基于网优大数据平台的LTE站间距算法研究
2017-09-15刘佳
刘佳
基于网优大数据平台的LTE站间距算法研究
刘佳
(中国移动通信集团设计院有限公司,北京 100080)
LTE站间距相关指标是中国移动网优大数据平台六维度报表中的重要指标,但已知的站间距基本算法在大数据环境下耗时过长,因此基于网优大数据平台中工参数据的存储方式,采用GeoHash技术,设计并实现了一种小区级站间距并行计算方法。采用该方法后,计算站间距时可以采用Spark等大数据技术来显著提升计算速度。
站间距 LTE 大数据 六维度报表 GeoHash
1 引言
中国移动网优大数据平台从各省采集LTE网络数据(包括工参、性能数据、资源数据、MR数据等),将采集到的数据进行解析,并对原始数据进行抽取及处理,将处理后的数据存入数据库,以供上层应用和分析使用[1]。其中工参数据每日更新存储在Redis数据库中;性能数据、资源数据、MR数据均存储在Hbase数据库中[2]。
六维度报表是基于底层数据采集的上层应用之一,六纬度报表总体框架分为数据存储、数据处理和数据呈现三部分。通过大数据服务引擎将数据源提供的数据进行计算、汇总后,存入MPP数据库表中,等待前台页面查询。六维度报表数据源包括工参数据、性能数据及MR数据等,整体实现架构如图1所示。

图1 六维度报表实现架构图
站间距相关指标(包括平均站间距、超远站占比、超近站占比)采用工参数据进行计算,是六维度报表中网络结构与覆盖分析的重要指标[3]。要计算平均站间距、超远小区占比必须先计算小区级站间距,目前小区级站间距计算是六维度报表实现中算法最复杂的[4]。小区级站间距计算复杂度大,且在网优大数据平台中需要计算全国约300万小区的站间距,若采用传统计算方式,计算时间太长,因此必须采用并行计算的方法提升计算效率。
本文对站间距计算方法进行研究,采用GeoHash技术,设计并实现了一种小区级站间距的并行计算方法,该并行计算方法已在网优大数据平台六维度报表中实际应用。
2 站间距基本算法与传统实现方法分析
2.1 站间距基本算法介绍
室分站点不参与站间距分析计算,小区级站间距按照泰森多边形法及方向角法分别计算后,取较小值[5]。
(1)泰森多边形法
1)根据全网所有基站生成泰森多边形[6];
2)根据每个基站泰森多边形,找到本网络内它的所有泰森多边形相邻基站(泰森多边形共边);
3)计算所有相邻基站到本小区的距离,平均值为本小区站间距,单位使用“m”,使用地球椭球体模型计算距离;
4)小区无相邻基站,定义为“孤小区”,站间距结果为空。
(2)方位角法
1)根据小区A方位角与搜索角宽度确认方向,搜索角宽度范围为20°~360°,默认为120°。初期按照120°实现,后期考虑共站其他小区的角度;
2)以小区经纬度为圆心,以搜索半径a(默认2 km)为半径,在搜索方向上画弧;
3)如果所得扇区内存在基站X(1个或N个),则将该基站X到A的平均距离计做站间距,如果N>3,那么取最近的3个值纳入计算;
4)如果未找到基站X,那么将搜索半径由a升级到b(默认10 km),按照2)、3)步骤进行依次计算;
5)如果在b搜索半径内仍未找到基站X,将搜索半径由b升级为c(默认20 km),按照2)、3)步骤进行依次计算;
6)在c搜索半径内仍未发现基站,则站间距计为空。
2.2 站间距传统实现方法分析
站间距基本算法中方位角法较为简单,每个小区可以分别计算,计算速度主要受搜索范围影响,本文不进行主要探讨。
泰森多边形法实现的关键步骤为Delaunay三角网剖分。图2中每一个点都代表一个独立的站点,以这个点为端点的所有线段的另外一侧端点就为当前站点的第一圈紧邻站点。第一圈紧邻站点与当前站点距离平均值即为该站点小区的站间距。在传统实现方法中,必须先对目标区域进行Delaunay三角网剖分,再对各个站点进行站间距计算。当目标区域较大,例如对全国范围进行计算时,Delaunay三角网剖分算法将非常耗时。
泰森多边形法传统实现方式的问题在于无法像方位角法一样分别对各个站点进行计算。如果能将泰森多边形法的实现方式改进成各个站点可以独立计算,就可以通过增加计算节点的方式来提高计算效率。本文研究的站间距并行计算实现方法,即是对泰森多边形法的实现方式进行改进,让每个站点独立按照Delaunay三角网剖分的原则选取第一圈紧邻站点,并计算站间距。

图2 Delaunay三角网剖分示意图
3 小区级站间距并行计算实现方法
本文基于GeoHash技术设计了一种小区级站间距并行计算方法[7],方法总体描述如下:首先获取某基站一定范围内的邻近基站列表,在这个范围内计算该基站的泰森多边形法站间距和该基站小区的方位角法站间距,最后将泰森多边形法站间距和方位角法站间距中的较小值取为该基站每个小区的站间距。
在计算泰森多边形法站间距时,对Delaunay三角网剖分算法进行改进[8],改进示意图如图3所示:

图3 Delaunay三角网剖分算法改进示意图
原有Delaunay三角网剖分算法需要将所有点纳入计算,本文将该算法改进为可以对一个点按Delaunay三角网剖分法则计算所有相连的边[9]。经过改进后,泰森多边形站间距计算可以针对每个基站点独立计算,从而使得整个小区级站间距算法可以并行计算。
3.1 采用GeoHash技术获取邻近基站列表
从Redis数据库中读取所有工参数据并采用GeoHash进行编码。
GeoHash将区域划分为一个个规则矩形,并对每个矩形进行编码。编码的前缀可以表示更大的区域,例如wx4g0ec1,它的前缀wx4g0e表示包含编码wx4g0ec1在内的更大范围。这个特性可以用于搜索附近的点,但是从GeoHash的编码算法中可以看出它的一个缺点:位于格子边界两侧的两点,虽然十分接近,但编码会完全不同。为此,我们同时搜索当前格子周围的8个格子,即可解决这个问题。
GeoHash编码长度为5时,栅格大小为2.5 km左右。
获取某基站的邻近基站列表时,首先计算该基站的GeoHash编码,编码长度可指定为5,然后计算该基站所在栅格的周围8个格子的GeoHash编码,最后找出前5位GeoHash编码与上述9个GeoHash编码之一相同的基站点,即为该基站的邻近基站列表[10]。
3.2 泰森多边形法站间距计算
遍历邻近基站列表找出距离最短的基站作为第一边,记录下第一边,并将该基站添加到结果列表resultList中。
遍历其他邻近基站,计算目标基站到邻近基站连线边与第一边的顺时针夹角,将所有邻近基站的夹角按从小到大顺序排序。
排序后邻近基站列表记为list 1,将与目标基站距离最短基站添加到list 1的末尾。
遍历list 1,选择第一个基站与第一边构成三角形,并检测该三角形外接圆内是否有基站点,如果有,则选择下一个邻近基站重复上述空圆检测;如果没有,将该邻近基站添加到结果列表resultList,并将算法中的第一边替换为目标基站与该邻近基站的连线,重复上述操作,继续对后续的邻近基站进行空圆检测,直到遍历完list 1。
计算目标基站与结果列表resultList中所有基站距离的平均值,即为该基站下所有小区的泰森多边形法站间距。
3.3 方位角法站间距计算
遍历邻近基站列表,计算某一基站与小区基站的方位角,如果方位角与小区方位角差距绝对值小于60,则继续计算,否则跳过。
计算基站与小区基站的距离,如果距离小于等于2 km,则将该基站加入list 1;如果距离大于2 km且小于等于10 km,则将该基站加入list 2;如果距离大于10 km且小于等于20 km,则将该基站加入list 3。
邻近基站列表遍历完成后,检查list 1、list 2、list 3,如果list 1不为0且长度大于3,取其中最小的3个距离值求平均值即为站间距;如果list 1长度小于3,则所有值求平均值即为站间距。
如果list 1的长度为0,则计算list 2;如果list 2的长度也为0,则计算list 3;如果list 3的长度也为0,返回空值。
4 算法验证及应用
4.1 算法准确性验证
采用Java语言编写程序实现小区级站间距并行计算方法。为了测试算法准确性,采用测试数据对算法进行了测试,测试数据准备方法如下:
在百度地图上取6×6个点,相邻两点间距离为500 m,利用百度地图工具得到各个点的经纬度。原图比例尺以及所取点如图4所示。对中间16个点进行站间距计算,计算结果均为500 m左右,准确度较好。
4.2 算法效率分析及与传统实现方法的比较
采用Java语言编写多线程程序实现小区级站间距并行计算方法。测试数据采用北京市工参数据,程序执行时间与线程数量之间的关系如图5所示。根据测试结果,增加线程数量可以提升计算效率。

图4 百度地图上展示的算法测试数据
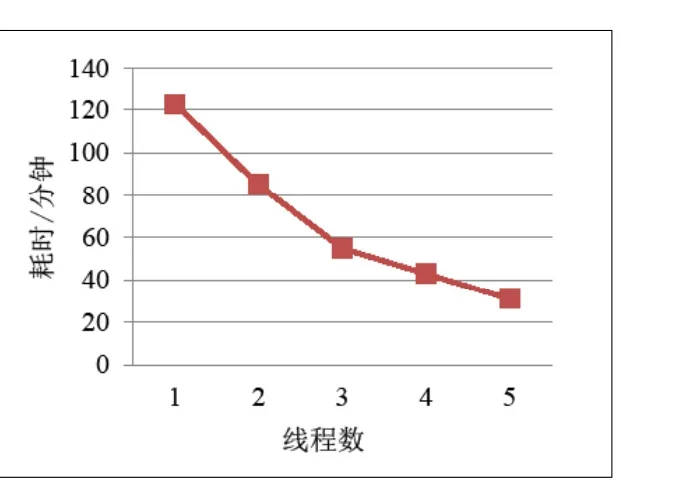
图5 程序运行时间与线程数关系图
传统实现方法是先对所有小区完成Delaunay三角网剖分以后,再进行站间距计算,计算速度与上述采用一个线程进行计算的效率相当,无法通过增加计算资源来提升计算效率。
改进后的算法可以通过多线程或多个计算节点的方式来提升计算效率。目前在大数据领域已有一些优秀的分布式计算框架,例如Spark等。Spark基于内存计算,将磁盘数据读入内存,将计算结果保存在内存,这样可以很好地进行迭代运算,提高了在大数据环境下数据处理的实时性。改进后的算法可以充分利用这些优秀的大数据处理技术来进一步提升效率。
4.3 算法实际应用情况
在网优大数据平台中,利用Spark采用上述算法进行计算,结果与原网优平台计算结果大致相同,且计算效率得到极大提升。以北京市为例,北京市所有小区的站间距仅用几分钟就计算完成。
5 结束语
六维度报表中站间距算法较为复杂,且在大数据环境下,对于计算效率提出了更高要求。为了能够使用Spark等大数据技术提升计算速度,本文采用Geohash技术,设计并实现了一种小区级站间距的并行计算方法。在网优大数据平台中,该算法已经被使用。以北京市为例,北京市所有小区的站间距仅用几分钟就计算完成。在站间距计算速度得到极大提升的前提下,站间距可以作为小区工参中的一个属性被回填到数据库中,这样可以满足更精细化的应用需求的开发,例如分场景的站间距评估等。
[1] 胡舜耕,魏进武. 大数据及其在电信运营中的应用研究[J]. 电信技术, 2015(1): 14-17.
[2] 余海波. 大数据在电信移动通信网络优化中的应用[J].广西通信技术, 2014(4): 8-11.
[3] 李泉. TD-LTE网络优化分析和研究[J]. 移动通信, 2016,40(10): 3-6.
[4] 李宝磊,周俊,任晓华. TD-LTE网络优化关键问题的研究[J]. 电信工程技术与标准化, 2015(1): 57-61.
[5] 陈大业,李丙辉,薛云山,等. 根据经纬度计算站间距模块的设计与实现[J]. 电信技术, 2014(2): 37-39.
[6] 申永源,曹布阳. 泰森多边形并行生成算法研究与实现[J]. 福建电脑, 2010(7): 1-4.
[7] 金安,程承旗,宋树华,等. 基于Geohash的面数据区域查询[J]. 地理与地理信息科学, 2013,29(5): 31-35.
[8] 刘少华,程鹏根,赵宝贵. 约束数据域的Delaunay三角剖分算法研究及应用[J]. 计算机应用研究, 2004,21(3): 26-28.
[9] 李小丽,陈花竹. 基于网格划分的Delaunay三角剖分算法研究[J]. 计算机与数字工程, 2011,39(7): 57-59.
[10] 赵雨琪,牟乃夏,祝帅兵,等. 基于GeoHash算法的周边查询应用研究[J]. 软件导刊, 2016,15(6): 16-18. ★
Research on LTE Site Spacing Calculation Method Based on Network Optimization Big Data Platform
LIU Jia
(China Mobile Group Design Institute Co., Ltd., Beijing 100080, China)
LTE site spacing related KPIs are important in the six-dimensional report of the network optimization big data platform for China Mobile. However, the existing algorithms of site spacing are time-consuming in the environment of big data. Therefore, a cell-level parallel calculation method of site spacing was designed and realized using GeoHash based on the engineering parameters stored in the network optimization big data platform. According to the method, the calculation speed of the site spacing calculation can be highly enhanced based on big data technology such as Spark.
site spacing LTE big data six-dimensional report GeoHash

10.3969/j.issn.1006-1010.2017.15.005
TN929.5
A
1006-1010(2017)15-0024-05
刘佳. 基于网优大数据平台的LTE站间距算法研究[J]. 移动通信, 2017,41(15): 24-28.
2017-05-17
责任编辑:黄耿东 huanggengdong@mbcom.cn
刘佳:工程师,硕士毕业于北京邮电大学,现任中国移动通信集团设计院有限公司咨询设计师,主要从事移动网络设计、优化相关工具平台研发工作。
