基于Spark/GraphX图聚类算法的入室盗窃串并案研究
2017-09-23鲍世方
鲍 世 方
(上海公安学院 上海 200137)
基于Spark/GraphX图聚类算法的入室盗窃串并案研究
鲍 世 方
(上海公安学院 上海 200137)
随着我国城镇化进程的不断加速,广泛的人口流动使社会治安环境日趋复杂,犯罪分子系列性作案居高不下,给人民的生命财产安全构成极大的威胁。针对刑事犯罪活动中日益突出的系列入室盗窃案件,提出采用图聚类算法来进行串并案分析。首先利用Spark/GraphX分布式图计算框架,通过提取入室盗窃案的案件特征,计算两两案件之间的相似度,构建案件相似度矩阵;然后依据图论理论,采用图聚类算法实现串并案分析模型。实战工作表明该模型可为侦破案件提供有效的串并线索,极大地减少人工作业,提高了侦查工作的效率。
Spark GraphX 图聚类算法 入室盗窃 串并案
0 引 言
随着我国城镇化进程的不断加速,人口的流动造成社会治安环境日趋复杂,刑事案件发案率居高不下。其中“系列入室盗窃案的发案率一直居高不下且呈高发态势[1]”,其多发性、连续性、跨区域流窜性对人民的生命财产安全构成极大的威胁,对社会的稳定发展造成了严重的影响[2]。
犯罪分子的反侦查能力日益提高,犯罪分子作案时多戴手套、穿鞋套等以达到不留“痕迹”的目的,现场的指纹和脚印等具有标识性的犯罪线索很可能被破坏,留下的案件线索有限,对传统的经验型串并案分析[2]是极大的挑战。传统的经验型串并案分析根据单一的比较明确的特征属性进行数据碰撞搜索已不能满足现实的需要,更不能很好地对抗职业犯罪和高科技犯罪。因此如何快速有效地从杂乱无章的案件信息中发现“蛛丝马迹”,进而实现串案并案侦查成为案件侦破工作中的重中之重。
串并案[2]是系列刑事案件侦破工作中的重要方法,在案件之间相互补充、相互举证,特别是在个案侦查工作陷入困境时,更体现其有效性。但传统的经验串并案是依据侦查人员的经验,进行人工逐一排查,这种分析不但繁琐,而且效率低下,侦查人员的经验直接影响串并案结果的准确性。近年来一些专家利用数据挖掘技术进行串并案的研究,推进了数据挖掘技术在公安实战中的应用[3]。
图聚类算法[4-5]是建立在图论基础上的聚类算法[6-8],它根据分割函数,将图分割为K个(K≥2)子图,使得子图内部的关联更紧密,子图之间的关联更稀松。文献[7]提出一种基于Hash函数样本抽样的大规模数据聚类算法;文献[5,8]提出的属性图聚类算法是一种图聚类算法的特殊情况,是在图聚类算法的基础上考虑图节点和边的属性的相似性进行图分割,其中文献[5]在此基础上提出一种加权属性图聚类。如何快速有效地通过分割函数进行图分割是目前研究的热点和难点。
Spark[9]是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
GraphX[9]是一个分布式图处理框架,基于Spark平台提供对图计算和图挖掘简洁易用的而丰富多彩的接口,是一个分布式的图处理系统。
本文通过分析往年入室盗窃案件数据,提取案发时间、案发地理坐标、侵入方式、作案手段、案情关键词等犯罪行为特征数据,利用Spark/GraphX分布式图计算框架,计算两两案件之间的相似度;依据图论理论,将案件看成图(G)中的顶点(V),将案件之间的相似度看成图(G)中的边(E),这样就得到了一个基于案件相似度的图;采用图聚类算法实现串并案分析模型,给侦破案件提供更多线索和依据,提高侦查工作的效率,节省大量的人工串并案成本。
1 案件特征数据提取
本文研究的案件为入室盗窃案件,案件特征数据主要是案发时间、案发位置、侵入方式、侵入部位、作案手段、案情关键词。其中侵入方式、侵入部位、作案手段和案情关键词都反应了犯罪嫌疑人的作案习惯,对串并案尤为重要。但这些数据都存储在案情描述里面,本文研究通过文本分析实现案件特征数据的提取。
本文对案件特征数据提取采用Spark特征提取方法(利用Spark MLlib中的mllib.feature包),将每个案件信息转换为用向量表示的特征数值。特征(feature)是用于模型训练的变量,比较常用的有以下几种:
(1) 数值特征
这些特征通常为实数或整数,比如案发位置坐标。
(2) 类别特征
取值只能是可能集合中的某一种,借助k之1方法将其表示为长度为k的二元向量。比如案发时间、侵入方式、侵入部位、作案手段。k之1(1-of-k)方法是一种用于机器学习任务的特征变量表示方法。假设变量可取值有k个,如果对这些值用1到k进行编序,则可以用长度为k的二元向量来表示一个变量的取值,这个向量里,该取值对应的序号所在的元素为1,其他元素都为0。
(3) 文本特征
数据中的文本内容,将文本内容分词,提取词干,并用二元向量表示为稀疏矩阵的一种派生特征。比如案情关键词。
1.1 提取案发时间
由于入室盗窃案件的特殊性,受害人报案时只能提供案发时间段,比如:2015年2月15日10点到2015年2月15日19点。我们从以下三个维度提取案件时间特征:
(1) 按日期提取
将时间段标记为:[起始日期时间,截止日期时间]。本例中为[2015-02-15 10:00:00, 2015-02-15 19:00:00],后期计算相似度是如果两个时间段有交集标记为1,否则标记为0。
(2) 按星期提取
根据案发日期时间段获取起始日期和结束日期,根据日期函数获取日期对应的星期,从而获取案发日期时间段的星期范围。经过计算得知2015年2月15日为星期三,所以案发时间段的星期范围为星期三;如果起始日期和结束日期不一致,星期范围依次类推。为了便于计算我们将计算出的星期范围用向量标记,比如:星期三记为:[0,0,1,0,0,0,0],将星期三、星期五记为:[0,0,1,0,1,0,0]。
(3) 按时段提取
根据案发日期时间段提取案发的时间段。本例中为[10,19],如果起始时间点大于截止时间点,比如将[19,1]标记为[19,24][0,1]。为了更准确度提取时段的特征信息,我们将时间段划分为凌晨(0-3)、黎明(3-6)、早上(6-9)、上午(9-12)、中午(12-14)、下午(14-17)、傍晚(17-20)、深夜(20-24)。例如:将[0,24]标记为[1,1,1,1,1,1,1,1],将[10,19]标记为[0,0,0,1,1,1,1,0],将[19,1]标记为[1,0,0,0,0,0,1,1]。
1.2 提取案发地理坐标
根据报案时提供的案发地点的地址信息,通过地理坐标转换工具,将文字描述的地址信息,转换为地理坐标[10]。本文以百度地图为例,具体实现步骤如下:
(1) 获取百度地图授权[11]。
(2) 将案件信息分批次标记,建立唯一键,便于分布式操作。
(3) 调用百度地图API[11],根据地址信息获取地理坐标信息。
(4) 如果获取到地理坐标信息,将地址信息和坐标信息关联;如果未获取到地里坐标信息,将地址信息最后一位截取掉,重新执行步骤3、步骤4。重复执行6次,如果还未关联到坐标信息,跳出循环。
(5) 最终获取案件案发位置坐标,形如:[121.232 3,31.322]。
1.3 提取侵入方式
入室盗窃案件由于其特殊性,往往在案发后才发现,无法准确的获取。本文研究通过分析案情描述将侵入方式可归纳为:从门侵入、从窗侵入、攀爬侵入、其他侵入,记为[1,1,1,1]。根据各个案件情况,按提取的侵入方式将其标记为[1,0,0,0]、[0,1,0,0]、[0,0,1,0]、[0,0,0,1]。
1.4 提取侵入部位
根据房屋的结构将案件侵入部位归纳为:门、阳台、厨房、卧室、卫生间、地下室、天井、天台,记为:[1,1,1,1,1,1,1,1]。根据各个案件情况,按提取的侵入部位将其标记为:
[1,0,0,0,0,0,0,0]、[0,1,0,0,0,0,0,0]、[0,0,1,0,0,0,0,0]、[0,0,0,1,0,0,0,0]、[0,0,0,0,1,0,0,0]、 [0,0,0,0,0,1,0,0]、[0,0,0,0,0,0,1,0] 、 [0,0,0,0,0,0,0,1]
1.5 提取作案手段
作案手段反应嫌疑人的个人技能和作案习惯,特别是惯犯,即使有意隐藏,也难免留下独特的作案痕迹。根据作案选择的工具和个人技能,将作案手段归纳为:技术开锁、撬锁、倒插片、溜门、撬门、门挖洞、钓鱼、攀爬、撬窗、破坏窗栅、破坏窗网、砸窗玻璃,记为:[1,1,1,1,1,1,1,1,1,1,1,1]。根据各个案件情况,按提取的作案手段将其标记为:
[1,0,0,0,0,0,0,0,0,0,0,0]、[0,1,0,0,0,0,0,0,0,0,0,0]、[0,0,1,0,0,0,0,0,0,0,0,0]、[0,0,0,1,0,0,0,0,0,0,0,0]、[0,0,0,0,1,0,0,0,0,0,0,0]、[0,0,0,0,0,1,0,0,0,0,0,0]、[0,0,0,0,0,0,1,0,0,0,0,0]、[0,0,0,0,0,0,0,1,0,0,0,0]、[0,0,0,0,0,0,0,0,1,0,0,0]、[0,0,0,0,0,0,0,0,0,1,0,0]、[0,0,0,0,0,0,0,0,0,0,1,0]、[0,0,0,0,0,0,0,0,0,0,0,1]。
1.6 提取案情关键词
通过分析案情描述信息来提取关键词特征数据,本文通过汉语分词系统NLPIR/ICTCLAS[12]开放的词频统计接口,统计案情描述的词频,形成案情关键词组。比如对以下案情描述进行词频统计,提取关键词,见表1所示。

表1 入室盗窃案情关键词提取
2 图聚类算法
图论是一个数学学科,研究一组实体(称为顶点)之间两两关系(称为边)的特点。GraphX是基于Spark进行并行图计算的程序库。本文基于图论将每个案件看作图的顶点,案件之间的相似度看作图的边而构成无向图,利用GraphX对图分布式操作功能,对案件及其相似度构成的无向图进行图分割,使分割后的子图内部联系更密切,子图之间联系更稀松,以达到案件串并的目的。
2.1 入室盗窃案件空间特征向量的构建
案件特征提取的目的是将案件数据表示为多维空间特征向量,每行表示一起入室盗窃案件的空间向量,每一列表示入室盗窃案件的一个特征向量,见表2所示。
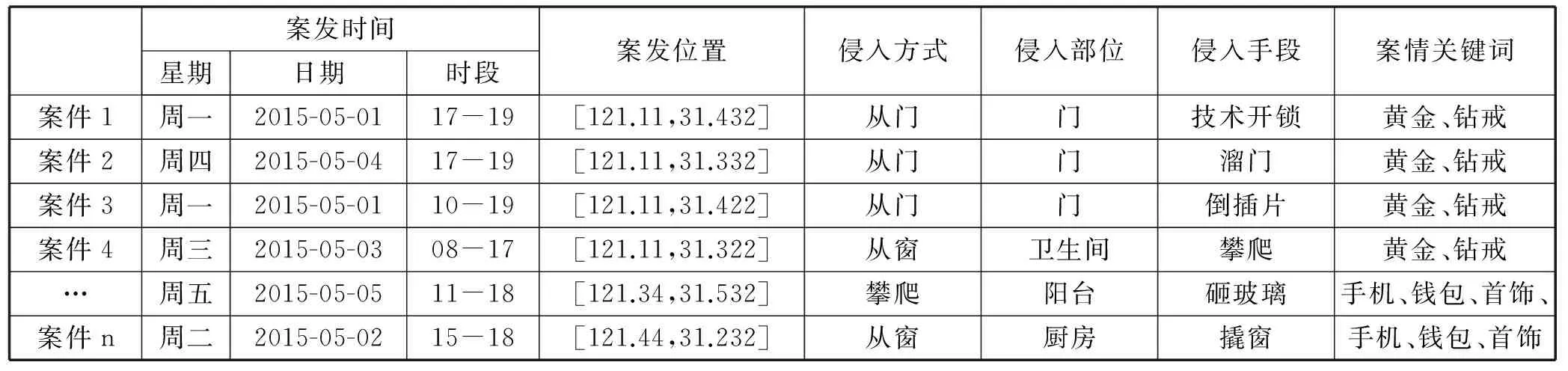
表2 入室盗窃案件特征多维空间特征向量表示
根据特征提取规则将案件特征值转换为空间特征向量,见表3所示。
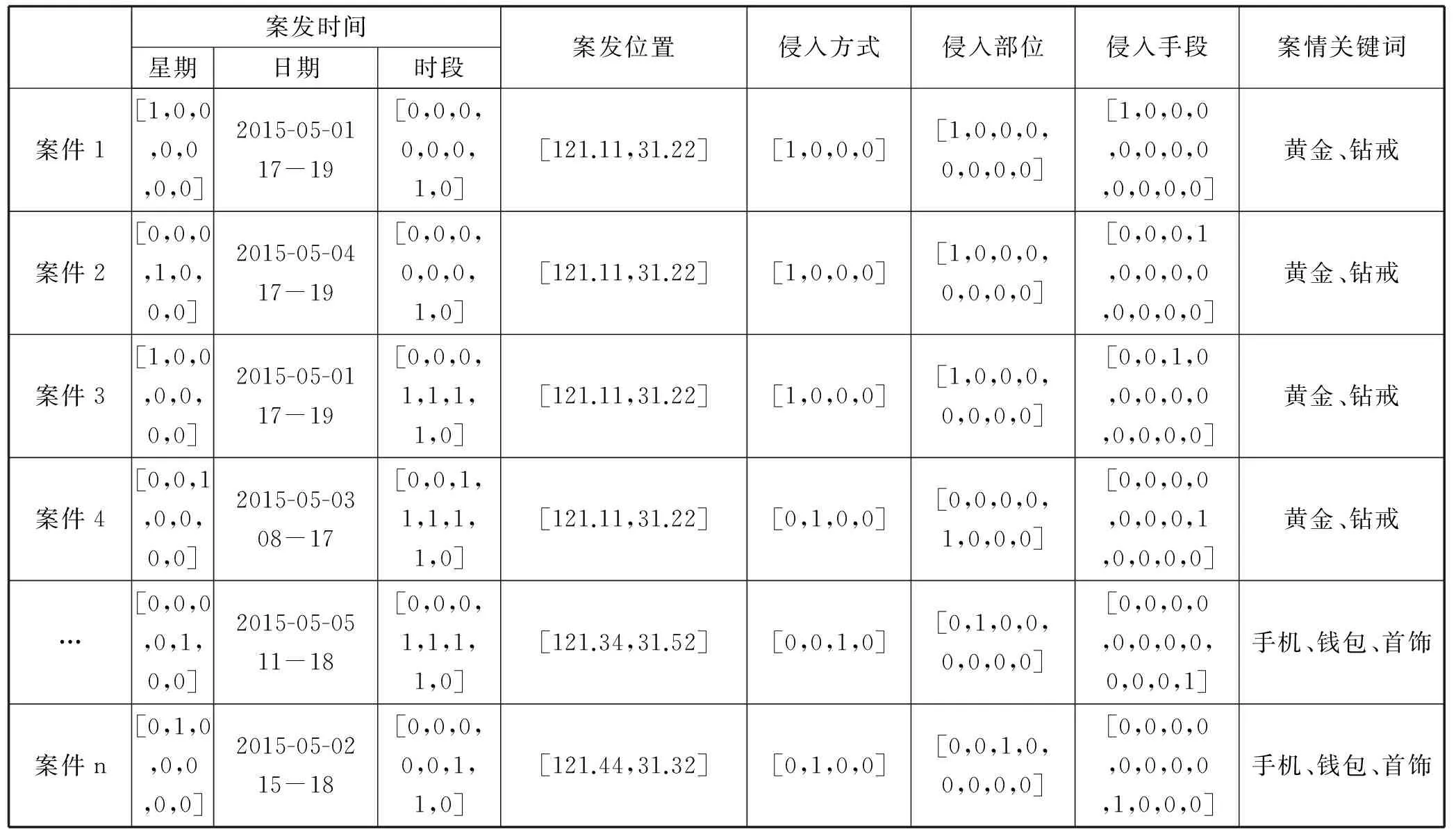
表3 入室盗窃案件特征值空间特征向量表示
2.2 设定相似度加权计算模型
入室盗窃案件按不同特征的组合计算案件集合的相似度与案件特征数量为非线性相关,其相似度不一定随案件特征数量的增多而提高。为了进一步提高案件相似度的精度,通过加入经验值设定案件特征的权值进行加权计算来提高案件的相似度精度。
2.3 构建案件相似度矩阵
依据案件空间特征向量和案件特征的权值构建案件的相似度矩阵。设定案件a1和a2;案件的特征表示为f11-f18和f21-f28;案件特征的权值为q1-q8;案件a1和a2的特征相似度为fx1-fx8;则a1和a2的相似度为:
x12=∑ifxi×qii=1,2,…,8
其中:
fx3=f13和f23中相等的个数/f13的长度
fx8=f18和f28中相等的个数/f18的长度
依据上面的公式构建案件的相似度矩阵,矩阵是n乘n的下三角矩阵,n代表案件的数量,具体的数值代表案件与案件之间的相似度。
2.4 构造案件关系图
根据案件的相似度矩阵利用Spark的MLlib工具包GraphX建立案件的无向图[5],见图1所示。
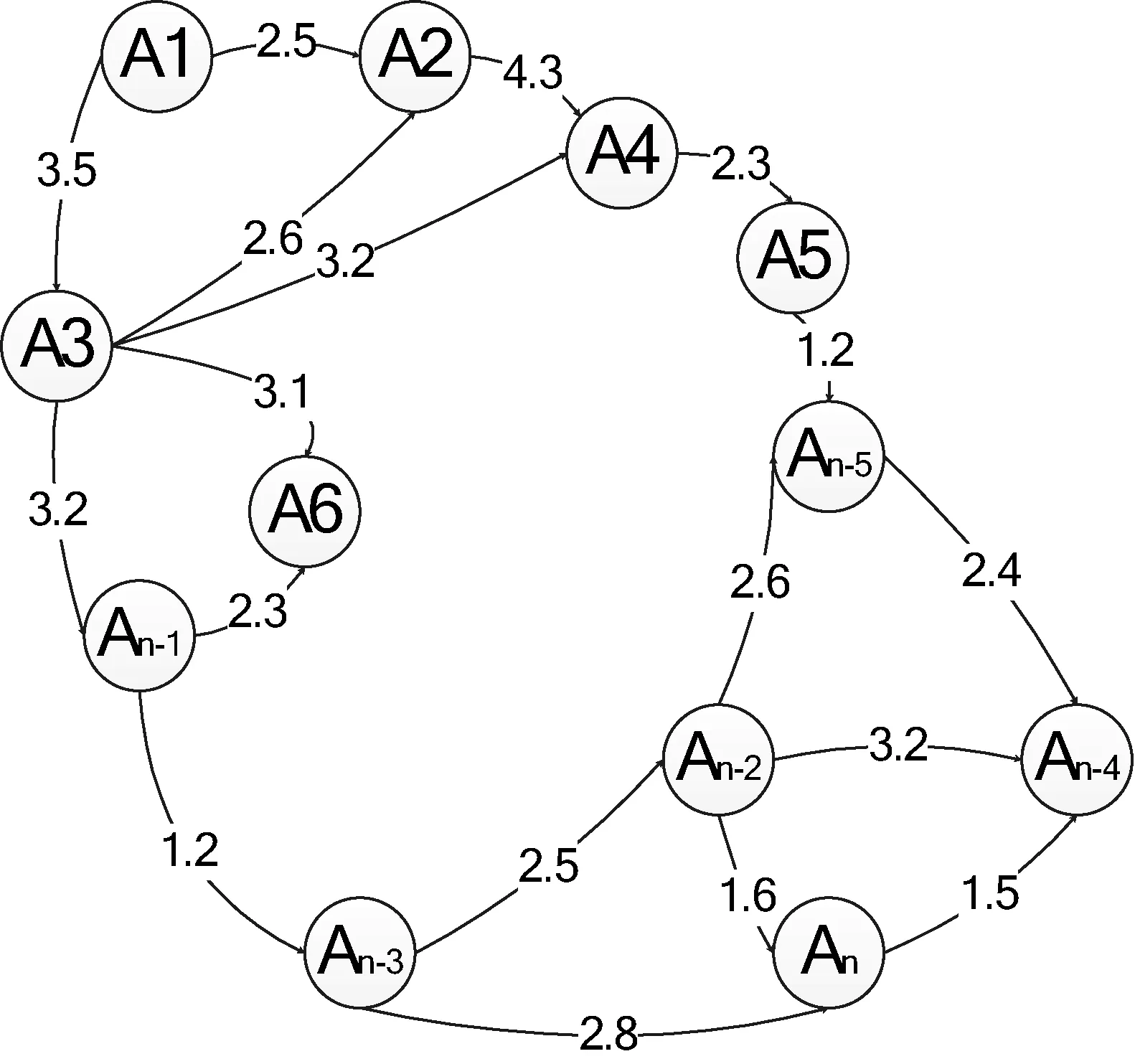
图1 案件的无向图
2.5 图分割算法
图聚类算法就是依据图的顶点间的相似度实现聚类算法,其思想就是使用图论的知识,将样本数据构建成的图进行分割操作。图分割的主要目的是使同组之间的权重最高[13],而不同组别之间的权重尽可能的低的过程。权重越高,表示相似度越大,案件串并的可能性就越大,权重太低,表示相似度越小,案件串并的可能性就越小,放弃案件之间的串并[14]。假如将一个图G划分为A,B两个子图,其中|A|,|B|分别表示子图 A,B中顶点的个数。图分割算法[15-17]主要由以下几种:
(1) 最小分割算法
Cut(A,B)=∑u∈A,v∈Bw(u,v)
(1)
对于规范的数据,利用最小分割算法进行分割的效果会比较好,而对于非规范的数据,利用最小分割算法会出现偏向最小分割的结果。
(2) 最小比率分割算法
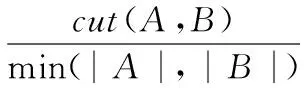
(2)
最小比率分割算法只考虑到如何使A,B两个子图间的相似性最小,这样可以减少分割的次数。
(3) 最小规范化分割算法
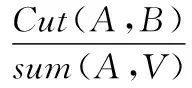
(3)
将A,B两个子图的相似程度表示为Cut(A,B),将A图中所有点的权值之和表示为sumA,最小规范化分割算法不仅对规范化数据实用,对于非规范的数据也比较实用。
(4) 最小最大分割算法
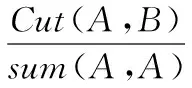
(4)
最小最大分割算法即要求最小化A、B之间的相似性,同时最大化sum(A,A)与sum(B,B),这样即减少分割次数,又保证分割效果。
3 实验结果及分析
3.1 实验数据集
实验数据集来自某市公安部门2015年案件信息和串并破案记录,经特征提取后进行的实验。
3.2 实验环境
本文选取的硬件环境为通过虚拟技术虚拟出多台配置相同的硬件。2 GB运行内存,操作系统为CentOS7,Spark版本为2.2.0,Hadoop版本为2.8.0,编程语言Scala版本为2.12.2,JDK版本为1.8。
3.3 实验评价标准指标
影响案件串并模型的优劣,一是案件特征的提取速度和案件相似度计算速度。二是串并案的准确性。其中串并案的准确性尤为重要,但是案件特征的提取速度和案件相似度计算速度也应在可控范围内,否则无论串并案的准确性再高也失去了实战的意义。
3.4 串并案模型验证
本文主要基于Spark分布式计算框架,来验证不同切割函数的优劣。非分布式的方法不在进行实验验证,因为随着数据量的增加,从理论上分析非分布式的方法的速度会越来越慢,直至不可控。而Spark分布式计算框架是基于内存计算,减少大量的I/O操作,通过提高机器性能,可以将案件特征的提取速度和案件相似度计算速度控制在合理范围内,为实战应用打下坚实的基础;通过完善分割函数,串并案模型的准确性也会得到改善,表4为各种分割函数的效果对比,准确率以实际串并破案为依据。
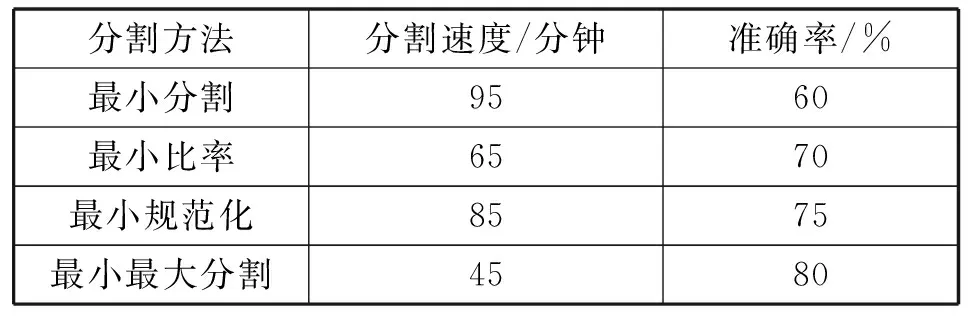
表4 入室盗窃案件串并准确率对比
由表4可知,基于Spark/GraphX分布式图计算框架下,利用最小最大分割函数进行图分割,无论从速度还是准确率上对比,效果都最为明显。实验发现,根据最小最大分割比率,通过适当减少案件之间的相似度比较的维度,速度和准确率会有明显提高,这对于实战也是非常有用的。
4 结 语
本文基于Spark分布式计算框架和图聚类算法架构了用于侦破系列案件的串并案分析模型。从当前已发生个别案件开始,在公安海量数据中进行串并分析,根据图聚类的结果,刻画出犯罪团伙;在公安实战工作中能够对系列入室盗窃案件的侦破提供有效地支撑。在聚类过程中,特征值的选取当前主要依据警务专家的经验值,在相关特征的提取方面也存在一定的难度,尚需要人工的参与。因此对于串并案自动分析模型的研究还面临着一些挑战,如何实现案件之间相似度的自动计算将是下一步研究的方向。
[1] 刘东进,郑旭强.利用刑事技术侦破入室盗窃系列案的几点体会[J].广东公安科技,2016,24(4):55-56.
[2] 韩宁,陈巍.基于聚类分析的串并案研究[J].中国人民公安大学学报(自然科学版),2012,18(1):53-58.
[3] 张超,张金波,伍坤.基于数据挖掘聚类方法识别串并多发性侵财案件平台的设计与实现[J].警察技术,2017(2):34-36.
[4] 陈德华,解维,李悦.面向大规模图数据的分布式并行聚类算法研究[J].计算机研究与发展,2012(49):222-227.
[5] 张素智,张琳,曲旭凯.基于最短路径的加权属性图聚类算法研究[J].计算机应用与软件,2016,33(11):212-214,281.
[6] 石铠,任泺锟,彭一鸣,等.基于多节点社团意识系统的属性图聚类算法[J].计算机科学,2017,44(S1):433-437.
[7] 郭占元,林涛.面向大规模数据快速聚类K-means算法的研究[J].计算机应用与软件,2017,34(5):43-47,53.
[8] 边宅安,李慧嘉,陈俊华,等.多智能体系构架下的属性图分布式聚类算法[J].计算机科学,2017,44(S1):407-413.
[9] 百度.Spark[EB/OL].http://baike.baidu.com/item/spark/.
[10] 王增利,刘学军,陆娟.入室盗窃多尺度地理因子分析[J].地理学报,2017,72(2):329-340.
[11] 百度.百度地图服务[EB/OL].http://lbsyun.baidu.com/.
[12] 张华平.NLP汉语分词系统[EB/OL].http://ictclas.nlpir.org.
[13] 刘晓平,吴敏,金灿.采用图分解的特征识别算法研究[J].图学学报,2010,31(1):67-71.
[14] 王会青,陈俊杰.基于图划分的谱聚类方法的研究[J].计算机工程与设计,2011,32(1):289-292.
[15] Ulrike von Luxburg.A Tutorial on Spectral Clustering[EB/OL].http://www.kyb.mpg.de.
[16] Bach F R,Jordan M I.Learning Spectral Clustering[J].Advances in Neural Information Processing Systems,2003,16(2):2006.
[17] Aarti Singh.Spectral Clustering[EB/OL].https://www.cs.cmu.edu.
RESEARCHOFBUNCHINGANDMERGINGBURGLARYCASEBASEDONSPARK/GRAPHXGRAPHCLUSTERINGALGORITHM
Bao Shifang
(ShanghaiPoliceCollege,Shanghai200137,China)
With the acceleration of the urbanization process in our country, the extensive population flow makes the public security environment become more and more complex, and the serial crimes of criminals are still high, which poses a great threat to the people’s lives and property safety. In this paper, in view of the increasingly prominent series of burglaries in criminal activities, a graph clustering algorithm is proposed to perform the parallel case analysis. First of all, we used the Spark/GraphX distributed computing framework to extract the case characteristics of burglaries, calculated the similarity between cases, and built the case similarity matrix. Then, according to the graph theory, the graph clustering algorithm was used to implement the parallel case analysis model. The actual combat work shows that the model can provide effective string and clue for detecting cases, greatly reduce manual operation and improve the efficiency of the investigation.
Spark GraphX Graph clustering algorithm Burglary Bunching and merging case
TP3
A
10.3969/j.issn.1000-386x.2017.09.022
2017-07-26。鲍世方,讲师,主研领域:公安信息系统研发,公安数据分析,公安信息化教学。
