独立软件开发商使用多租户最主要的原因是固有数据的聚合效益。所有用户的所有数据都存储在单独的数据架构中,而不是从多个数据源收集数据,从而导致可能存在不同的数据架构。
4)峰值负载能力:增加最高可能的负载水平。
5)利用率和效率:改进往往只有10%~20%利用率的系统。
6)可靠性:通过使用多个冗余位点来提高,这使得云计算更适合业务连续性和灾难恢复,尽管这样,仍需要许多大型的云计算。
7)可扩展性:通过动态的(“按需”)近实时的细粒度自服务式的资源配置提高可靠性,不需要用户设计高峰负载。使用网络服务作为系统接口,进行性能监控,建立一致的松散耦合体系。
8)安全性:由于数据的集中,安全性为重点的资源的增加等可以改善安全性,但是对于某些敏感数据的失控,存储内核安全性的缺乏,这样的问题仍然存在。
9)可持续性:通过改善资源利用率,使用更高效的系统,和碳中和来实现。然而,电脑和相关基础设施仍然是主要的耗能。
10)维护性:云计算应用更易于维护,因为它们不需要在每个用户的电脑里安装。它们更容易获得支持和改进因为更新可以立即达到客户端。
2.2 数据挖掘算法
云计算,有希望实现几乎无限的计算和存储资源,适合解决需要大量资源的计算问题。已经有对云计算中数据挖掘的一个问题从数据挖掘算法的角度进行了研究。将云计算强大海量的容量用于数据挖掘和机器学习。在他们的实验中,在云计算平台使用亚马逊网络服务的S3和EC2实现了三个算法,即全局效应(GE),K最近邻(KNN),受限玻尔兹曼机(RBM)。他们分别基于KNN模型和RBM模型建立了两个预测来测试他们基于云计算的平台的性能。
2.3 数据挖掘结构
云是使用网络提供资源和服务的基础设施。通常来讲,一个云计算平台包括,存储云,数据云和计算云,分别负责存储服务,数据管理和计算任务。
2.4 数据挖掘算法特性
在这个小节,本文通过GraphLab介绍几个高效的大型并行数据挖掘系统的关键特性,阐明其他并行框架为何没有这些特性。
2.4.1 图表结构计算
最近许多关于数据挖掘的最新进展都主要集中在数据间的依赖性,通过对数据依赖性建模,本文能够从有噪声的数据中提取更多的信号[7]。例如,对类似的购物者之间的依赖性进行建模,相较于单独研究顾客数据,本文可以做出更好的商品推荐。
2.4.2 异步迭代计算
许多重要的数据挖掘算法需要迭代更新大量的参数。因为底层的图形结构,参数更新(顶点或者边缘)依赖于(通过图的邻接结构)其他参数动态计算的值,而在很多数据挖掘的算法中,迭代计算收敛是不对称的[8]。例如,在参数优化中,通常大量参数会在几次迭代中快速收敛,然而剩余的参数会在很多次迭代后才慢慢收敛。
2.4.3 可串行性
通过确保所有的并行执行有相同的连续执行,串行化解决了设计,实现和测试并行数据挖掘算法中的许多问题。此外,很多算法如果可串行则会收敛得更快,甚至只有进行串行化才能保证其正确性。
3 方法与模型
3.1 分类
分类在数据挖掘中是一个重要的内容,也许也是研究最多的内容。在这里,数据集由一个包括许多属性的属性集表示,R=(a1,a2,…,aN),其中ai(i=1,2,…,N)是一个个属性。属性集可以划分为两部分:1)预测属性 C=(c1,c2,…,cm);2)分类属性 D=(d1,d2,…,dn)。
分类的准则为
如 果 (c1∈I1)∧(c2∈I2)∧…∧(cm∈Im),那 么(d1∈J1)∧(d2∈J2)∧…∧(dn∈Jn);
其中 Ii和 Jj(i=1,…,m;j=1,…,n)分别是 ci和dj的值。
“如果”的部分包含了条件,“那么”的部分包含了预测分类的标签。数据记录水平地分为两部分,训练集和测试集,它们互相独立。数据挖掘算法基于训练集发现分类的准则,用测试集来评估这些准则的分类性能。

图1 遗传算法
3.2 在云计算环境中分类准则挖掘
3.2.1 约束条件分析
云计算就是由分布式计算机集群构成硬件资源的网络。任务被划分为并行的段,并分配给可用的计算资源进行处理。在这种情况下,一个计算任务能否被云解决取决于任务的分解和并行性。云可处理的计算任务要求如下:
1)任务可以被划分为互相独立的子任务;2)子任务和数据可以被分配给未占用的处理节点;
3)处理节点间的同步和交流的机制是必不可少的。
3.2.2 模型描述
存储和计算资源分散在云环境中,服务器设定为中心控制来寻找和分配资源。服务器的任务为:首先,它将分配的任务分成几个子任务(在此,一个子任务可视作一个数据区),并把它们分配给分散处理的节点;此后,在服务器的监督下子任务在分散节点上执行;最终,服务器收集每个节点的处理结果并将它们合成为一个全面的分类准则作为挖掘的结果。
编程模型的伪代码为

3.3 算法设计
将规范的遗传算法进行改进用于云计算环境来挖掘分类准则。然而,改进的算法仍然遵循规范遗传算法的基本程序,包括编码,初始化,适应性评估,选择,交叉和变异。
3.3.1 编码
遗传算法的第一步是将代表个体的变量编码为比特串。匹兹堡和密歇根方法可以用于编码个体。在匹兹堡方法中,每个个体编码一组预测规则,然而在密歇根方法中,每个个体编码单个预测规则。当任务为分类时,规则间的相互作用很重要。
3.3.2 初始群体和适应度函数
数据集中的数据块被编码为二进制字符串来表示初始群体。在创造初始群体后,用一个适应度函数来衡量每个字符串的适应度,并给出一个适应值。
3.3.3 选择算子
使用“余数随机选择”作为选择过程,能更好地与预期的适应值匹配。
3.3.4 交叉算子
在选择过程后,发生交叉。较差是将成对的字符串进行重新组合以产生新的样本。根据概率Pc随机选择交叉点。交叉点之后的片段进行互换,产生后代。
3.3.5 变异算子
完成交叉后,就是变异了。按照一个较低的概率Pm对字符串中的每一个比特进行变异。如果对一个比特进行变异,这个比特的值在其范围内进行变化。在经过选择,交叉和变异后,产生了新的一代。
4 设计
4.1 Sphere的设计
4.1.1 概述
Sphere是一个基于Sector存储云的计算云。让本文以一个例子来介绍一下球。假设本文有十亿张图片,本文的目标是在这些图像中找到一个特定的对象。假设图像大小为1MB,那么总数据量就是1TB。整个图像的数据集存储在64个文件名为img1.data…img64.data的文件中,每个文件包含一个或多个图像。本文可以建立一个用于访问图像数据集的每个文件的索引文件。该索引文件表示数据文件中的每个记录的偏移量和大小。为了使用Sphere,用户可以编写一个函数—“findSpe⁃cialObject”从每一个图像中寻找指定的对象。在这个函数中,本文将把图像作为输入,输出将是本文指定的对象。
findSpecialObject(input,output);
标准串行程序如下:

4.1.2 计算范例
Sphere允许开发者使用几个简单的接口来编写特定的分布式数据并行应用程序。使用Sphere的计算范例基于以下概念。一个Sphere数据库包含一个或多个物理文件。Sphere上的计算由用户定义函数完成。用户定义的功能可以独立地应用于数据集中的每个元素,而其结果可以被写入到本地磁盘或其他节点上的共同目标文件。
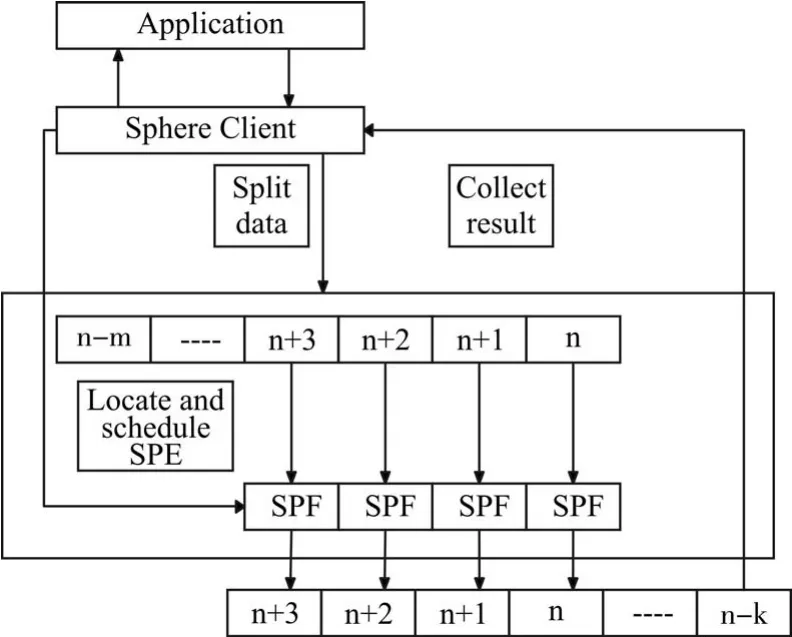
图2 Sphere的设计
4.2 Sector的设计
Sector是一个为云提供存储服务的存储云。Sector有如下假设:
1)第一个假设是,Sector可以访问大量的商业计算机。
2)第二个假设是,系统中的各个节点通过高速网络链接。
3)第三个假设是,Sector存储的数据集被分为一个或多个文件。
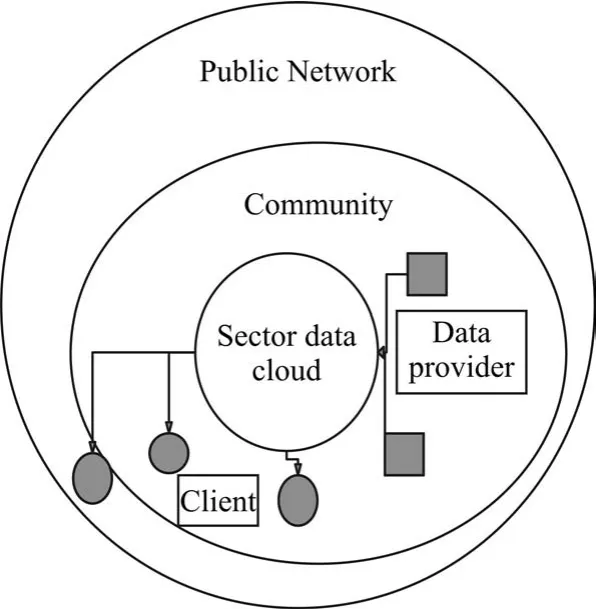
图3 Sector的设计
5 云的性能评价
这一节中,考虑使用云计算的企业的主要关注点之一就是性能,所以本文提出一种云计算服务的性能评价的科学计算方法。在云中实现应用程序高速配送是一个多方面的挑战,需要一个全面的方法和应用程序请求响应路径端到端的综合考虑。性能问题包括应用程序与数据的最终用户之间地理上的接近度,在云中和进出云的网络性能以及计算层和多层次的数据存储之间的访问速度[9]。
一些云供应商将它们的服务集中在一个特定的软件栈上,这通常可以将云供应商从基础设施即服务(IaaS)领域转换到平台作为服务(PaaS)的领域。正如人们所预料的那样,在不同的栈特定的云都与最流行的软件相结合。这样节省了大量的时间和费用,并且无需处理较低水平的基础设施的设置和配置。另一方面,它们往往需要开发人员遵循一定的架构和某种实际经验去编写应用程序,这导致了更高程度上的厂商依赖性。
5.1 方法
本文设计的性能评价方法包含云的评估以及与其他基础设施如比如网格和PPI的科学计算比较。为此,本文将评价过程分为两个部分,第一云计算,第二基础设施无关性。
5.1.1 云计算评价
云的一个吸引力是总有没有使用的资源,使它们可以在任何时间获得,而不需要额外的等待时间。然而,其他大型系统的负载根据提交模式随时间而变化,本文想知道大型云是否可以绕过这个问题[10]。
5.1.2 基础设施无关性评价
目前还没有一个唯一的公认的科学计算基准。特别是,没有这样的基准可以在一个通用的科学计算方案里,其中一个基础设施由几个独立的工作共享,尽管这样的场景会产生大量的性能损失。为了解决这个问题,本文的方法都是采用传统的包含了成套的工作的基准,然后在真正的科学计算环境中孤立的重复的运行。
5.2 实验设置
本文现在描述一下本文的实验设置,在实验设置里本文使用了之前描述的性能评价方法。
5.2.1 性能分析工具
本文为GrenchMark大规模分布式测试框架扩展了一些新的功能使得它可以用来测试云计算基础设施。该框架已经能够生成和提交真实的和合成的工作负载给网格,集群和其他大型分布式环境。通过这项工作,本文使GrenchMark能够测量云的具体指标如资源获取时间和实验耗费。
5.2.2 云资源管理
本文还为框架增加了基本的云资源管理功能,因为目前的框架并没有资源管理组件也没有可以访问和管理云资源的中间件[11]。
5.2.3 性能指标
本文使用在这项工作中使用的基准所定义的性能指标。本文还定义和使用基于实例类型T的一个虚拟集群的HPL效率作为集群的HPL基准性能与一个只有一个实例在真实环境中形成的集群的性能的百分比。
5.2.4 实验环境
因为目前所有五个EC2实例类型上所有的单任务基准都已经有足够的性能值报告,所以本文所有的测试都在亚马逊的EC2环境中进行。
5.2.5 优化和调整
基准采用命令行参数编译。本文没有使用任何附加架构或实例依赖优化措施。对于HPL基准,性能评价的结果取决于两个重要因素:基本线性代数的子项目与问题的规模。
5.3 实验结果
5.3.1 资源的获取与释放
本文研究了三种资源获取与释放的情况:短时间的单个虚拟机,短时间的多个虚拟机,长时间的单个虚拟机。
1)单个虚拟机:本文首先对5个虚拟机中的每一个进行资源获取,一旦资源状态变为已安装马上进行释放,重复20次。获取EC2中与资源获取和释放的有关开销。总资源获取时间是安装和启动时间的和。
2)多个虚拟机:接下来本文对同时请求获取多个资源的性能进行研究。这个对应于现实生活中一个用户想要从亚马逊EC2资源上创建一个同构集群的情况。
3)持续长期研究:本文研究了CloudStatus团队在网上发布的安装时间测量方法。本文已经利用网络爬虫和分析工具在2010年11月和2011年1月(三个月)中每2分钟进行取样。
5.3.2 单任务单机工作负载性能
在这组实验中,本文使用单虚拟机基准测试了CPU,I/O,存储器层次结构的原始性能。
1)计算性能:本文使用整套LMBench评估每种虚拟机类型的计算性能。包括整型,64位整型,浮点型和双精度浮点型运算的性能。
2)I/O性能:本文用Bonnie基准评估每种虚拟机类型的I/O性能,分为两步。第一步通过在十三个文件尺寸在1024KB和40GB之间的顺序输出基准的重写结果上运行Bonnie,确定使基于内存的I/O缓存无效的最小文件尺寸,这包括了在写入前已经受损的数据块的读取—寻找—写入操作序列。第二步本文分析了当文件尺寸超过5GB时的I/O性能。最后总结结果,本文发现亚马逊EC2测试的I/O性能与随机进行I/O操作的实现性能相当。
3)存储器层次结构性能:本文使用Cache⁃Bench在每种虚拟机型号上测试了存储器层次结构的性能。
4)性能稳定性:对每种虚拟机类型从单机基准获得的结果是一致的。
5)可靠性:本文在SJSI实验中遇到了几个系统问题。
5.3.3 单任务多机工作负载性能
在这组实验中,本文用单任务多机基准测试了亚马逊EC2组成的同构集群的性能。
HPL性能:对于HPL基准本文测试了多种虚拟集群的m1 HPCC性能。
HPCC性能:本文在单元集群组成一个虚拟机,16核集群组成至少两个虚拟机上用HPCC基准得到虚拟EC2集群的性能。
可靠性:本文在这些实验中遇到了几个可靠性问题:最重要的两个是关于HPL的,并且重复出现。
5.3.4 多任务工作负载性能
本文跟踪一个真实的系统运行复杂的工作负载来评估性能开销,而不是在虚拟亚马逊EC2集群上运行单任务。为此,本文在EC2上重现了本文的多集群DAS3网格系统轨迹,主要是包含了任务被提交给其中一个DAS3集群的轨迹部分。并行任务执行的结果稳定且开销较低。对于每一种虚拟机类型,本文发现重复工作负载重现需要的独立完成时间值与中等工作负载的完成时间的差值小于1%。
6 结语
近年来,商业集群已经相当普遍,在未来几年,将开始使用高性能的广域网连接这些集群并且正在走向一个有着大量的分布式数据集的时代,理论上将在磁盘上花费大量的时间,因此本文需要一个高性能计算模式以减小移动数据的规模[12]。通过回顾Sector和Sphere,本文知道Sector和Sphere的设计初衷就是为了完成这些任务。在本文中,本文还讨论了Sector/Sphere框架和关联规则的融合。这使得本文在网络上可以获得广泛的云服务关联规则算法的应用程序。这篇文章的最初目的是为了评价HPC的虚拟化生存能力。经过本文的分析,答案似乎是肯定的。然而,本文也希望选择这样一个HPC环境最好的虚拟化技术。为了做到这一点,本文将特征比较和性能结果结合,并评价Fu⁃tureGrid测试平台的潜在影响。本文将扩展这项工作到其他云服务,特别是存储和网络相关的服务;它们如何在未来应对不同的云用户数量带来不同特点和要求的工作负载的组合压力?本文还将性能评价扩展到其他真实和合成的应用,希望为科学界创建一个性能数据库。本文首先对已经在使用的大型计算云进行了一个全面的性能评估。然后,本文使用科学计算的替代方法比较了云的性能和成本,如网格和并行生产基础设施。本文的主要发现是被测试的云的性能和可靠性低。因此,在大型科学计算下,被测试的云是不够的,但它仍然可以满足科学家对于资源急切而暂时的需要。基于这一发现,本文已经分析了如何提高目前的云的科学计算能力,并确定了两个研究方向,每一个都具有很大的潜力。
[1]K.C.Lan,A.Hussain,and D.Dutta,Effect of Malicious Traffic on The Network[C]//Proc.Passive and Active Mea⁃surement Wksp.(PAM),San Diego,CA,Apr.2003.
[2]裴庆琪,沈玉龙,马建峰.无线传感器网络安全技术综述[J].通信学报,2007,28(8):113-122.
PEI Qingqi,SHEN Yulong,MA Jianfeng.Survey of wire⁃less sensor network security techniques[J].Journal on Communications,2007,28(8):113-122.
[3]Y unhong Gu,Robert L.Grossman.-UDT:UDPbased da⁃ta transfer for high-speed wide area networks[J].Comput⁃er Networks,2007,51(7):1777-1799.
[4]K.Keahey,R.Figueiredo,J.Fortes,T.Freeman,and M.Tsugawa,Science clouds:Early experiences in cloud computing for scientific applications[J].Cloud Computing and Applications,2008:199-211.
[5]K.Keahey,I.Foster,T.Freeman,and X.Zhang,Virtual workspaces:achieving quality of service and quality of life in the Grid,2011:66-79.
[6]Wang,L.,Tao,J.,Kunze,M.,Castellanos,A.C.,Kramer,D.,and Karl,W.2008.Scientific cloud comput⁃ing:early definition and experience[C]//In Proceeding of the 10th IEEE International Conference on High Perfor⁃mance Computing and Communications.Scientific Pro⁃gramming,2005(13):265-275.
[7]Kawaguchi T,Kakuma T,Yatsuhashi H,Watanabe H,Saitsu H,Nakao K,et al.Data mining reveals complex in⁃teractions of risk factors and clinical feature profiling asso⁃ciated with the staging of non-hepatitis B virus/non-hepa⁃titis C virus-related hepatocellular carcinoma[J].Hepatol Res,2011,41:564-71.
[8]Freitas,A.A.A survey of evolutionary algorithms for data mining and knowledge discovery[J].Advances in Evolu⁃tionary Computation,2002:819-845.
[9]Han J,Kamber M.-Data Mining:Concepts and Tech⁃niques[M].San Francisco:CA Morgan Kaufmann Pub⁃lishers,an imprint of Elsevier,2006:259-261,628-640.
[10]Y.S.Kon and N.Rounteren,Rare association rule min⁃ing and knowledge discovery:technologies for frequent and critical event detection.H ERSHEY[J].PA:Infor⁃mation Science Reference,2010:787-803.
[11]W.Sun,M.Pan,and Y.Qiang,“Inproved association rule mining method based on t statistical[J].Application Research of Computers,2011,28(6):2073-2076.
[12]Kurosaki M,Hiramatsu N,Sakamoto M,Suzuki Y,Iwa⁃saki M,Tamori A,et al.Data mining model using sim⁃ple and readily available factors could identify patients at high risk for hepato-cellular carcinoma in chronic hepati⁃tis C[J].JHepatol,2012,56(3):602-608.
An A lgorithm Research Based on High-performance Cloud Date M ining
ANG Chaoqun1HU W ei2HU Ran1
(1.Department of Management and Engineering,Naval University of Engineering,Wuhan 430033)(2.No.91919 Troops of PLA,Huanggang 438000)
TP301.6
10.3969/j.issn.1672-9722.2017.09.008
2017年4月11日,
2017年5月21日
昂朝群,女,硕士,工程师。研究方向:数据库设计与开发、云计算。胡炜,男,硕士,助理工程师,研究方向:数据挖掘和云计算。胡冉,男,硕士,研究方向:信息管理。
