科技资源元数据的关联与推荐方法
2017-10-13高少华诸云强
宋 佳 高少华 杨 杰 诸云强,5
(1.中国科学院地理科学与资源研究所资源与环境信息系统国家重点实验室,北京 100101;2.武汉大学资源与环境科学学院,湖北武汉 430079;3.中国科学院大学,北京 100049;4.江苏省地理信息资源开发与利用协同创新中心,江苏南京 210023;5.白洋淀流域生态保护与京津冀可持续发展协同创新中心,河北保定 071002)
科技资源元数据的关联与推荐方法
宋 佳1,4高少华2杨 杰1,3诸云强1,4,5
(1.中国科学院地理科学与资源研究所资源与环境信息系统国家重点实验室,北京 100101;2.武汉大学资源与环境科学学院,湖北武汉 430079;3.中国科学院大学,北京 100049;4.江苏省地理信息资源开发与利用协同创新中心,江苏南京 210023;5.白洋淀流域生态保护与京津冀可持续发展协同创新中心,河北保定 071002)
大数据背景下,科技资源发现和推荐的关键是建立海量、多类型科技资源间的关联,并对其进行相关度排序。在深入研究科技基础性工作专项科技资源核心元数据的基础上,选择科技资源的内容特征、资源地点和资源时间为关联要素。然后结合专家打分和层次分析法,提出了科技资源元数据语义相关度算法,建立了科技资源间的关联。进一步按照相关度计算结果对科技资源进行排序,并将相关度高的科技资源优先推荐给用户。最后以科技基础性工作专项项目汇交的科技资源元数据为例,开展了科技资源元数据关联与推荐的实践。本研究提出的方法为促进海量科技资源的精准发现、智能推荐与共享应用提供了借鉴。
科技资源;元数据;语义关联;语义相关度
1 引言
科技资源包括科学数据、图集、志书/典籍、标本资源、标准规范、论文专著或研究报告等。在大数据背景下,各类科技资源实体的数量以前所未有的速度增长,如何有效地将这些实体进行关联并在检索过程中为用户推荐最相关的科技资源,已经成为一个迫切需要解决的科学问题。
元数据的提出为科技资源之间的关联提供了必要条件。所谓元数据,就是关于数据的数据。王国复等[1]认为,元数据是对数据资源的规范化描述,它是按照一定标准(即元数据标准),从数据资源中抽象出相应的特征属性,组成的一个特征元素几何(即元数据元素)。元数据不仅方便用户使用数据资源,而且随着网络技术的发展和数字化资源的猛增,元数据在数据共享、资源的发现以及知识管理方面的作用越来越明显,越来越为人们所重视[2]。虽然目前众多项目、系统和平台在建设过程中纷纷涉及并颁布共享相关元数据标准[3]。但是,由于科技资源类型较多,其中涉及的学科领域也很多。所以,在数据描述等方面普遍存在语义异构现象,以及关键词在表达搜索意图时的局限性,使得以关键词匹配为主的检索方法在效率和结果质量上不再满足用户需求[4]。
为了解决这个问题,面向语义的数据关联的研究应运而生,其主要是通过数据语义,建立数据间的关联。目前的研究方法大致有两类:一是通过建立相应的领域本体进行推理,实现数据间的关联。如王东旭[5]、侯志伟[6]、孙凯[7]分别研究了地学领域的本体,并构建了地学数据的空间本体、时间本体以及形态本体,并将其应用于对地理空间数据的语义检索和发现中,取得了较好的检索结果。但是,科技资源涉及多个学科及多个领域,采用基于本体的语义推理方法需要构建面向多学科、多领域的完整的知识概念体系,这将导致面向科技资源的本体构建过程变得极为复杂而难以完全实现。二是通过定量地描述元数据之间的相关度来建立数据之间的关联。该方法具有构建过程简单且适用于多学科、多领域、多来源科技资源的特点。现在已有很多学者在此方面展开研究。例如,在对地理空间数据的研究上,诸云强[8,11]通过考虑数据主题、分类、空间拓扑、时间拓扑、空间精度、时间粒度、数据类型、数据格式等8个基本特征提出了地理空间元数据的多尺度和定量的关联方法,并通过计算相似度实现数据的推荐。赵红伟[9-10]根据地理空间数据在空间、时间、内容上的语义关系,提出了地理空间数据本质特征语义相关度计算模型,并利用RDF设计了地理空间元数据关联模型。通过计算元数据之间的语义相关度构建了地理空间元数据关联网络,从而有效地支持了地理空间语义关联检索与推荐等,提高了检索的查准率。针对极地科学数据,罗侃[12]建立了极地科学元数据关联指标体系,实现极地科学数据的关联查询应用。由以上研究可以看出,通过建立元数据之间的语义关联,可以丰富检索结果,使用户更容易得到所需要的数据,并且基于元数据语义关联的方法还可以实现数据的推荐,即在基于元数据语义相关度计算的基础上,将相关度高的数据排在前面,优先推荐给用户。
目前,针对计算元数据间的语义相关度,进行关联与推荐的研究,主要以空间数据为代表。对于科技资源来说,空间数据只是其中的一部分资源,而对于其他类型科技资源的关联与推荐鲜有研究。本文以科技基础性工作专项项目产生的科学数据、图集、志书/典籍、标本资源、标准物质、论文专著和研究报告等科技资源为研究对象,通过元数据语义相关度的计算探讨科技资源的关联与推荐。
2 科技基础性工作专项科技资源核心元数据规范
作为科技创新活动的要素,科技资源是一切科技活动的核心。科技资源涵盖的学科领域众多,具有资源类型种类繁多、结构差异较大的特点。而元数据则是对各种科技资源的外部形式和内部形态的详细描述,为了能够对不同类型的信息资源进行描述和处理,不同领域的专业人员研究并定制了用于各个领域和各种场合的元数据标准[13]。其中,在国际上常用的元数据标准包括描述网络信息资源的都柏林核心元数据、描述国家数字地理空间数据的术语及其定义集合的地理空间元数据内容标准、地理信息元数据(ISO 19115)、地理信息服务(ISO 19119)等。除此之外,还有各学科领域的相关元数据标准,如生态科学数据元数据、气象数据核心元数据等。
现有元数据标准主要适应各学科领域的特定资源,而科技资源包含数据、志书/典籍、标本资源、标准物质等,难以直接采用现有的元数据标准。所以,在综合考虑各类科技资源共性特征的基础上,提出了科技基础性工作专项科技资源核心元数据规范,如表1所示,包括19个核心元数据项。其中,必选项有16项,可选项有3项。该规范已经应用在科技基础性工作专项项目的科技资源汇交工作中。
通过对表1所述科技基础性专项科技资源的核心元数据项进行选择,下文选择了表达科技资源核心特征的三要素,即资源内容(中文名称、关键词、资源类型、资源描述摘要、资源学科分类)、资源地点和资源时间,建立了科技资源之间的关联,并计算相应的语义相关度,为用户进行推荐。
3 科技资源元数据语义相关度计算
语义相关度的计算不仅包括传统字面匹配的相关度,还包括体现语义层次上概念间关系的计算。例如,用户需要与“北京市”有关的科技资源,而像“京津冀地区”的科技资源在字面匹配相关度上与“北京市”不相关,但在空间概念上相关。即两种资源的字面匹配相关度很小,但空间概念上的语义相关度很大。因此,在基于元数据的语义关联时,需要综合考虑词汇层面之间的相关度,以及词汇在空间关系、时间关系等其他语义关系上的相关度。
本文通过计算元数据在资源内容、资源地点和资源时间上的相关度,采用层次分析法,确定不同层次下各因素在本层次中的影响程度,即权重值,最终计算出不同科技资源对象之间的语义相关度。
3.1 内容相关度
资源内容包括中文名称、关键词、资源类型、资源描述摘要和资源学科分类。为了建立元数据的关联,前三者需要计算两两科技资源的字面匹配相关度,后者属于资源所属的学科,需要计算类与类之间的相关度。因此,资源内容相关度计算如式(1)所示。

在式(1)中,S1表示内容相关度;S11、S12、S13和S14分别表示中文名称、关键词、资源类型和资源描述摘要的内容字面匹配相关度;S15表示资源学科的类别相关度;W11、W12、W13、W14和W15表示各因素的权重值。
内容字面匹配相关度计算首先要对文本进行分词,可借助IkAnalyzer分词软件[14]实现分词,两两对比计算所包含的相同词语的个数所占比例,分别得到中文名称、关键词、资源类型和资源描述摘要在字面上的匹配相关度。
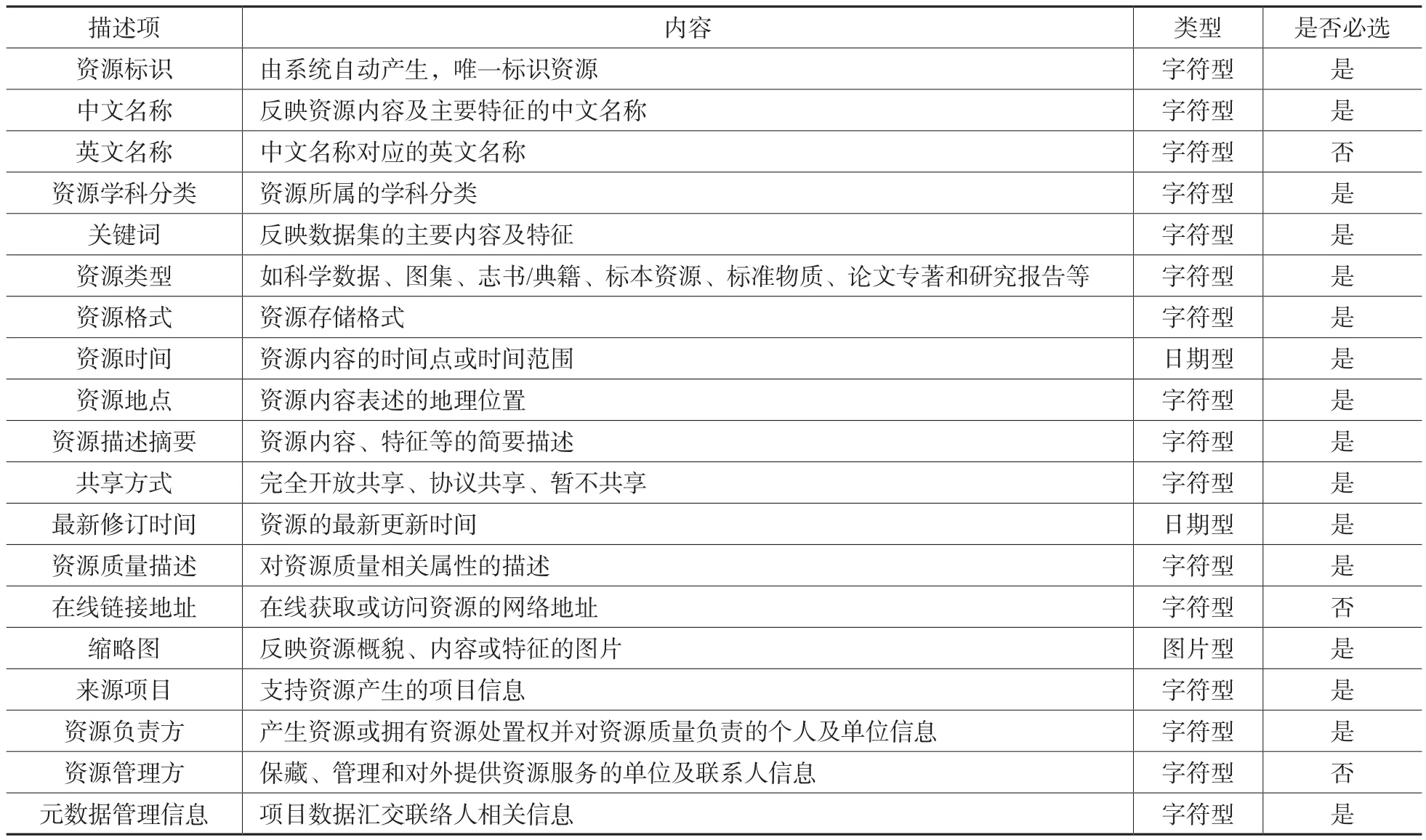
表1 科技基础性工作专项科技资源核心元数据规范
类别相关度计算采用文献[15]提供的方法。本文采用的学科分类参照国家标准《学科分类与代码GB/T 13745-2008》。具体做法是:假设需要计算相关度的两个类别在分类树上的节点分别为X和Y,找到距离X和Y最近的父节点P,可根据式(2)计算类别相关度。

在式(2)中, N(X)、 N(Y)分别表示X和Y到P的距离, N( P)表示P到根节点的距离。
若存在两个科技资源实体属于多个类别,分别计算每个类别的相关度,并取最大值作为这两个科技资源实体最终的类别相关度。
3.2 地点相关度
资源地点是资源内容所表述的地理位置。资源地点相关度的计算首先需要根据该地理位置,得到其地理坐标后,将其表达为一个空间几何对象;然后根据空间几何对象之间的空间关系,计算对象之间的空间语义相关度。
对于具体的空间几何对象,其类型包括点状对象、线状对象和面状对象。鉴于科技资源的复杂性,为了实现统一表达,均将其所描述的地理位置映射到同一尺度下的空间面状对象上。
空间关系包括空间拓扑关系、空间度量关系和空间方位关系。对于空间语义相关度的计算,空间方位关系对空间语义相关度计算的影响不大,空间度量关系与具体的拓扑关系相关,而空间拓扑关系较为复杂,因此,如何根据实体之间的拓扑关系计算资源地点相关度是解决问题的关键。对于面状实体之间的拓扑关系,本文将考虑空间拓扑关系即相等、相接、相交、包含、被包含和相离6种关系,如表2所示。假设用户需要的科技资源地理位置映射到的空间实体为X,关联的科技资源的地理位置映射到的空间实体为Y,则根据X和Y的空间拓扑关系在计算资源地点相关度S2时,可以分为以下几种情形。
(1)当X和Y的拓扑关系为相等或是Y被包含于X时,S2=1;
(2)当X和Y的拓扑关系为相接时,可根据相交边界的长度以及Y的边界长度进行计算,具体的可由式(3)求得:
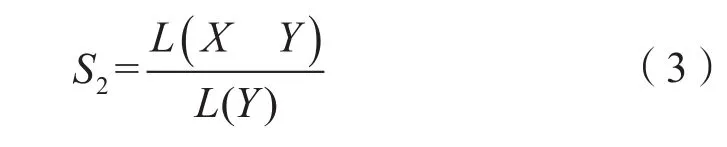
在式(3)中,L( Y)表示实体Y的边界长度,L( XY)表示实体X与实体Y两个实体相接的边界长度。
(3)当X和Y的拓扑关系为相交或是X包含于Y时,具体的可由式(4)得到:

在式(4)中, A( Y)表示实体Y的面积, A( XY)表示实体X与实体Y两个实体相交的面积。
(4)当X和Y的拓扑关系为相离时,可根据X和Y的空间距离进行计算,具体的可由式(5)得到:

在式(5)中, D( X , Y)表示实体X和实体Y之间的空间距离。
3.3 时间相关度
资源时间指的是资源内容的时间点或时间范围。对于采用时间点描述的资源时间,例如科技资源中标本的采集、制备时间,为统一时间描述,需要将其转化为时间段。对于所有的时间段,均统一为以天为最小时间单位,然后采用Allen[16]提出的时间区间代数理论,根据时间段之间的13种拓扑关系如表3[9]所示,计算资源时间相关度S3。
根据时间拓扑关系,假设用户需要的科技资源的时间段为X,推荐的科技资源的时间段为Y,计算资源时间相关度S3,可将其分为以下几种情况:
当时间拓扑关系为相交、包含等的时间段时,可依据X和Y重叠的时间长度,由式(6)得到:
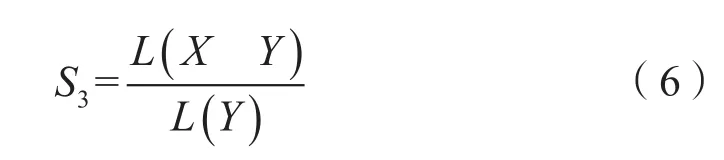
在式(6)中, L( Y)表示时间段Y的时间长度,L( X Y)表示时间段X与时间段Y重叠部分的时间长度。
当时间拓扑关系为相接、相离的时间段时,可依据X和Y的时间距离,由式(7)得到;

在式(7)中,D( X, Y)表示时间段X和时间段Y之间的时间距离。
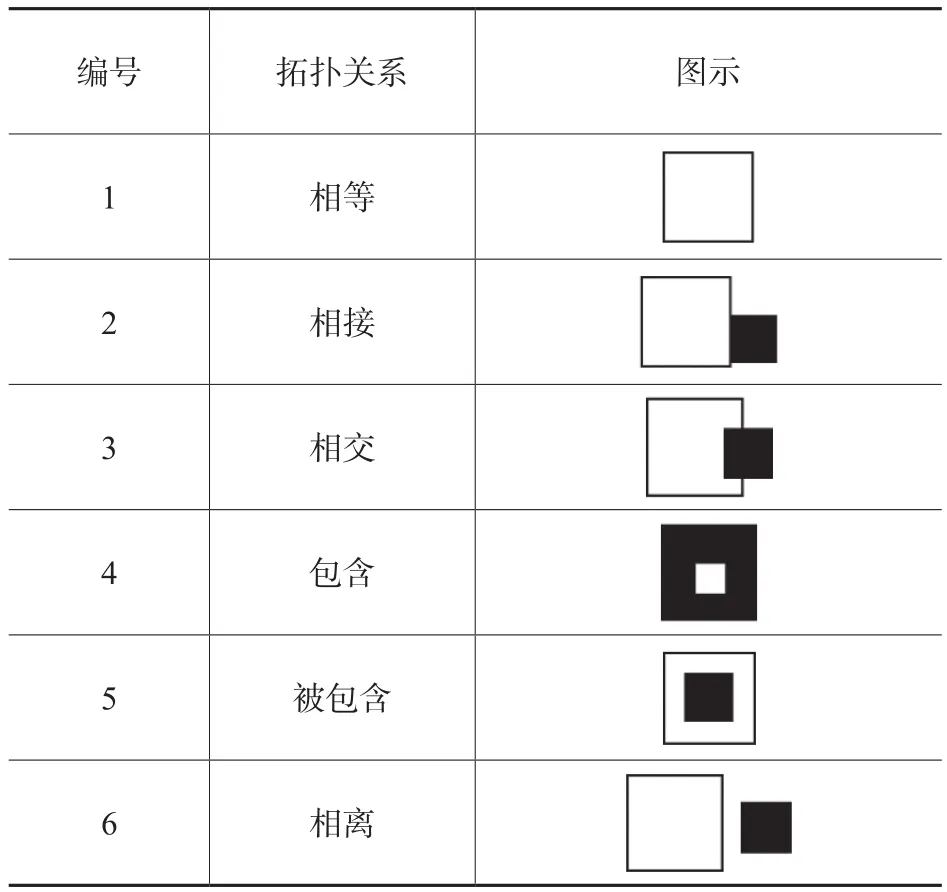
表2 面状实体—面状实体拓扑关系

表3 时间段—时间段拓扑关系
3.4 语义相关度
根据对资源内容相关度、资源地点相关度和资源时间相关度的计算,元数据语义相关度S可由式(8)得到:

在式(8)中,S表示元数据语义相关度;S1、S2、S3分别表示上文计算得到的资源内容相关度、资源地点相关度和资源时间相关度;W1,W2,W3表示各相关度的权重值。
元数据语义相关度的计算还需确定各因素的权重值大小。权重的确定可以由层次分析法获得。层次分析法(AHP)是由美国运筹学家Saaty[17]提出来的,其原理简单,且数学推理严格,具有很广泛的应用。根据层次分析法,首先对各种因素按照其影响程度分级分类,本文将影响元数据语义相关度的因素分为两级,分别为一级因素(资源内容、资源地点和资源时间)和二级因素(中文名称、关键词、资源类型、资源描述摘要和资源学科分类);然后按照层次构造判断矩阵;最后通过相关计算得到每个因素的权重值。具体方法如图1所示。
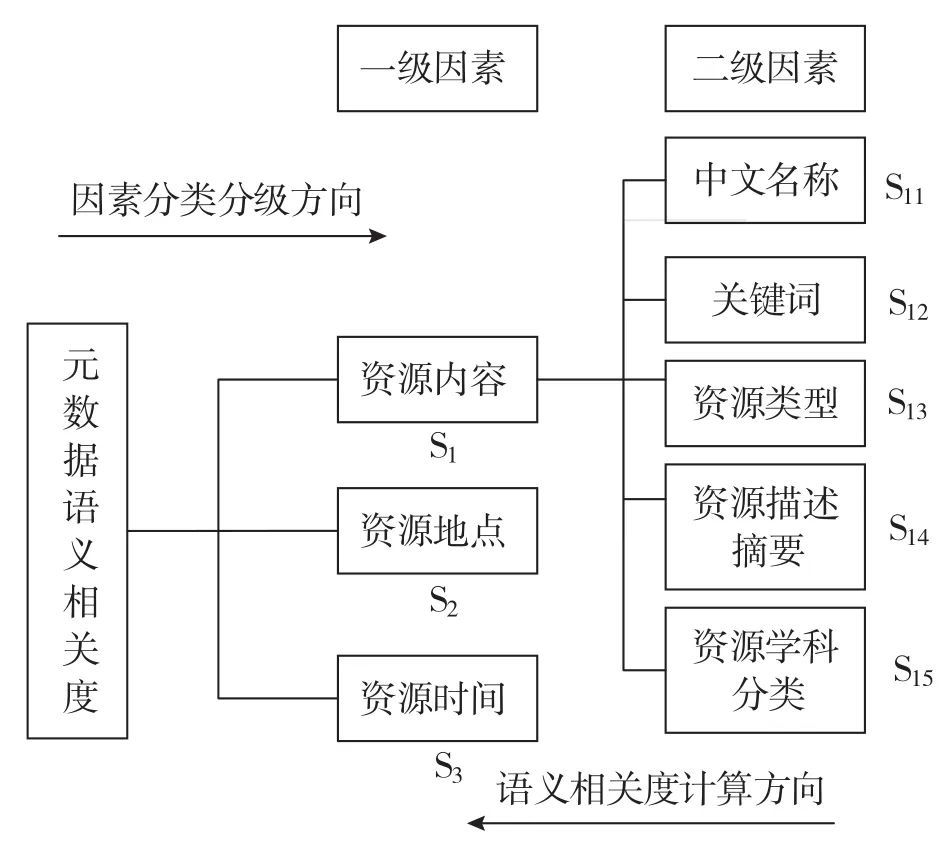
图1 元数据语义相关度计算
(1)构造判断矩阵
判断矩阵表示在同一层次下不同因素对上一级某因素的重要程度,将因素之间的相对重要性用数值表示,构成矩阵形式。因此,对于构造的判断矩阵A=(aij)n╳n,其中aij为因素i与因素j重要性比较结果,aij的取值一般为1,2,…,9以及它们的倒数。1表示因素i与因素j同等重要,3表示因素i比因素j稍微重要,5表示因素i比因素j明显重要,7表示因素i比因素j强烈重要,9表示因素i比因素j极端重要,而2、4、6、8分别有3、5、7、9相应的类似含义,只是程度稍小,可由专家打分得到。
(2)一致性检验
在利用判断矩阵计算各因素的权重前,首先要对判断矩阵进行一致性检验。判断矩阵是否满足一致性检验,关系到后续由判断矩阵得到的权向量是否能真实反映各因素之间的客观权重。一致性检验主要由“一致性比例(CR)”来确定,其计算方法如式(9):

其中,CI为一致性指标,RI为平均随机一致性指标。当CR<0.10时,则认为判断矩阵一致性是可以接受的,否则需要对判断矩阵进行适当的改正。一致性指标CI的计算方法如式(10):

在式(10)中,λmax为判断矩阵的最大特征值;n为判断矩阵的阶数。
平均随机一致性指标RI是通过多次重复进行随机判断矩阵特征值的计算后取算术平均值得到的,其值可根据判断矩阵的阶数,经查表得到。
(3)计算权重值
计算同一层次下各种因素对上一层次中相关联因素的影响程度,即权重值,归结为计算判断矩阵的特征向量的问题。具体的计算方法有和积法、特征向量法和最小二乘法等,为了计算简便,本文将采用近似计算和积法。
根据图1,对影响元数据语义相关度计算的各级因素,通过组织相关专家进行打分,得到各级因素的判断矩阵如表4、表5所示。经过计算,表4和表5两个判断矩阵均满足一致性检验。因此,利用这两个判断矩阵得到的权向量可以真实反映各因素之间的客观权重。
基于表4和表5判断矩阵的结果,利用近似计算和积法,得到各因素的权重值,如表6所示。
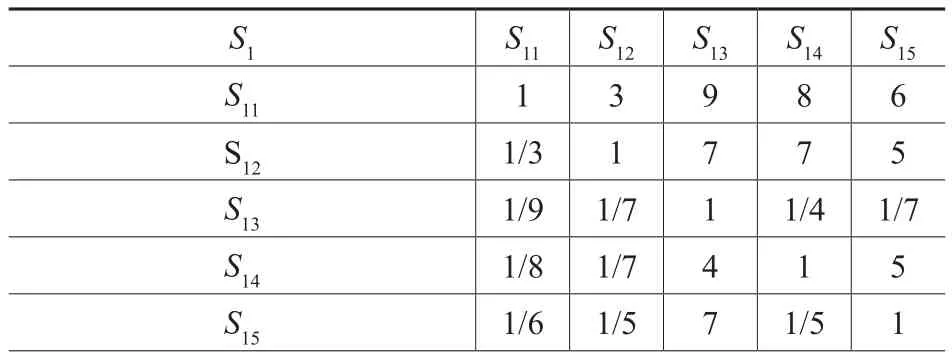
表4 资源内容判断矩阵

表5 元数据语义相关度判断矩阵

表6 各因素权重值
4 实例分析:“森林土壤剖面调查数据”元数据的关联与推荐实验
本文以资源中文名称为“2009—2010年中国森林土壤剖面调查数据”的元数据为被关联对象,利用提出的科技资源元数据关联方法计算其他资源对象与被关联对象之间的语义相关度。按第3节方法和表6权重进行计算,得到语义相关度排序后前15条的计算结果,如表7所示。
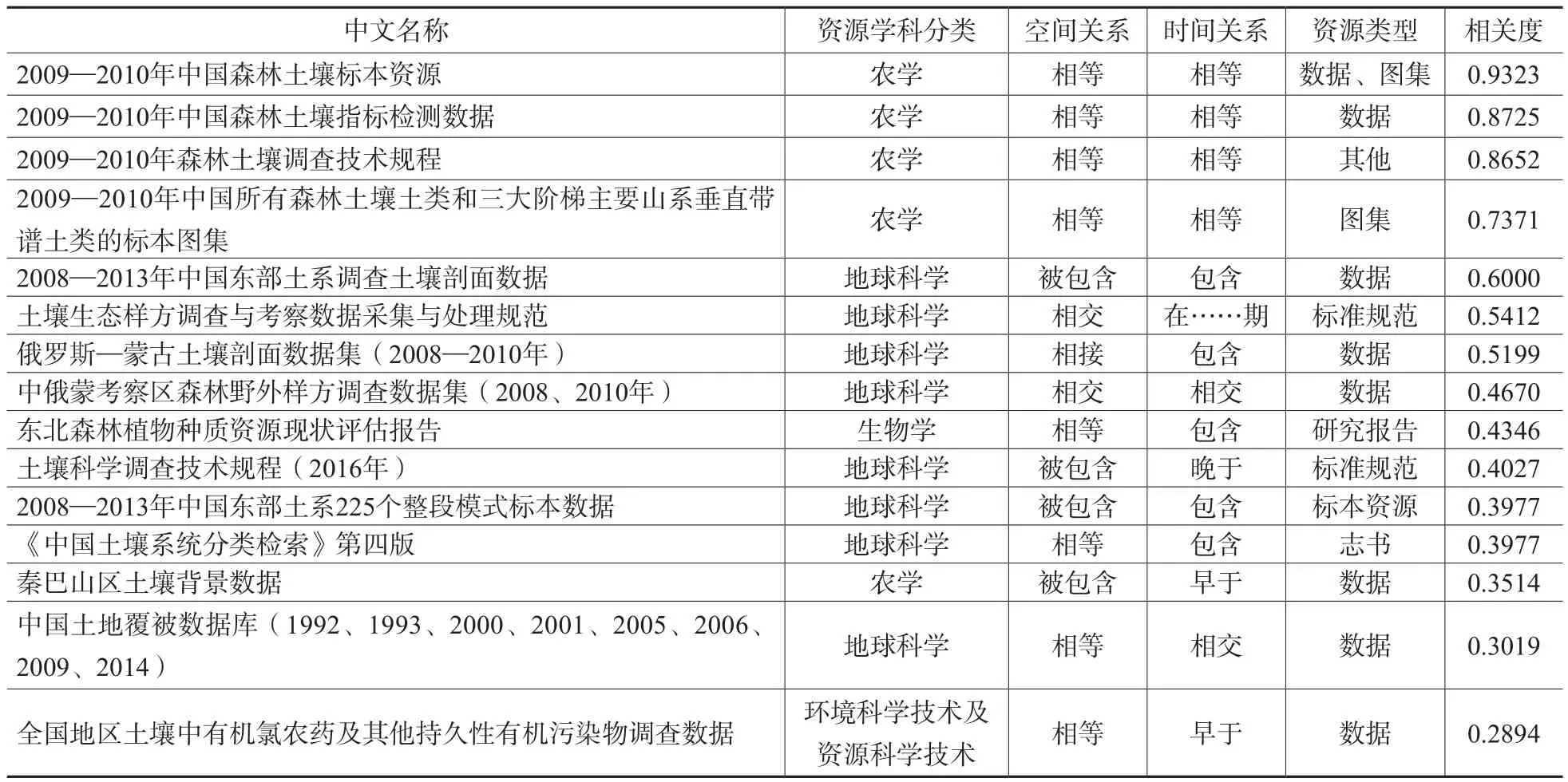
表7 “2009—2010年中国森林土壤剖面调查数据”相关的元数据及相关度计算结果
表7列出的资源在相关性上随着相关度的减小而减弱,并且用本文方法计算得到的相关度与资源的实际相关程度有较好的吻合。被关联资源“2009—2010年中国森林土壤剖面调查数据”所属学科为农学,资源类型为数据,资源时间为2009年1月1日至2010年12月31日,资源地点为中国。由表7可以看出,前2条资源在资源学科分类、资源时间、资源地点、资源类型的特征上与被关联资源完全相同,因此综合后的语义相关度最高。而第3条和第4条资源在资源学科分类、资源时间、资源地点的特征上与被关联资源完全相同,而在资源类型上与被关联资源不同,因此综合后的语义相关度较前2条略低。从表7中还可以看出,因为考虑了资源的学科特征,除了被关联资源所属的农学外,地球科学、生物学等其他相关学科的资源也可以被关联起来。同理,因为考虑了资源的类型特征,除数据类型以外的其他资源类型,如志书、图集等也可以被关联起来。这些不同学科、不同类型的科技资源不仅丰富了关联与推荐的结果,而且可以作为原有科技资源的一种补充,使用户从多个方面充分获得所需科技资源的相关信息。
5 结论与展望
本文以多学科、多领域、多渠道、多类型的海量科技资源为研究对象,在综合考虑科技资源共性特征的基础上,提出科技基础性工作专项科技资源核心元数据规范,并选择了最能表达科技资源核心特征的几个要素,即科技资源内容(中文名称、关键词、资源类型、资源描述摘要、资源学科分类)、资源地点和资源时间作为关联项,提出面向科技资源的语义相关度算法。最后对语义相关度计算结果进行排序,优先将相关度高的科技资源推荐给用户。
(1)通过提出科技基础性工作专项科技资源核心元数据规范来降低关联和推荐的复杂性,以元数据作为科技资源关联的中介对象,经对元数据相关项之间语义相关度的计算,提取并定量地表达了其中隐含的语义信息,间接地建立了科技资源之间的语义关联方法。
(2)根据语义相关度对关联资源进行排序,定量地反映了资源之间的关联程度,为科技资源的精准发现、资源推荐和共享应用提供了方法支撑。实验结果表明,通过计算元数据之间的语义相关度对科技资源进行关联与推荐的方法,具有操作简单、构建方便的特点;通过计算语义相关度,可避免传统检索方法的局限性,推荐结果在一定程度上可以满足用户的不同需要;通过元数据建立科技资源之间的关联,具有较好的可扩展性。
(3)本文在层次分析法中确定的权重带有一定程度的主观性,后续研究可考虑引入机器学习的方法,通过训练样本确定权重大小,并在计算语义相关度时适当加入其他项进行计算。
[1]王国复, 涂勇, 王卷乐, 等.科学数据共享中的元数据技术研究[J].中国科技资源导刊, 2008, 40(1): 30-36.DOI: 10.3772/j. issn. 1674-1544. 2008. 01. 006.
[2]徐枫.元数据技术及其在科学数据共享中的应用.科学数据共享管理研究[J].北京: 中国科学技术出版社,2002: 178-196.
[3]黄如花, 邱春艳.国内外科学数据元数据研究进展[J].图书与情报, 2014(6): 102-109.
[4]侯志伟.地学数据时间本体及其在语义检索中的应用:以地质年代本体为例[D].北京: 中国科学院大学, 2016.
[5]王东旭, 诸云强, 潘鹏, 等.地理数据空间本体构建及其在数据检索中的应用[J].地球信息科学学报, 2016,18(4): 443-452.DOI: 10.3724/SP. J. 1047. 2016. 00443.
[6]侯志伟, 诸云强, 高星, 等.时间本体及其在地学数据检索中的应用[J].地球信息科学学报, 2015, 17(4):379-390.DOI: 10.3724/SP. J. 1047. 2015. 00379.
[7]孙凯, 诸云强, 潘鹏, 等.形态本体及其在地理空间数据发现中的应用研究[J].地球信息科学学报, 2016,18(8): 1011-1021.DOI: 10.3724/SP. J. 1047. 2016.01011.
[8]ZHU Y, ZHU A, SONG J, et al. Multidimensional and quantitative interlinking approach for Linked Geospatial Data [J]. International Journal of Digital Earth, 2017,10(9): 1-21.DOI: 10.1080/17538947. 2016. 1266041.
[9]赵红伟, 诸云强, 杨宏伟, 等. 地理空间数据本质特征语义相关度计算模型[J].地理研究, 2016, 35(1): 58-70.DOI: 10.11821/dlyj2016.01.006.
[10]赵红伟, 诸云强, 侯志伟, 等.地理空间元数据关联网络的构建[J].地理科学, 2016, 36(8): 1180-1189.DOI:10.13249/j. cnki. sgs. 2016. 08. 008.
[11]ZHU Y, ZHU A, FENG M, et al. A similaritybased automatic data recommendation approach forgeographicmodels[J].International Journal of Geographical Information Science, 2017, 31(7): 1403-1424. DOI:10.1080/13658816. 2017. 1300805.
[12]罗侃, 诸云强, 程文芳, 等.极地科学数据关联方法及应用研究[J].极地研究, 2016, 28(3): 361-369.DOI:10.13679/j. jdyj. 2016. 3. 361.
[13]许鑫, 张悦.非遗数字资源的元数据规范与应用研究[J].图书情报工作, 2014, 58(21): 13-20.DOI: 10.13266/j. issn. 0252 – 3116.2014.21.002.
[14]IK-Analyzer.v[EB/OL].[2017-08-23].http: //code.google.com/p/ik-analyzer/.
[15]WU Z, PALMER M. Verb semantics and lexical selection[C]//32nd annual meeting of the association for computational linguistics. Las Cruces, New Mexico,Stroudsburg: Association for Computational Linguistics,1994: 133-138.
[16]ALLEN J F. Maintaining knowledge about temporal intervals[J].Communications of the ACM, 1983, 26(11):832-843. DOI: 10.1145/182.358434.
[17]SAATY T L. How to make a decision: the analytic hierarchy process[J]. European Journal of Operational Research, 1990, 48(1): 9–26.
Association and Recommendation Method for Metadata of Scientific and Technical Resources
SONG Jia1,4, GAO Shaohua2, YANG Jie1,3, ZHU Yunqiang1,4,5
(1.State Key Laboratory of Resources and Environmental Information System, Institute of Geographic Sciences and Natural Resources Research, CAS, Beijing 100101;2.School of Resource and Environment Science, Wuhan University, Wuhan, Hubei 430079;3.University of Chinese Academy of Sciences, Beijing 100049;4.Jiangsu Center for Collaborative Innovation in Geographical Information Resource Development and Application, Nanjing, Jiangsu 210023;5.Collaborative Innovation Centre for Baiyangdian Basin Ecological Protection and Jingjinji Regional Sustainable Development, Hebei University, Baoding, Hebei, 071002)
In the context of big data, e ffi cient discovery and recommendation for scientific and technical data resources is to build the association between these data resources and then sort them by relevancy. Based on the investigation of core metadata of National Special Program on Basic Works for Science and Technology of China, this study chooses the content, location and temporal information of the data resources as associationfactors. Then, a semantic relevance algorithm is proposed based on the method of expert scoring and analytic hierarchy process, and the semantic association between these data resources is achieved in this study. These data resources are able to be sorted in terms of the semantic relevance, and the data resources with high relevance value can be recommended to the users. The proposed method is validated in the application case of data archiving and sharing for the projects of National Special Program on Basic Works for Science and Technology of China, and it has great significance in promoting the accurate discovery, intelligent recommendation and sharing for scientific data.
scientific and technical resources, metadata, semantic association, semantic relevance
G203
A
10.3772/j.issn.1674-1544.2017.05.005
宋佳(1980—),男,博士,中国科学院地理科学与资源研究所助理研究员,研究方向:地球信息科学(通讯作者);高少华(1993—),女,武汉大学资源与环境科学学院硕士研究生,研究方向:地图学与地理信息系统;杨杰(1990—),男,中国科学院地理科学与资源研究所硕士研究生,研究方向:地学模型数据匹配方法;诸云强(1977—),男,博士,中国科学院地理科学与资源研究所研究员,主要研究方向:地学数据本体与共享、资源环境信息系统。
科技基础性工作专项项目“科技基础性工作数据资料集成与规范化整编”(2013FY110900);国家自然科学基金重点项目“网络文本蕴含信息理解与知识图构建”(41631177)。
2017年7月31日。
