基于Word2vec和依存分析的事件识别研究
2017-09-23王红斌郜洪奎
王红斌+郜洪奎

引言
事件提出到现在一直受到学术界的关注,從而引起国家的重视。2009年,中国重点支持的科研项目之一是突发性灾难事件的研究。中国是大国,交通事故发生频繁;中国希望通过相关研究可以预防灾难和减少事故的发生。事故处理部门主要关心事故发生时间、地点、人员伤亡以及哪个路段、哪个时间容易发生事故,从而采取措施来最大限度的减少伤亡。对于事件的研究不仅具有理论研究价值,还具有实际的应用前景。
事件抽取已有部分研究,并已取得较好的研究成果。国内外对事件抽取研究大致分为两类:基于规则的方法和机器学习方法。基于规则的方法是事先制定一个字典,然后用待选词与字典进行匹配。国内外基于规则方法的相关研究如下:Alan D采用二元分类器和多元分类器方法来进行事件抽取研究,并且在ACE英文语料库进行了实验,取得较好的结果;对于中文事件的抽取研究,吴平博等人采用预先定义的模版来制定规则,从处理的文本中抽取事件信息来填充句型模板中的槽。张毅采用面向规约挖掘的事件相关性分析研究事件。熊宗炬和熊志斌针对特定领域突发事件的研究,并给出了原型系统。李超等人针对音频事件的研究。上述事件抽取都限定特定领域,缺乏普遍性。
结合上述国内外事件抽取发现,基于规则方法在一定范围内效果相当不错,但是它依赖具体环境,可移植性差,对于一些没有统计到字典的词,识别不出来。而且字典的制定费时费力,需要领域专家的指导。由于这些突出问题导致对事件抽取研究都转向了机器学习,机器学习方法可以解决当前这些面临的问题。国内外运用机器学习的相关研究例如:该方法采用以文档相关性的研究方法和跨越不同事件的推理演绎方法;杨尔弘根据中文特点,采用语句聚类的方法获得事件的信息结构(事件模板),并以此为标准进行抽取事件;赵妍妍等人结合Ahn等人的工作对机器学习需要的特征进行了改进;付剑锋等人采用依存分析进行深入的挖掘词与词间的句法关联性。但是机器学习方法需要大量的语料和众多的特征作为支持,现如今语料资源的缺乏和特征的选取也影响了机器学习的提高。而且这两种抽取方法均没有考虑词语问词性特征以及词语之间的依赖性和事件句之间的关联。
针对以上情况,本文提出了一种新的事件抽取方法充分考虑核心词和其他词语的特征、句间关系和词语间的依存性。采用本文提出的这种方法实验发现,在事件识别和事件要素提取均有明显提高。
1事件识别
事件这一概念被提出,且有较多含义,百度百科上定义为产生重大影响,并且对社会和人类产生深刻影响。事件,反映着自然界中的运动以及产生和变化的行为,是人类进行探索和发掘知识的基本单位。在自然语言处理和信息检索领域,检索的主题被称作事件。美国国防高级研究计划委员会上认为事件是比话题小的概念。事件是话题的子集,多个事件共同组成一个话题。事件表示为在“特定时间特定地点发生”。大会上指出话题的识别和跟踪包括五大步奏,其中最重要的就是事件识别。国际上定时召开的ACE评测会议极大促进了事件抽取的向前发展,大会认为事件通常是一种状态转向另一种状态,并把“事件”定义为含有参与者,时间,地点等特征的集合。综合以上不同领域对事件的研究发现,尽管事件这一概念在不同领域内定义不同。但是,事件的定义都包括行为(一般由动词、名词或动名词来描述)、事件的参与者、事件发生的地点和时间等要素。下面给出了事件的正式定义。
定义1事件(Event):特定时间特定地点发生、由参与者参与、表现出若干动作。
例如:
(1)2016年8月14日,在市中心,一辆公交车与多辆小轿车发生追尾,小轿车司机当场死亡,公交车司机受重伤。
定义2事件触发词(Event Denoter):文本中清晰的表示发生事情的词语,即事件的动作要素。文献表明事件触发词一般为动词,名词,动名词。
例如:
(2)北京时间2016年8月16日,澳大利亚发生了5.7级地震。
在事件识别和事件抽取两大任务中,关键任务还是事件识别,事件的识别在两大任务中起到决定性作用。例如:张三患上了高血压,瘫痪在床。
(1)小李在工作期间由于大意摔成瘫痪。
(2)强大的暴雪致使公路瘫痪。
(3)黑客攻击网络导致12306瘫痪。
上面三个例子,触发词都是瘫痪,但是只有句子1才符合要求,才是真正事件。因此,对于事件识别,不能孤立考虑句子,要结合依存分析把触发词以及距离触发词相近的词以及这些词的词性、位置信息、句子间的关联性、依存关系等作为事件识别的特征。
2 word2vec和依存关系
2.1word2vec
计算机只认识0和1。因此,进行自然语言处理,首先要将现实世界存在的文本或文档转化为计算机认识的语言。最直观的方法就是向量模型表示方法。也就是用0和1表示表示文本或文档,在某一位置存在的用1表示,其余用0。采用该方法可以把对文本的处理转化为向量空间上的运算。Word2vec是2013年谷歌推出的一款高效的将文本语言转化为向量的工具。Word2vec在自然语言处理中可以用于很多用途,例如同义词、聚类等。
本文主要借助word2vec进行扩展同义词,该工具具有训练速度快,可以在较短时间内训练出大量数据。实验前,需要对数据进行预处理等操作,然后在采用word2vec工具把数据转化为向量。采用word2vec进行数据处理的流程图如下图1所示:
在本文实验中,为了更好的进行数据训练,需要不断调整训练中参数变化。例如训练中具体的算法和相应的模型以及训练窗口的大小等因素。本文中采用的参数如下图2所示:
经过训练后得到词向量模型,然后就可以调用word2vec提供的方法进行相似度计算,得到同义词。本文的同义词扩展是根据ACE定义的8大类33小类事件出发,根据初始定义的种子触发词采用该方法进行扩展。最后,分别使用计算每个种子词相似度较高的词语,再对每个种子词的相似度得分列表进行加权平均,从而得到最终的相似度列表。采用word2vec进行挖掘查找同义词,对于查找和种子触发词的同义词可以进行加权,而对于只与其中某个种子词相关,与其他种子词相似度较低的词将得到相似度得分的打压和降权。endprint
2.2依存关系
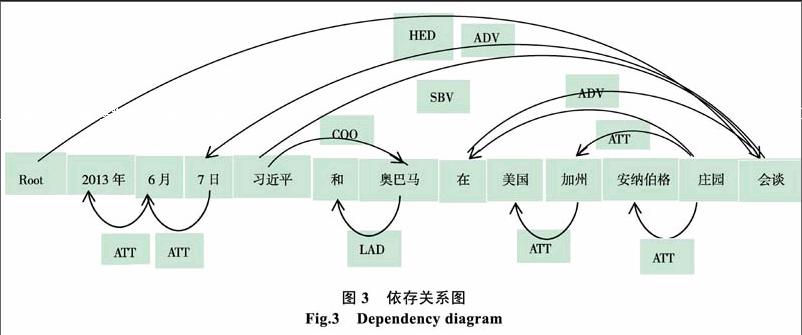
依存关系是进行句法分析的重要方法。采用依存分析发现句子中中心词和其余词语的关系,并且转化为语义依存来描述。当前领域内的主流方法是基于短语的句法分析。首次提出基于依存结构句法分析概念是在1984年,由Hudson在提出。依存分析概念提出后,就受到学者们一致好评和广泛的推广。依存关系主要包括两个部分:一个是核心词、另一个是依赖词。依存关系的基本原理是充分挖掘句子中词与词间的关系,转化为描述自然语言的语法结构。词语间有联系和相互支配,反映出词语间的不对等现象,这种相互间具有方向性的关系就被称为“依存关系”。依存关系中,定义箭头发出的是支配者,箭头指向的就是从属者。例如:2013年6月7日,习近平和奥巴马在美国加州安纳伯格庄园会谈,依存分析表示如下图3所示:
“2013年6月7日,习近平和奥巴马在美国加州安纳伯格庄园会谈。”上述事件句中,Root是全句核心节点。HED代表的是核心词,核心词是“会谈”;“会谈”也是本事件句的触发词。依存关系表示中,COO表示并列关系,LAD表示左附加关系,SBV表示主谓关系,ATT表示定中关系。词语间的依存关系是用带箭头的有向弧表示。在图中,箭头的发起端代表的词是依存词,箭头的指向端代表的詞是核心词。在“2013年6月7日,习近平和奥巴马在美国加州安纳伯格庄园会谈”事件句中,美国、加州、安纳伯格、庄园都是表示地点的事件要素。经过分析可知,只有庄园是真正的地点要素。首先采用word2vec转为向量,然后采用依存分析词语之间关系。依存分析表示地点词是按照核心词和依赖词顺序排列,真正的地点要素是后面的依赖词。本例中美国是加州的核心词、安纳伯格是庄园的核心词、加州是庄园的核心词。本文根据依存关系只要出现地点词最终地点要素均是依赖词。依存分析是依赖于分词之上的,因此分词的效率直接影响依存分析的结果。因此本文采用的分词工具是中科院的ICTCLAS,依存分析采用的是斯坦福大学Stanford。
3实验
3.1事件识别
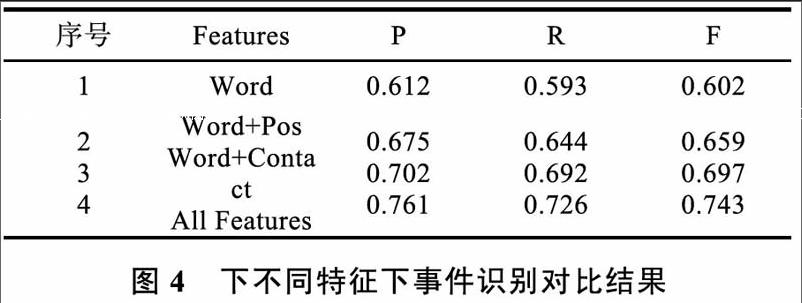
本实验先对数据进行预处理等操作,然后在此基础上运用word2vec工具进行词向量处理和依存分析相结合进行事件识别。实验所用语料是来自网络上搜集关于事件的报道,采用SVM和最大熵作为分类器。实验用的训练语料是80124篇、测试语料为812篇。采用准确率(P)、召回率(R)、F值作为评价指标。实验进行事件识别选用的特征有词、词和词法、词和句间关系。事件识别对比实验如下图4所示。
(1)以词(Word)为特征;
(2)以词和词法(Word+POS)作为特征;
(3)以词和句间联系(Word+ContacO作为特征;
(4)上述全部特征(AU Features)作为特征
从图4对比实验可知,选择句间关系和依存关系这些特征来识别事件效果要好于单独用词作为特征识别事件。事件识别中,特征选择越多,事件识别的效果越好。
4结束语
本文提出了一种结合word2vec和依存分析的事件识别和事件要素抽取方法。实验结果表明,该方法在事件识别中可以提高事件识别的准确率和召回率以及F值。但是对于事件要素对象上,存在一些问题。例如人称代词没有具体指出指代上下文的哪一个对象。因此,下一步是考虑如何解决事件要素中出现的人称指示代词。endprint
