航运企业信息管理系统的大数据分析与挖掘
2017-10-13于美丽
◆于美丽
航运企业信息管理系统的大数据分析与挖掘
◆于美丽
(长航凤凰股份有限公司上海华泰海运分公司 上海 200082)
为了降低成本、提升船效,通过BRICH聚类算法,信息系统根据输入的船舶航次信息,包括航线、等泊停时等,以及规使费、燃油费、租金、固定成本等,搜集船舶相近航次信息,自动计算最优航线,使单船单航次效益最大化。该算法系统已应用于所属公司,对船舶运营的效益预测科学精确,对公司领导决策有着风向标意义。当前运价低迷,干散货运输企业面临巨大的生存压力,科学化的管理系统成为航运企业亟需的新型管理模式。大数据的积累和挖掘有助于产生最佳航运线路,对于企业控本增效、排船优化起着至关重要的作用。
信息管理系统;大数据分析;数据挖掘;BRICH算法;航行最佳路径
0 前言
信息管理系统的建设着眼于实现干散货运输企业的管理流程、提高船舶的运行率、降低企业管理成本、加大经营利润的功能,全方位、多层次地将航运业务与计算机软件相结合,使计算机管理的精准、高效融入到航运管理的每个细节之中,提供了航运企业运营的最优化平台。数据挖掘自动在企业现有数据库中寻找预测性信息,以往需要进行大量手工分析的问题如今可以迅速直接由数据本身得出结论。调度人员可以根据系统分析数据,适时调整船舶装卸货,安排船期,力求单船单航次效益最大化。
1 需求分析与设计
根据企业船舶周转过程中产生的所有数据,从装港、运输、卸港,牵扯到商务港使费、船管部燃油供给财务运单及销账,设计系统架构如图1。
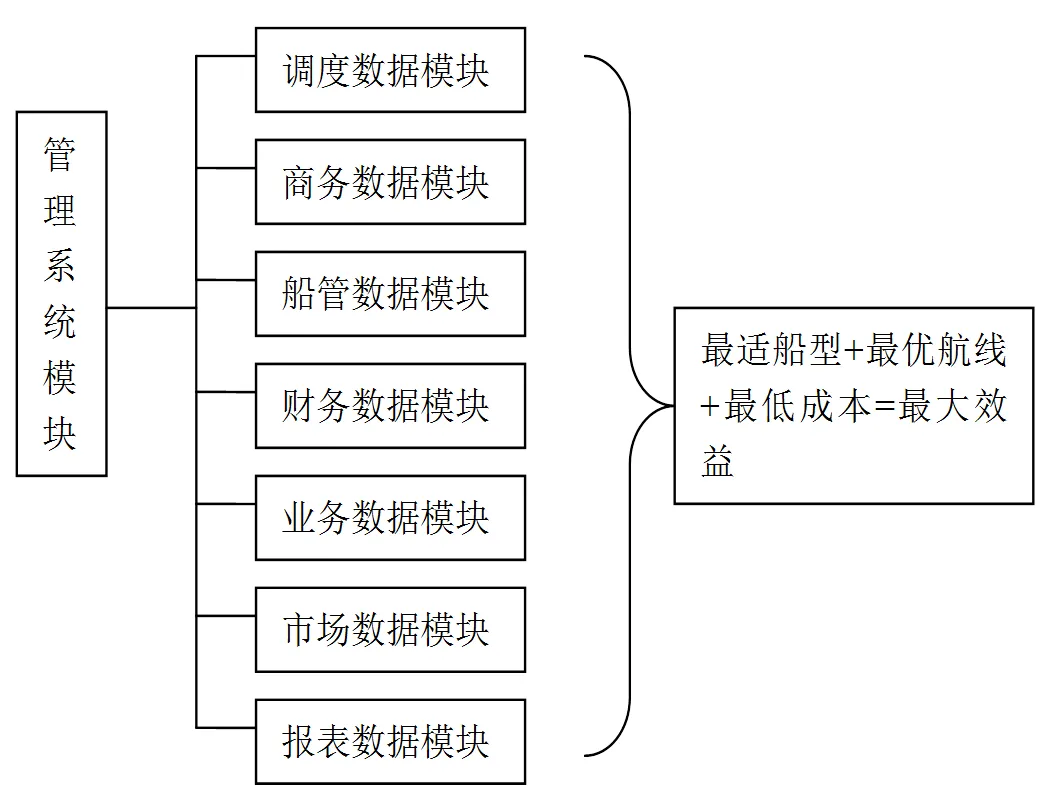
图1 设计系统架构
(1)调度数据模块中,涉及海轮、拖轮、港内过驳、长江驳船航次信息的设计及录入,如图2所示。
针对航次具体信息及后期应用,对不同船型的航次设计表项,包括装货、卸货、在港停时、中途停时、货种、货主、始发中途到港、港口里程。在此基础上生成船舶效率报表(按单船、按货主、按船型),船发量报表、流量流向报表、生产指标完成报表、货主码头卸载报表、周卸空报表、海轮专线营运时间统计报表等。
(2)财务数据模块中,涉及固定成本录入、运单运费录入、运单消耗、港使费预测录入,用于港使费实际与预测对比,公司资金到位率查询。

图2 海轮航次信息录入
(3)船管数据模块中,涉及船舶单航次耗油成本及千公里油耗。由于港使费和燃油费是我司主要成本支出,但是这两部分支出都是来自于港务局、港口及船舶上报,为了控制成本,精细核算,我司将根据港使费实际与预测进行比较,根据船舶耗油情况计算单船千公里油耗(见图3)。该举措需要将商务部做出的港使费月度预算及燃油部提供的船舶月度油耗分别与信息系统里实际发生的港使费付款通知单和船舶加油加水付款通知单进行比对,以提供超支或平衡的支出对比。这就对信息系统平台和Excel平台提出了一个读取、共享、交换数据的要求。最终建立了Excel和信息系统之间的数据通道,实现了方便快速的将商务处的港使费预测Excel表及将单船单航次实际耗油导入到系统中,与系统中的实际发生值进行比对,最终生成比较表。实现了Excel与信息系统不同平台之间数据的通信,大大方便了处理数据,精细管理。
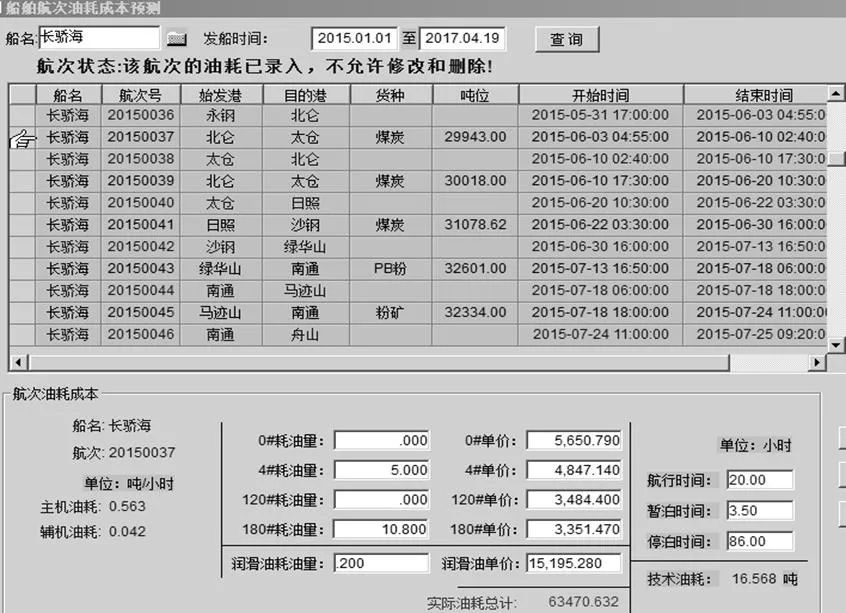
图3 船舶航次耗油成本预测
(4)商务数据模块中,超载奖申请功能、航次租船费用审核功能、由运量调整引起的超载奖补差价功能(见图4)。

图4 新增付款通知单
(5)市场数据模块中,周卸空报表、按货主统计船舶效率、产量报表。
(6)业务数据模块中,开票通知单和销账通知单的生成、查询、审核、统计功能。
以上功能最大的技术突破是适时增加了表的索引功能,并对不同表建立视图,增加表与表之间的连接,并加快了系统的运行。这样不同部门之间,自上而下形成一个流程,对应实际的经营模式,一个部门处理完业务后交由下一部门,不同部门对应不同权限,只有上一流程操作完之后,下游部门才可进行接下来的操作,使公司业务更严格,更规范。
2 最优模块的生成
在公司船舶卸空之后,不需要经过财务的各种单据和费用到场,直接通过系统,预测该航次的效益状况。涉及(1)固定成本,包括船员工资及附加、船舶保险费、事故损失费、维修费、光租租金、车船税、物料费、税金附加、管理费用分摊及其他费用共十个大项,以年度财务总成本为基础,根据实际航次时间,把财务成本拆解到本航次。(2)燃油成本,有船管部提供每个航次的油耗,包括油品种、耗油量。油单价,由库存油和新加油根据进水池原理计算耗油单价,由单价和耗量计算油成本。(3)港使费,包括港务费、船代费、系解缆费、拖轮费、饮水费、护航费、停泊费、通讯费、业务代理费和其他费用共十个大项。港务费是沿海是净吨的0.25元,进江是1.1元。船代费根据港口设定,如日照港是装载吨的0.2元,葫芦岛是0.9元。停泊费比较固定,均为净吨*0.06*停泊天数。(4)运费,根据业务处合同自动生成。(5)船舶航次信息,运营中心监控船舶动态,及时输入船舶开港、中途停时、卸港等行成完整航次信息。有了以上五大数据,就可以对每个航次的效益进行核算,为领导决策及时提供科学有效信息,适时调整船舶发运,保证效益最大化。
在以上成本、收入明朗的情况下,采用数据挖掘中的BIRCH算法,BIRCH也是一种聚类算法,其全称是Balanced Iterative Reducing and Clustering using Hierarchies。BIRCH是一个综合的层次聚类特征(Clustering Feature, CF)和聚类特征树(CF Tree)两个概念,用于概括聚类描述。聚类特征树概括了聚类的有用信息,并且占用空间较元数据集合小得多,可以存放在内存中,从而可以提高算法在大型数据集合上的聚类速度及可伸缩性。
BIRCH算法分为两个步骤:(1)扫描数据库,包括船舶动态,离港、航行、港使信息、燃油信息、合同信息,在此基础上建立动态的一棵存放在内存的CF Tree。如果内存不够,则增大阈值,在原树基础上构造一棵较小的树。(2)对树节点继续使用全局性的聚类算法,改进聚类质量。由于CF Tree的树节点代表的聚类可能不是自然的聚类结果,原因是给定的阈值限制了簇的大小,并且数据的输入顺序也会影响到聚类结果。因此需要对叶节点进一步利用一个全局性的聚类算法,改进聚类质量。CF是BIRCH增量聚类算法的核心,CF树中得节点都是由CF组成,一个CF是一个三元组,这个三元组就代表了簇的所有信息。给定N个d维的数据点{x1,x2,....,xn},CF定义为:CF=(N,LS,SS)。其中,N是子类中节点的数目,LS是N个节点的线性和,SS是N个节点的平方和。
CF有个特性,即可以求和,具体说明如下:CF1=(n1,LS1,SS1),CF2=(n2,LS2,SS2),则CF1+CF2=(n1+n2, LS1+LS2, SS1+SS2)。例如: 假设簇C1中有三个数据点(2,3)(4,5),(5,6),则CF1={3,(2+4+5,3+5+6),(2^2+4^2+5^2, 3^2+ 5^2+6^2)}={3,(11,14),(45,70)},同样的,簇C2的CF2={4,(40,42),(100,101)},那么,由簇C1和簇C2合并而来的簇C3的聚类特征CF3计算如下:
CF3={3+4,(11+40,14+42),(45+100,70+101)}={7,(51,56),(145,171)}
另外还有簇的质心和簇的半径。假如一个簇中包含n个数据点:{Xi},i=1,2,3...n.,则质心C和半径R计算公式如下:C=(X1+X2+...+Xn)/n,(这里X1+X2+...+Xn是向量加),R=(|X1-C|^2+|X2-C|^2+...+|Xn-C|^2)/n。其中,簇半径表示簇中所有点到簇质心的平均距离。CF中存储的是簇中所有数据点的特性的统计和,所以当我们把一个数据点加入某个簇的时候,那么这个数据点的详细特征,例如属性值,就丢失了,由于这个特征,BIRCH聚类可以在很大程度上对数据集进行压缩。
最大效益的设计,应该聚集航次所有信息,收入刨去成本、租金得到的最优路径(见图5)。

图5 单船单航次里利润预测表
3 结束语
综上所述,最优效益的产生依赖于航次诸信息的聚集算法,在运力充沛、货源紧张、运价低迷的行情下,信息系统根据输入的船舶航次信息,包括航线、等泊停时等,以及规使费、燃油费、租金、固定成本等,搜集船舶相近信息,自动计算最优航线,使公司效益最大化,对指导公司管船排船具有指导意义。该算法系统已应用于所属公司,对船舶运营的效益预测科学精确,对公司领导决策有着风向标意义。
[1]BIRCH:An Efficient Data Clustering Method for Very Large Databases.
[2]蒋国仁,郑士君.中远集运船舶管理信息系统设计.水运管理,2003.
[3]郑士君,韩成敏等.船舶管理信息化研究.上海海事大学学报,2002.
[4]黄爱平,郑士君.船舶通导设备计算机信息系统.航海技术,2003.
