全国矿产资源潜力评价成果数据智能检索方法研究
2017-09-18赵亚楠朱月琴李朝奎肖克炎范建福李秋平
赵亚楠,朱月琴,李朝奎,肖克炎,范建福,李秋平
(1.湖南科技大学地理空间信息技术国家地方联合工程实验室,湖南 湘潭 411201;2.国土资源部地质信息技术重点实验室,北京 100037;3.中国地质调查局发展研究中心,北京 100037;4.中国地质科学院矿产资源研究所,北京 100037;5.西北大学城市与环境学院,陕西 西安 710127)
全国矿产资源潜力评价成果数据智能检索方法研究
赵亚楠1,朱月琴2,3,李朝奎1,肖克炎4,范建福4,李秋平5
(1.湖南科技大学地理空间信息技术国家地方联合工程实验室,湖南 湘潭 411201;2.国土资源部地质信息技术重点实验室,北京 100037;3.中国地质调查局发展研究中心,北京 100037;4.中国地质科学院矿产资源研究所,北京 100037;5.西北大学城市与环境学院,陕西 西安 710127)
针对矿产资源潜力评价成果数据,提出使用Hadoop平台下的HDFS对海量数据进行存储,构造地质矿产资源数据存储模型。使用支持单条记录快速查询的HBase数据库管理其元数据,并进行矿产资源潜力评价成果数据的快速检索,同时,在HBase上设计多级索引目录支持非主键查询,解决了HBase只支持简单的基于主键索引的缺点,实现了对矿产资源潜力评价成果数据的智能检索,并通过实验进一步验证该方法的正确性和可行性。
矿产资源;潜力评价;成果数据;Hadoop平台;HBase多级索引方法
1979~1985年和1992~1996年,这两段时间我国先后开展了成矿远景区划工作和第二轮矿产资源潜力评价工作,对主要的成矿区带进行了矿产资源潜力评价。“数字地球”、“数字国土”等项目的开展,也使得地质数据也进入了“大数据”时代[1]。实现海量地质数据管理的同时如何高效、快捷的从全国矿产资源潜力评价成果数据中获取所需数据则显得至关重要。因此,需要一种方法,既能解决结构化与非结构化海量地质数据的存储问题,又要实时、高效的进行数据检索。Hadoop是当前十分流行的基于Share-nothing的分布式处理系统,具有高效率的数据处理功能、容易拓展等优点[2]。HDFS作为底层基础设施,为云计算提供了高可靠性、高性能的存储服务,可用于解决地质大数据的存储问题。由于单纯的HDFS文件系统不太适合低延迟的访问应用,因此,用支持高效检索的分布式数据库HBase来满足其检索需求。针对矿产资源潜力评价成果数据,设计列式存储表格,将矿产资源潜力评价元数据存储于HBase中,便于高效检索。同时,设计HBase多级索引目录,并通过实验证明,该方法具有可行性。
1 理论计算检索技术方法研究现状
1.1大数据的智能检索方法研究现状
矿产资源潜力评价成果数据是通过矿产资源勘查和总结地质调查成果数据得到,可用于科学的评价未知矿的潜力,对于指示找矿具有重要的意义。伴随着大数据时代的到来,如何迅速的从冗余的大数据中提取所需信息是人们仍需解决的问题。随着近几年数据处理等技术的快速发展,NoSQL技术已成为一个热门的研究领域,各种NoSQL数据库产品也不断地被开发出来,例如HBase数据库。不同于传统数据库,NoSQL数据库放弃了RDBMS所遵循的“12 Codd’s rules”里的很多规则,同时在存储和应用等方面也做出了创新,很难对它的检索方法进行统一定义,因为它们本身就缺乏一个相对统一的技术解决方案[3]。本文归纳了主要的键值对型和列式存储模型的非关系数据库检索方法。
1)单级索引方面。即“行健索引”或“主键索引”,其实现机制与关系数据库所采用的B+Tree等方案类似。
2)二级索引方面。NoSQL由于具有弱原子性、一致性、隔离性、持久性等特点和开源分布式的特性,使其在达到数据低冗余及高度一致性的条件下实现二级检索较为困难,目前也仅有Cassandra等几种方法支持二级检索。
3)全文索引方面。NoSQL只能借助Lucene等工具包由开发者根据实际需要进行开发实现。
Hadoop是一个可部署于多台廉价机器上的分布式处理体系,被广泛应用于大数据存储、管理等方面。如何结合Hadoop实现海量数据的高效查询,学者们针对具体的应用情况从不同的角度进行了大量的研究。如,利用HBase建立并存储索引表及索引数据,通过分布式倒排索引方法实现了网页的快速查询检索[4];使用应用程序将R-树写入到HBase中,实现HBase的多条件查询[5];通过设计一致性哈希的分布式内存缓存机制,来实现HBase的基于非主键检索和基于范围的检索[6];使用HDFS保存索引文件来实现对HDFS的文件进行分布式查询[7];通过lucene信息检索库来实现HBase全文检索的功能[8]。
1.2矿产资源潜力评价成果数据管理现状
1.2.1 矿产资源潜力评价成果数据概况
全国潜力评价成果数据包含专题内容多,来源范围广,覆盖大,是全国地质机构的成果汇总,数据总量达到了13T,其中包括了二十多个矿种,四十七个项目、九个类型的地质数据[9]。主要包含了MapGIS格式的WT点文件、WL线文件、WP图形文件;JPG、TIF及MSI格式的图片数据;XML和TXT的元数据文件、DOC的说明文件及XLS的表格数据。其中矢量数据是全国矿产资源潜力评价数据模型规定的成果数据,采用全国统一系统库,利用MapGIS 67绘制而成。
1.2.2 矿产资源潜力评价数据管理模式现状分析
20世纪60年代起,美国便加大地质数据库的研究,并投入了大量资本,其他发达国家紧随其后,根据各自国家地质情况,运用网格计算、海量图库管理技术、多类型空间数据集成等技术,建立起关于各自国家重力、磁力、水文、矿产资源分布等方面的数据库[10]。我国的地质数据管理工作也在稳步前行,其管理系统是地理信息系统技术、数据库技术以及网络技术的综合应用[11]。自2007年国土资源部开展了全国矿产资源潜力评价项目,矿产资源潜力评价信息管理系统的建立已成为国内学者的研究热点。叶江等[12]结合MapGIS K9和GIS二次开发方法,实现了西藏地区矿产资源潜力评价数据管理体系;左超群[13]在Oracle 11G及MapGIS地理数据库的基础上,建立了矿产资源潜力评价数据模型;朱静苹等[14]通过MapGIS、SOL Server 2008及GeoMAG软件,完成江苏矿产资源潜力评价成果数据集成。
2 矿产资源潜力评价成果数据智能检索
矿产资源潜力评价成果数据量大,且数据结构复杂,包含了矢量空间数据、遥感影像数据、文本等,其中非结构化数据增长较快。因此,构建一套地质大数据的智能检索系统,完成海量地质数据稳定高效的智能检索尤为重要。全国矿产资源潜力评价成果数据智能检索模型主要包括三个功能模块:数据存储模块、并行计算模块和智能检索模块,结构图如图1所示。
2.1数据存储模块
从当前大数据存储技术发展来看,基于Hadoop的数据存储技术是具有研究意义和实际利用价值的,Hadoop是一个开源分布式的平台,它通过分布式文件系统HDFS来实现底层存储模块。HDFS具有高容错性的特点,允许用户在廉价的物理机上部署分布式系统,从而为潜力评价成果数据提供了数据存储服务[15]。本文基于Hadoop构建了矿产资源潜力评价成果数据存储模型(图2)。
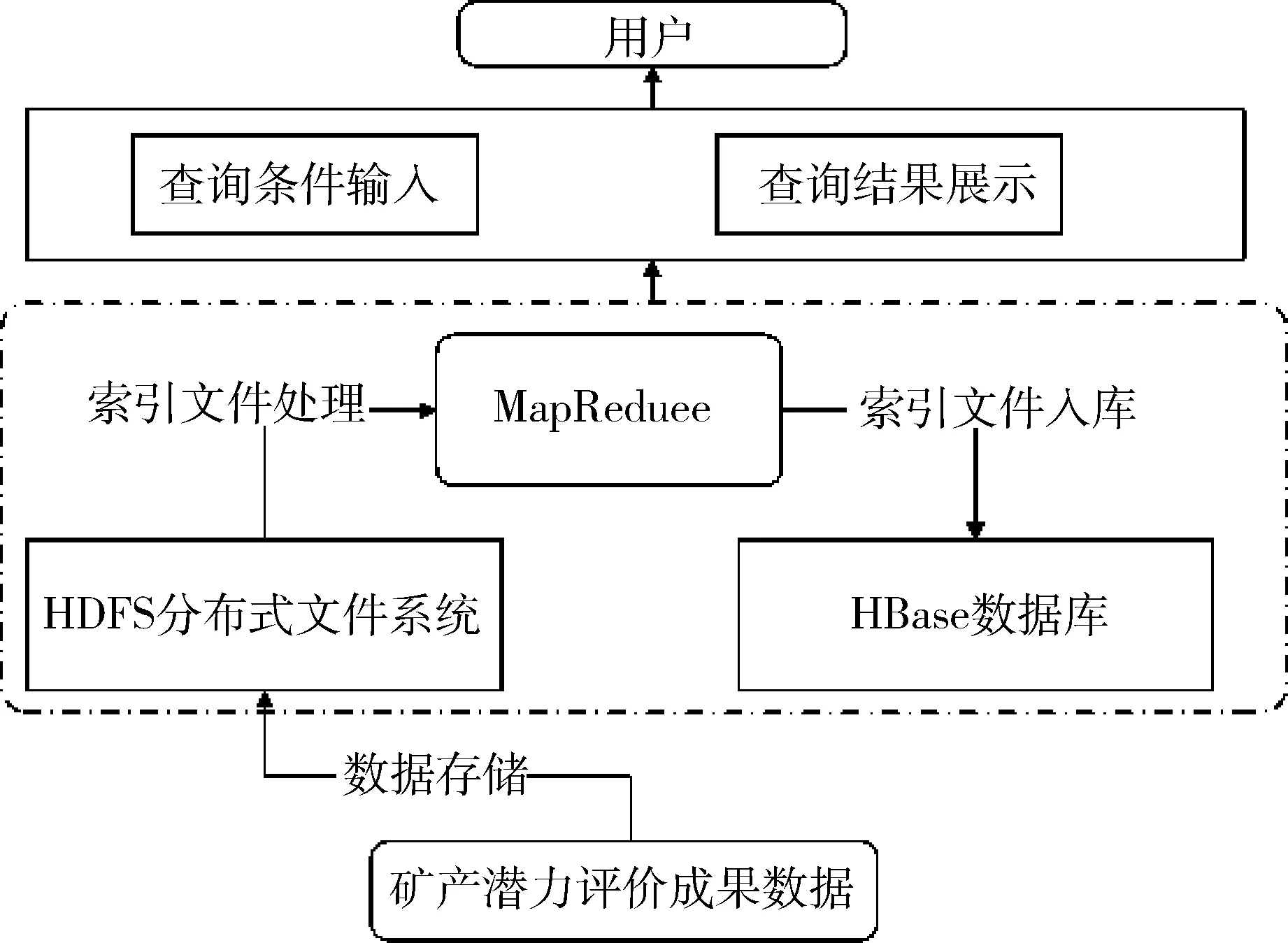
图1 智能检索架构图
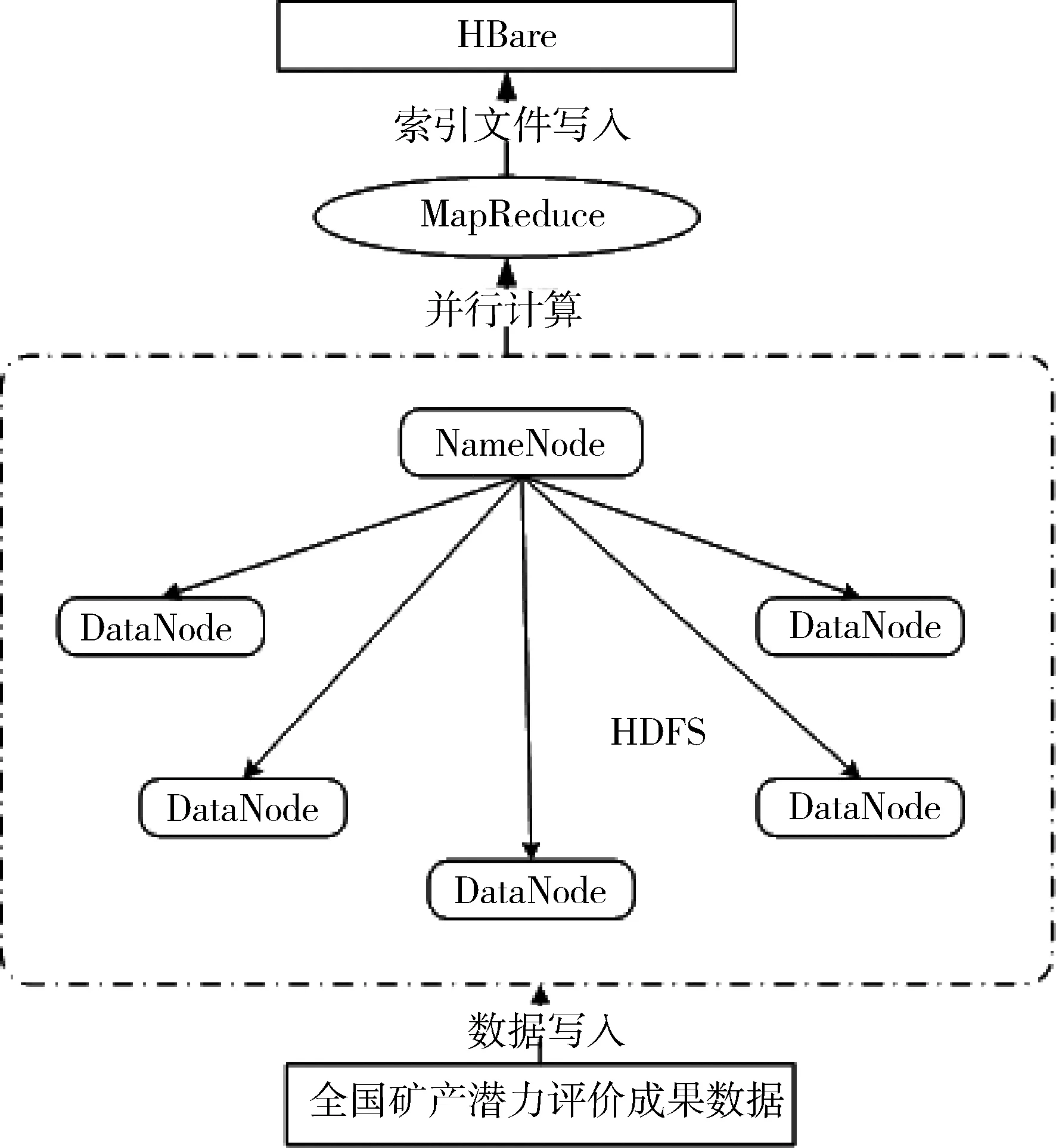
图2 矿产资源潜力评价成果数据存储模型
图2通过HDFS及其相关技术把底层的物理存储接口统一化,并通过虚拟化方法将系统中的存储设备映射为一个统一的资源进行管理,从而实现多个DataNode协调工作,将全国矿产资源潜力评价成果数据存储于HDFS上,通过并行计算将索引文件保存在HBase列式存储表中,完成数据的高效存储。
2.2并行计算模块
MapReduce作为并行编程模型[16]被主要用来进行大数据的并行计算,其工作过程主要分为:map阶段和reduce阶段。本文在MapReduce的基础上,使用HBase提供的TableOutputFormat方法,实现矿产资源潜力评价成果索引数据快速导入HBase。在map阶段,MapReduce将HDFS上的全国矿产资源潜力评价成果元数据分成固定大小的分片,然后将各个分片分解成键值对的形式,这里表示为
2.3智能检索模块
2.3.1 矿产资源潜力评价成果数据索引表设计
HBase将矿产资源潜力评价成果索引表数据以列式存储表的形式存储,从而形成一个稀疏多维度的排序映射表[17-18]。HBase中,表名(Table Name)用作唯一标识一张表;行关键字(RowKey)作为主键,用作唯一标识一行数据,在HBase中对行数据进行查询时,可通过单个行关键字、给定行健范围及全表扫描三种形式进行;列位于列族下,数量没有严格的规定,可根据用户的需求进行增加,从而确保了HBase存储的灵活性。
HBase不同于关系数据库,它没有严格的形态规定,既包含了矢量图形数据,又包含了文本类型数据,而存储表的数据记录也可能包含不同大小的列。因此,本文设计了全国矿产资源潜力评价成果数据索引表逻辑模型与物理模型。
2.3.1.1 逻辑模型(有序映射的映射集合)
HBase通过坐标系统来查询单元里的数据:[行健,列族,列限定符,时间版本],设计矿产资源潜力评价成果数据索引表逻辑模型如图4所示。
在理解图4模型概念时,可以将这些坐标从里往外看,认为开始以时间版本为Key、数据为Value建立单元映射,接着以列限定符为Key、单元映射为Value建立列族映射,最后以行健为Key、列族为Value建立表映射。
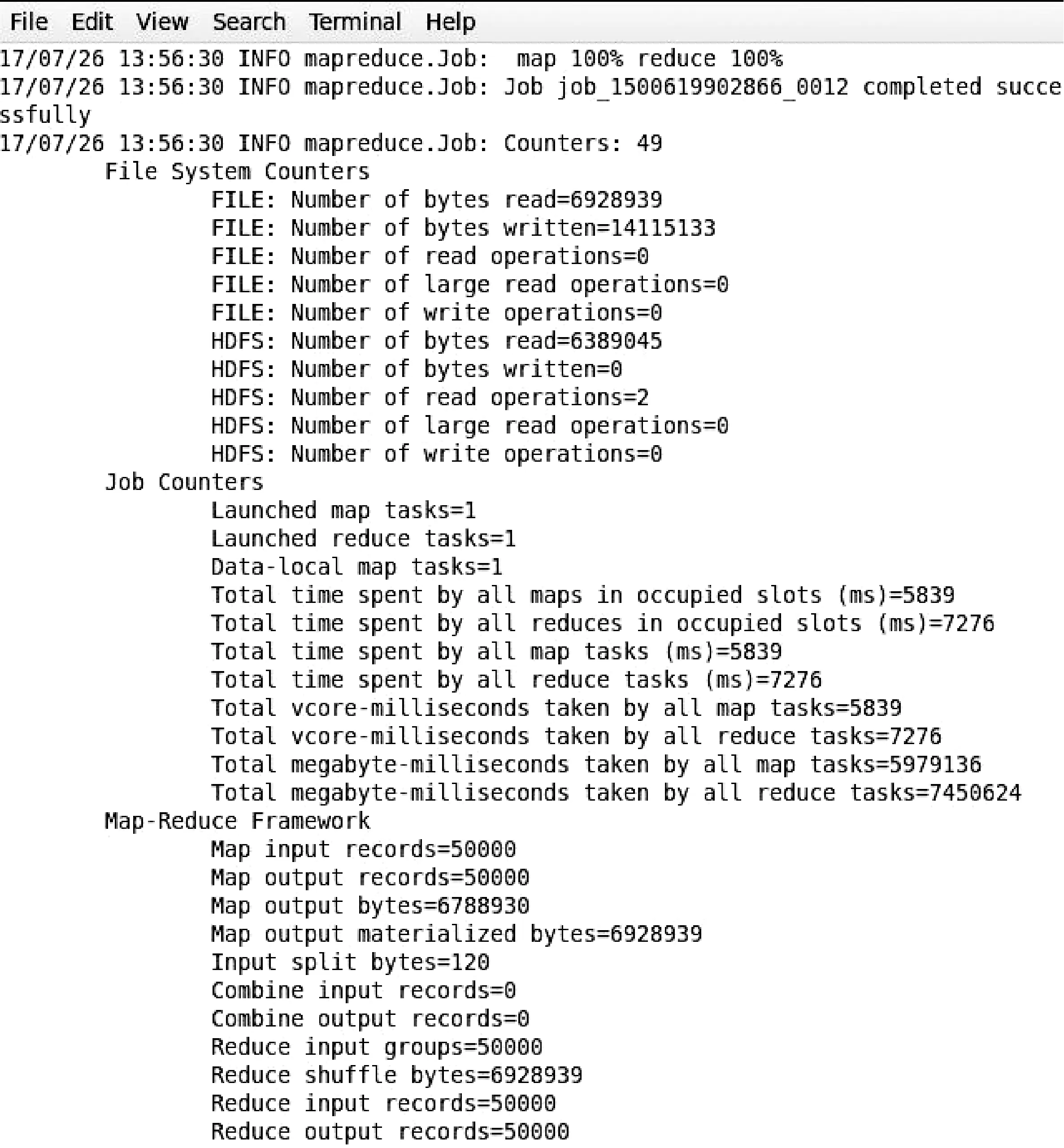
图3 MapReduce任务执行图
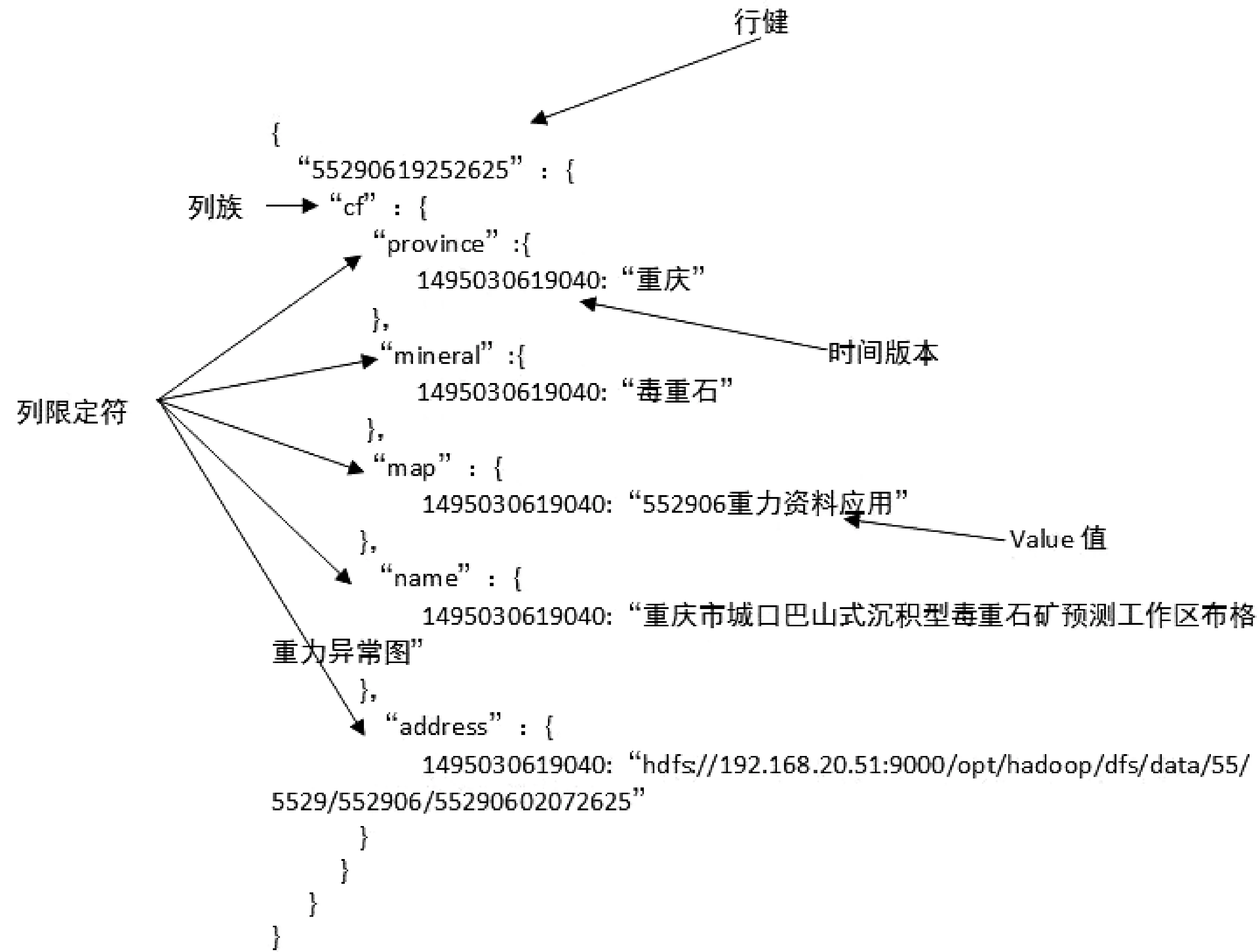
图4 矿产资源潜力评价成果数据索引表逻辑模型
2)物理模型(面向列族)
HBase中的列族下面包含了列,各列族在磁盘上都会有各自的HFile集合,这样就形成了物理隔离,从而允许数据在HFile层面上分别进行管理,存储在HFile里的地质矿产资源潜力评价索引数据物理模型如图5所示。
该矿产资源潜力评价成果数据索引表物理模型中的各列下没有空记录,如果有空数据则HBase在该列将不会存储数据,因此HBase列式存储表是面向列的,一行数据中同列族的需要物理的存储在一处。则以55290602072625为rowkey的数据在HFile中的存储是完整的。如果数据有多个列族,同时各列族下有潜力评价成果数据,那么每个列族使用自己的HFile意味着,当从HBase中读取数据时不需要读取这一行中的所有数据,只需读取用到的部分列族中的数据,这样则实现了数据的高效存储与快速读取。
2.3.2 HBase多级索引方法
HBase是基于Hadoop之上的一种非关系型数据库,为海量数据的存储和管理提供了一套具有高可扩展性的技术和方法,同时它提供实时高效的大数据查询分析能力。由于HBase只支持基于主键的快速检索,而不支持基于非主键的数据查询,这使得HBase的应用受到了极大地限制。本文根据矿产资源潜力评价成果数据,提出了一套基于依据元数据管理表的多级索引方案,其一、二级索引如图6和图7所示。

图5 矿产资源潜力评价成果数据索引表物理模型
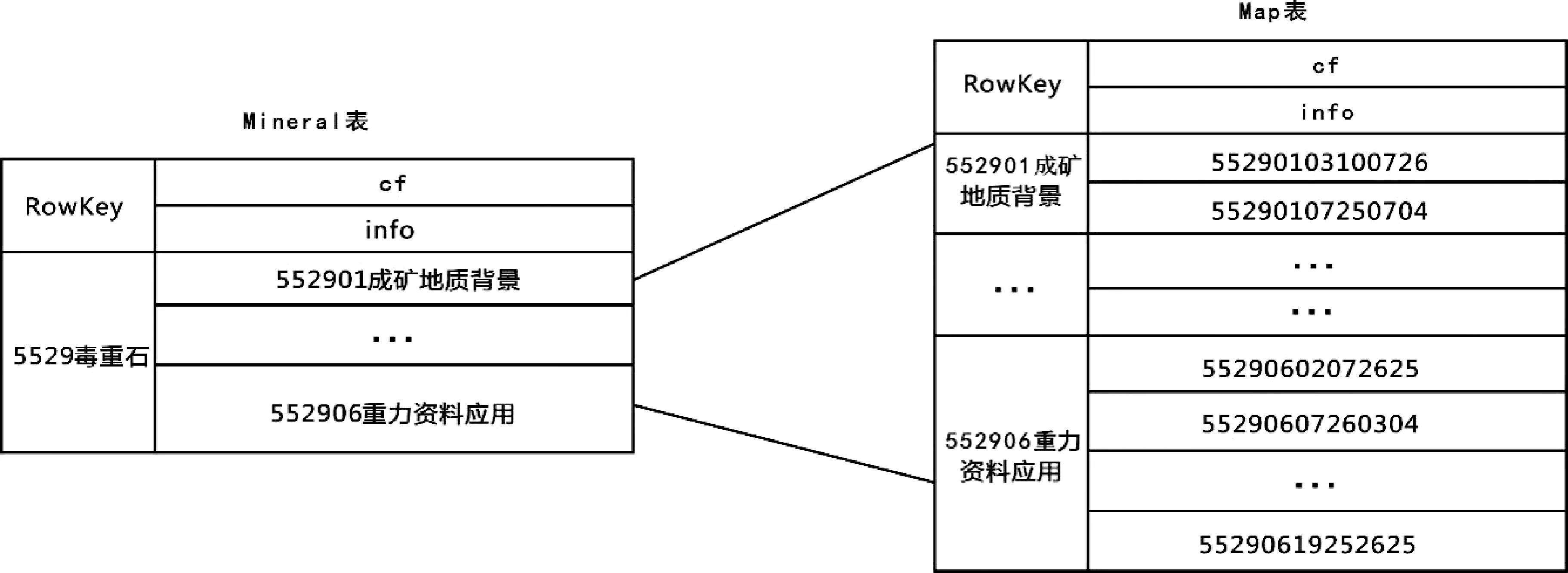
图6 矿产资源潜力评价成果元数据多级索引(第一级)
在图6和图7中,索引表的RowKey设计比较简短,避免了组合RowKey造成的元数据冗余问题,同时也避免了RowKey字段过长导致系统无法缓存更多的其他数据而导致内存的有效利用率降低的问题。检索过程如下。
首先,当客户端想检索符合cf:map=“552906重力资料应用”的cf:address的值,根据HBase主键查询,需要全表扫描Component才能得到需要的数据,然而,通过多级索引方法,只需检索Map表,从Map表中找到一级表的RowKey,然后从对应的列簇中获取符合条件的数据集合,接着检索程序会在这个小集合中抽取出符合条件的value值,再将检索到的value值赋给Component表,定位到相应的cf:address,从而进一步调用存储在HDFS中的矿产资源潜力评价成果数据。
由于地质矿产资源潜力评价成果数据具有较复杂的层次关系,多级索引方法同时设计了Mineral表,用来表示各属性之间的层次关系,同时避免了设计过于繁琐的主键,方便快速检索。假设检索符合cf:mineral=”5529毒重石”下包含了哪些图件,即Component表对应的主键是多少。这时,可以检索Mineral表,通过Rowkey ”5529毒重石”来得到对应的Value值,同时以该Value值作为新的Rowkey去检索Map表得到它包含的图件信息,从而实现智能检索。
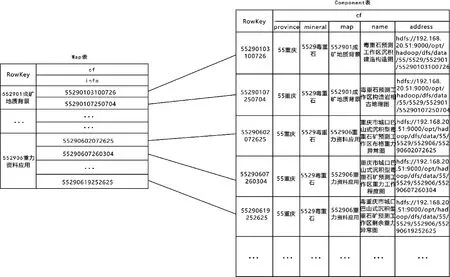
图7 矿产资源潜力评价成果元数据多级索引(第二级)
3 矿产资源潜力评价成果数据智能检索实验
3.1HBase优化前后对比试验
3.1.1 硬件环境
实验环境为7台虚拟机搭建的集群,其中3台为DataNode,1台为NameNode,3台为Zookeeper和HBase,表1给出了硬件环境。

表1 集群配置情况
3.1.2 HBase优化前后检索对比实验
为了验证基于矿产资源潜力评价成果元数据多级索引表格在检索方面的优势,分别选取了5万条、10万条、15万条、20万条、25万条、30万条的数据,从中检索符合cf:map= “552901成矿地质背景”的cf:name及对应的矿产资源潜力评价成果数据,检索结果如图8所示。
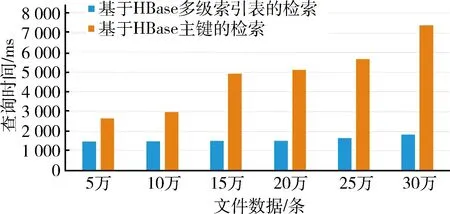
图8 HBase优化前后检索时间对比柱状图
从图8可以看出,本文设计的多级索引表格在地质矿产资源潜力评价成果数据检索方面与传统HBase相比有较大优势,这是因为,传统的HBase在RowKey上建立了类B+树索引,可以支持高效的基于主键的数据查询,由于缺少非主键索引的能力,因此在面对非主键查询时只能通过全表扫描Component表的方式找出符合条件的数据。而多级索引表格,则可通过检索前一张表的RowKey,得到的Value值赋给Component表作为二级RowKey,从而避免Component表的全表扫描,节省大量时间。
3.2HBase与Oracle对比实验
3.2.1 硬件环境
表2给出了测试用到的硬件环境,其中Oracle采用单节点,HBase则是基于Hadoop集群在7台电脑上部署的集群,其中,3台PC作为DataNode,1台PC作为NameNode,3台PC配置Zookeeper、HBase。
3.2.2 数据检索对比试验
为了对比HBase多级索引表与传统关系数据库的数据查询效率,将地质矿产资源潜力评价成果元数据分别导入Oracle数据库和HBase数据库,在试验中用来实验的数据量分别为50万条、100万条、150万条、200万条、250万条,每次均抽取50万条,测试基于Oracle、基于HBase多级索引表的实验,每组数据实验三次,取平均值作为实验结果如图9所示。

表2 测试数据库硬件环境

图9 数据检索时间对比柱状图
从图9可以看出,在数据量较少时,Oracle在矿产资源潜力评价成果元数据表的检索方面比HBase略占优势。然而,随着数据量的增长,Oracle的检索时间呈现快速上升的趋势,尤其当数据量达到250万条时,检索耗时与200万条的数据量耗时相比上升了约37%。HBase在数据量较少时,检索速率较慢,而随着数据量的增长,检索优势逐渐突显了出来。造成上述现象的原因是Hadoop分布式集群的系统开销时间长于Oracle,当数据量小时,Oracle自然占优势。而当数据量增大时,HBase是基于列存储的,进行字段查询时,可直接定位到该列,避免了全表扫描,同时设计的多级索引表把检索的负担主要分配到了RowKey上,节省检索时间。而Oracle是基于行存储的,从一个表中无论检索几个字段,都需要将表中相关的数据全部扫描一遍,因此随着数据量的增大,查询速度渐不及HBase。
4 结 论
本文结合大数据智能检索研究现状,将HBase数据检索技术应用于矿产资源潜力评价成果数据智能检索领域,针对地质数据情况提出了相关的方法改进,并通过实验验证了方法的可行性。
1)本文设计的多级索引表格在地质矿产资源潜力评价成果数据检索方面较传统HBase有较大优势。
2)当数据量很少时,传统关系数据库检索效率高,而当数据量急剧上升时,本文的智能检索方法则展示出了较大优势。
[1] 严雯英.基于MapGIS与Oracle的地质空间数据库设计与实现[D].湘潭:湖南科技大学,2016.
[2] Pan J,Biannic Y L,Magoulès F.Parallelizing multiple group-by query in share-nothing environment:a MapReduce study case[J].Acm International Symposium on High Performance Distributed Computing,2010:856-863.
[3] 刘家志.基于Hadoop架构和多级索引技术的医学影像存储检索系统研究[D].成都:电子科技大学,2014.
[4] 万轶,向广利.基于hadoop和hbase的分布式索引集群研究[J].信息技术与信息化,2015(1):102-103.
[5] 陈新鹏.基于HBase的数据生成与索引方法的研究[D].北京:北京邮电大学,2013.
[6] 葛微,罗圣美,周文辉,等.HiBase:一种基于分层式索引的高效HBase查询技术与系统[J].计算机学报,2016(1):140-153.
[7] 孙永超.基于Hadoop的信息检索系统研究[J].情报探索,2016,1(8):125-130.
[8] 邹敏昊.基于Lucene的HBase全文检索功能的设计与实现[D].南京:南京大学,2013.
[9] 左群超,叶亚琴,文辉,等.中国矿产资源潜力评价集成数据库模型[J].中国地质,2013,40(6):1968-1981.
[10] 吴湘宁.地质环境数据仓库联机分析处理与数据挖掘研究[D].武汉:中国地质大学(武汉),2014.
[11] 沈泉飞,顾和和,张海荣,等.矿产资源管理信息系统设计与开发[J].测绘与空间地理信息,2007,30(4):21-24.
[12] 叶江,张铃,郭娜,等.基于MapGIS K9数据中心的矿产资源潜力评价信息管理系统开发与实现——以西藏地区为例[J].国土资源科技管理,2013,30(6):81-86.
[13] 左群超.矿产资源潜力评价数据模型研发、应用与数据集成方法技术体系[J].地质通报,2015,34(12):2334-2351.
[14] 朱静苹,尚培颖,狄群,等.江苏矿产资源潜力评价成果数据集成及应用[J].地质学刊,2015,39(3):400-403.
[15] 孙永超.基于Hadoop的信息检索系统研究[J].情报探索,2016,1(8):125-130.
[16] Nguyen Andrew V,Wynden Rob,Sun,Yao.HBase,MapReduce,and Integrated Data Visualization for Processing Clinical Signal Data[J].AAAI Spring Symposium-Technical Report 2011:40-44.
[17] Franke Graig,Morin Samuel,et al.Distriuted Semantic Web Data Management in HBase and MySQL Cluster[C].Proceedings of the 2011 IEEE 4th International Conference on Cloud Computing,CLOUD 2011:105-112.
[18] Yang Jin,Tang Deyu,Zhou Yi.A Distributed Storage Model for EHR Based on HBase[C].Proceedings of the 2011 4th International Conference on Information Management,Innovation Management and Industrial Engineering,ICIII 2011:369-372.
Researchontheintelligentretrievalmethodofthenationalmineral’spotentialevaluationachievementdata
ZHAO Yanan1,ZHU Yueqin2,3,LI Chaokui1,XIAO Keyan4,FAN Jianfu4,LI Qiuping5
(1.National-Local Joint Engineering Laboratory of Geospatial Information Technology,Hunan University of Science and Technology,Xiangtan411201,China;2.Key Laboratory of Geological Information Technology of Ministry of Land and Resources,Beijing100037,China;3.Development and Research Center,China Geological Survey,Beijing100037,China;4.Institute of Mineral Resources,Chinese Academy of Geological Sciences,Beijing100037,China;5.College of Urban and Environmental Science,Northwest University,Xi’an710127,China)
Based on the national mineral resource’s potential evaluation achievement data,this paper puts forward that the HDFS of Hadoop platform can be used to store and construct the data storage model of geological minerals.We Uses the HBase which supports fast query of individual records to manage its metadata and realize the rapid retrieval of mineral resources potential evaluation achievement data.At the same time,we designs multi-level index catalog in HBase to achieve the non-primary key query.We correct the defect of the HBase which only support primary key index and achieve the goal of the intelligent retrieval base on mineral resources potential evaluation result data.Then we verified the correctness and feasibility of this method by the contrast experiment.
mineral resource;potential evaluation;results data;Hadoop platform;HBase multilevel index method
2017-06-27责任编辑:赵奎涛
国土资源部公益性行业科研专项项目资助(编号:201511079)
赵亚楠(1992-),女,山东淄博人,硕士研究生,主要从事地质大数据技术研究工作,E-mail:1364176112@qq.com。
朱月琴(1975-),女,博士,高级工程师,主要从事地质大数据、地图综合与可视化研究工作,E-mail:yueqinzhu@163.com。
P208
:A
:1004-4051(2017)09-0072-07
