改进的二进制搜索防碰撞算法*
2017-09-04匡迎春
贾 浩,沈 岳,2,匡迎春,王 金
(1.湖南农业大学 信息科技学院,湖南 长沙 410128; 2.湖南省农村农业信息化工程技术研究中心,湖南 长沙 410128)
改进的二进制搜索防碰撞算法*
贾 浩1,沈 岳1,2,匡迎春1,王 金1
(1.湖南农业大学 信息科技学院,湖南 长沙 410128; 2.湖南省农村农业信息化工程技术研究中心,湖南 长沙 410128)
针对射频识别(Radio Frequency Identification,RFID)系统中多个标签同时与阅读器交互所产出的碰撞以及二进制搜索算法中出现的信息冗余和搜索效率低的问题,提出了一种改进二进制搜索防碰撞算法。该算法动态地调整阅读器发送的指令,利用标签冲突位构建识别树,从而大幅降低了阅读器与标签的交互次数及传输的数据量,有效地提高了标签识别的效率。通过MATLAB对系统的吞吐率、搜索次数以及阅读器发送的信息量进行仿真,仿真结果表明该算法与已有的二进制搜索算法相比,具有一定优势。
RFID;二进制搜索;防碰撞算法;碰撞位
0 引言
射频识别(Radio Frequency Identification,RFID) 是一种通过无线电信号识别特定目标并读写相关数据的非接触式的自动识别技术。当射频识别系统开始工作时,阅读器通过天线发射射频信号,并产生电磁场区域。在电磁场区域内,多个标签同时向阅读器传递信息时,造成了信息的冲突,就会出现标签的识别冲突,使阅读器不能高效、准确、实时地识别标签的问题,即标签碰撞问题。
RFID防碰撞算法主要有以 ALOHA 算法为代表的概率性算法和以二进制搜索算法为代表的确定型算法[1]。当大量标签并存时,ALOHA 算法的帧冲撞严重,易引起性能急剧恶化,不适宜大规模标签读取[2]。二进制搜索算法解决了“标签饥饿”问题,同时解决了时隙大量浪费的问题,因此以二进制搜索算法为基础的改进算法到了广泛应用[3]。
二进制搜索算法虽然解决了时隙大量浪费以及标签识别准确率低的问题,但是在搜索过程中产生了大量的冗余信息以及部分重复路径,造成了阅读器识别的效率较低。因此本文提出了一种改进的二进制搜索防碰撞算法。该算法能够动态地对阅读器发送的指令进行调整,在保证标签正确识别的基础上,减少阅读器与标签之间的搜索路径以及阅读器发送的冗余信息,极大地提高了标签的识别效率。
1 二进制搜索算法
二进制搜索算法中采用曼彻斯特(Manchester)编码实现阅读器确定标签碰撞的准确比特位置。曼彻斯特编码用电平跳变(上升沿/下降沿)来表示数值位,可在多个标签同时响应时按位识别出碰撞位。同时根据标签碰撞的位置,按一定规则重新搜索标签。
1.1 基本二进制搜索算法
基本二进制搜索算法以标签的ID号为识别基础。首先阅读器发送全“1”的序列号,各个标签将接收的序列号与自身的ID号比较。若标签的ID的二进制数值小于或等于阅读器发送的序列号,则该标签将自身的ID回传给阅读器,否则不作响应。基本二进制搜索算法具体步骤如下:
(1)阅读器发送一个全“1”的序列号请求命令,工作区域内的所有标签同时收到请求命令后,将其自身的ID回传给阅读器。
(2)阅读器对接收到的标签的ID进行逐一检测,判断有无碰撞位。
(3)确定标签发生碰撞时,将阅读器发送的序列号请求命令的最高碰撞位置“0”,并作为新的命令由阅读器发送,对标签进行逐一检测。若标签ID的二进制数值小于或等于阅读器发送的序列号,则作出响应。若标签继续存在碰撞,则继续修改阅读器发送的命令序列号,直到没有碰撞产生。
(4)阅读器通过发送的命令,筛选出响应的标签并直接读取标签的信息,然后将标签置为“去选择”状态。在阅读器工作范围内,只有当标签被阅读器激活,才能再次对阅读器发送的请求命令作出响应。
(5)重复步骤(1)~(4),即可识别出全部标签。
分析基本二进制搜索算法的搜索过程发现两方面的冗余信息。第一,阅读器每识别一个标签后,重新发送新的命令,从头开始进行新一轮的搜索,没有利用之前搜索过程中获取的标签信息,增加了标签的搜索路径。第二,基本二进制搜索算法中将阅读器发送的序列号中的最高碰撞位后的所有比特位都置为“1”,而这部分编码不能提供关于标签的任何信息,产生了大量的冗余信息[4]。
1.2 后退式二进制搜索算法
后退式二进制搜索算法针对基本二进制搜索算法中每识别一个标签都要从头开始进行新一轮搜索的问题进行了改进。将后退式二进制搜索算法识别标签的过程用二叉树来描述,其主要的改进点为:后退二进制算法完成一个标签的识别后不返回根节点,而是从离此标签最近的有待识别标签的内部节点开始搜索,直到该分支点以下标签全部搜索完毕,然后继续向上返回进行搜索[5]。具体识别过程如表1所示。
针对后退式二进制搜索算法的搜索过程进行分析,该算法缩短了阅读器的搜索路径,极大地加快了识别的过程。然而,后退式二进制搜索算法中将阅读器发送的序列号中的最高碰撞位后的所有比特位都置为“1”,而这部分编码不能提供关于标签的任何信息,产生了大量的冗余信息。同时,标签回传给阅读器的最高碰撞位之前的信息,对于阅读器也是已知的。
1.3 动态二进制搜索算法
动态二进制搜索算法针对基本二进制搜索算法中阅读器发送的序列号中包含大量冗余信息的问题进行了改进:读写器在发出指令(Request)得到碰撞位后,会以已知部分(L-1~X,X)作为搜索依据,X为当前最高冲突位,L为标签序列号长度。序列号前X位与L-1~X相同的标签将剩下的X-1~0位返回给读写器[6],该算法的识别过程如表2所示。

表2 动态二进制搜索算法具体识别过程
针对动态二进制搜索算法的搜索过程进行分析,该算法极大地减少了传输的数据量和搜索所需的时间,提高了标签识别的效率。然而,动态二进制搜索算法中阅读器每识别一个标签后,重新发送新的命令,从头开始进行新一轮的搜索,没有利用之前搜索过程中获取的标签信息,增加了标签的搜索路径。
2 改进的二进制搜索算法
2.1 算法基本思想
已有的几种二进制搜索算法都是按照某种规则自顶向下构建识别树,中间节点的构建和访问识别树的子叶以及如何动态调整阅读器发送的命令都是搜索过程当中非常重要的环节。本算法基于二进制算法做出了以下几个方面的改进。
(1)阅读器发送的信息量减少。本算法采用了动态二进制算法的思想:阅读器发送的命令序列号是动态改变的。但是,改进的二进制算法中阅读器发送的命令序列号的长度是固定的,只是阅读器发送的内容发生了改变。此外,阅读器内容的改变也是有规律的。改进算法发送的命令序列号为两位,默认为“00”,每识别一个电子标签后自动加“1”,变为“01”,依此规律,直到阅读器发送的命令序列号为“11”或标签全部被识别。改进的二进制算法在保证阅读器科学、准确、高效识别电子标签的前提下,有效地减少了阅读器发送的总的信息量。
(2)阅读器搜索次数的减少。这主要通过对标签碰撞位中“0”的个数识别标签,随后以标签碰撞位的数据为子叶节点,构建自底向上的识别树,通过计算识别数的叶子节点中“0”的个数即可实现标签的识别。该方法减少了识别树中间节点的个数,有效降低了识别树的复杂度,缩短了标签识别的过程,减少了阅读器搜索的次数。
2.2 算法流程
改进的二进制搜索算法流程如下:
(1)阅读器发送Request(1)命令,阅读器工作区域内的标签将自己的ID号回传给阅读器,并检测出标签的碰撞位,依此设定碰撞设定命令CID。
(2)当标签发生碰撞时,根据碰撞位中“0”的唯一个数来识别标签,筛选出“0”的个数唯一的发生碰撞的电子标签。
(3)阅读器初始化发送的命令序列号,发送的命令序列号的信息为碰撞设定命令CID,默认为“00”。标签根据CID确定对比的碰撞位,确保阅读器发送的序列号只与标签的最高两位碰撞位信息进行比较。
(4)阅读器发送Request(CUID),CUID自动累加1,标签将自身的最高两位碰撞位与CUID比较,若标签最高两位碰撞位小于或等于CUID,则标签作出响应;否则,标签不予响应。
(5)直至CUID重新置为“00”或标签没有碰撞时,识别结束。
3 仿真实验与分析
本文对基本二进制搜索算法、后退式二进制搜索算法、动态二进制搜索算法以及本文提出的改进二进制搜索算法针对标签数量较大、标签碰撞位连续及标签碰撞位不连续等几种情况进行对比分析。
假设阅读器工作范围内有N个标签,标签的序列号为M位,标签的碰撞位数为L(L=Log2N)位。
针对于二进制算法的特点,需要循环遍历搜索。因此,识别N个标签所需的次数为:
T1(N)=N*(log2N+1)
传输数据的长度为:
L1(N)=M*[N*(log2N+1)]
系统的吞吐率为:

针对动态二进制搜索算法的特点,识别N个标签的次数为:
T2(N)=N*(log2N+1)
传输数据的长度为:
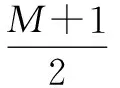
系统的吞吐率为:

针对后退式二进制搜索算法的特点,识别N个标签的次数为:
T3(N)=2N-1
传输数据的长度为:
L3(N)=M(2N-1)
系统的吞吐率为:
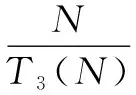
针对改进的二进制搜索算法,假设阅读器搜索N个标签的次数为T4(N)=2L-1+1,采用数学归纳法证明:
(1)当L=1时,即标签只有一位碰撞位,阅读器的工作范围内只有两个标签,根据算法流程,即T4(1)=2。
(2)当L=2时,表示标签有两位碰撞位,阅读器的工作范围内有4个标签,根据算法流程,即T4(2)=3;
(3)假设L-1个标签碰撞位时等式成立,即T4(N)=2L-1-1+1,则增加一位标签碰撞位,增加的标签碰撞位与之前的标签碰撞位位置完全不同,需要增加2L-1-1次搜索操作才能全部识别,即T4(N)= 2L-1-1+1+ 2L-1-1=2L-1+1,等式成立。
传输数据的长度为:
L4(N)=2*(2L-1+1)
系统的吞吐率为:
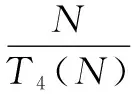
以阅读器搜索的次数和标签传输的信息量以及系统的吞吐率为例,对以上几种算法对比分析。阅读器对标签的搜索次数对比如图1所示。当碰撞的标签的数量较少时,改进的二进制搜索算法优势并不明显,且阅读器发送的指令增加了标签设计的复杂性,消耗了标签的能量。当碰撞的标签数量较多时,改进的二进制搜索算法能够较大幅地减少阅读器的搜索次数,其优势对比更加明显。碰撞标签与阅读器之间传输的信息量对比如图2所示。

图1 四种搜索算法搜索次数对比分析

图2 四种算法传输的数据总量对比分析
搜索算法明显低于二进制搜索算法和动态二进制搜索算法,且比后退式二进制算法减少一半以上。当标签的碰撞位较少,而碰撞的标签较多时,改进的二进制搜索算法减少的阅读器与标签之间的通信量将会更加明显。系统的吞吐率如图3所示。当标签的数目少于100时,改进的二进制搜索算法的系统吞吐率极大地优于其他几种算法,提高了系统识别的效率。

图3 四种算法吞吐效率对比分析
4 结论
本文针对RFID系统中已有的二进制搜索算法的冗余度高、传输数据量大、识别效率低的问题,提出了一种改进的二进制搜索算法。该算法只处理碰撞位的信息,在一定程度上减少了阅读器发送的信息量,从而提高了标签的识别效率。通过MATLAB模拟仿真表明,改进的二进制搜索算法与其他二进制搜索算法相比,该算法在标签的识别次数和阅读器发送的通信量以及系统的吞吐率方面都体现出一定的优势,具有较高的识别效率。
[1] Liu Xiaohui, Qian Zhihong, Wang Guiqin, et al. An improved RFID anti-collision algorithm[J]. Advanced Materials Research, 2013, 791-793:1243-1246.
[2] Zhang Lijuan, Zhang Jin, Tang Xiaohu. Assigned tree slotted aloha RFID tag anti-collision protocols[J]. IEEE Transactions on Wireless Communications, 2013, 12(11):5493-5505.
[3] 冯娜,潘伟杰,李少波,等. 基于新颖跳跃式动态搜索的RFID防碰撞算法[J]. 计算机应用,2012,32(1):288-291.
[4] 吴跃前,辜大光,范振粤,等. RFID系统防碰撞算法比较分析及其改进算法[J]. 计算机工程与应用,2009,45(3):210-213.
[5] 周艳聪,孙晓晨,顾军华. 一种改进二进制防碰撞算法研究[J]. 计算机应用研究,2012,29(1):256-259,262.
[6] 李飞,曹敦,傅明. 一种BIBD编码的RFID防碰撞算法的改进[J]. 计算机应用与软件,2012,29(6):151-154,166.
Improved binary search anti-collision algorithm in RFID system
Jia Hao1, Shen Yue1,2, Kuang Yingchun1, Wang Jing1
(1. College of Information Science and Technology, Hunan Agricultural University, Changsha 410128, China;2. Hunan Research Center of Rural and Agricultural Informatization Engineering Technology, Changsha 410128, China)
Aiming at the issues of the RFID(Radio Frequency Identification) system such as the generated collision when multiple tags and reader inteact as well as the information redundancy and the low search efficiency in the process of binary search algorithm,this essay carries out an improved binary search algorithm for avoiding collision. The algorithm reduces the data quantity of interaction times and transmission of multiple tags and reader by adjusting the transferred instruction of reader and constructing recognition tree through using tag collision bit, therefore, it improves the efficiency of label recognition. Through the use of MATLAB, the throughput, search times of the system and the amount of information transmitted by the reader are simulaled. The result shows that compared to the existed binary search algorithm, the improved algorithm has certain advantages.
RFID; binary search; anti-collision algorithm; collision bit
国家科技支撑计划(2012BAD35B05)
TP301
A
10.19358/j.issn.1674- 7720.2017.16.007
贾浩,沈岳,匡迎春,等.改进的二进制搜索防碰撞算法[J].微型机与应用,2017,36(16):23-25,29.
2017-02-28)
贾浩(1990-),男,硕士,主要研究方向:射频识别。
沈岳(1965-),男,教授,主要研究方向:物联网。
匡迎春(1971-),女,博士,教授,主要研究方向:单片机。
