基于随机森林的用电行为分析
2017-10-10陈晶晶李红娇
陈晶晶, 李红娇, 许 智
(上海电力学院 计算机科学与技术学院,上海 200090)
基于随机森林的用电行为分析
陈晶晶, 李红娇, 许 智
(上海电力学院 计算机科学与技术学院,上海 200090)
长期以来窃电问题一直困扰着电力企业,它不仅损害了供电企业的合法权益,扰乱了正常的供用电秩序,而且给安全用电带来了威胁.通过机器学习算法,对电力用电数据进行分析处理,可以预测用户是否存在窃电行为.基于电力数据中用户用电量提取相关特征,结合随机森林算法,提出了一种预测用户是否具有窃电行为的方法.对比多组实验数据,调节特征数量以及算法参数,以提高预测准确率和预测速度.
随机森林; 分类; 窃电用户; 机器学习
用户窃电行为会对企业的经济效益及社会的稳定发展等带来不良影响.首先,非正常线损会影响供电部门的正常盈利,容易造成企业亏损现象,同时用户的窃电行为会影响正常的市场经济秩序,全国每年因窃电造成的损失高达200多亿元[1];其次,用户窃电会影响周围用户用电,而且私自乱接线,会有引发触电或者火灾等安全隐患,严重影响社会稳定秩序.
传统的窃电方法有很多,如改变电表结构、电线私拉乱接、无表用电等.目前,使用干扰器,让电表慢转、停转甚至反转成为主要的窃电方式.但是无论窃电方式如何变化,原理万变不离其宗,就是影响电能计量装置的正常计数.电能计量装置主要由电流互感器、电压互感器、端子盒、二次接线、电能表以及电能专用计量箱组成,主要的功能就是计量用户在单位时间内消耗的有功电能和无功电能等[2].目前,电力企业在反窃电技术上存在一定的局限,仅凭线损率的计算来估计窃电用户,只有当线损率大于15%时,才能肯定该用户为窃电用户[3].近年来,越来越多的人将机器学习与电力数据相结合来提取特征,挖掘出窃电用户行为.文献[4]认为,电力用户数据的不断增加,用电数据特征数目也会随之增加,导致用电特征数据连续化,如果用传统的CURE算法进行数据挖掘,就需要对电力大数据进行离散化,其计算量大、耗时长,且容易丢失重要的特征信息,故提出了一种利用信息熵原则分析法提取特征值的方法,以提高预测的准确度.文献[5]利用日用电量、用户最大线损率、用表类型、所在台区线损、三相不平衡率、微机扫描情况、功率因数及合同容量比作为反窃电模型的单项指标,结合人工神经网络分析窃电行为,但其只涉及某一个用户窃电可疑性的大小,并没有对整个用户样本预测准确率进行分析.文献[6]提出根据某段时间周期内用户的用电量总体变化趋势来评测用户窃电的可能性,但是并没有结合机器学习,在效率上不够高效.
本文根据某电力公司提供的电力数据,利用用户的日用电量数据进行分析,并没有加入线损率、用表类型等属性,这样可以减少训练的数据量,加快数据预处理以及后续预测的速度.根据用户的日用电量,提取特征分析,随后结合随机森林算法,预测窃电用户,并分析结果.
1 经典机器学习算法介绍
从电力大数据中挖掘出窃电用户和正常用户,是一个二分类的问题.因此,利用机器学习中的分类算法对电力数据进行分析.机器学习的分类算法常见的有支持向量机(SVM)算法,K-近邻算法,决策树算法等.但这些算法并不都是适合电力大数据的二分类.
1.1 支持向量机算法
该算法的核心思想是,寻找一个非线性映射,通过该映射把样本数据映射到高维的特征空间中.利用的估计函数为:
f(X)=ωφ(X)+b
(1)
式中:ω——权值大小;φ(X)——映射函数;b——偏置.
根据统计学理论,支持向量机通过极小化目标函数确定回归函数[7].但支持向量机算法设计的初衷是对小样本数据进行训练,并不适合电力窃电用户行为的挖掘,究其原因,在于该算法会导致训练时间长,且极消耗电脑内存,故该算法不适合大数据下窃电用户的挖掘.
1.2 K-近邻算法
该算法是1968年由Cover和Hart提出的.其基本原理是从大样本空间中,对一个待分类的数据对象从训练数据集中找出与之最相近的K个点,取出其中众数最多的类别作为待测数据点的分类类别.此算法适用于样本分布均匀的数据.但在电力数据中,窃电用户数据相对于正常用电用户的数据较小,存在样本分布不平衡的特点,且此算法结果的理解性不高,所以也不适合电力窃电用户的挖掘.
1.3 决策树算法
20世纪70年代,FRIEDMAN J提出将决策树算法运用到分类问题的研究中.决策树是一个树状结构,它是通过一个特征属性对样本进行分类,其每个非叶子节点表示一个特征属性上的测试,每个分支代表这个特征属性的输出.使用决策树进行决策是从根节点开始,根据决策树的分支,对待测数据的对应特征属性进行分类,直至叶子节点,得出分类结果.20世纪70年代末,QUINLAN J R开发出决策树ID3算法,提出了利用信息轮中的信息增益作为决策树属性拆分节点的判断依据[8].1984年,BRIMAN L和FRIEDMAN J重新整理决策树算法,得出了分类回归树(CART)算法.1993年,QUINLAN J R在ID3的基础上提出了C4.5算法,用Gini不纯度代替信息增益作为决策树属性拆分节点的选择[9].决策树算法具有输出结果易于理解、对中间值缺失值不敏感的优点,适合电力数据挖掘的要求[10].
但是单独的决策树会存在过拟合的风险.BREIMAN L于2001年提出了随机森林(randomforests)算法,它是一种组合多个树分类器进行分类的算法,避免产生过拟合的风险.
1.4 随机森林算法
随机森林算法通过重采样(bootstrap)方法,从样本里有放回地重复抽取n个样本生成新的样本,然后重复以上步骤,生成m个决策树,这些决策树之间是独立的,新分类的分类结果是根据分类树投票多少来决定的[11].
假设给定一系列分类树:h1(x),h2(x),h3(x),…,hk(x),根据输入变量(X,Y)定义余量函数(margin function)为:
mg(X,Y)=avgkI(hk(X)=Y)-
maxZ≠YavgkI(hk(X)=Z)
(2)
式中:X——输入特征变量的集合;Y——输入变量的正确标签集合;Z——预测错误的标签集合;I(·)——示性函数,前一项是代表将变量X正确分类的平均分类器数,后一项是将变量X错误分类最多的平均分类器数.
余量函数用来度量随机森林算法对输入变量X产生的误差.余量函数可以用于定义随机森林的预测误差,即:
E=PX,Y(mg(X,Y)<0)
(3)
定理随着随机森林分类器的数目增加,E几乎处处收敛于:
mg(X,Y)=PX,Y[Pθ(h(X)=Y)-
maxZ≠YPθ(h(X)=Z)<0]
(4)

从该定理可以看出,随机森林的预测误差会收敛到泛化误差,这说明随机森林在理论上是不会发生过拟合现象的.
随机森林算法流程如下:
(1) 从样本空间有放回地随机采样选出n个样本;
(2) 从所有提取出的特征中随机选择k个特征,对选出的样本利用这些特征建立决策树;
(3) 重复前两步m次,则生成m棵决策树,即形成了随机森林;
(4) 对于测试数据,经过每棵决策树进行决策,然后通过投票决定分到哪一类.
从上述分析可以看出,随机森林具有如下5个优点:一是经过理论推断,该算法有效地避免了过拟合;二是每一棵树都是随机选择部分样本和部分特征,使得算法具有很好的抗噪能力,稳定性好;三是可以并行计算;四是可以处理高维数据,并且不需要自己选择特征,算法通过投票决策;五是实现比较简单,易于理解.
因此,本文决定结合随机森林算法,对电力数据进行窃电用户和正常用户的二分类.
2 基于随机森林算法的用电数据分析
2.1 数据格式
智能电表数据有很多维,如用电量、无功功率、电压、电流等,如果把这些数据都放入算法里,内存消耗极大且运行速率很差,甚至还会形成“维数灾难”.
本文只是利用用户的日用电量作为指标.利用某电力公司提供的数据集,数据大小为6.54 G,属性有用户的ID,当天电表数,前天电表数,当天用电量,日期,窃电标志等.
表1是某电网公司经过处理后得到的电表数据.表1中,ID代表的是用户名(已处理过了);Date代表日期时间;KWH_TD代表的是当天的电表读数;KWH_YSD代表的是前一天的电表读数;KWH代表的是当天的用电量;Label为该用户的标签,“1”表示该用户为窃电用户,“0”表示该用户是正常用户,“Nan”代表缺失值.

表1 电表数据
由表1可知,每个用户有很多天连续的数据,但是每一个用户的数据量不等;部分用户数据存在缺失情况;这些数据后面都有窃电用户的标示,方便之后对数据进行测试.
2.2 特征提取
用电数据预处理的特征提取流程如图1所示.

图1 用电数据特征提取流程
2.2.1 提取含零百分数特征
根据用户电表数据分析可知:
(1) 某用户每天的用电量都为零,几乎可以判断该用户为窃电用户;
(2) 某用户存在连续用电量都为零,但不是全为零,该用户为窃电用户的可能性极高;
(3) 某用户用电量为零,断断续续,该用户也有可能是窃电用户.
当然也会存在一些用户长时间不在家的可能性,但这种可能性比较小.因为每个用户的数据量是不一样,所以不能提取含零的数据个数,而是提取含零百分数特征,避免特征的不公平性.
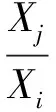
(5)
式中:PZeroi——含零百分数;Xj——第i个用户有j个包含零的数据;
Xi——第i个用户总的数据量.
2.2.2 提取含缺失值百分数特征
根据用户电表数据分析可知:
(1) 某用户电表读数在电网中心不显示,说明电表出现问题,该用户为窃电用户的可能性很大;
(2) 某用户电表读数经常不显示,但是会有几天读数,该用户存在窃电嫌疑.
当然,数据存在缺失值也有可能是电网中心存在“丢包”现象,导致数据缺失,但一般这种情况很少发生.因此,当某用户电表读数丢失,很有可能是用户故意干扰电表计数以及上传,故可以提取缺失值百分数特征.
(6)
式中:PNani——缺失值的百分数;Xj——第i个用户存在j个缺失值的数据.
2.2.3 提取方差特征
方差主要体现数据的波动情况.某用户用电量总是会发生忽高忽低,出现大幅度的波动现象,则该用户窃电的可能性很大.

(7)

2.2.4 提取平均值特征
平均值代表用户的用电水平,如果一个用户用电量低于一个水平,如用电量平均只有0.1 kWh,则该用户窃电的可能性极大.
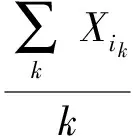
(8)
式中:Ai——用户的用电量平均值;Xik——第i个用户第k天的用电量;k——用户数据量的大小.
2.3 实验过程
2.3.1 实验环境配置
电脑配置如下:惠普Envy13-d025tu,内存为8 G,显卡为HD520,处理器为酷睿i5-6200,主频为2.3 GHz.本文选择python工具处理用电数据,使用的是python2.7版本,该软件集成了numpy,pandas,sklearn机器学习包等数据分析所需要的包,方便用户分析数据,同时还拥有Spyder集成开发环境,类似于Matlab界面,模仿了Matlab的“工作空间”功能,可以很方便地观察和修改数组的值.
2.3.2 参数介绍
由于电力用电数据达6.54 G,直接读入内存,会影响电脑运行速度,甚至会导致电脑进程崩溃.python里的pandas模块下read_csv函数很好地解决了这一问题.chunksize参数设置为200 000,进行每次200 000个数据迭代,将训练数据读取进来,分片式处理用户用电数据.数据预处理后得到用户用电特征数据仅3.01 MB,即将“大数据”转化成“小数据”,有利于下一步随机森林预测.将数据分为训练集和测试集,训练集有44 219 条记录,测试集有9 956条记录.
Sklearn中随机森林算法的参数有很多个,常用的参数如表2所示.
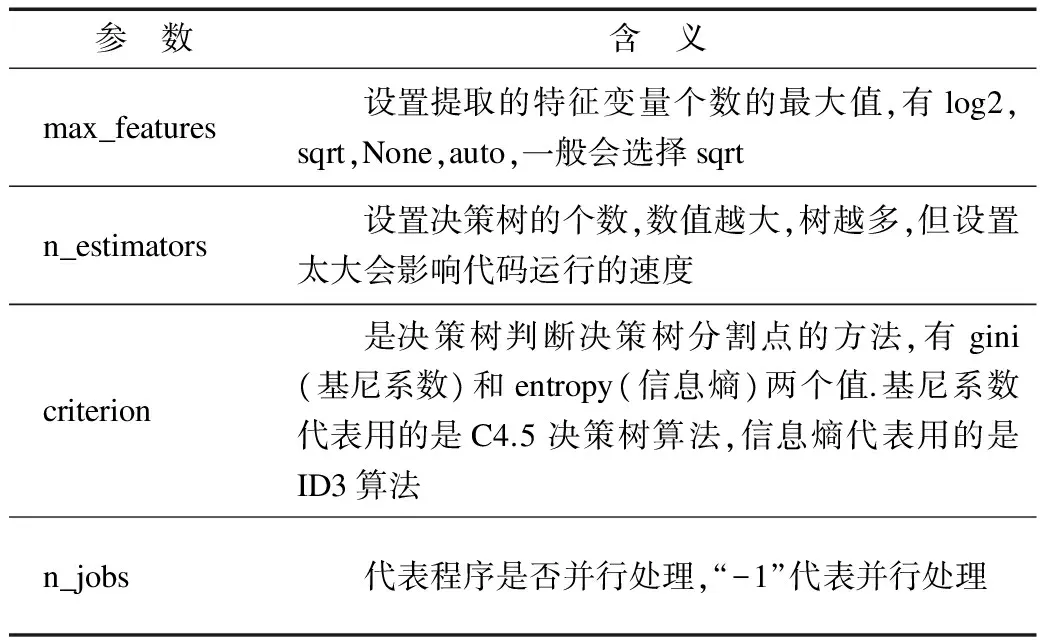
表2 随机森林分类器参数
2.3.3 基于不同特征的实验结果
将n_estimators设置为600,max_features设置为3,criterion设置为gini,n_jobs设置为-1,输入训练集44 219行数据,测试数据9 956行数据,得出的结果如表3所示.
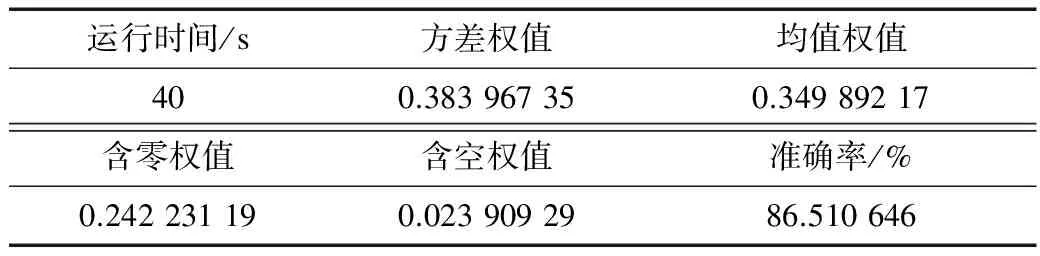
表3 4个特征的测试数据
其中准确率Accuracy定义为:

(9)
式中,Pt,Nt,Nf,Pf分别表示窃电用户准确预测的人数,正常用户准确预测的人数,正常用户预测错误的人数,窃电用户预测错误的人数.
实验结果显示:随机森林建立600棵树,训练44 219记录,到对9 956条数据进行预测,只需要40 s,处理速度很快,且预测的准确率达86.5%.方差占权值很大,说明窃电用户嫌疑最大的可能就是用电量波动性很大的用户,而缺失值的权值很小,说明发生用户用电量数据缺失,并不能完全代表该用户是窃电用户.
移除缺失值特征,保留算法参数不变,得出的实验结果如表4所示.

表4 3个特征测试数据
由表4可以看出,运行时间不变,准确率下降了一点,同时单一用户数据含零权值的权值比重下降很多,说明含零百分比权重存在,但相对于方差和均值的重要性要弱一点.
移除单一用户数据含零权值特征,将max_fatures改为2,得出的实验结果如表5所示.

表5 2个特征的测试数据
综合表3,表4,表5可以看出,当提取的4个特征全部放入随机森林决策树中时,准确率会有所提高.
2.3.4 基于随机森林模型不同参数的测试
不同参数测试数据如表6所示.

表6 不同参数测试数据
从表6可以看出,决策树数量越大,运行时间越长,但准确率并不随着n_estimators越大而变得越准;entropy比gini运行速度更快一点,同时准确率也提高了不少.
2.3.5 实验结果分析
综合上述实验发现,当决策树大小为300,判断依据为信息熵entropy,以及最大特征数为3时,运行速度和准确都会提升,准确率基本维持在0.865 5.但该实验还存在一些不足之处:如每个用户的数据量不同,会导致提取特征的公平性有所缺失,因为用户在每一个季度里的用电量是有明显差异的,这会影响方差这一特征.因此,可以对每个用户进行一个星期的均值特征提取,分析其波动情况,进一步提高预测准确率.
此外根据以上实验数据发现,本文所提出的4个特征值方差的重要性最高,即:如果一个用户每天用电量变化幅度大,很可能就是窃电用户;缺失值百分数的重要性最低,即:电表出现故障以及人为破坏电表的行为较少.
3 结 语
面对智能电网的不断发展,电力数据暴增不可避免,通过单一提取用电量这一维数据,可以大大减小数据量,加快数据处理速度,同时通过随机森林的并行处理,可以快速准确地挖掘出窃电用户.
[1] 周文婷,顾楠,王涛,等.基于数据挖掘算法的用户窃电嫌疑分析[J].河南科技,2015(10):1 767-1 772.
[2] 丁晓.用电检查与反窃电智能信息平台的设计与应用[J].电力需求侧管理,2012(3):49-52.
[3] 柴鹏飞,陈国栋.数据分析在反窃电中的应用[J].河南电力,2013(2):61-64.
[4] 郭崇,王征,纪建伟,等.电力用户数据中用电特征数据挖掘模型仿真[J].计算机仿真,2016(5):447-450.
[5] 曹峥,杨镜非.BP神经网络在反窃电系统中的研究与应用[J].水电能源科学,2011(9):199-202.
[6] 杨小铭,花永冬,黄淳驿,等.低压台区用户的防窃电的趋势嫌疑度分析方法研究[J].电器与能效管理技术,2016(10):28-36.
[7] 李瑾,刘金朋.采用支持向量机和模拟退火算法的中长期负荷预测方法[J].中国电机工程学报,2011(16):63-66.
[8] QUNLAN J R.Induction of decision tree[J].Machine Learning,1986(1):81-106.
[9] HASTIE T,TIBSHIRANI R,FRIEDMAN J.统计学习基础——数据挖掘、推理与预测[M].范明,柴玉梅,等,译.北京:电子工业出版社,2004:40-44.
[10] 冯少荣.决策树算法的研究与改进[J].厦门大学学报(自然科学版),2007(4):496-500.
[11] 方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2011(3):32-38.
(编辑 胡小萍)
AnalysisofPowerConsumptionBehaviorBasedonRandomForest
CHENJingjing,LIHongjiao,XUZhi
(SchoolofComputerScienceandTechnology,ShanghaiUniversityofElectricPower,Shanghai200090,China)
For a long time,the problem of electricity stealing has been plaguing power enterprises.It not only detriments the legitimate rights and interests of power enterprises,disturbs the normal order of the power supply,but also causes the electrical safety threat.The data of electrical power with machine learning algorithms is analyzed,which can predict the existence of users stealing power behavior.Based on feature extraction of electricity consumption in power data,and by using the random forests algorithm,a method of predicting the existence of users stealing power behavior is proposed.By comparing multiple sets of experimental data,the parameters of the algorithm are adjusted to improve the accuracy of forecasting.
random forests; classify; stealing users; machine learning
10.3969/j.issn.1006-4729.2017.04.005
2017-03-09
陈晶晶(1993-),男,在读硕士,江苏盐城人.主要研究方向为电力信息技术专业.E-mail:757167127@qq.com.
国家自然科学基金(61403247);上海市信息安全综合管理技术研究重点实验室开放课题(AGK2015005);上海市科学技术委员会地方能力建设项目(15110500700).
TP18;TP301.6;TM715
A
1006-4729(2017)04-0331-06
