基于词句协同排序的单文档自动摘要算法
2017-09-22蒲朝仪伍之昂
张 璐,曹 杰,蒲朝仪,伍之昂
(南京财经大学 江苏省电子商务重点实验室,南京 210023) (*通信作者电子邮箱luzhang@njue.edu.cn)
基于词句协同排序的单文档自动摘要算法
张 璐*,曹 杰,蒲朝仪,伍之昂
(南京财经大学 江苏省电子商务重点实验室,南京 210023) (*通信作者电子邮箱luzhang@njue.edu.cn)
对于节录式自动摘要需要从文档中提取一定数量的重要句子,以生成涵盖原文主旨的短文的问题,提出一种基于词句协同排序的单文档自动摘要算法,将词句关系融入以图排序为基础的句子权重计算过程中。首先给出了算法中词句协同计算的框架;然后转化为简洁的矩阵表示形式,并从理论上证明了收敛性;最后进一步通过去冗余方法提高自动摘要的质量。真实数据集上的实验表明,基于词句协同排序的自动摘要算法较经典的TextRank算法在Rouge指标上提升13%~30%,能够有效提高摘要的生成质量。
自动摘要;节录式摘要;单文档;图排序;词句协同
0 引言
随着Web2.0的迅猛发展,各种用户原创内容爆炸式增长,造成了互联网上严重的信息过载,使得有价值信息的获取愈发困难。自动摘要技术能够从海量文本中抽取出最为重要的语句,形成高度概括原文主旨的精炼短文,能够有效地缓解信息过载。
总体而言,自动摘要分为基于抽象的自动摘要和基于抽取的自动摘要[1]。基于抽象的自动摘要受制于自然语言处理的瓶颈,实现相对困难。目前主要的研究和应用集中在基于抽取的自动摘要,又称节录式摘要,计算文档中句子的权重并进行排序,从中抽取高权重语句生成摘要[2]。现有工作中对句子权重的计算主要分为两种思路:通过词的权重推测句子的权重[3-4]或通过句子特征计算权重[5-6]。事实上,文档中的词与句是不可分割的整体,充分考虑词句之间的协同关系有助于进一步提高自动摘要的质量。本文面向单文档自动摘要,将文档建模为以句子为顶点、句子间的关联为边的句网络图,以图排序算法为基础,重新设计迭代过程,在计算句子权重时融入词对句子权重评分的影响,提出一种词句协同排序(Word-Sentence-Rank,WSRank)的自动摘要算法。实验表明,词的融入有助于进一步提高句子权重计算的准确性,提升摘要的质量。
1 相关工作
自动摘要作为自然语言处理与信息检索领域重要的研究议题,一直广受关注。根据是否需要对原文语义进行理解,自动摘要可分为基于抽象的自动摘要和基于抽取的自动摘要[1]。基于抽象的自动摘要需识别文本的主要内容,然后利用自然语言处理技术重新组织或添加新内容以生成摘要,受制于自然语言生成技术的局限性,目前相关的研究与应用都有限。实用的自动摘要技术主要基于语句抽取的方式,即通过计算文档中句子的重要程度,从中选择重要语句生成摘要,又称节录式摘要[2]。根据所处理的文档数量不同,自动摘要又分为单文档摘要和多文档摘要,单文档摘要从单篇文档中提取涵盖原文主旨的概括性内容[6-7];多文档摘要则将多篇探讨相关主题的文档融合在一起,从中提取主题相关的内容[8-9],并可通过摘要更新关注其演化信息[10-11]。
本文的研究主要面向单文档节录式自动摘要,其核心议题是文档中句子的权重评分。早期的评分手段主要利用句子及其中单词的语义特征或统计性特征,通过构建评价函数计算句子的权重。基于单词的特征主要包括词频、TF-IDF(Term Frequency-Inverse Document Frequency)、大小写、共现信息(N-Gram)等[3-4,12-14];基于句子的特征包括是否包含总结性词汇[5]、是否包含数字[12]、在文章或段落中的位置[15]、句子长度[16-17]等。这类方法简单直观,不依赖于外部语料库和训练集,但由于需要人工拟合评价函数,主观性较强,计算参数只能根据经验设定,因此最终的摘要效果一般。
另一种句子评分方法基于机器学习,试图通过训练样本的学习构建分类器,从而直接判定一个句子是否应被选为摘要句[18]。如Kupiec等[19]选用词频、大小写、句子位置、长度、是否包含总结性词汇等5种特征,构建朴素贝叶斯分类器提取科技文献的摘要;Conroy等[20]提出基于隐马尔可夫模型的自动摘要方法,相比朴素贝叶斯分类具有更少的独立性假设要求。这类方法在针对特定体裁文本,特别是科技文献时的效果很好,但在一些其他类型的文本,如新闻摘要方面则无明显的优势[21],其原因在于摘要的质量受制于训练样本和领域知识,因此通用性较差。
句子评分的第三类方法基于图排序思想,这类方法将句子建模为图的顶点,利用句子相似性或共现关系建立节点之间的边,在此基础上应用PageRank[22]、HITS(Hyperlink-Induced Topic Search)[23]等图排序算法迭代计算顶点权重,收敛后的权重即为相应句子的评分。最为典型的图排序自动摘要算法是TextRank[6],其由PageRank演化而来,在其后续加强版本中进一步融入了语法和语义特征对句子得分进行线性加权[7],本文将以这两种方法作为比较对象,验证WSRank算法的效果。其他以图排序为基础自动摘要算法还包括基于亲和图的方法[24]、基于N-Gram图的方法[25]、基于概念图的方法[26]等。
基于图排序的自动摘要方法无需训练样本,不受语言和应用领域的限制,并且计算速度快,可扩展性强,得到了越来越多的应用。已有方法大多以句子为粒度进行计算,即主要考虑句子层面的关系,但在基于单词特征生成自动摘要的研究工作中[3-4,12-14],揭示出了词对句子评分的重要影响,这种影响不应忽略。虽然部分研究工作尝试以单词为顶点运行图排序算法[27-28],但单词权重与句子权重之间的相互增强关系并未得到清晰的表述,本文将针对这一问题展开研究,通过建立词句间的协同增强模型,将词的权重融入句子权重的计算过程中,从而生成更加准确的自动摘要。
2 词句协同的自动摘要算法
本文将词与句的关系融入到句子权重评分中,提出一种词句协同排序的节录式单文档自动摘要算法。其背后隐含的基本思想是:当一个句子包含越多的重要单词(如关键词)时,该句子的重要程度越高;相应地,若一个单词在重要语句中出现的频率越高,则该单词的重要性也越高。
在进行算法描述之前,本文首先给出若干变量的符号定义,并对节录式自动摘要问题进行形式化描述。假设文档T中的句子集合为S并且|S|=m,词的集合为W并且|W|=n,节录式自动摘要的目标是计算得到一个m维向量X=[X1,X2,…,Xm]T,其中Xi表示第i个句子的权重得分,从中提取得分最高的Top-K个句子,将其按原文中的顺序组合生成摘要。在自动摘要研究领域,K的值可根据多种约束条件定义,如摘要中包含的句子数量、摘要的最大单词数/字数、摘要词数/字数在原文中所占的比例等。利用词袋模型(bag-of-words),文档T可被描述为一个m×n的矩阵P=[pij](1≤i≤m,1≤j≤n),其中pij表示第j个单词在第i个句子中的词频。为计算句子权重,首先构建一个无向加权图G,称为句网络图,以便运行类似PageRank的图排序算法。虽然PageRank算法主要应用于有向图中,但已有相关研究表明,对于非正则无向图,PageRank同样能够得到有效的排序结果[29],因此在文本摘要中,需要构建非正则的句网络图,本文以文档中的句子为顶点,句子间的相似关系为边,建立句网络图,由于文档中一般包含很多彼此间相似度为0的句子,这些句子间不存在边,由此导致顶点的度数不可能相等,因此所构建的句网络图为非正则图。假设其邻接矩阵为A=[aij](1≤i,j≤m),其中aij为边(i,j)的权重,由第i个句子与第j个句子间的相似度定义。本文采用雅可比相似度计算边的权重,即:
(1)
其中:Si表示第i个句子,Wi表示句子Si中词的集合。
2.1 计算过程
WSRank算法采用迭代的方式计算句子权重,由于词的引入,需对基本的图排序算法进行扩充,使其能够在词与句之间进行重要度的传播。首先,在句网络图G上运行类似PageRank的图排序算法,计算句子的初始权重:

(2)
其中,d∈[0,1]表示阻尼系数,用以处理图中度为0的悬挂顶点[22]。在初始化时Xi可取任意非负值,后续迭代中则由上一轮迭代给出。
得到句子权重后,可根据句子计算单词权重,进行句-词增强,假设Yj(1≤j≤n)表示W中第j个单词的重要度,其计算方法如式(3)所示:

(3)
在获得所有单词的权重后,可根据单词重新计算句子权重,进行词-句增强,计算方法如式(4)所示:
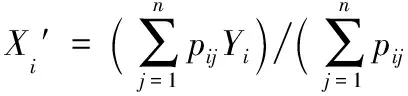
(4)
最后,将式(2)~(4)获得的句子权重进行线性组合,获得该轮迭代的句子权重,并作为下一轮迭代的初值,计算方法如式(5)所示:
(5)
其中α为调节因子。当某一轮迭代之后,所有句子权重与该轮迭代前的差值均小于预设阈值ε时,则达到收敛状态,停止迭代。此时,可以得到m维句子评分向量X=[X1,X2,…,Xm]T,其中Xi表示第i个句子的权重得分,从中提取得分最高的Top-K个句子,将其按原文中的顺序组合便可自动生成摘要。
类似于任意随机行走模型,以上计算过程也可转换为矩阵运算形式。假设Xt表示第t轮迭代得到的句评分向量,根据PageRank算法,式(2)可重新表示为:
X=AXt-1
(6)

Yt-1=QTXt-1
(7)
由此,词-句增强过程即式(4)可转换为:
Xt-1′=QYt-1
(8)
结合式(6)~(8),线性组合过程即式(5)可重新表示为:
Xt=αAXt-1+(1-α)Xt-1=αAXt-1+(1-α)QQTXt-1= [αA+(1-α)QQT]Xt-1
(9)
矩阵表达方式给出了WSRank算法更加简洁的迭代过程,即首先使用随机值初始化向量X0,然后根据式(9)迭代更新Xt直至收敛。
2.2 自动摘要算法
在实际的文档中,围绕同一主题一般存在多个语句,并且这些句子往往会包含若干相同的关键词,导致这些语句在评分上通常较为接近。如果某个句子得到较高的权重评分,与其相似的语句同样会得到高分,如果自动摘要算法简单地从排序后的句子中提取的Top-K个语句,则会出现若干语句重复表达同一主旨的情况,并且丢失一些评分次高但包含其他重要信息的句子,因此,本文在基本的WSRank算法上增加了一个冗余去除的过程,在提取摘要句时加入相似性判断,从而剔除同义语句,保证摘要能够更准确全面地表达原文的主旨。假设AS表示当前已提取到的摘要句集合,Si为剩余句子中权重评分最高的句子,去冗余过程考察Si与AS中最相似的语句的相似度,即:
(10)
通过设置阈值θ,仅当Sim(Si,AS)≤θ时,将Si选为摘要句,否则继续考察评分低于Si的语句。本文将加入冗余去除的自动摘要算法命名为WSRank*,其伪代码算法1所示。
算法1 WSRank*算法。
输入:A表示句网络图邻接矩阵;Q表示词句关系矩阵;d、α、ε、θ、K为算法参数。 输出:AS表示摘要句集合,初始化为∅。
1)
Randomly initialize vectorXt,t←0;
2)
while ‖Xt-Xt-1‖2≥εdo
3)
t←t+1;
4)
UpdateXtaccording to 式(9);
5)
end while
6)
while|AS|≤Kdo
7)
SelectthesentenceSiwiththehighestscoreinSaccordingtoXt;
8)
ifSim(Si,AS)≤θthen
9)
AS←AS∪Si;
10)
endif
11)
S←S-Si;
12)
end while
值得注意的是,如果将算法第8)行中的判断条件去除,WSRank*将蜕变为WSRank。算法共包含5个参数,其中K为摘要句数量,由摘要长度约束;阻尼系数d按照PageRank算法的建议,一般取值0.85;相似性阈值θ取0.8;其余参数将在实验部分讨论。
算法的主要计算量集中在第4)行的X向量更新过程,根据式(9),QQT在每次迭代中仅执行1次,其中包含乘法操作mn次,因此,如果不进行冗余去除,WSRank算法的计算复杂度为O(Imn),I为迭代次数,由3.4节的实验可知,I的取值一般不会超过15。对于WSRank*算法而言,由于约束条件K的存在,冗余判断的计算量最多为K2次,因此其计算复杂度为O(Imn+K2)。
2.3 收敛性证明
WSRank*与WSRank的差异主要在摘要句选取阶段,这部分不存在收敛性问题,算法的收敛性主要取决于算法1第4)行的权重评分计算过程。根据随机行走模型,要证明WSRank算法的收敛性,只需证明向量X和Y存在唯一的平稳概率分布。令Ωm={X∈Rm|∀Xi≥0,1≤i≤m},Ωn={Y∈Rn|∀Yi≥0,1≤i≤n},并且Ω={[X,Y]∈Rm+n|X∈Ωm,Y∈Ωn},可以看出,Ωn,Ωn及Ω均为等比凸集。由计算过程可知,Xt-1受Yt-1影响,不失一般性,本文分别将式(9)和(7)简写为Xt=f1(Xt-1,Yt-1),Yt=f2(Xt-1,Yt-1)。
在图排序算法中,邻接矩阵的不可约是一个基本假设,如PageRank[22]、MultiRank[30]、MutuRank[31]等,本文同样假设句网络图G的邻接矩阵A不可约,即图中任意两个顶点间至少存在一条路径。本文给出如下两个定理并证明。
定理1 如果A是不可约的,那么B=αA+(1-α)QQT同样是不可约的。
证明 由于Q≥0且1-α≥0,因此,A不可约意味着句网络图中任意两点间存在至少一条路径。根据B的定义,边权重增加一个非负的值不改变顶点间的连通性,因此B也是不可约的。
证毕。
定理2 如果A是不可约的,那么f1(X,Y)和f2(X,Y)分别存在一个平稳概率X′∈Ωm和Y′∈Ωn,并且X′=f1(X′,Y′),Y′=f2(X′,Y′),且X′>0,Y′>0。
证明 此问题可转换为不动点问题(fixed point problem)。假设存在映射F:Ω→Ω:
F(X,Y)=[f1(X,Y),f2(X,Y)]
显然,F(·)是良好定义的,即当[X,Y]∈Ω时,F([X,Y])∈Ω并且是连续的。根据Brouwer不动点定理[32],必然存在[X′,Y′]∈Ω使得F[X′,Y′]=[X′,Y′],即f1[X′,Y′]=X′,f2[X′,Y′]=Y′。
证毕。
定理2表明当A不可约时,所有F(·)的不动点均为正。根据文献[33],不动点是唯一的,即当所有界内的点均非不动点时,WSRank的平稳概率是唯一的,因此,根据定理2,WSRank算法存在唯一的平稳概率,算法是收敛的。
3 实验
本文利用公开数据集DUC02(http://www-nlpir.nist.gov/projects/duc/guidelines/2002.html)验证自动摘要算法的性能,这是一种在单文档自动摘要中得到广泛应用的基准数据集,包括TextRank[6]在内的多种经典算法均使用该数据集验证算法性能。针对单文档自动摘要,DUC02中共有533篇有效文档(从DUC02的567篇文档中去除34篇重复文档),每篇文档包含单词数为10,50,100,200等多个不同长度的参考摘要,本文选择生成100单词数的自动摘要,并与相同词数的参考摘要进行对比。验证的内容包括:生成摘要的总体质量、去冗余及关键词对摘要质量的提升、算法收敛速度、最佳参数选取等。
3.1 摘要质量总体评价
本文通过WSRank与多种其他自动摘要算法的对比,验证自动摘要的质量。DUC02中包含若干自动摘要系统在数据集上的运行数据,虽然无法获得各系统的详细名称和算法细节,但数据集通过匿名编号的方式提供了了运行结果,本文选择其中综合性能最佳的S28系统加入对比。此外,同样采用句网络排序的TextRank算法[6]及TextRankExt算法[7]也是本文的比较对象,其中TextRankExt是TextRank的扩展版,在句子TextRank得分的基础上融入了位置得分和动名词WordNet得分等语义因素,通过线性加权的方式计算句子的最终评分。
摘要质量的评价方法采用自动摘要领域广泛使用的Rouge指标[34],Rouge是一种基于召回率(Recall)的自动化评价方法,根据比较力度的不同,本文选择Rouge-N、Rouge-W、Rouge-SU4四种具体的评价指标,详细定义可参考文献[34],其中Rouge-N中的N-gram采用1-gram和2-gram。由于数据集中包含多篇文档,本文以所有文档Rouge指标的平均值作为比较对象。实验结果如图1所示。

图1 DUC02数据集中的自动摘要质量对比
从图1中可以发现,TextRank除在Rouge-1中的效果好于S28外,其余4个指标的得分均为最低,但通过加入语义因素,TextRankExt在Rouge-SU4指标中缩小了与S28的差距,并且在Rouge-1、Rouge-2以及Rouge-L三个指标上取得了优于S28的得分,这说明在图排序过程中仅在句子层面进行迭代具有一定的局限性,适当加入其他因素有助于提升摘要的生成质量。而WSRank在全部5个指标中均取得了最高得分,说明较之语义,在句子评分中融入词的权重能够取得更好的效果,从而生成更加准确的摘要。
除宏观的总体质量比较外,本文还对数据集中的每篇文档运行WSRank、TextRank、TextRankExt三种算法生成的自动摘要进行了细粒度的比较,表1列出了每种算法在相应指标下得分最高的文档数。可以发现,由于TextRankExt和WSRank分别在语义和单词权重方面对TextRank进行了提升,因此它们几乎在每篇文档中所取得的摘要效果均好于TextRank,仅有极少数文档的TextRank摘要能够取得最优。而对于TextRankExt和WSRank两种算法,WSRank在Rouge-N与Rouge-L指标下的优势较为明显,在Rouge-W与Rouge-SU4指标下略少于TextRanKExt算法,但由于数量相差不大,且WSRank在优势文档中得分更高,因此反映在平均分的总体评价上,WSRank仍领先于TextRankExt。

表1 DUC02数据集上自动摘要算法最优文档数量对比
3.2 冗余去除对摘要质量的提升
相似的语句在评分上较为接近,若这些语句都得到了较高的评分,自动摘要算法从排序后的句子中提取的Top-K个语句组成的摘要就变成了相似语句的重复,反而会丢失一些评分次高但却有着重要意义的句子。本文在生成自动摘要的过程中加入了冗余去除过程,在提取摘要句时进行相似性判断,从而剔除文档中的同义语句,保证了摘要的准确性。表2展示了冗余去除对于摘要质量的影响,其中,相似度阈值θ=0.8,选择相对较大的θ的目的是希望放宽相似度的判定,从而更加尊重排序算法所得出的句子权重,同时也更能说明去冗余对摘要质量的提升。实验结果表明,即使选择相对宽松的相似性定义,WSRank*仍能在所有指标上超越WSRank,说明去冗余对于提升摘要质量具有重要的意义,而在算法的实际使用中,则要根据文档的特点和摘要要求,灵活选择θ的取值。

表2 冗余去除对摘要质量的影响
3.3 关键词对摘要质量提升
WSRank与传统句排序算法如TextRank最大的不同之处在于考虑了关键词对句子评分的影响。关键词可定义为句-词增强中得分较高的单词,其在词-句增强过程中反作用于句子得分。本文通过比较WSRank和TextRank提取的摘要句数量验证关键词对摘要质量的提升,实验结果如图2所示。在进行统计前,首先根据参考摘要去除无效摘要句,即不在参考摘要中的句子,最终WSRank和TextRank算法共得出1 788个摘要句,Kappa统计值为50.53%,说明两种算法在摘要句判定上基本是一致的,两种算法同时计算出的摘要句1 281个,但WSRank计算出406个TextRank未计算出的摘要句,同时,TextRank计算出101条WSRank未计算出的摘要句。这说明融入关键词参与排序后,可以多找出406个摘要句而丢失101个摘要句,性能提升较为明显。
3.4 参数对摘要性能的影响
除阻尼系数d根据PageRank[22]的建议一般取0.85外,算法还包含两个重要参数ε和α,其中ε决定了算法的收敛速度,α主要调节词句协同排序时的相互的权重占比。对于ε,本文考察了其在区间[10-5,10-1]变化时算法的迭代次数,如图3所示。可以发现,WSRank算法的收敛速度令人满意,即使当ε=10-5时,算法仍能在13次迭代之内收敛。

图2 WSRank与TextRank摘要句命中对比

图3 参数ε对算法收敛速度的影响
参数α的主要作用是平衡词与句在排序过程中的权重比例,α越大,句所占据的权重就越大,极端情况下,当α=1时,WSRank算法将蜕变为TextRank算法。图4显示了α从0.4变化到0.9时WSRank算法摘要质量的变化,可以发现,在Rouge-2、Rouge-L、Rouge-W以及Rouge-SU4四种指标中,摘要质量均随着α的增大而变高,直到α=0.75时,摘要质量达到最佳,此后α的增大将导致质量的降低。这说明排序中句子的权重仍应占据较大比例,但适当融入词的权重对句排序具有积极的影响,对于两者的比例,通过比较四种Rouge指标得分变化趋势,建议调节因子取值0.7~0.75,大于0.75将会使摘要质量急剧下降。
4 结语
本文提出一种词句协同排序的单文档自动摘要算法,在基于图模型的句排序算法中融入词句关系的影响,从而有效提升了自动摘要的质量。通过转化为矩阵运算形式简化了算法的表述,并基于此证明了算法收敛性。在摘要句选择阶段,利用冗余去除进一步提升了所生成的自动摘要的质量。通过真实数据集上的实验,验证了算法的效果和性能。下一步将试图扩展词句协同排序至多文档自动摘要中,并引入语义处理机制,进一步提升摘要的生成质量的同时增强摘要的可读性。

图4 参数α对摘要质量的影响
References)
[1] LLORET E, PALOMAR M. Text summarisation in progress: a literature review [J]. Artificial Intelligence Review, 2012, 37(1): 1-41.
[2] FERREIRA R, CABRAL L D S, LINS R D, et al. Assessing sentence scoring techniques for extractive text summarization [J]. Expert Systems with Applications, 2013, 40(14): 5755-5764.
[3] LUHN HP. The automatic creation of literature abstracts [J]. IBM Journal of Research & Development, 1958, 2(2): 159-165.
[4] NOBATAY C, SEKINEZ S, MURATAY M, et al. Sentence extraction system assembling multiple evidence [J]. Journal of Neurophysiology, 2001, 85(4): 1761-1771.
[5] GUPTA P, PENDLURI V S, VATS I. Summarizing text by ranking text units according to shallow linguistic features [C]// ICACT 2011: Proceedings of the 13th International Conference on Advanced Communication Technology. Piscataway, NJ: IEEE, 2011: 1620-1625.
[6] MIHALCEA R, TARAU P. TextRank: bringing order into texts [EB/OL]. [2016- 12- 20]. http://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf.
[7] BARRERA A, VERMA R. Combining syntax and semantics for automatic extractive single-document summarization [C]// ICCLITP 2012: Proceedings of the 13th International Conference on Computational Linguistics and Intelligent Text Processing. Berlin: Springer, 2012: 366-377.
[8] 秦兵,刘挺,李生.基于局部主题判定与抽取的多文档文摘技术[J].自动化学报,2004,30(6):905-910.(QIN B, LIU T, LI S. Multi-document summarization based on local topics identification and extraction [J]. Acta Automatica Sinica, 2004, 30(6): 905-910.)
[9] NENKOVA A, VANDERWENDE L, MCKEOWN K. A composi-tional context sensitive multi-document summarizer: exploring the factors that influence summarization [C]// SIGIR 2006: Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2006: 573-580.
[10] 刘美玲,郑德权,赵铁军,等.动态多文档摘要模型[J].软件学报,2012,23(2):289-298.(LIU M L, ZHENG D Q, ZHAO T J, et al. Dynamic multi-document summarization model [J]. Journal of Software, 2012, 23(2): 289-298.)
[11] HE R F, QIN B, LIU T. A novel approach to update summarization using evolutionary manifold-ranking and spectral clustering [J]. Expert Systems with Applications, 2012, 39(3): 2375-2384.
[12] FERREIRA R, LINS R D, CABRAL L, et al. Automatic docu-ment classification using summarization strategies [C]// SDE 2015: Proceedings of the 2015 ACM Symposium on Document Engineering. New York: ACM, 2015: 69-72.
[13] GUPTA P, PENDLURI V S, VATS I. Summarizing text by ranking text units according to shallow linguistic features [C]// ICACT 2011: Proceedings of the 13th IEEE International Conference on Advanced Communication Technology. Piscataway, NJ: IEEE, 2011: 1620-1625.
[14] MEENA Y K, GOPALANI D. Analysis of sentence scoring methods for extractive automatic text summarization [C]// Proceedings of the 2014 International Conference on Information and Communication Technology for Competitive Strategies. New York: ACM, 2014: Article No. 53.
[15] ABUOBIEDA A, SALIM N, ALBAHAM A T, et al. Text summarization features selection method using pseudo genetic-based model [C]// IRKM 2012: Proceedings of the 2012 International Conference on Information Retrieval & Knowledge Management. Piscataway, NJ: IEEE, 2012: 193-197.
[16] LLORET E, PALOMAR M. COMPENDIUM: a text summarization tool for generating summaries of multiple purposes, domains, and genres [J]. Natural Language Engineering, 2013, 19(2): 147-186.
[17] ANTIQUEIRA L, OLIVEIRA O N, COSTA L D F. A complex network approach to text summarization [J]. Information Sciences, 2009, 179(5): 584-599.
[18] SHEN D, SUN J T, LI H, et al. Document summarization using conditional random fields [C]// IJCAI 2007: Proceedings of the 20th International Joint Conference on Artificial Intelligence. Menlo Park: AAAI, 2007: 2862-2867.
[19] KUPIEC J, PEDERSEN J, CHEN F. A trainable document summarizer [C]// SIGIR 1995: Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 1995: 68-73.
[20] CONROY J M, O’LEARY D P. Text summarization via hidden Markov models [C]// SIGIR 2001: Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2001: 406-407.
[21] ZHANG J J, CHAN H Y, FUNG P. Improving lecture speech summarization using rhetorical information [C]// ASRU 2007: Proceedings of the IEEE Workshop on Automatic Speech Recognition & Understanding. Piscataway, NJ: IEEE, 2007: 195-200.
[22] PAGE L, BRIN S, MOTWANI R, et al. The PageRank citation ranking: bringing order to the Web [EB/OL]. [2016- 12- 10].http://ilpubs.stanford.edu:8090/422/1/1999- 66.pdf.
[23] KLEINBERG J M. Authoritative sources in a hyperlinked environment [J]. Journal of the ACM, 1999, 46(5): 604-632.
[24] WAN X, XIAO J. Towards a unified approach based on affinity graph to various multi-document summarizations [C]// ECRATDL 2007: Proceedings of the 2007 European Conference on Research & Advance Technology for Digital Libraries. Berlin: Springer, 2007: 297-308.
[25] GIANNAKOPOULOS G, KARKALETSIS V, VOUROS G. Testing the use of N-gram graphs in summarization sub-tasks [J]. Natural Language Processing, 2008: 324-334.
[26] MORALES L P, ESTEBAN A D, GERVAS P. Concept-graph based biomedical automatic summarization using ontologies [C]// NLP 2008: Proceedings of the 3rd Textgraphs Workshop on Graph-Based Algorithms for Natural Language Processing, Association for Computational Linguistics. New York: ACM, 2008: 53-56.
[27] BARALIS E. GraphSum: Discovering correlations among multiple terms for graph-based summarization [J]. Information Sciences, 2013, 249: 96-109.
[28] GOYAL P, BEHERA L, MCGINNITY T M. A context-based word indexing model for document summarization [J]. IEEE Transactions on Knowledge and Data Engineering, 2013, 25(8): 1693-1705.
[29] GROLMUSZ V. A note on the PageRank of undirected graphs [J]. Information Processing Letters, 2012, 115(6/7/8): 633-634.
[30] NG M, LI X, YE Y. MultiRank: co-ranking for objects and relations in multi-relational data [C]// KDD 2011: Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2011: 1217-1225.
[31] WU Z, CAO J, ZHU G, et al. Detecting overlapping communities in poly-relational networks [J]. World Wide Web Journal, 2015, 18(5): 1373-1390.
[32] BAZARAA M S, JARVIS J J, SHERALI H D. Linear Programming and Network Flows [M]. Hoboken, NJ: John Wiley & Sons, 2011:45.
[33] KELLOGG R. Uniqueness in the Schauder fixed point theorem [J]. Proceedings of the American Mathematical Society, 1976, 60(1): 207-207.
[34] LIN C Y. Rouge: a package for automatic evaluation of summaries [EB/OL]. [2016- 12- 18].http://anthology.aclweb.org/W/W04/W04- 1013.pdf.
This work is partially supported by the National Natural Science Foundation of China (71571093, 71372188), the National Center for International Joint Research on E-Business Information Processing (2013B01035), the Surface Projects of Natural Science Research in Jiangsu Provincial Colleges and Universities (15KJB520012), the Pre-Research Project of Nanjing University of Finance and Economics (YYJ201415).
ZHANGLu, born in 1983, Ph. D., lecturer. His research interests include natural language processing, data mining.
CAOJie, born in 1969, Ph. D., professor. His research interests include data mining, business intelligence.
PUChaoyi, born in 1993, M. S. candidate. Her research interests include natural language processing.
WUZhi’ang, born in 1982, Ph. D., associate professor. His research interests include data mining, social computing.
Singledocumentautomaticsummarizationalgorithmbasedonword-sentenceco-ranking
ZHANG Lu*, CAO Jie, PU Chaoyi, WU Zhi’ang
(JiangsuProvincialKeyLaboratoryofE-Business,NanjingUniversityofFinanceandEconomics,NanjingJiangsu210023,China)
Focusing on the issue that extractive summarization needs to automatically produce a short summary of a document by concatenating several sentences taken exactly from the original material. A single document automatic summarization algorithm based on word-sentence co-ranking was proposed, named WSRank for short, which integrated the word-sentence relationship into the graph-based sentences ranking model. The framework of co-ranking in WSRank was given, and then was converted to a quite concise form in the view of matrix operations, and its convergence was theoretically proved. Moreover, a redundancy elimination technique was presented as a supplement to WSRank, so that the quality of automatic summarization could be further enhanced. The experimental results on real datasets show that WSRank improves the performance of summarization by 13% to 30% in multiple Rouge metrics, which demonstrates the effectiveness of the proposed method.
automatic summarization; extractive summary; single document; graph-based ranking; word-sentence collaboration
TP399; TP391.1
:A
2017- 02- 20;
:2017- 02- 27。
国家自然科学基金资助项目(71571093, 71372188);国家电子商务信息处理国际联合研究中心项目(2013B01035);江苏省高校自然科学基金资助项目(15KJB520012);南京财经大学校预研究资助项目(YYJ201415)。
张璐(1983—),男,江苏滨海人,讲师,博士,CCF会员,主要研究方向:自然语言处理、数据挖掘; 曹杰(1969—),男,江苏姜堰人,教授,博士,CCF会员,主要研究方向:数据挖掘、商务智能; 蒲朝仪(1993—),女,贵州遵义人,硕士研究生,主要研究方向:自然语言处理;伍之昂(1982—),男,江苏宜兴人,副教授,博士,CCF会员,主要研究方向:数据挖掘、社会计算。
1001- 9081(2017)07- 2100- 06
10.11772/j.issn.1001- 9081.2017.07.2100
