基于磷虾群算法的汽轮机组最优初压研究
2017-09-03牛培峰刘阿玲马云鹏李国强
牛培峰, 陈 科, 刘阿玲, 马云鹏, 赵 振, 李国强
(1. 燕山大学 电气工程学院, 河北秦皇岛 066004; 2. 山东省莱西市院上镇中心中学, 山东青岛 266600)
基于磷虾群算法的汽轮机组最优初压研究
牛培峰1, 陈 科1, 刘阿玲2, 马云鹏1, 赵 振1, 李国强1
(1. 燕山大学 电气工程学院, 河北秦皇岛 066004; 2. 山东省莱西市院上镇中心中学, 山东青岛 266600)
为找到汽轮机变工况运行时的最优初压,利用改进的磷虾群算法(A-KH)和快速学习网(FLN)建立热耗率预测模型,然后利用A-KH算法的全局搜索能力,在可行的压力区间内对所建模型热耗率最低时对应的主蒸汽压力进行寻优,并将优化后的最优初压曲线与厂家设计压力曲线进行对比.结果表明:优化后的最优初压曲线能有效降低汽轮机组的热耗率,对汽轮机的安全经济运行更具有指导意义.
汽轮机; 热耗率; 最优初压; 磷虾群算法; 快速学习网
我国用电结构的改变导致电网的峰谷差增大,也就意味着大型机组不得不进行调峰运行,汽轮机组经常在变负荷状态下运行,为了使机组能够在变负荷状态下保持较高的热效率,常采用复合滑压运行方式,即定-滑-定运行方式.因此,确定定-滑-定运行分界点和寻找最优初压对提高热电厂的热经济性具有重要作用.
目前,热电厂汽轮机的运行初压一般都是按照厂家提供的滑压运行曲线来设定的,并没有考虑汽轮机组运行的实际情况,无法正确描述机组在变负荷状态下的运行状态.因此,要确保汽轮机组在变负荷运行时依然保持较好的运行情况,就必须对汽轮机的运行初压进行优化.在一定程度上,对汽轮机的运行初压进行优化可以归结为求解热耗率最小时对应的主蒸汽压力,即最优初压[1],其确定方法有2种:理论寻优法和实验寻优法[2-3].理论寻优法利用汽轮机各级的几何参数进行热力学计算,从而得出最优初压,但这种方法计算量很大且所需数据较难采集;实验寻优法通过选定几组不同的主蒸汽压力进行实验,并计算出对应主蒸汽压力的热耗率,对比实验结果找出最优初压,但这种方法选取的初压点有限,可能导致所寻压力并非是最优初压.
磷虾群算法(KH)[4]是一种新的智能优化算法,由于其操作简单、搜索多样性强和调整的参数较少而应用广泛.然而在对复杂问题进行优化时,KH算法容易陷入局部最优.为解决上述问题,笔者提出了一种改进的磷虾群算法(A-KH),实验表明,A-KH算法具有较高的收敛精度,且跳出局部最优的能力也得到加强.
以600 MW超临界汽轮机组为研究对象,笔者采用A-KH算法和快速学习网(FLN)[5]建立了汽轮机组热耗率预测模型,该模型具有较高的预测精度和较强的泛化能力,能够很好地对汽轮机组的热耗率进行预测.然后,利用A-KH算法去搜索相应负荷下热耗率最低时的主蒸汽压力,最终给出了汽轮机最优初压曲线.
1 磷虾群算法和快速学习网
1.1 磷虾群算法
KH算法的灵感来自于磷虾觅取食物和相互之间的交流[6].在KH算法中,每只磷虾位置代表一个可行解.在海洋生活中,磷虾个体的位置会受到以下3个因素影响[7].
(1)种群位置迁移引起的个体游动.
Ni,new=Nmaxαi+ωnNi,old
(1)
式中:αi为移动方向,αi=αi,local+αi,target,αi,local为局部邻近个体的感应方向向量,αi,target为种群最优个体的方向向量;Nmax为最大感应速度,取0.01 m/s;ωn为惯性权值,其值范围为[0,1];Ni,old为上次个体游动的位置变化;Ni,new为下一次个体游动的位置变化.
(2) 觅食行为.
Fi=Vfβi+ωfFi,old
(2)
式中:βi为磷虾个体觅食的方向向量,βi=βi,food+βi,best,βi,food为食物源方向向量,βi,best为当前最优磷虾位置的方向向量;Vf为觅食的速度,取0.02 m/s;ωf为惯性权值,其值范围为[0,1];Fi,old为第i个磷虾个体上次觅食运动的位置变化;Fi为第i个磷虾个体觅食运动的位置变化.
(3) 磷虾个体的随机扩散.
Di=Dmaxδ
(3)
式中:Dmax为磷虾个体最大的扩散速度;δ为一个随机的扩散方向向量,其值范围为[-1,1];Di为第i个磷虾个体随机扩散的位置变化.
针对不同的磷虾个体,越靠近食物源位置,扩散现象越不明显.上述3个因素共同决定了磷虾个体的游动方向,即朝着适应度值最小的方向改变.其中种群位置迁移引起的个体游动和觅食行为都包含一个全局搜索策略和一个局部搜索策略,2种策略并行进行,使得该算法成为一种稳定有效的优化算法[8].
综上所述,从t到t+Δt时间内的位置矢量为:

(4)
式中:ΔT为速度矢量的步长调节因子.
ΔT的定义如下:
(5)
式中:Uj和Lj分别为第j个变量的上、下边界;N为变量总数;Ct的取值范围为[0,2].
1.2 快速学习网
FLN是一种新型双并联前馈神经网络,其最大的特点是在单隐藏层神经网络的基础上增加了输入层与输出层的直接联系[9].因此,FLN可以看成是一种隐藏层到输出层的非线性与输入层到输出层的线性组合模型,其应用前景广泛.
对于任意N个随机样本{(xi,yi),i=1,2,…,N},其中,xi=[xi1,xi2,…,xin]T∈Rn表示第i个样本的n维特征向量,yi=[yi1,yi2,…,yil]∈Rl表示第i个样本的l维输出向量.令隐藏层神经元数为m个,隐藏层激活函数为g(x),则FLN的输出如下:
(6)
式中:j=1,2,…,N;Woi为输入层与输出层之间的连接权值;Wk,in为输入层到第k个隐藏层神经元之间的连接权值;Wk,oh为第k个隐藏层神经元到输出层之间的连接权值;bk为第k个隐藏层神经元的阈值.
式(6)用矩阵形式可表达为:
(7)
(8)
(9)
式中:W为输出权值矩阵;G为隐藏层输出矩阵;Y为期望输出;l为输出层节点个数;Woi和Woh分别为输入层到输出层的权值矩阵和隐藏层到输出层的权值矩阵.
式(7)用最小二乘范数解求法可得
(10)
(11)

FLN算法步骤如下:(1) 随机生成输入权值矩阵Win和隐藏层阈值矩阵b;(2) 通过式(9)计算隐藏层输出矩阵G;(3) 通过式(10)计算输出权值矩阵W;(4) 通过式(11)将输出权值矩阵W分割为Woi和Woh.
2 改进的磷虾群算法
与其他优化算法相比,KH算法的优势在于其搜索多样性强、操作简单和调节的参数少[10].但KH算法中的搜索完全依赖随机性,导致该算法收敛精度低,且不易跳出局部最优[11].针对以上KH算法的缺陷,笔者提出了A-KH算法.改进后的算法具有较强的全局搜索能力,同时收敛速度和收敛精度也有较大幅度的提高,主要有以下4个改进点.
(1) 采用反向学习算法[12]进行种群位置初始化,可以有效提高初始化种群位置的质量.
在A-KH算法中,基于反向学习算法的种群位置初始化过程如下(其中NP为可行解的维数,NK为种群数量,G为当前迭代次数):
① 初始化种群位置P(G=0)={xij},i=1,2,…,NP,j=1,2,…,NK.
(12)
式中:xi,min和xi,max分别为第i维元素的最小值和最大值.
③ 从组合种群位置{P(G=0)∪P′(G=0)}中选择NK个适应度值较小的位置作为初始种群位置.
(2) 从式(5)可以看出,Ct在KH算法中扮演着重要的角色,为了更好地平衡算法前期的探索能力和后期的开采能力,引入线性递减的Ct:

(13)
式中:Ct∈[0,2];a=0.45,b=0.1;Gmax为最大迭代次数.
(3) 从式(1)和式(2)可以看出,惯性权值(wn,wf)决定了KH算法的收敛速度和位置更新方式.在原始的KH算法中,(wn,wf)随着迭代次数的增加呈线性递减,这有可能会影响该算法的收敛精度和收敛速度.为了解决该问题,引入了sine混沌图谱[13]来更新(wn,wf)的值.
(14)
式中:∂=0.8;xk∈(0,1);c∈(0,4];θ=0.1;k=1,2,…,Gmax.
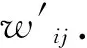
Xi(t+Δt)=Xi(t)wij+
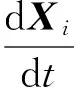
(15)

wij=φ=1/[1+exp(-fj/h)G]
(16)
(17)
式中:h为在第一次迭代中种群位置最优的适应度值;fj为第j个磷虾的适应度值.
A-KH算法的流程如下:(1) 初始化参数设定,即种群数量NK、最大迭代次数Gmax、最大感应速度Nmax、觅食速度Vf和磷虾个体的最大扩散速度Dmax等;(2) 在可行域空间内利用式(12)反向学习算法初始化磷虾种群的位置;(3) 计算每一个磷虾相应的适应度值,并选择NK个适应度值较小的位置作为初始种群位置;(4) 采用式(14)sine混沌图谱更新惯性权值(wn,wf);(5) 计算由磷虾种群位置迁移引起的个体游动、觅食行为和随机扩散对磷虾个体位置的变化量;(6) 采用式(13)计算Ct;(7) 利用式(15)产生下一代种群的位置;(8) 计算新产生位置矢量的适应度值,重复步骤(5)~步骤(8),直到达到最大迭代次数,算法结束;(9) 输出最优个体,即找到的最优解.
为了更好地体现A-KH算法搜索的高效性,采用6个典型的数值测试函数对KH算法和A-KH算法进行仿真实验,6个测试函数见表1,其中前3个为单峰测试函数,后3个为多峰测试函数.A-KH算法与KH算法的参数设置相同:种群数量为40,最大迭代次数为500,可行解的维数设置为30,运行次数为20,最大感应速度Nmax=0.01 m/s,觅食速度Vf=0.02 m/s,磷虾个体最大扩散速度Dmax=0.005 m/s.对20次寻优结果的平均值和均方差进行记录,结果见表2.
从表2可以看出,在设定的参数条件下, A-KH算法具有更优的寻优效果和更高的收敛精度.在对f1、f2、f4、f5和f6函数进行寻优时,A-KH算法能够找到理论最优值或非常接近,可以近似看成理论最优值.对于函数f3,A-KH算法搜索的精度虽然不高,但也比KH算法提高了1个数量级.与KH算法相比,A-KH算法不仅搜索的精度更高,而且跳出局部最优的能力也更强,可以应用于模型参数的寻优和实际工程问题的优化.

表1 测试函数

表2 2种算法测试效果的对比
3 汽轮机组热耗率建模
汽轮机组的热耗率是指汽轮发电机组每发1 kW·h电量所消耗的热量,是反映机组能量转换过程中一项重要的经济指标[14].选择热耗率预测模型参数时,通过比较输入参数和输出参数对热力性能实验结果的影响,并结合相关资料[8,15],选择发电负荷、主蒸汽压力、主蒸汽温度、再热器出口蒸汽压力、再热器出口蒸汽温度、再热器入口蒸汽压力、再热器入口蒸汽温度、再热减温水流量、过热减温水流量、汽轮机背压、循环水进水口温度和给水流量共12个参数作为热耗率预测模型的输入,热耗率作为输出.其中,主蒸汽压力对热耗率值有直接的影响,热耗率的计算详见文献[16].
3.1 模型建立及参数优化
以某热电厂600 MW超临界汽轮机组为研究对象,从集散控制系统(DCS)中采集10 d机组正常运行数据,其中春、夏、秋、冬四季各采集的天数为2、2、3、3,每隔2 h采集一次,每天12组,每一组均包含上述12个自变量参数,总共采集了120组多工况运行数据,发电负荷的范围在298.455~563.555 MW内,其他11个参数的变化区间均在额定范围内.其中,前8 d共96组运行数据作为训练样本,后2 d共24组运行数据作为测试样本,用于检测所建模型的泛化能力和预测精度.
采用FLN模型建立热耗率预测模型,由于FLN的输入权值和隐藏层阈值是随机产生的,很难确保所建的热耗率预测模型具有较强的泛化能力和较高的预测精度.因此,采用A-KH算法和FLN模型进行综合建模,A-KH算法用来对FLN模型的输入权值和隐藏层阈值进行寻优,目标函数以适应度值最小为原则,以最大迭代次数为循环终止条件,当寻优结束后,将最优寻优参数作为FLN模型的输入权值和隐藏层阈值,即完成A-KH-FLN热耗率预测模型(以下简称A-KH-FLN模型)的建立.A-KH算法的参数设置与前面相同.FLN模型的参数设置如下:3层网络结构为12-20-1,隐藏层激活函数为sigmoid,输入权值和隐藏层阈值的寻优范围均为[-1,1],通过多次实验,确定循环迭代次数为200.具体流程图见图1.
在模型结构参数优化中,目标函数为:

i=1,2,…,N
(18)
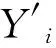
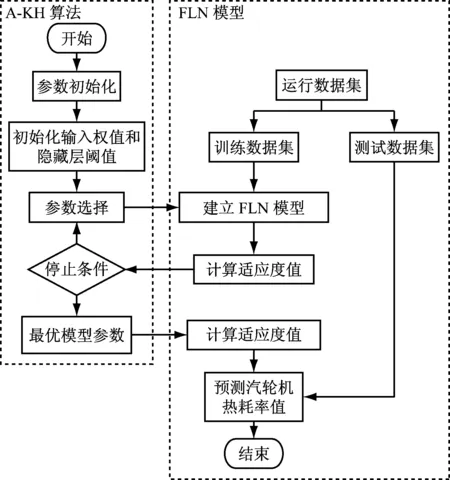
图1 采用A-KH算法优化FLN模型结构参数的流程图
3.2 模型性能分析
图2给出了A-KH-FLN模型对训练样本的热耗率预测情况.由图2可知,A-KH-FLN模型的预测值与实际值的跟踪情况良好,表明A-KH-FLN模型对训练样本具有很高的拟合精度和较强的跟踪能力.
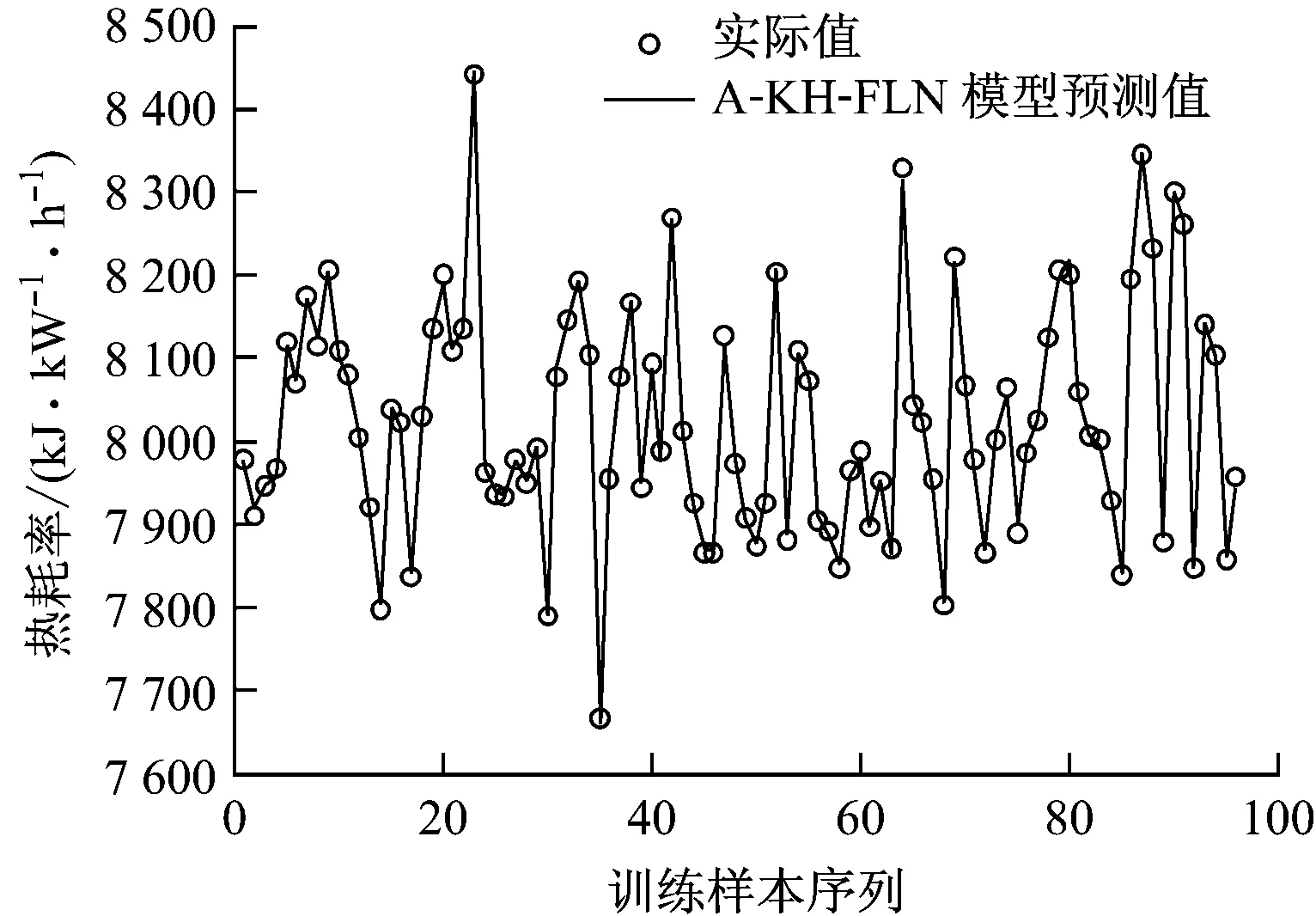
图2 训练样本热耗率预测值与实际值的对比
Fig.2 Comparison of training data between predicted results and actual measurements
图3给出了A-KH-FLN模型对测试样本的热耗率预测情况.由图3可知,A-KH-FLN模型具有较高的预测精度和较强的泛化能力.

图3 测试样本热耗率预测值与实际值的对比
Fig.3 Comparison of testing data between predicted results and actual measurements
为了更好地体现A-KH-FLN模型的预测效果,表3给出了训练样本和测试样本的均方根误差(RMSE)、平均绝对百分比误差(MAPE)和平均绝对误差(MAE)3个性能评价指标,其中KH-FLN模型是由KH算法和FLN模型建立的热耗率预测模型.由表3可知,A-KH-FLN模型训练样本的RMSE为6.106 1,MAPE为6.042 3×10-9,MAE为4.615 8;测试样本的RMSE为11.413 3,MAPE为2.091 2×10-5,MAE为9.322 3,各项指标均优于其他2种模型,说明A-KH-FLN模型具有良好的预测性能和泛化能力,能够用于工程应用.
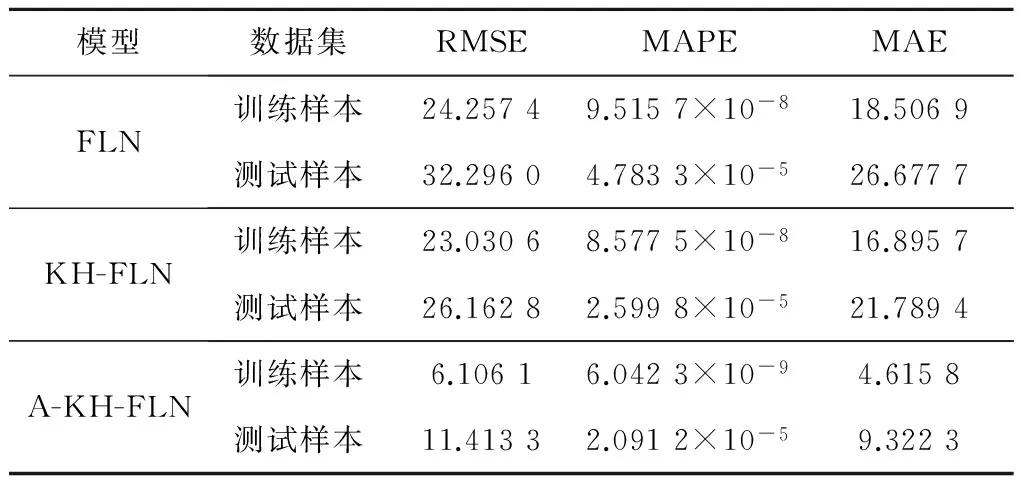
表3 各模型对热耗率的预测精度
图4为3种模型对测试样本的预测误差曲线.

图4 各模型对测试样本的预测误差曲线
由图4可知,相比于其他2种模型,A-KH-FLN模型的误差曲线波动平稳,误差较小,说明A-KH-FLN模型的泛化能力较稳定.
4 汽轮机组最优初压研究
4.1 优化问题描述
汽轮机在变工况条件下运行时,有且只有主蒸汽压力和主蒸汽流量是可以调节的.根据线性规划条件式可知,给定主蒸汽压力,主蒸汽流量也就可以确定了.因此,在某一工况下,主蒸汽压力值与汽轮机组热耗率值是一一对应的.当热耗率最低时对应的主蒸汽压力为最优初压.相关的数学模型描述如下:
(19)
式中:HR为汽轮机组的热耗率,kJ/(kW·h);NgE为汽轮机组运行负荷,MW;po为当前主蒸汽压力,MPa;X为影响热耗率的其他因素;Ngmin和Ngmax分别为汽轮机组允许的最小和最大负荷,MW;pod为机组的额定主蒸汽压力,MPa;Ngd为汽轮机组额定负荷,MW.
4.2 采用A-KH算法优化汽轮机初压
A-KH算法参数设置如下:种群数量为10,最大迭代次数为50,其余参数设置与第2节相同.在所建热耗率预测模型的基础上,以最大迭代次数为寻优终止条件,采用A-KH算法对主蒸汽压力进行寻优,并找出该负荷下对应的最优初压.
在全部工况中,挑选5种典型工况:300 MW、360 MW、420 MW、480 MW和540 MW.5种工况优化前后的实验结果见表 4.由表4可知,420 MW下优化后热耗率值下降最多,为56.19 kJ/(kW·h),各负荷下对应的热耗率降低值平均为28.35 kJ/(kW·h).在电厂中,通过A-KH算法优化得到最优初压,将其作为该负荷下的主蒸汽压力设定值,可以有效降低汽轮机组的热耗率,长期如此运行能够提高电厂的热效率,同时可以带来可观的经济效益.
图5给出了汽轮机组最优初压的变化曲线.分析图5可知,汽轮机变工况运行时,最优初压是一条曲率随负荷增加逐渐降低的平滑曲线,而不是厂家提供的一条斜直线.结果表明,经过A-KH算法优化后的汽轮机最优初压曲线能够更好地指导汽轮机组的安全运行.

表4 各负荷下优化前后的结果对比
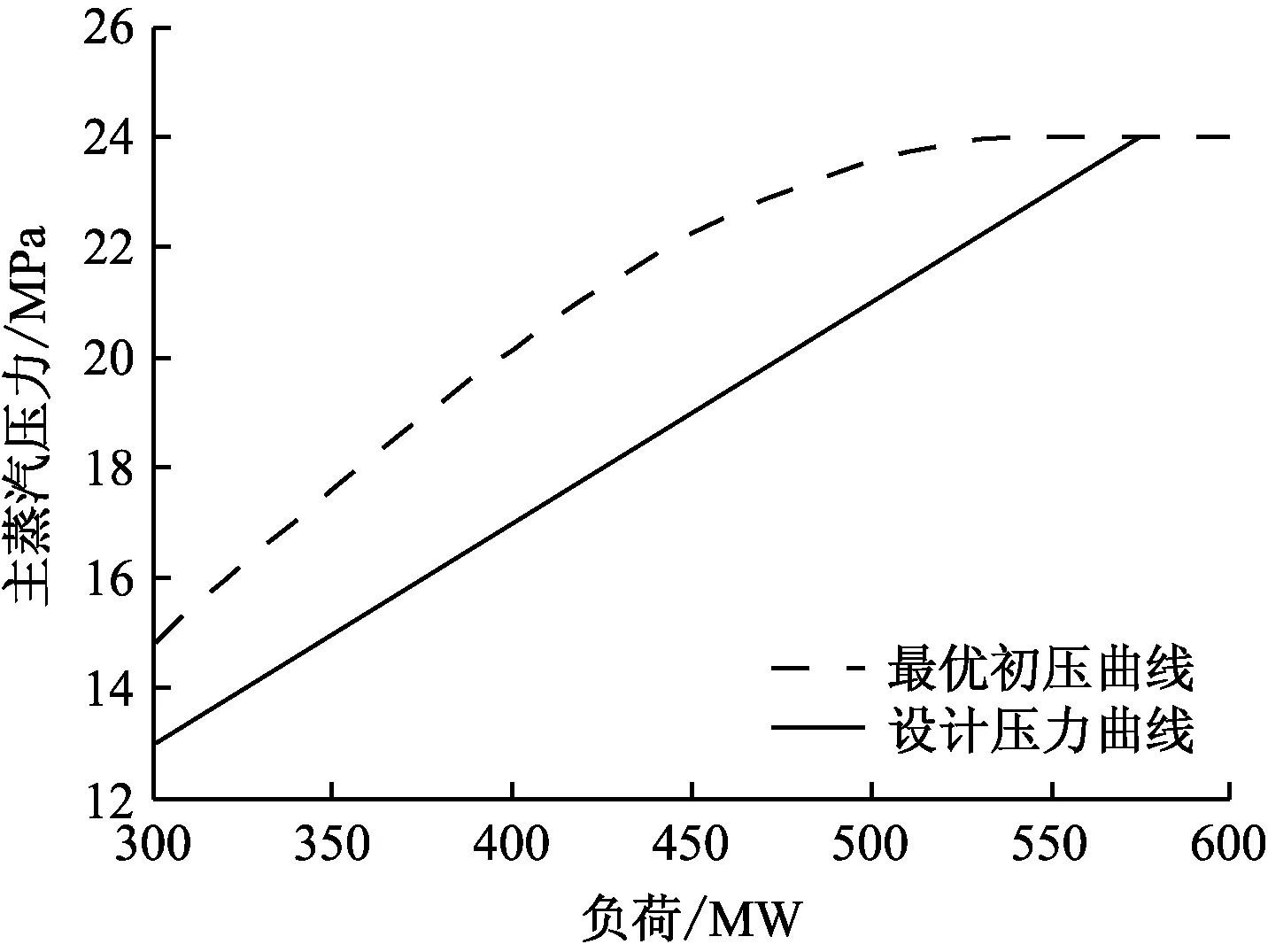
图5 最优初压曲线与设计压力曲线的对比
5 结 论
(1) 针对KH算法易陷入局部最优且收敛精度低等缺点,提出了A-KH算法,经测试函数验证,A-KH算法具有更高的搜索精度和更强的跳出局部最优的能力.
(2) A-KH-FLN模型能够准确反映输入与输出之间的非线性映射关系,相比于其他模型,该模型具有更高的预测精度和更强的泛化能力.
(3) 在热耗率预测模型基础上,利用A-KH算法的全局搜索能力对汽轮机组热耗率最低时的主蒸汽压力进行寻优,相比于厂家设计压力曲线,得到的最优初压曲线能有效降低汽轮机组的热耗率,对汽轮机的安全经济运行更具有指导意义.
[1] 刘伟, 叶亚兰, 司风琪, 等. 基于BP神经网络和SA-BBO算法的汽轮机组最优运行初压的确定[J]. 热能动力工程, 2013, 28(1): 18-22.
LIU Wei, YE Yalan, SI Fengqi, et al. Determination of the optimum initial operation pressure of a steam turbine unit based on a BP (back propagation) neural network and SA-BBO (simulated annealing biogeography-based optimization) algorithm[J]. Journal of Engineering for Thermal Energy and Power, 2013, 28(1): 18-22.
[2] 郭江龙, 常澍平, 姚力强, 等. 大型汽轮机复合滑压运行参数寻优方法研究[J]. 汽轮机技术, 2010, 52(6): 467-469.
GUO Jianglong, CHANG Shuping, YAO Liqiang, et al. Method research on parameter optimization in composite sliding pressure operation of large scale steam turbine[J]. Turbine Technology, 2010, 52(6): 467-469.
[3] 周志平, 范鑫, 李明, 等. 超临界600 MW机组滑压运行参数优化分析与试验[J]. 热力发电, 2011, 40(10): 50-54.
ZHOU Zhiping, FAN Xin, LI Ming, et al. Analysis and test of parameters' optimization for sliding pressure operation of supercritical 600 MW unit[J]. Thermal Power Generation, 2011, 40(10): 50-54.
[4] GANDOMI A H, ALAVI A H. Krill herd: a new bio-inspired optimization algorithm[J]. Communications in Nonlinear Science and Numerical Simulation, 2012, 17(12): 4831-4845.
[5] LI Guoqiang, NIU Peifeng, DUAN Xiaolong, et al. Fast learning network: a novel artificial neural network with a fast learning speed[J]. Neural Computing and Applications, 2014, 24(7/8): 1683-1695.
[6] WANG Gaige, GANDOMI A H, ALAVI A H. Stud krill herd algorithm[J]. Neurocomputing, 2014, 128: 363-370.
[7] WANG Gaige, GUO Lihong, WANG Heqi, et al. Incorporating mutation scheme into krill herd algorithm for global numerical optimization[J]. Neural Computing and Applications, 2014, 24(3/4): 853-871.
[8] 牛培峰, 杨潇, 马云鹏, 等. 基于改进的磷虾群优化算法的汽轮机初压优化研究[J]. 动力工程学报, 2015, 35(9): 709-714.
NIU Peifeng, YANG Xiao, MA Yunpeng, et al. Optimization on initial pressure of a steam turbine based on improved krill herd algorithm[J]. Journal of Chinese Society of Power Engineering, 2015, 35(9): 709-714.
[9] 李国强. 新型人工智能技术研究及其在锅炉燃烧优化中的应用[D]. 秦皇岛: 燕山大学, 2013.
[10] LI Junpeng, TANG Yinggan, HUA Changchun, et al. An improved krill herd algorithm: krill herd with linear decreasing step[J]. Applied Mathematics and Computation, 2014, 234: 356-367.
[11] WANG Gaige, GANDOMI A H, ALAVI A H. An effective krill herd algorithm with migration operator in biogeography-based optimization[J]. Applied Mathematical Modelling, 2014, 38(9/10): 2454-2462.
[12] RAHNAMAYAN S, TIZHOOSH H R, SALAMA M M A. Opposition-based differential evolution (ODE) with variable jumping rate[C]//Proceedings of IEEE Symposium on Foundations of Computational Intelligence. Honolulu, USA: IEEE, 2007: 81-88.
[13] WANG Gaige, GUO Lihong, GANDOMI A H, et al. Chaotic krill herd algorithm[J]. Information Sciences, 2014, 274: 17-34.
[14] 刘超, 牛培峰, 游霞. 反向建模方法在汽轮机热耗率建模中的应用[J]. 动力工程学报, 2014, 34(11): 867-872, 902.
LIU Chao, NIU Peifeng, YOU Xia. Application of reversed modeling method in prediction of steam turbine heat rate[J]. Journal of Chinese Society of Power Engineering, 2014, 34(11): 867-872, 902.
[15] 云曦, 阎维平. 火电厂汽轮机组影响热耗率计算的因素[J]. 东北电力技术, 2007, 28(3): 15-18.
YUN Xi, YAN Weiping. Factors effecting heat consumption calculation for steamed turbine of fossil-fired power plant[J]. Northeast Electric Power Technology, 2007, 28(3): 15-18.
[16] 盛德仁, 李蔚, 陈坚红, 等. 汽轮机组热耗率分析及实时计算[J]. 热力发电, 2003, 32(5): 16-18.
SHENG Deren, LI Wei, CHEN Jianhong, et al. Analysis and real-time calculation of specific heat consumption for steam turbine unit[J]. Thermal Power Generation, 2003, 32(5): 16-18.
Study on the Optimal Initial Pressure of a Steam Turbine Unit Based on Krill Herd Algorithm
NIUPeifeng1,CHENKe1,LIUAling2,MAYunpeng1,ZHAOZhen1,LIGuoqiang1
(1. School of Electrical Engineering, Yanshan University, Qinhuangdao 066004, Hebei Province, China; 2. Yuanshang Town Central Middle School, Qingdao 266600, Shandong Province, China)
To obtain the optimal initial pressure of a steam turbine under variable working conditions, a heat rate prediction model was established using operating data of the turbine by improved krill herd algorithm (A-KH) and fast learning network (FLN), with which the optimal initial steam pressure corresponding to the lowest heat rate was searched in the range of premitted pressure by taking use of the global searching ability of A-KH algorithm, and the optimal initial pressure curve was subsequently compared with the design curve. Results show that via the optimal initial pressure curve, the heat rate could be lowered effectively, which may serve as a reference for safety and economic operation of steam turbines.
steam turbine; heat rate; optimal initial pressure; krill herd algorithm; fast learning network
1674-7607(2017)08-0615-07
TK267
A
470.30
2016-08-30
2016-10-08
国家自然科学基金资助项目(61573306,61403331);河北省自然科学基金资助项目(F2016203427);中国博士后科学基金资助项目(2015M571280)
牛培峰(1958-),男,吉林舒兰人,教授,博士生导师,研究方向为复杂工业系统的智能建模与智能控制和流程工业综合自动化. 陈 科(通信作者),男,硕士研究生,电话(Tel.):15603372641;E-mail:m15603372641@163.com.
