基于内容和引用的科学领域主题的发现
2017-10-09张长宏张明亮
张长宏,张明亮
(青海民族大学)
基于内容和引用的科学领域主题的发现
张长宏,张明亮
(青海民族大学)
结合了文献的引用和内容,将内容相似度和引用相似度融合形成统一的语义空间,谱聚类后发现更准确的主题.最后以IEEE VIS 顶级会议的文献为数据集进行了验证,显示有较好的效果.
主题发现;引用分析;内容分析;IEEEVIS文献
0 引言
发现科学领域内的主要研究内容及未来方向,对于科学管理部门做好后期的规划有着重要的指导意义,也对研究者对一个研究领域的了解、熟悉及提高研究效率有着重要意义.对科学文献研究传统的方法以引用分析为主要分析方法,1964年Martyn J.提出了耦合分析法[1],1965年Garfield提出了引用分析[2],1973年Small H提出了共引分析[3],并成为分析文献的主要方法.他们都以通过文献的引用关系来进行聚类,再通过每个类中最关键的文献来确定该类的研究主题,能够较好的发现科学领域的主要研究方向.但是都有一定的滞后,对于未来的研究方向总是有一个延迟.2004 年,陈超美提出了分析知识领域演化情况的可视化分析方法,并基于Java语言研究开发了知识图谱绘制软件 Citespace Ⅰ[4],具有时序分割、 同被引聚类、 寻径网络、 时序网络可视化分析等功能.2006年又推出了Citespace Ⅱ[5],其版本不断的更新.后来将共现的思想应用于文献的关键词来构建共词网络进行科学领域的研究,对共词网络进行聚类来发现主要的学科研究方向,但是词汇量相对较少,不能很好的反映研究的科学方向.随着自然语言处理技术的进步,提出了主题模型,能较好的反映文本的内容,如LSA,PLSA,LDA[6]等主题模型,并在许多领域得到了广泛使用.但是该本的维度比较高,其噪音也比较高.
针对上面的问题,提出将文本内容与引用关系结合,将两个语义空间中对象关系表示到一个统一的语义空间,再对其融合后的矩阵进行谱聚类,提取更准确的主题.
1 主题的提取方法
为了提取主题,分三步来做,分别是文本内容相似度计算、文本引用相似度的计算、两个相似度矩阵合并后再进行谱聚类,并提取各个主题的主要关键词.
1.1文本相似度的计算
将收集的文献集的题目和摘要作为每一篇文献的文本内容,进行分词后,统计每个词的词频TF,并计算每个词逆文档频率IDF,两者的乘积就得个词的TFIDF.当某个词的TFIDF越高,表示它对文章越重要,故常用排名最靠前的几个词来表示文献的内容,也可用一个类中排名前几位的关键词来表示一个类的内容.最后按照余弦公式(1)来计算两篇文献的相似度,其值越大,表示两篇文献越相似.分子表示两篇文献中所有相同单词的TFIDF差值的平方和,分母表示两篇文献各自的所有单词的TFIDF值的平方和的平方根的乘积.
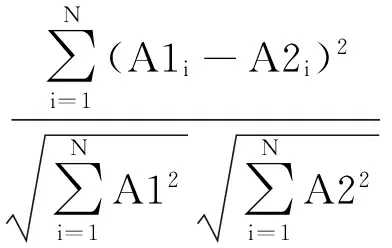
(1)
1.2文本引用相似度的计算
根据文献的参考文献建立文献的引用矩阵,任意两个文献的相似度用公式(2)来计算.当两个文献的参考文献相同越多,两个文献的主题越相似.但是这样构建的矩阵稀疏,分子表示两篇文献共同的参考文献数量,分母表示所有参考文献中有共同参考文献的最大值.

(2)
1.3相似度矩阵的合并及聚类
为了将引用关系和内容相似统一到一个语义空间,采用公式(3)进行合并得到混合矩阵W,认为引用关系和内容的影响是相同的,再利用谱聚类方法对此矩阵进行聚类.
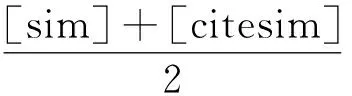
(3)
也可以将上面的相似度矩阵转换成距离矩阵,因为相似度最大值是1,最小值是0,故用全1矩阵减去相似度矩阵得到距离矩阵,再采用Kmeans等方法进行聚类得到各个主题.该实验中采用了谱聚类算法[7],其类算法如下:
(1)把矩阵W的每一列元素加起来得到N个数,得到对角矩阵D,并把W-D的结果记为拉普拉斯矩阵L=D—W.
(2)求出L的前k个特征值(前k个指按照特征值的大小从小到大排序),以及对应的特征向量.
(3)把这k个特征向量排列在一起组成一个N×k的矩阵,使用 K-means 算法进行聚类.引用关系和内容相似度矩阵的合并的本质,直观的讲,就是在主题相似的基础上,提高了主引用文献的相似性,从而保证了聚类有着更高的准确性.认为引用关系和文献内容是同等重要,故对融合矩阵的权重都设为了0.5.如果下一步进行深入研究,可以去调整两个矩阵的权重使其达到合理的值,但要保证权重之和要为1.
最后根据各个类中的文献,提出TDIDF最高的10个词来表示各个类的内容,TFIDF的值越高,对应的词越能表示文献的主题.
2 实验的验证
随着人们生活中的数据指数级的增长,不仅要求数据处理技术不断提高,而且需要快速的解读数据中信息,可视化技术为人们提供了去发现、分析,探索数据中的现象和规律,这几年发展非常迅速.可视化现已广泛应用于生命医学、材料、天文物理、气候模拟,金融等领域的数据分析,一方面是为了验证数据方面的有效性,另一方面是揭示可视化领域主要的研究内容和现在主要的研究趋势,故笔者采用了可视化领域最高级别的会议IEEE VIS(1990-2015)的数据做为数据集.2016年,Isenberg P[8]对可视化顶级会议IEEE VIS所发表的所有的文献进行了整理,剔除和修正了所有的文献信息.将可视化会议由三个会议科学可视化,信息可视化,可视分析、科学与技术(VAST)的发展进行了总结,并提供网站可以下载数据集.数据集来源于[9],总共有2803篇文献,剔除没有摘要的,总共2702篇.表1就是剔除后每年的文献情况.

表1 文献分年统计情况
2.1主题的提取
采用上面的方法,首先提取了一元和二元的单词,建立所有文献的tfidf矩阵,以及引用矩阵.根据tfidf矩阵中平均值最高的笔者采用了2000维的数据,按照余弦相似度公式(1)来计算文献间的相似度.对于引用矩阵,只考虑了引用IEEE VIS 中的论文情况,是个稀疏矩阵,使用了两个文献中引用相同文献的数量作为分子,而将引用矩阵中引用数量的最大值做为分母,再按公式(3)计算得到文献引用的相似度矩阵.最后使用谱聚类算法得到所有主题,并提取tfidf值最高的10个词做为类的标识.表2是所有主题的主要关键词.表中的主题是按平均强度来排名,自上而下,主题的强度不断减弱.根据文献和关键词为每个类提供了一个标签.

表2 文献集主题及对应的关键词
2.2主题的分析
从图1看到各个主题的变化趋势,可以看到主题1一直是最强的,由于可视化的应用领域的多样性和研究方法的多样性.主题4基因数据和社区网络数据的研究从2004年开始一直不断的增长,是第二个热门的研究主题.主题7时空数据的也在不断的增强,尤其是2013年以后,随着移动网络的快速发展,其数据量大,而且非常有应用价值,能及时发现一些规律,是第三个热门的主题.比较独特是主题2虚拟现实,90年代初期,是个研究的热点,但是慢慢的减弱,但从2011以后慢慢又热了起来,尤其现在随着硬件技术的发展,虚拟现实和混合现实越来越热.主题3表面建模自上世纪90年代初期,逐渐成为最热门的主题,但是自2005年后就其研究的热度不断的下降.
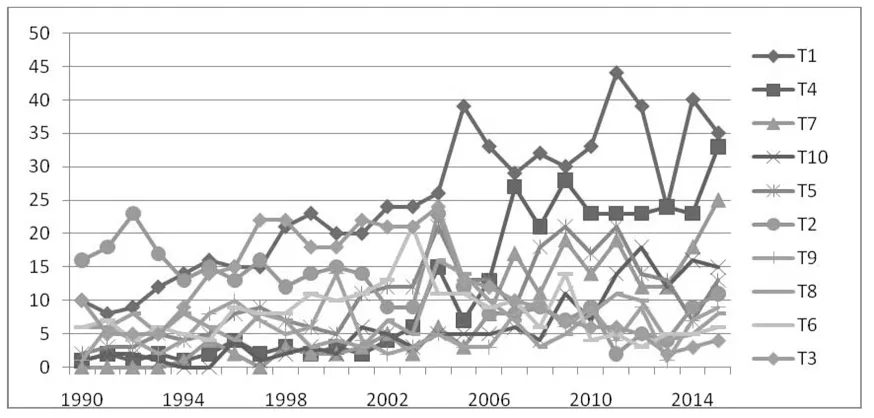
图1 主题的强度年度变化趋势图
3 结束语
该文将文献的内容相似度矩阵和引用相似度矩阵融合为一个矩阵,采用了谱聚类算法提取了可视化领域的最高级别的会议(IEEE VIST)1990~2015年的所有文献的主题,分析了主题的发展趋势,发现了比较热门的主题.实验证明对准确度有一定的提高,同时也为可视化领域的内容和发展的趋势进行了分析.
[1] Martyn J.BIBLIOGRAPHIC COUPLING[J].Journal of Documentation,1964,20(4):236-236.
[2] Garfield E.Use of citation data in writing the history of science[J].Isis,1965(Volume 56,Number 4).
[3] Small H.Co-citation in the scientific literature:A new measure of the relationship between two documents[J].Journal of the Association for Information Science and Technology,1973,24(4):265-269.
[4] Chen C M. Searching for intellectual turning points:progressive knowledge domain visualization[J] . Proceedings of the National Academy of Sciences of the United States of America( PNAS) ,2004( 1) :5303 - 5310.
[5] Chen C M. CiteSpace II:detecting and visualizing emerging trends and transient patterns in scientific literature [J] . Journal of the American Society for Information Science and Technology,2006,57( 3) :359 - 377.
[6] Blei D M,Ng A Y,Jordan M I.Latent dirichletallocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[7] Zha H,He X,Ding C,et al.Spectral relaxation for K-means clustering[C] International Conference on Neural Information Processing Systems:Natural and Synthetic.MIT Press,2001:1057-1064.
[8] Isenberg P,Heimerl F,Koch S,et al.Vispubdata.org:A Metadata Collection about IEEE Visualization (VIS) Publications[J].IEEE Transactions on Visualization & Computer Graphics,2016,PP(99):1-1.
Abstract:Traditional topic analysis in the field of science mainly uses citation analysis.With the development of natural language processing technology,content-based analysis technology has been widely used.They have their own advantages.This paper combines the references and contents of the literature,and merges the similarity of content and the similarity of reference to form a unified semantic space.Using spectral clustering,we detect a more accurate topic.Finally,the datasetsof the IEEE VIS top conference literature has been verified,showing a better effect.
Keywords:Topic detection; Citation analysis; Content analysis; IEEEVIS literature
(责任编辑:李家云)
TheTopicsDetectionBasedonContentandReferencesintheScienceField
Zhang Changhong,Zhang Mingliang
(Qinghai Nationalities University)
TP393
A
1000-5617(2017)02-0100-04
2017-01-14
