基于BloomFiltering检测的安全重复数据删除技术分析
2017-10-10张瑞,温蜜
张 瑞, 温 蜜
(上海电力学院 计算机科学与技术学院, 上海 200090)
基于BloomFiltering检测的安全重复数据删除技术分析
张 瑞, 温 蜜
(上海电力学院 计算机科学与技术学院, 上海 200090)
数据的不断增长推动了云计算、云存储的发展,大量数据被存储到云端,数据的不断积累占据了太多存储空间.为了节省空间,重复数据删除技术被提出并广泛使用.在原始信息锁加密的基础上进行改进,引入布隆过滤器来实现重复检测,继而完成安全存储.对方案性能进行分析后发现,可以实现基本的安全机密性,并降低了计算开销.
云存储; 重复数据删除; 信息锁加密; 布隆过滤器; 安全存储
随着大数据时代的发展,数据每时每刻都影响着处于信息时代的人们.人类社会产生了多样化的数据渠道,有互联网、日常生活等众多数据来源.据统计,这些数据已累积到前所未有的体量,IDC预计到2020年,全球将产生近40 ZB的数据[1].数据的不断增长同时会占据越来越多的存储空间.由此看来,为了节省存储空间及上传带宽,解决办法的提出就变得尤为重要.
数据不断产生,难免会存在许多重复的数据,并被重复存储,浪费大量的空间.因此,重复数据删除技术[3]就被提出并得到了广泛使用,例如DropBox,Mozy及百度云等的云服务器[2].重复数据删除技术的作用就是云服务器只存储数据的一个副本,删除数据集中重复的数据,只把相应链接发送给拥有相同数据的用户,从而消除冗余数据,达到节省存储空间的目的.
据统计调查,该技术去重效果显著,可以节省约90%的存储空间[4].但是由于数据都是被存储到云服务器端,用户就失去了对数据的直接控制权,有些重要数据如用户的隐私信息也就得不到保护,信息容易泄露或被篡改.因此,如何保证用户信息的安全机密性和完整可用性又是一个重要的挑战.为此,数据就必须要加密保存.然而,重复数据删除和加密技术的理念截然相反[5].重复数据删除的原理是利用数据相似性来检测相同数据,以降低存储空间中重复数据占有的比例;而加密的目的则在于使得生成的密文与理论上的随机数无差别.相同数据由不同的人加密,所得到的密文完全不同,难以实现重复数据的删除.
针对上述问题,DOUSCEUR J R等人[6]提出了采用收敛加密来实现安全高效的数据重复删除.在该方案中,以文件自身生成的摘要值作为密钥,使用对称加密算法进行加密,保证了相同的明文可以得到相同的密文,允许云存储提供商利用重复数据删除而只能获得加密的数据.在此基础上,各种改进方案相继被提出.BELLARE M等人[7]提出了信息锁加密方案,相比于原始收敛加密更安全高效;JIANG T等人[8]提出了完全随机的信息锁加密方案,在文献[7]的基础上做了改进,加入了树结构实现重复检测,但树结构进行检测时比较复杂.本文采用简单的布隆过滤器来检测重复,可以更加快速高效地检测到重复数据,并完成去重.
1 基础知识
1.1 布隆过滤器
布隆过滤器(Bloom filtering,BF)多用于对重复数据的检测,其基本过程简单易懂,且在不断被改进,以降低其误判率.算法过程如下.
首先创建一个m位的BitSet,将所有位初始化为零,然后选择k个不同的哈希函数,第i个哈希函数对字符串str哈希的结果记为hi(str),其值在0~(m-1)内.
其中,加入字符串过程为:对字符串str,分别计算h1(str),h2(str),h3(str),…,hk(str),然后将BitSet的第h1(str),h2(str),h3(str),…,hk(str)位设为1,如图1所示.
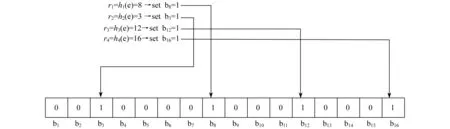
图1 Bloom Filtering的创建过程
检查字符串是否存在的过程为:检查BitSet的第h1(str),h2(str),h3(str),…,hk(str)位是否为1,若其中任何一位不为1,则可以判定str一定没有被记录过.若全部位都是1,则认为字符串str存在.
若一个字符串对应的bit不全为1,则可以肯定该字符串一定没有被Bloom Filtering记录过.但是若一个字符串对应的bit全为1,实际上是不能完全肯定该字符串被Bloom Filtering记录过的,这是因为其中存在误识别率(假阳性).
定义BF用于查询检测过程中会存在一定的误识别率,即把不存在的数据视为存在集合中,称为假阳性.这个概率是很小且可计算的,适当选择哈希函数k的个数和数组m的大小,来控制假阳性概率使其达到最小.可忽略的假阳性概率大小为:
式中:n——元素个数.
1.2 信息锁加密

1.3 所有权认证
所有权认证[9](Proof of Ownership,PoW)就是对用户进行一种检测,判断用户是否拥有数据的全部内容,而不是仅有数据的摘要值,目的是在客户端重复数据删除时保证数据的安全性.通过这种方法,用户可以向服务器证明其确实拥有整个文件,而后即可进行访问操作.
此处所有权认证运用椭圆形曲线加密方法来实现,其中(Vi,si)代表用户的一对密钥对,用来重复检测认证,P代表椭圆形曲线加密的基准点.在用户上传数据发现标签T已存在时,就需要对用户进行PoW检测,所有权认证过程[10]如下:
(1) 服务器选择一个随机数c∈R{0,1,2,…,2σ-1},发送给用户;
(2) 用户计算y=h(M)+sic,将y通过安全通道发送给服务器;
(3) 服务器计算h(yP+cVi),判断结果是否等于T;如果结果为T,则证明用户对该数据拥有所有权,可以进行重复数据删除操作;如果结果不为T,服务器则终止后续操作.
2 系统模型
2.1 模型介绍
本系统模型只包括用户和云服务器两个实体,二者之间进行通信交流,如图2所示.用户将个人数据经外包加密上传至不完全可信的云存储服务器.在原始信息锁加密方案的基础上有许多变体方案,JIANG T等人[8]在信息锁加密方案的基础上引入决策树的数据结构,实现了信息锁加密的相等检测.本文采用布隆过滤器的结构来实现信息锁加密的相等检测.本方案和信息锁加密有些许不同,不再是简单使用收敛密钥对数据加密,而是采用随机密钥加密数据,再对随机密钥进行加密的方法.

图2 系统模型
用户在上传数据到云存储服务器时,实现了客户端与服务器端的相互作用.其中,用户在上传数据时被分为初始上传者(数据所有者)和后续上传者(数据持有者).
2.1.1 初始上传者
2.1.2 后续上传者
数据持有者在将数据存储到服务器时,如果经检测前面已有人上传,则后续上传者需要进行EQ检测,判断重复性,并且需要对该用户进行所有权认证,判断其是否真正拥有该数据,再进行后续操作.
2.2 方案介绍
2.2.1 BF实现重复检测
布隆过滤器技术用于数据的检测查询,是重复数据检测技术常用的一种方法.该技术过程简单易懂,并且具有较高的时间和空间利用效率.本文将布隆过滤器结构用于信息锁加密技术的相等检测部分,通过标签信息检测冗余.具体算法过程如下.
从上述算法过程可知,利用BF可以简便地实现重复检测,也可以保证数据的隐私,实现数据的安全存储,节省空间.用户和服务器之间对数据进行重复检测时,只需要上传摘要值的密文,不需要上传所有数据,既可实现客户端重复数据删除,又可以节约带宽,提高带宽利用率.
2.2.2 CBF实现重复检测
上述BF技术可以实现重复检测,但BF只能实现插入操作,不能实现删除操作,对动态集合支持有限.后来有学者提出了计数布隆过滤器(Counter Bloom Filtering,CBF),CBF将BF二进制向量的每一位扩展成一个计数器,如图3所示.
该方案算法过程与BF结构过程几乎完全相同.
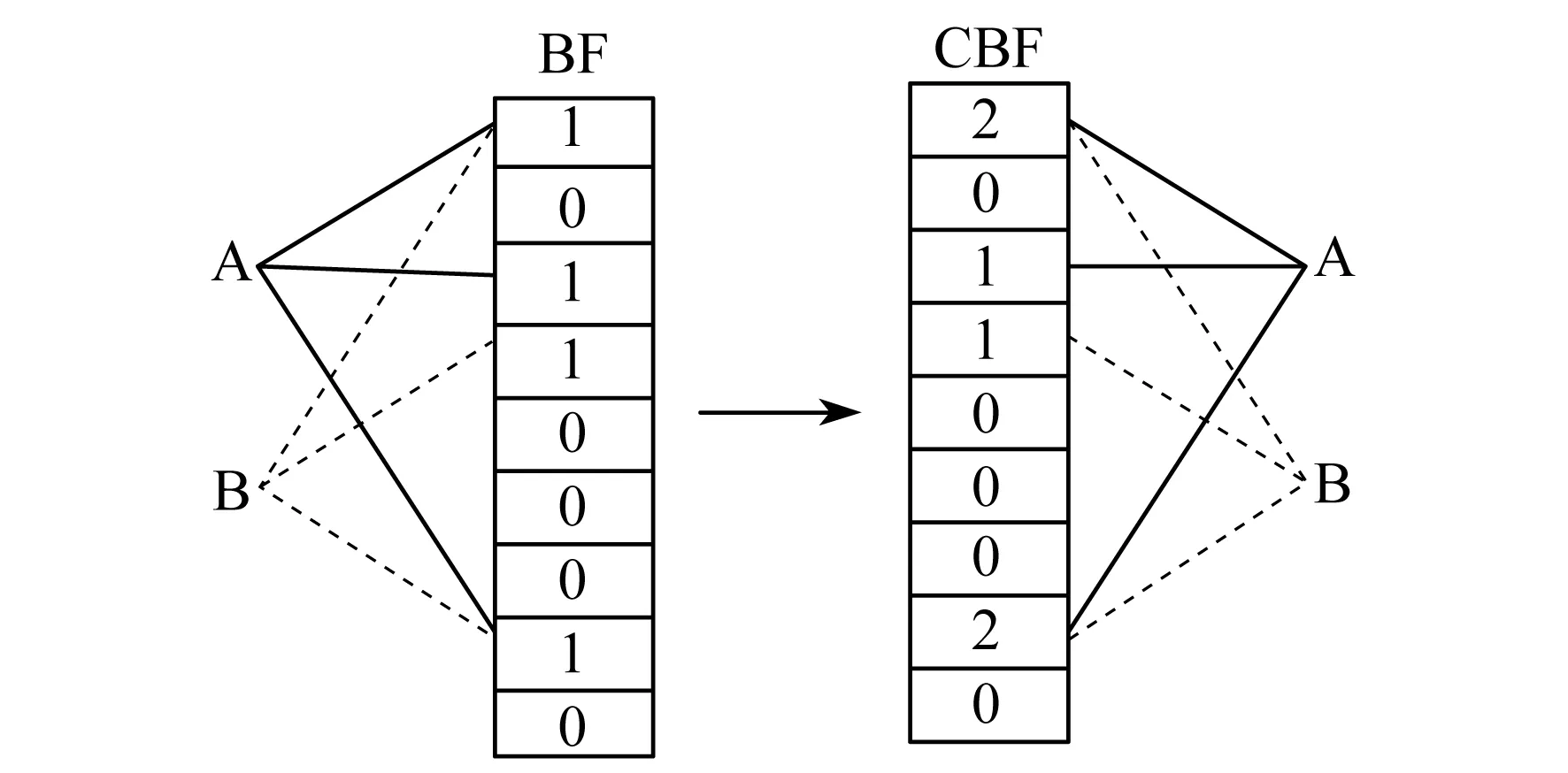
图3 BF到CBF的转换示意
上述过程为整个上传数据的过程,可以实现重复数据的查询删除,查询效率与BF结构相同,可以实现BF结构所支持的所有操作,并具有自己的特色.本方案在用户要删除数据时,需要同时删除对应CBF哈希表中的记录,即对应哈希位的计数器减1,这是BF结构无法支持的操作.
本文中采用的BF结构可以方便快捷地实现重复检测,从而完成重复数据的删除,并保证了数据的安全.
3 性能分析
本文的方案较信息锁加密存在不同,不用收敛密钥对数据加密,而是采用随机密钥加公共参数来加密数据,并对随机密钥再进行加密,以保证数据的机密安全性,采用所有权认证以保证数据的完整可用性.
与文献[6]相比,本方案在安全性方面优于单纯使用收敛加密方案.在忽略BF错误率的情况下,本方案操作简单,计算开销小.文献[8]使用树结构来实现重复检测,再加上各种配对计算,计算开销远超过本方案.与文献[7]提出的方案进行比较,结果如表1所示.由表1可以看出,由于哈希操作简单耗时较短,本方案在计算开销方面耗时较少.

表1 数据重复删除的计算消费
由文献[12]可知,对于160位的数据,单一指数运算耗时1.1 ms,配对运算耗时3.1 ms,乘法操作耗时0.6 ms,哈希运算可忽略不计(0.2 ms),方案计算花费比较如图4所示.由图4可以看出,本方案的计算开销较文献[7]的方案明显降低.

图4 3种方案的用户端计算开销
4 结 语
本文提出了基于Bloom Filtering检测的信息锁加密的方法,实现了重复数据的安全删除,安全性高于基础的收敛加密方法;提高了系统的运行效率,节约了计算成本.该方法的设计思想简单且易于实现,在目前的重复数据删除技术研究中应用比较广泛.
[1] LI J,CHEN X,LI M,etal.Secure deduplication with efficient and reliable convergent key management[J].IEEE Transactions on Parallel and Distributed Systems,2014,25(6):1 615-1 625.
[2] LI J,CHEN X,HUANG X,etal.Secure distributed deduplication systems with improved reliability[J].IEEE Transactions on Computers,2015,64(12):3 569-3 579.
[3] 敖莉,舒继武,李明强.重复数据删除技术[J].软件学报,2010,21(5):916-929.
[4] ARMKNECHT F,BOHLI J M,KARAME G O,etal.Transparent data deduplication in the cloud[C]//Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security,2015:886-900.
[5] 张明月.客户端加密重复数据删除机制的研究[D].西安:西安电子科技大学,2014.
[6] DOUCEUR J R,ADYA A, BOLOSKY W J,etal.Reclaiming space from duplica files in a serverless distributed file system[C]//Proc of the 22nd Int Conf on Distributed Computing Systems.Piscataway:IEEE,2002:617-624.
[7] BELLARE M,KEELVEEDHI S,RISTENPART T.Message-locked encryption and secure deduplication[C]//EUROCRYPT,2013:296-312.
[8] JIANG T,CHEN X,WU Q,etal.Towards efficient fully randomized message-locked encryption[C]//Australasian Conference on Information Security and Privacy.Springer International Publishing,2016:361-375.
[9] HALEVI S,HARNIK D,PINKAS B,etal.Proofs of ownership in remote storage systems[C]//ACM Conference on Computer and Communica-tions Security,2011:491-500.
[10] YAN Z,DING W,YU X,etal.Deduplication on encrypted big data in cloud[J].IEEE Transactions on BigData,2016,2(2):138-150.
[11] HUR J,KOO D,SHIN Y,etal.Secure data deduplication with dynamic ownership management in cloud storage[J].IEEE Transactions on Knowledge and Data Engineering,2016,28(11):3 113-3 125.
[12] SCOTT M.Efficient implementation of cryptographic pairings[EB/OL].[2007-04-05].http://www.pairing-conference.org/2007/invited/Scottslide.pdf.
(编辑 白林雪)
AnalysisofSecurityDeduplicationBasedonBloomFilteringDetection
ZHANGRui,WENMi
(SchoolofComputerScienceandTechnology,ShanghaiUniversityofElectricPower,Shanghai200090,China)
The fast growth of data promotes the development of cloud computing and cloud storage,so a large amount of data is stored in the cloud,and the accumulation of data occupies too much storage space.In order to save space,data deduplication technology is proposed and widely used.Based on the original message-lock encryption(MLE),bloom filtering is used to achieve the duplicate detection then complete the safety storage.The performance of scheme is analyzed,which can achieve basic security and confidentiality and reduces the computational overhead.
cloud storage; deduplication; message-lock encryption; bloom filtering; secure storage
10.3969/j.issn.1006-4729.2017.04.019
2017-04-17
张瑞(1990-),女,在读硕士,安徽宿州人.主要研究方向为安全重复数据删除,信息安全.E-mail:593705081@qq.com.
国家自然科学基金(61572311);上海市地方能力项目(15110500700).
TP309;TP309.7
A
1006-4729(2017)04-0402-05
