基于优化Adaboost迭代过程的SVM集成算法
2017-08-28田一明单新颖
田一明,陈 伟,单新颖
(1.国家康复辅具研究中心(北京市老年功能障碍康复辅助技术重点实验室,民政部神经功能信息与康复工程重点实验室),北京1001761;2.河北工业大学 控制科学与工程学院,天津 300130)
基于优化Adaboost迭代过程的SVM集成算法
田一明1,2,陈 伟1,单新颖1
(1.国家康复辅具研究中心(北京市老年功能障碍康复辅助技术重点实验室,民政部神经功能信息与康复工程重点实验室),北京1001761;2.河北工业大学 控制科学与工程学院,天津 300130)
为提高Adaboost算法迭代过程中生成基分类器的分类精度以及简化整个集成学习系统的复杂度,文章提出了一种优化Adaboost迭代过程的SVM集成算法。该算法提出了一种在其迭代过程中加入样本选择和特征选择的集成方法。通过均值近邻算法对样本进行选择,并利用相对熵法进行特征选择,最后利用优化得到的特征样本子集对基分类器SVM进行训练,并用加权投票法融合各个SVM基分类器的决策结果进行最终判决。通过对UCI数据集的仿真结果表明,本算法与支持向量机集成算法相比,能够在更少的样本以及特征的基础上,实现较高的识别正确率。
集成学习;均值近邻;支持向量机
1 集成学习出现背景
在处理复杂模式识别的问题时,传统的机器学习方法所得到的识别结果往往不能使人满意。集成学习是目前应对复杂模式识别问题的一种有效方法。一些国际上的知名学者认为集成学习有着巨大的潜力,它将会是21世纪机器学习最为重要的研究方向[1]。近年来各国学者针对集成学习方法的研究做了大量的工作,但是集成学习也同样面临着许多问题,如增加了处理问题的时间以及增大了计算机的存储开销,并且由于不能很好地对分类器的性能进行差异性度量,造成集成学习的优势不明显等问题。付忠良[2]利用自适应提升的思想设计了一种多标签代价敏感分类集成学习算法。孙博等[3]对集成学习中基分类器之间的多样性度量方法从不同角度进行了分析,并展望了多样性度量进一步的研究方向。韩敏等[4]使用最大相关和最小冗余准则对基分类器进行选择,这种方法能够在一定程度上到达各分类器之间的冗余性最小而实现分类器与实际输出之间的相关性最大,从而实现准确性和差异性的平衡。唐焕玲等[5]提出了一种基于投票信息熵的Adaboost样本权重维护策略,考虑基分类器之间的差异性对基分类器的信任度的影响。
本文提出一种对Adaboost迭代过程进行改进的支持向量机(Support Vector Machine,SVM)集成算法。本算法在Adaboost迭代过程中加入对样本的选择和特征的选择,去除训练集中的相似样本,提高样本和特征的差异性。通过使用UCI公共数据库中的数据集对本算法进行验证,实验结果表明,本算法能够去除训练集中的冗余信息,减少SVM的训练时间,以少量训练样本获得较高的识别率。
2 优化Adaboost迭代过程的SVM集成算法
2.1 基于均值近邻的样本选择算法
基于均值近邻的样本选择算法[6]首先通过计算待选择训练样本的均值,之后将距离该均值最近的样本作为选中样本,通过迭代过程,不断选择新的样本,直到训练集中的样本数满足预定阈值要求。
2.1.1 巴氏距离
样本之间关系的量化可以通过类似于信息熵的指标作为衡量的标准,同时也可以用巴氏距离来衡量。巴氏距离的定义如下:

式中µ1和µ2分别代表两个样本在样本集中表达水平的均值,σ1和σ2为这两个样本在样本集中表达水平的标准差。巴氏距离可以更全面地考虑样本之间的关系。
2.1.2 样本选择算法具体步骤
(1)初始化。设定所选样本个数θ,以及选择阈值τ,初始的样本均值向量为µ0,初始样本集为S,初始的待定级为空集G。
(2)计算样本集中样本与µ0的巴氏距离Bi,在样本集中搜索最小距离Bmin,将所对应的第k个样本记为选中样本Xs。计算选中样本与其余样本的巴氏距离Bki,将Bki与选择阈值进行比较来决定是否将样本移动到待定集G。
(3)如果无任何样本使得Bki<τ,或者待定集中的样本为空,则退出,否则重复第二步。
2.2 基于相对熵的特征选择
2.2.1 相对熵
为了选出更有类别区分度的特征,本文提出一种相对熵特征选择方法。针对特征t和类别Ci,将特征空间分为属于类别Ci的和不属于类别Ci的。此时,特征t相对熵为:

式中,P(Ci)为样本属于类别Ci的概率,P(Ci|t)为在出现特征t的前提下样本属于类别Ci的条件概率。为样本不属于类别的概率,为在出现特征t的前提下样本不属于类别Ci的条件概率。
上式中的单个元素:

衡量了特征t对类别Ci和Ci的鉴别信息,其值与类别的相关程度成正比,表明特征对类别的区分能力越好。
2.2.2 特征的选择
利用相对熵法进行特征选择,就是对特征计算其RE,然后按照值RE从大到小对特征进行排序,最终特征维数的选择一般有两种方法。
(1)指定特征维数M,按照从大到小顺序选取前M个特征构成特征空间。
(2)指定一个衰减幅度Ψ,选择RE值大于RE(t0)×Ψ的前M个特征,其中RE(t0)为排序第一个特征所对应的RE值。
2.3 集成学习系统
本文采用加权多数投票法对每次循环生成的个体SVM分类器进行集成。每一个基分类器对样本类别作出决策,综合所有基分类器的投票结果作出对样本类别的综合决策,最终票数最多的类别被确定为这个样本的类别,直到所有样本的类别被全部预测,所得到的分类结果即为分类器集成的最终分类结果。
3 实验及分析
3.1 实验数据
实验采用UCI数据库中的数据集Wine和Zoo对本文算法进行了测试,其中这两种数据集的特征均为数值类型。
3.2 分类实验
应用本文算法对两种数据集进行测试,通过样本选择性能和识别正确率等指标对所提算法进行分析。
3.2.1 样本选择结果
使用均值近邻对样本进行选择,不能完全体现样本的重要性和差异性。因此,引入样本重要性指数来定义其在样本集中的重要性,如公式所示:

式中:Vi是第i个样本的重要性指数,Z为训练个体分类器的个数,ui是第i个样本在Z次迭代中被选择的次数。样本的重要性指数越高,对分类就越有效。两种测试集中样本的归一化重要性指数如图1所示。
从图1可知,两种不同的数据集,其中不同样本的重要程度是不同的。如果这些样本都用来训练分类器,这显然是会影响效率的。本文选择重要性指数高于0.6的样本作为样本子集,用优化过的样本集对基分类器进行训练,有利于提高基分类器的分类性能。

图1 不同特征集下样本重要性指数
3.2.2 特征选择结果
依据本文算法测试当对两种数据集选择不同的特征时,所对应的平均正确分类率,如图2所示。
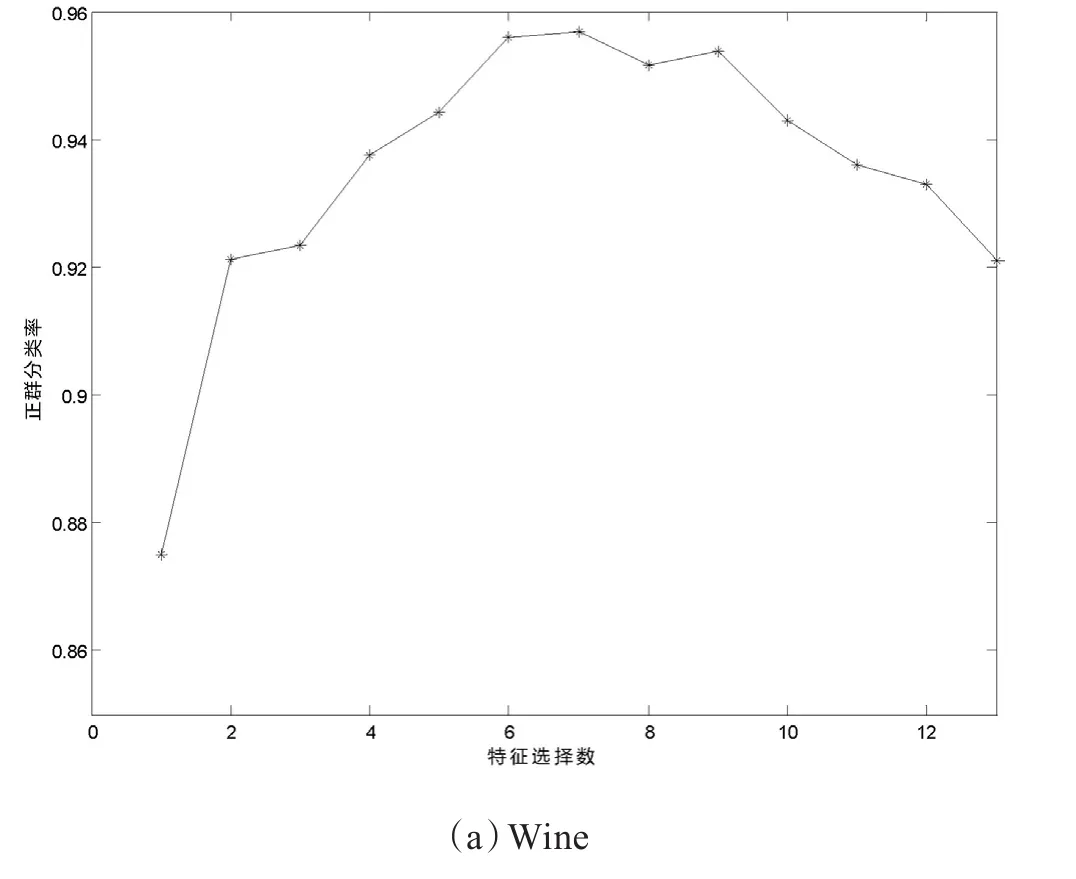

图2 特征选择数目与识别率之间关系
从图2可以看出,并不是特征越多,所得到的分类正确率越高。刚开始,分类正确率曲线随着特征选数的增加而升高,当达到某一个数量值时,特征选择数的增加对分类正确率没的积极的作用不明显了。总体来看,过少的特征不足以起到对样本充分表达的效果,导致正确分类率不能达到理想的效果,而冗余的特征也会导致分类率变差。因此本文提出的算法不仅能够降低冗余特征的影响,同时能够保证有充分的特征对样本进行表达。
3.2.3 本文方法与SVME的性能对比
通过将本文算法与SVME算法分别对两个数据集的实验测试,从平均正确分类率、样本选择数与特征选择数量3个方面比较这两种算法的性能。实验结果如表1所示。

表1 实验结果
从表1可以看出,对于不同的数据集,本文算法选择的特征数与样本数都少于SVME算法。对于离散型数据集Zoo,本文方法只用了SVME算法的46%特征数量和29%的样本数对基分类器进行训练,正确率也比SVME算法提高了3%。同时本算法对连续型数据集Wine也起到了不错的效果,能够在提高连续型数据集识别率的前提下,特征数分别只有SVME算法的83%,样本选择数分别只有SVME算法的31%,起到了对样本集和特征优化的作用。
4 结语
本文通过对Adaboost的迭代过程进行改进,在每次迭代的过程中加入了对样本选择和特征选择的部分来构造SVM集成算法,最后通过加权投票法对基分类器进行集成,从而得到最终的综合分类器。采用4种来自UCI的数据集对本文方法进行分类试验,结果表明,本文方法对不同种类的数据集均能实现有效的样本选择和特征选择,从而能够去除一部分噪音样本和冗余特征,选择可靠样本进行训练,提高每次迭代过程中训练出基分类器的性能,本算法训练出的集成分类器比较传统方法训练出的集成分类器具有更好的分类性能。
[1]DIETTERICH T G.Machine learning research:Four curren directions[J].AI Magazine,1997(4):97-136.
[2]付忠良.多标签代价敏感分类集成学习算法[J].自动化学报,2014(6):40-42.
[3]孙博,王建东,陈海燕,等.集成学习中的多样性度量[J].控制与决策,2014(3):385-395.
[4]韩敏,吕飞.基于互信息的选择性集成核极端学习机[J].控制与决策,2015(11):2089-2092.
[5]唐焕玲,鲁明羽,邬俊.基于投票信息熵的Adaboost改进算法[J].控制与决策,2010(4):487-492.
[6]杨立.基于均值近邻的样本选择算法[J].微型机与应用,2014(17):80-82.
SVM integration algorithm based on optimized Adaboost iterative process
Tian Yiming1,2, Chen Wei1, Shan Xinying1
(1. National Rehabilitation Aids Research Center(Key Laboratory of Beijing Elderly Dysfunction Rehabilitation Assistive Technology, Ministry of Civil Affairs Neurological Rehabilitation Engineering Key Laboratory), Beijing 1001761, China; 2. Control Science and Engineering College of Hebei University of Technology, Tianjin 300130, China)
In order to improve the classi fi cation accuracy of generating base classi fi er in Adaboost algorithm iterative process and simplify the complexity of the whole integrated learning system, this paper puts forward an integrated algorithm of SVM to optimize Adaboost iterative process. An integrated approach of adding sample selection and feature selection is proposed during its iteration process. The mean nearest neighbor algorithm is adopted to select the samples, and relative entropy method is used for feature selection, fi nally the optimized feature sample set is used for training the base classi fi er SVM, the weighted voting method is fi nally decided by fusing the decision results of each SVM based classi fi er. Through the simulation result of UCI data sets, compared with the algorithm integrated with support vector machine algorithm, the algorithm can achieve a high correct recognition rate based on fewer samples as well as features.
ensemble learning; mean nearest neighbor; support vector machines
田一明(1988— ),男,河北唐山,博士研究生;研究方向:康复机器人,专业化养老。
