Mapreduce模型及支撑系统概述
2017-10-09李炜贺丽娟陕西国防工业职业技术学院陕西西安710300
李炜,贺丽娟(陕西国防工业职业技术学院,陕西西安,710300)
Mapreduce模型及支撑系统概述
李炜,贺丽娟
(陕西国防工业职业技术学院,陕西西安,710300)
MapReduce是由并行编程模型及相关支撑系统组成的数据处理框架,通过定义接口和运行时支持库, 通过定义良好的接口和运行时支持库,能够自动并行执行大规模计算任务,通过隐藏底层实现细节,降低实现并行编程的难度,Hadoop 是目前MapReduce 框架最流行的开源实现。文章首先介绍了 MapReduce 并行编程模型及其hadoop的运行原理、运行机制, 深入研究了 MapReduce 计算任务在 Hadoop 系统中的运行过程。
大数据;MapReduce;hadoop;HDFS
0 引言
MapReduce 由Google公司于2004提出的一种最为成功的面向数据的并行编程模型[1],该模型给程序员在复杂的分布式集群平台上提供了简单的编程接口和强大的支撑系统,使海量数据的并行编程模型变得简单易学、大大的降低并行编程难度,让程序员只需要了解应用程序的业务逻辑实现。MapReduce 模型的支撑系统来自行处理以下工作:(1)任务调度并行(2)弹性分布(3)系统负载均衡和容错等问题。
首先在数据预处理阶段,Hadoop系统把数据先载入到分布式存储文件中;其次数据处理阶段,在Hadoop实现大规模并行数据处理时,可使用Python、java、HiveQL 和 Pig Latin 等编程语言简化并协助对于数据的处理,提高数据处理的 能力与效率[2]。
1 MapReduce 编程模型及Hadoop系统
1.1 MapReduce编程模型
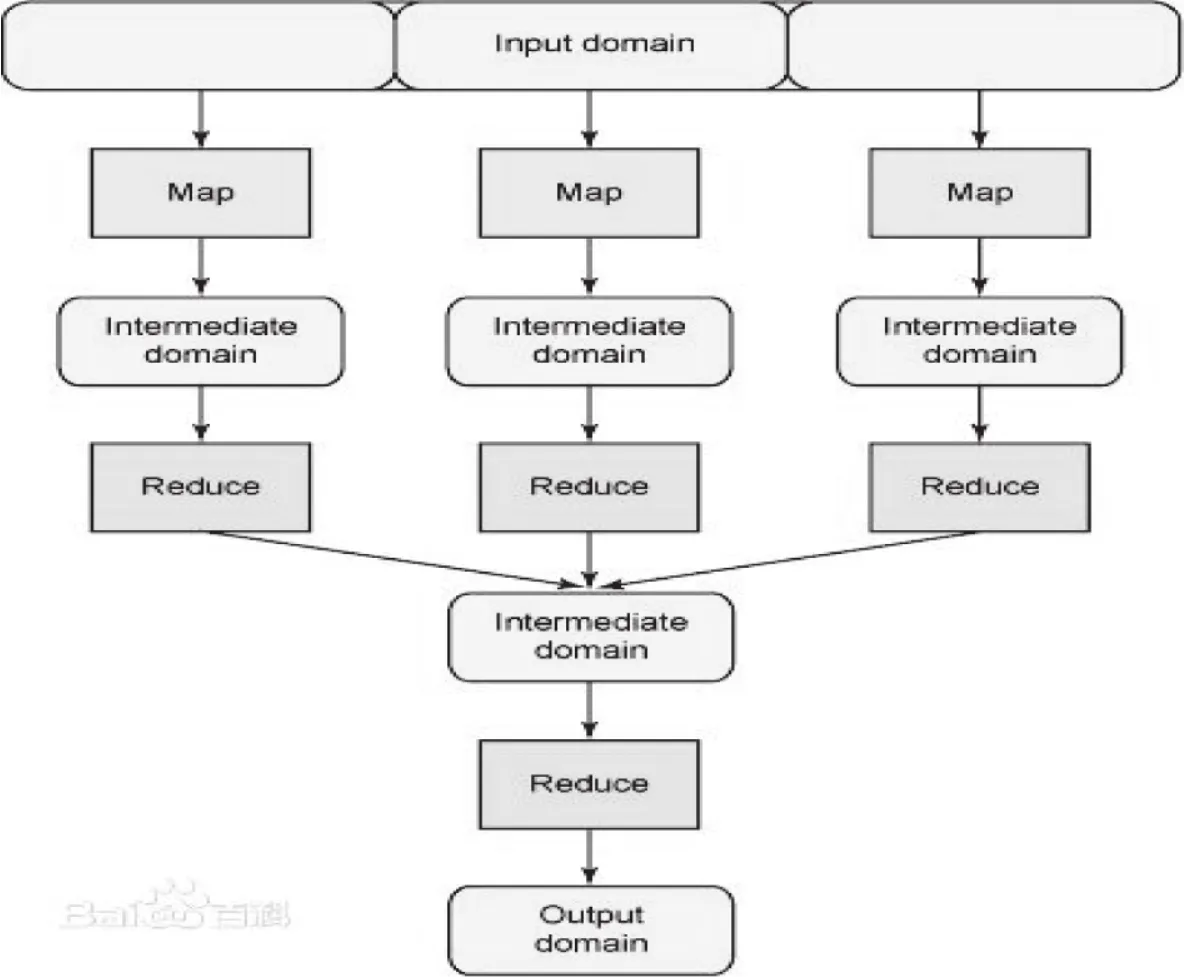
MapReduce编程模型的核心是map和reduce两个指定函数的定义和执行,map()责分块数据的处理,reduce()函数负责对分块数据处理的中间结果进行归约。MapReduce其实就是Divide/Conquer 的过程, map阶段将输入数据U<keys,values>,然后对这些值进行map操作,得到中间数据[3]。接着对这些拆分后的数据进行高度并行的map运算, 最后将 Map 后的结果进行 Reduce, 得到最终的结果。 有时,由于数据的原因,需要将原始数据分解成多个MapReduce过程。其处理对于数据的处理流程示意图如图1所示。
1.2 Hadoop系统
Hadoop 它是由Apache基金会所开发的以MapReduce编程模型为核心的开源分布式的系统基础架构计算框架项目[4]。其中HDFS和MapReduce为Hadoop的框架的核心设计。HDFS为海量大数据的存储提供了可行性的技术支持,MapReduce则为海数据的计算提供了可能。Hadoop它是一个可以实现对大量数据进行分布式处理的一种软件框架,以高效、可伸缩、可靠的、高错容、低成本的方式对数据进行处理。
1.2.1 Hadoop的组织架构
Hadoop 系统对大规模机器集群以主从的组织方式进行管理,即把各处理节点划分为一个Master节点和若干个Slave节点,如图 2-2。主节点上运行守护程序,守护程序主要负责对整个计算任务执行过程的统一管理,并且把计算任务分解成可并行执行的若干个子任务,同时分配到各从节点中。节点上运行守护程序,从节点的任务是负责调度各从节点中的处理机资源,并完成各子任务的具体执行。具体执行过程如下图2所示。
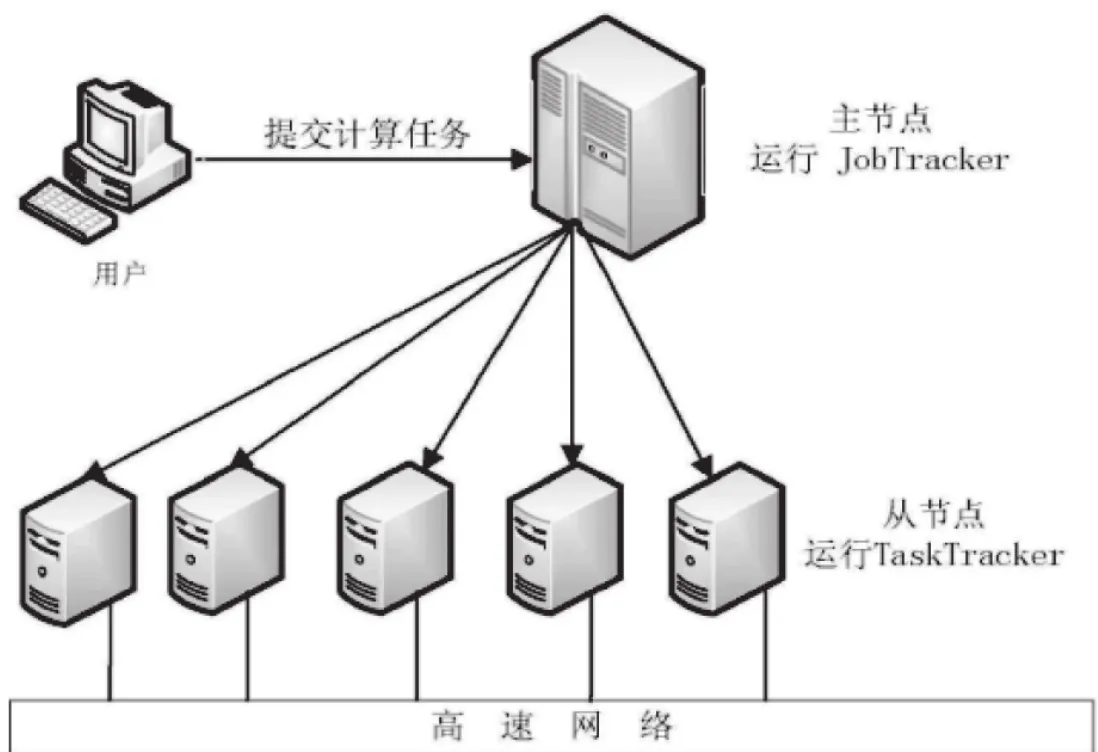
图2 Hadoop的组织架构
1.2.2 分布式文件系统 HDFS
HDFS采用master/slave架构,是Hadoop系统的重要组成。一个独立的HDFS集群由一个Namenode和若干个Datanodes组成。其中,Namenode是负责管理文件系统namespace以及客户端对文件的访问的中心服务器。集群中的Datanode一般是负责管理它所在节点上存储的一个节点。其处理流程图如图3所示。

图3 HDFS数据处理流程
2 MapReduce任务计算过程
一般给定系统集群资源后单个 MapReduce 计算任务的具体执行步骤如下。
(1)计算任务的提交
把用户提交的数据集的数据划分为若干个数据块,同时把各数据块载入到 Hadoop集群的各从节点,HDFS 文件系统的 DatatNode 和 NameNode 负责数据的管理和存储。程序集被送到主节点负责完成对程序的调度执行,主要通过主节点中的JobTracker 和多个从节点中的 TaskTracker实现完成。
(2)Map子任务的执行
主节点中的JobTracker把map函数的执行代码传输分配到选定的从节点中,再由从节点上的TaskTracker对节点或附近节点的数据块调度执行map函数,形成多个Map子任务。
(3)Reduce子任务的执行
部分Map子任务执行完毕时,选定的节点开始执行reduce函数,开始对由Map子任务产生的中间数据键值对<u2,v2>进行处理。Reduce的子任务数可以为一个或若干个。
(4)结果返回阶段
把存储在HDFS中计算任务的执行结果提交给用户。
本文主要介绍mapreduce模型及其支撑系统的模型,分别对mapreuce编程模型、hadoop的结构及Hdfs进行了简单的介绍,对于在实际系统中影响系统执行效果的资源优化配置如:系统容错、系统的任务调度及负载均衡等由于篇幅关系这里不在介绍。总之,随着大数据产业的发展,对于mapreduce及其支撑系统的研究具有非常重大的意义。
3 总结
[1]Dean J, Ghemawat S. MapReduce: Simplified data processingon large clusters. Communications of the ACM, 2008, 51(1):107-113.
[2]韩海雯.MapReduce计算任务调度旳资源配置优化研究[D].华南理工大学,2013.10.
[3]应毅.MapReduce 并行计算技术发展综述[J].计算机系统应用,2014.
[4]Tom White 著.周敏奇,王晓玲,金澈清等译.Hadoop权威指南(第二版)[M].北京:清华大学出版社,2011.
Overview graphs model and support system
Li Wei,He Lijuan
(Shanxi instiute of technology,Xi’an Shaanxi,710300)
MapReduce is composed of parallel programming model and its support system data processing framework, through the definition of interface support library and runtime support library, through the definition of a good interface and operation, capable of automatic parallel execution of large-scale computing tasks, by hiding the underlying implementation details, reduce the difficulty of parallel programming, Hadoop is currently the most popular MapReduce framework open source implementation. Firstly, this paper introduces the MapReduce parallel programming model and the operation principle and operation mechanism of Hadoop, and deeply studies the operation process of MapReduce computing task in Hadoop system. Key words: big data; graphs; hadoop; HDFS
李炜(1990.9),男,汉族,籍贯陕西礼泉,助教,硕士研究生,研究方向人工智能大数据。
