基于ANN-MC模型的农村饮用水源健康风险不确定性量化研究
2017-09-03邓玉倪福全李林桓王志刚刘金山周登科
邓玉, 倪福全, 李林桓, 王志刚, 刘金山, 周登科
(1.四川农业大学 水利水电学院,四川 雅安 625014; 2.四川农业大学 环境学院,四川 成都 611130)
基于ANN-MC模型的农村饮用水源健康风险不确定性量化研究
邓玉1, 倪福全1, 李林桓2, 王志刚2, 刘金山2, 周登科2
(1.四川农业大学 水利水电学院,四川 雅安 625014; 2.四川农业大学 环境学院,四川 成都 611130)
饮用水源健康风险非确定性的定量化对水安全的准确评估十分重要。为减小非确定性对健康风险的影响,基于美国环境保护署推荐的健康风险评价模型,将人工神经网络和蒙特卡洛分析方法进行耦合,构建了ANN-MC健康风险评估模型,并对四川盆地西南缘周山地典型区的农村饮用水源进行健康风险评价。结果表明:在2010年、2011年、2012年,样本非致癌风险高于可接受水平“1.0”的仅为0.31%、0.04%和0.04%,而在0.1≤HQ<1.0之间的样本数分别为95.00%、78.75%和66.80%,说明研究区域内大部分居民可能通过饮水途径造成健康危害;该区农村饮用水源中需要重点控制的污染物为氟化物、硝酸盐、铁、锰和铜。ANN-MC模型预测健康风险是一种有效评估饮用水源健康风险的方法,可为水安全管理提供更加可靠的科学依据。
饮用水源;健康风险;蒙特卡洛;人工神经网络;非致癌风险
“十二五”期间,我国虽已解决了2.98亿农村居民的饮水安全问题,但“十三五”期间农村饮水安全仍面临着水源地污染加剧、水质处理设备不完善、水质监测不到位、二次改水等水质问题[1]。水体中的化学污染物可通过饮水、饮食等途径进入人体,进而影响人体健康,甚至死亡。目前,已发现因饮用水不卫生引起的人体疾病有50多种,包括皮肤病、氟斑牙、腹泻、肾病、肝癌等[2]。因此,探究水质与人体健康之间的量化关系在饮用水安全管理工作中十分必要。
20世纪80年代,美国环境保护署(United States Environmental Protection Agency,USEPA)制定了一系列有关健康风险评估(Health Risk Assessment,HRA)的指南和技术性文件,建立了污染物与人体健康的量化关系,形成了完整的健康风险评估方法和体系,为健康风险管理提供了科学依据。实际上,在风险评估过程中由于信息存在假设简化、数据量少、对自然系统认识不足等问题,导致风险评估普遍存在较大的非确定性,很可能造成健康风险被错误评估。因此,定量化分析非确定性,对于提高健康风险评估结果的准确性和可靠性具有重要意义。
蒙特卡洛(Monte Carlo,MC)分析方法是在简单或复杂系统中处理非确定性应用最广泛的概率分析方法[3-4],可将其与风险评价模型中的一个或多个概率分布函数相结合,利用电脑模拟量化非确定性[5]。其优点是能将健康风险评价模型的随机变量表征为概率分布函数,将输出风险值表征为累积分布函数,这大大增加了数据信息。MC法已被广泛应用到风险评估中[5-9]。
人工神经网络(Artificial Neural Network,ANN)分析方法可在复杂系统中模仿动物神经网络行为特征,利用已知数据通过调整内部节点之间相互连接的关系进行神经网络训练,使其具有与大脑相类似的记忆和辨识能力及自学习和自适应能力,达到处理系统非线性关系、非确定性问题的目的[10-11]。研究表明,ANN法在水文预报[12]、水质预测[11,13]和环境风险评估[4,14]等方面已成为一种强大的分析工具。在ANN法运算过程中,确定输入数据与输出结果之间的相对重要性,对排除与ANN法性能的影响不显著的输入数据十分重要,一般可通过数据敏感性分析解决。而MC法具有分析输入数据敏感性的功能。JIANG等[4]、等[11]、MCCREDDIN等[14]联合利用ANN法和MC法仿真模拟和分析了复杂系统风险,并获得了可靠的分析结果。但相关研究在健康风险评估中还未见报道。
本文基于USEPA健康风险评价模型,确定模型中的随机变量及其分布,利用ANN法建立变量与健康风险之间的映射关系,再联合ANN法与MC法对饮用水进行健康风险评估,并与USEPA健康风险评估模型计算结果进行对比。主旨在于减小非确定性对健康风险评估结果的影响,为决策者提供更合理的风险管理依据。
1 材料与方法
1.1 MC法
蒙特卡洛(Monte Carlo,MC)分析方法假定随机变量的概率分布函数已知,通过随机抽样的方法得到多组输入变量,对每组数值变量进行模拟,从而得到大量输出,并拟合输出结果的概率分布[4]。本文将每个输入变量导入Crystal Ball v 11.1软件中进行概率分布函数匹配,并获得最佳的概率分布。随后,在不考虑输入变量之间相关性的情况下,对每个变量进行独立的随机抽样,获得一系列随机数的输出变量。MC法主要依赖两种随机抽样方法:简单随机抽样(Simple Random Sampling,SRS)和拉丁超立方体抽样(Latin Hypercube Sampling,LHS)[15]。LHS适用于小样本,本文将采用LHS进行随机抽样。一般而言,样本数量越大,输出精度越高[9]。为保证抽样的准确性,需对抽样样本进行K-S检验(Kolmogorov Smirnov Test),检验公式如下[16]:
(1)
(2)
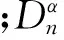
1.2 ANN法
在众多ANN架构中,反向传播(Back Propagation,BP)ANN法应用最流行,并在许多案例中得到了成功应用[17]。ANN法由相互连接的神经元组成,这些神经元被划分为3层:第1层为输入层,接受输入数据;中间为隐含层,主要是处理数据[18];最后1层为输出层,生成网络输出结果,ANN结构如图1所示。
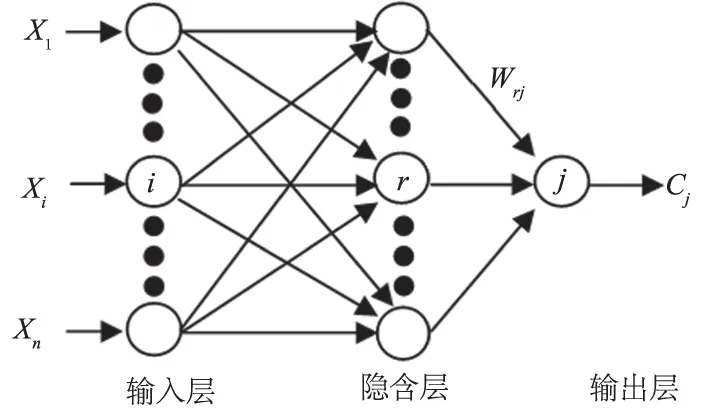
图1 ANN结构示意

1.3 ANN-MC健康风险评估模型的构建
ANN-MC的健康风险评价流程如图2所示。

图2 ANN-MC健康风险评价流程
ANN-MC健康风险评价的具体步骤为:①确定USEPA健康风险评价模型中的随机变量及其概率分布;②根据已知随机变量样本数据,将数据按ANN学习和检验进行分组;③设置学习率和误差等参数,将p组样本数据的随机变量作为神经网络的输入,得到的p组污染物日均暴露剂量(Chronic Daily Intake,CDI)作为输出,进行多次学习;然后用q组样本检验ANN性能,确保建立正确的ANN映射关系;④对随机变量进行n次随机采样(n为MC模拟次数),并输入ANN模型,得到n组响应量值,代入健康风险评价模型,可获得n个CDI值;⑤根据CDI值计算健康风险值,并作出相应的决策。
1.4 研究区概况
名山区隶属于四川省雅安市,位于四川盆地西南边缘,界于东经103°02′~103°23′,北纬29°58′~30°16′,幅员面积614.27 km2。名山区属亚热带季风性湿润气候区,多年平均气温15.4 ℃,多年平均降雨量1 299.4 mm,降雨时空分配不均,主要集中在6—9月。雨热同季,加之近年来气候变化异常,冬干春旱的现象每年发生,造成季节性缺水严重,农村人畜饮水十分困难。全区总人口27.83万人,其中农村居民24.12万人。据统计,到2010年底,全区农村居民中有11.81万人的饮水不安全,共覆盖了20个乡镇、171个行政村,其中饮水水质不达标人口达到6.09万人,为不安全人口的51.55%。其余饮水不安全的原因为:水量、方便程度或水源保证率不达标。
1.5 数据来源
综合考虑研究区水系特点、饮用水源、人群分布等因素,设置了农村饮用水源采样点,采样点分布如图3所示,并分别于2010年、2011年、2012年进行了水样采集。

图3 名山区农村饮用水源采样点分布
采样过程按照《生活饮用水标准检验方法》(GB 5750—2006)进行,采样容器为聚乙烯塑料瓶,采集水样为居民正在饮用水源。根据《生活饮用水卫生标准》(GB 5749—2006)确定了水源检测指标,包括pH、硫酸盐、氯化物、总硬度、六价铬、砷、镉、铅、铁、锰、氟化物、硝酸盐、铜、亚硝酸盐、氨氮等。
2 结果与讨论
2.1 输入变量筛选
本文采用USEPA颁布的《超级基金场地健康评价手册》[20]中提出的评估模式(USEPA模式),其包括数据的收集与分析、毒性评估、暴露评估、风险表征4个步骤。
步骤1 数据的收集与分析。该阶段的主要工作是在调查研究区基本情况、农村饮用水源、当地流行病学、居民的健康状况等信息的基础上,初步判定直接或潜在污染物、污染源和途径。
步骤2 毒性评估。依据USEPA Integrated Risk Information System(IRIS)数据库的化学污染物毒性分类标准进行毒性评估,确定剂量与不良健康效应发生概率之间的关系。
本文依据我国《生活饮用水卫生标准》(GB 5749—2006)和USEPA IRIS数据库的化学污染物毒性分类标准,分别对2010—2012年农村饮用水源水质指标进行污染和毒性评估,筛选出8项化学污染物(铁、锰、铜、六价铬、氟化物、硝酸盐、氨氮、亚硝酸盐)。本文采用的化学污染物剂量-反应关系数据均引自USEPA IRIS数据库,化学污染物的参考剂量(Reference Dose,RfD)值见表1。
步骤3 暴露评估。水中的化学污染物可经口、皮肤接触和呼吸3种途径进入人体,进而危害饮用该水源人群的健康[27]。本文主要针对饮水摄入途径进行研究,其日均暴露剂量(CDI)的计算公式如下[20]:
I=C·IR·ABS·EF·ED/(BW·AT)。
(3)
式中:I为日均暴露剂量(CDI),mg/(kg·d);C为水中污染物的实测浓度,mg/L;IR为饮水率,L/d;ABS为胃肠吸收系数,与污染物质有关;EF为暴露频率,d/a;ED为暴露持续时间,30 a;BW为居民平均体重,kg;AT为预期寿命,30×365 d。污染物的胃肠吸收系数见表2。

表1 化学污染物的参考剂量 mg/(kg·d)

表2 污染物的胃肠吸收系数
注:“—”表示未查询到该参数,计算时取“1”。
步骤4 风险表征。风险表征是在收集与分析、毒性评估、暴露评估所获得数据的基础上,估算不同暴露条件下,人群可能产生的健康风险水平或某种健康效应发生的概率[20],即非致癌风险。非致癌风险采用危害商(Hazard Quite,HQ)表示,其计算公式如下:
HQi=Ii/RfDi,
(4)
(5)
式中:HQi为第i种污染物的危害指数;Ii为第i种
污染物的日均暴露剂量,mg/(kg·d);RfDi为第i种污染物的参考剂量,mg/(kg·d);HQ为多种污染物多暴露途径的非致癌总危害指数;n为某一暴露途径中的污染物种类。
饮用水健康风险评价过程中,非确定性因素来源于各个方面,如个体之间的非确定性,包括饮水率、体重、暴露频率等[21]。本文将引用邓玉等[22]调查的名山区农村居民饮用水暴露参数进行水质检测,检测结果见表3,其中居民体重为57.6±11.47 kg、饮水率为1.88±0.66 L/d。

表3 水质检测结果 mg/L
注:“—”表示缺测数据,下同。
2.2 ANN-MC模型的应用
2.2.1 CDI计算
本文将3层BPANN用于评价各项指标的健康风险,并对每个指标单独建立模型。其中:输入层有4个神经元,对应4个随机数,即化学污染物含量、体重、饮水率和暴露频率;输出层为1个神经元,是模拟结果,即某化学污染物饮水途径的健康风险,输出层节点采用perlin传递函数,表达式为:
f(x)=x;
中间层为隐含层,其节点采用tagsin传递函数,表达式为:
thx=(ex-e-x)/(ex+e-x),
通过试验、误差处理获得隐含层优化节点数为9。因此,BPANN模型神经元为[4-9-1],且训练函数采用Levenberg-Marquart法。整个处理过程在MATLAB软件中完成。
BPANN训练采用2010年41个饮用水源中Fe的检测值作为样本,其中34个为训练样本,7个为检验样本。网络参数的初始值均为[-1,1]上的随机数,选取初始学习率为0.01、学习率增长系数为1.04、学习率减小系数为0.75、初始动量因子为0.9。学习过程中可自适应调整学习速率和动量因子,网络收敛条件为网络总误差e<10-6。通过对检验样本的检测,表明BPANN建立了正确的映射关系。网络总误差可用均方误差函数(Mean Square Error,MSE)评价,计算公式如下:
(6)

以2010年Fe的数据为例,检验ANN模型在本文中的表现,检验结果用相关系数R2表示,公式如下:
(7)

图4 Fe的实际CDI与ANN模型预测的CDI的相关系数
由图4可知,训练样本和检测样本中Fe的实际CDI与ANN模型预测的CDI的相关系数分别为0.996 5和0.994 1,均可在小误差情况下用于重复计算每日饮水中Fe摄入量的CDI,说明ANN模型建立正确。在输入基本随机变量后,ANN模型能够快速、准确地计算出相应污染物的每日饮水摄入量的CDI。
ANN模型建立后,可根据表3利用Crystal Ball软件根据8项输入变量的定义分布情况,在95%置信度水平下分别抽样生成10 000个随机数,随机数的抽样方法采用LHS。抽样的同时,用K-S检验法检验抽样样本是否满足误差要求。最后将生成的8项随机数导入已建立的ANN-MC模型中,计算出农村饮用水源、饮水途径的CDI,结果见表4。其中,MSE是衡量“平均误差”的一种较为方便的方法,MSE可以评价数据的变化程度,MSE的值越小,表明预测模型与输入数据之间的精确度越高。

表4 ANN-MC模型预测的农村饮用水源、饮水途径的CDI mg/(kg·d)
由表4可知,8项指标的CDI值的平均误差(MSE)均低于模型训练的网络误差10-6,其中Cr6+的CDI的MSE最小,为4.23×10-12~3.03×10-11mg/(kg·d);NO3-的CDI的MSE最大,为4.36×10-7~7.76×10-7mg/(kg·d),说明ANN-MC模型对于农村饮用水源、饮水途径的CDI预测表现良好。
2.2.2 饮水健康风险
将表4中ANN-MC模型预测的农村饮用水源、饮水途径的CDI值与表1中污染物的RfD值代入公式(4)和(5),计算出8种污染物指标饮水途径的非致癌风险,结果见表5。
将表1、2和4的数据代入公式(3)、(4)和(5),计算出农村饮用水源水质污染物USEPA模型饮水途径非致癌风险,结果见表6。
根据表1输入变量的分布情况,利用传统MC法在95%置信度水平下生成10 000个随机数,代入公式(3)、(4)和(5),计算出农村饮用水源水质污染物饮水途径非致癌风险值,获得5%、95%、100%概率累积分布区间上污染物的非致癌风险的统计分析结果,见表7。

表5 基于ANN-MC模型的污染物健康风险

表6 基于USEPA模型计算的农村饮用水源污染物健康风险

表7 传统MC法模拟农村饮用水源污染物的健康风险
对比表5、6和7可知,ANN-MC模型预测的健康风险与USEPA模型计算的健康风险和MC法5%~95%区间预测的健康风险比较接近。而MC法预测的健康风险在95%~100%区间内变化很大,其原因可能是MC法在该区间的抽样与原来分布不符,MC法抽样技术完全是随机的,即在输入的分布范围内随机抽样,而样本更有可能从较高概率的分布区域中抽取。当概率分布中包含低概率分布区域时,抽样会发生聚集,95%~100%区间为低概率分布区域,抽样数量少且收敛性较差,从而对MC法预测健康风险结果的准确性产生影响。
与MC法相比,ANN-MC模型中的抽样方法为LHS。LHS被设计成通过较少迭代次数的抽样,并准确地重建输入分布,其关键是对输入概率分布进行分层。分层在累积概率尺度(0.0,1.0)上把累积曲线分成相等的区间,再从每个区间中随机抽取样本,抽样被强制代表每个区间的值。如此,对于输入概率分布中包含低概率结果的情况的分析很有帮助,强制模拟中的抽样包含低概率样本,LHS确保低概率样本在模拟的输出中被准确地代表,使ANN-MC模型预测的健康风险低概率区间比较收敛。
因此,ANN-MC模型预测的健康风险与USEPA模型计算的健康风险更接近,即更符合实测数据的健康风险,说明ANN-MC模型比MC法更适合于健康风险评估。
2.3 讨论
通常认为,非致癌风险的最大可接受水平为“1.0”[23]。BLAYLOCK等[24]认为:当HQ<0.1时,化学污染物不会对人群产生不利健康的影响;当0.1≤HQ<1.0时,化学污染物可能会对人群产生不利健康的影响,需进一步调查后采取相应措施;当HQ≥1.0时,化学污染物很可能会对人群产生不利健康的影响,应立即采取补救措施。由表5可知,单种污染物饮用水途径的非致癌风险最大可接受水平为1.0以内,而部分总非致癌风险大于1.0,其中2010年、2011年、2012年总非致癌风险大于1.0的样本分别为0.31%、0.04%和0.04%,表明研究区水源中的化学污染物通过饮水途径对人体产生不利影响的可能性较低。但是非致癌风险为0.1≤HQ<1.0,水源中的化学污染物引起的健康危害不能忽视。ANN-MC模型预测表明2010年、2011年、2012年总非致癌风险为0.1≤HQ<1.0的样本分别为95.00%、78.75%和66.80%,表明区域内大部分居民可能存在饮水途径的健康危害,需要对区域内污染和疾病情况进行调查。同时,部分样本中氟化物、硝酸盐、铁、锰和铜等指标通过饮水途径产生的非致癌风险也超过了0.1,应将其列为区域内重点控制污染物,做进一步的污染源分析。
3 结语
基于USEPA健康风险评价模型,本文构建了ANN-MC健康风险评估模型,并对名山区农村饮用水源中8项指标进行了健康风险评价,得到如下结论:
1)ANN-MC模型预测的健康风险更符合实测数据的健康风险,ANN-MC模型比MC模型更适合于健康风险评估。
2)ANN-MC模型预测的健康风险表明,2010年、2011年、2012年总非致癌总风险HQ≥1.0的样本分别为0.31%、0.04%和0.04%,非致癌总风险为0.1≤HQ<1.0的样本分别为95.00%、78.75%和66.80%,表明区域内大部分居民可能受到饮水途径的健康危害。
3)本区农村饮用水源中需要重点控制的污染物为氟化物、硝酸盐、铁、锰和铜。

(责任编辑:张陵)
Quantitative Analysis of Uncertainty in Health Risk of Rural Drinking Water Sources Based on ANN-MC Model
DENG Yu1, NI Fuquan1, LI Linhuan2, WANG Zhigang2, LIU Jinshan2, ZHOU Dengke2
(1.College of Water Conservancy and Hydropower Engineering, Sichuan Agricultural University, Ya'an 625014, China; 2.College of Environmental Science, Sichuan Agricultural University, Chengdu 611130, China)
The quantification of uncertainty analysis in health risk associated with drinking water sources is very important to accurately estimate water safety. In order to reduce the impact of the uncertainty on the results of health risk assessment, in the paper, based on the model of health risk assessment recommended by the United States Environmental Protection Agency (USEPA) , and combined the methods of Artificial Neural Network (ANN) and Monte Carlo (MC), the model of ANN-MC health risk assessment was constructed, then the model was used to estimate the health risk associated with the rural drinking water sources of typical mountain area in the southwest edge of Sichuan Basin. Results show that in 2010, 2011 and 2012, the sample proportions that the non-carcinogenic risk of the samples is higher than the acceptable level 1.0 are only 0.31%, 0.04% and 0.04% respectively, and the sample proportions that the level of the non-carcinogenic risk of the samples is 0.1≤HQ<0.1 are 95%, 78.75% and 66.8% respectively, it means that most of residents′ health may be threatened by drinking water; The main pollutants in rural drinking water sources of study area are fluoride, nitrate, iron, manganese and copper. The ANN-MC method which has been used to forecast health risk is an effective method to assess the health risks of drinking water sources, and the assessment results can provide more reliable scientific basis for the management of water safety.
drinking water sources; health risk; Monte Carlo; neural network; non-carcinogenic risk
2016-12-26
国际科技合作项目(2012DFG91520-3);四川省教育厅“农村水安全”四川省高等学校工程研究中心项目(035Z2020)。
邓玉(1987—),女,重庆丰都人,讲师,硕士,从事农村饮水安全方面的研究。E-mail:mkdengyu@163.com。
倪福全(1965—),男,四川崇州人,教授,硕导,博士,从事水安全和农业水土环境方面的研究。E-mail:nfq1965@163.com。
10.3969/j.issn.1002-5634.2017.04.004
TV211.1;X503.1
A
1002-5634(2017)04-0025-08
